SQL - Leçon 15. Procédures stockées. Partie 1.
En règle générale, lorsque nous travaillons avec une base de données, nous utilisons les mêmes requêtes, ou un ensemble de requêtes séquentielles. Les procédures stockées vous permettent de combiner une séquence de requêtes et de les stocker sur le serveur. C'est un outil très pratique, et maintenant vous le verrez. Commençons par la syntaxe:CREATE PROCEDURE sp_name (paramètres) begin end instructions
Les paramètres sont les données que nous passerons à la procédure lors de son appel, et les opérateurs sont les requêtes réelles. Écrivons notre première procédure et voyons à quel point elle est pratique. Dans la leçon 10, lorsque nous avons ajouté de nouveaux enregistrements à la base de données de la boutique, nous avons utilisé une requête d'ajout standard du formulaire:
INSERT INTO clients (nom, e-mail) VALUE ("Ivanov Sergey", " [email protected]");
Car demande similaire nous l'utilisons à chaque fois que nous aurons besoin d'ajouter un nouveau client, il convient tout à fait de l'organiser sous la forme d'une procédure:
CREATE PROCEDURE ins_cust (n CHAR (50), e CHAR (50)) commence l'insertion dans les clients (nom, e-mail) value (n, e); fin
Faites attention à la façon dont les paramètres sont définis: vous devez donner un nom au paramètre et spécifier son type, et dans le corps de la procédure, nous utilisons déjà les noms des paramètres. Une nuance. Comme vous vous en souvenez, le point-virgule signifie la fin de la demande et l'envoie pour exécution, ce qui n'est pas acceptable dans ce cas. Par conséquent, avant d'écrire la procédure, vous devez remplacer le séparateur par; à "//" afin que la demande ne soit pas envoyée à l'avance. Cela se fait à l'aide de l'instruction DELIMITER //: 
Ainsi, nous avons indiqué au SGBD que les commandes doivent maintenant être exécutées après //. Il faut se rappeler que le délimiteur n'est redéfini que pour une session, c'est-à-dire la prochaine fois que vous travaillerez avec MySql, le séparateur redeviendra un point-virgule et devra être redéfini si nécessaire. Maintenant, nous pouvons placer la procédure:
CREATE PROCEDURE ins_cust (n CHAR (50), e CHAR (50)) commence l'insertion dans les clients (nom, e-mail) value (n, e); fin //

Donc, la procédure a été créée. Désormais, lorsque nous devons saisir un nouveau client, il suffit de l'appeler en spécifiant les paramètres nécessaires. Une instruction CALL est utilisée pour appeler une procédure stockée, suivie du nom de la procédure et de ses paramètres. Ajoutons un nouveau client à notre table clients:
appeler ins_cust ("Valery Sychov", " [email protected]")//

Convenez que c'est beaucoup plus facile que d'écrire une demande complète à chaque fois. Vérifions si la procédure fonctionne en cherchant à voir si un nouveau client est apparu dans la table des clients:

Apparu, la procédure fonctionne et fonctionnera toujours jusqu'à ce que nous la supprimions à l'aide de l'opérateur DROP PROCEDURE nom_procédure.
Comme mentionné au début de la leçon, les procédures vous permettent de combiner une séquence de demandes. Voyons comment cela se fait. Rappelez-vous dans la leçon 11, nous voulions savoir combien le fournisseur "Printing House" nous a apporté la marchandise? Pour ce faire, nous avons dû utiliser des requêtes imbriquées, des jointures, des colonnes calculées et des vues. Et si nous voulons savoir combien l'autre fournisseur nous a apporté la marchandise? Vous devrez composer de nouvelles requêtes, associations, etc. Il est plus facile d'écrire une seule fois une procédure stockée pour cette action.
Il semblerait que le moyen le plus simple est de prendre la vue et la requête déjà écrites dans la leçon 11, de la combiner dans une procédure stockée et de faire de l'ID du fournisseur (id_vendor) un paramètre d'entrée, comme ceci:
CREATE PROCEDURE sum_vendor (i INT) begin CREATE VIEW report_vendor AS SELECT magazine_incoming.id_product, magazine_incoming.quantity, price.price, magazine_incoming.quantity * price.price AS summa FROM magazine_incoming, price WHERE_coming_incoming.id_product \u003d price.id_product \u003d price SELECT id_incoming FROM entrant WHERE id_vendor \u003d i); SELECT SUM (summa) FROM report_vendor; fin //
Mais cela ne fonctionnera pas. Le truc c'est que aucun paramètre ne peut être utilisé dans les vues... Par conséquent, nous devrons modifier légèrement la séquence des demandes. Tout d'abord, nous allons créer une vue qui affichera l'identifiant du fournisseur (id_vendor), l'identifiant du produit (id_product), la quantité (quantité), le prix (prix) et la somme (summa) à partir de trois tables Livraison (entrante), Journal des livraisons (magazine_incoming), Prix ( des prix):
CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, price.price, magazine_incoming.quantity * price.price AS summa FROM incoming, magazine_incoming, price WHERE magazine_incoming.id_product \u003d incoming.id_product AND magazine_comingid .id_incoming;
Et puis nous créerons une demande qui résumera les quantités d'approvisionnement du fournisseur qui nous intéresse, par exemple avec id_vendor \u003d 2:
Nous pouvons maintenant combiner ces deux requêtes dans une procédure stockée, où le paramètre d'entrée sera l'identifiant du fournisseur (id_vendor), qui sera remplacé dans la deuxième requête, mais pas dans la vue:
CREATE PROCEDURE sum_vendor (i INT) begin CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, price.price, magazine_incoming.quantity * price.price AS summa FROM incoming, magazine_incoming, WHERE magazine_incoming. .id_product AND magazine_incoming.id_incoming \u003d entrant.id_incoming; SELECT SUM (summa) FROM report_vendor WHERE id_vendor \u003d i; fin //

Vérifions le fonctionnement de la procédure, avec différents paramètres d'entrée:

Comme vous pouvez le voir, la procédure se déclenche une fois, puis renvoie une erreur, nous indiquant que la vue report_vendor est déjà dans la base de données. En effet, la première fois qu'une procédure est appelée, elle crée une vue. Lors de l'accès une deuxième fois, il tente de créer à nouveau une vue, mais elle existe déjà, c'est pourquoi une erreur apparaît. Il y a deux manières possibles d'éviter cela.
Le premier est de retirer l'idée de la procédure. Autrement dit, nous créerons une vue une fois, et la procédure y fera uniquement référence, mais ne la créera pas. Il n'oubliera pas de supprimer la procédure déjà créée et de visualiser:
DROP PROCEDURE somme_vendor // DROP VIEW report_vendor // CREATE VIEW report_vendor AS SELECT \u003d price.id_product AND magazine_incoming.id_incoming \u003d incoming.id_incoming // CREATE PROCEDURE sum_vendor (i INT) begin SELECT SUM (summa) FROM report_vendor WHERE id_vendor \u003d i; fin //

Vérification du travail:
appeler sum_vendor (1) // appeler sum_vendor (2) // appeler sum_vendor (3) //
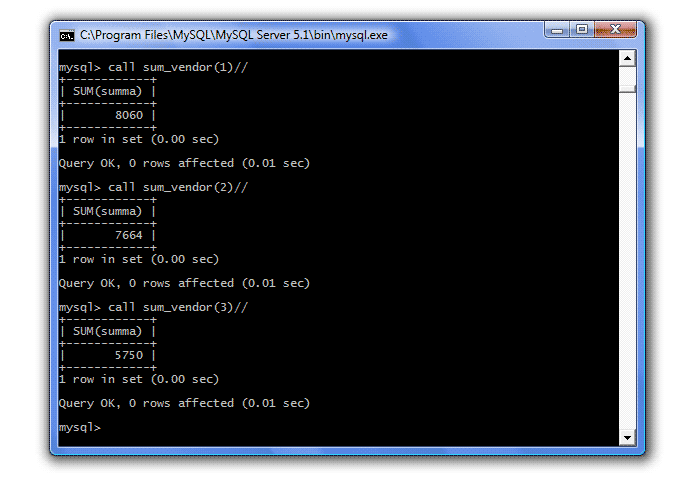
La deuxième option consiste à ajouter une commande directement dans la procédure qui supprimera la vue, si elle existe:
CREATE PROCEDURE sum_vendor (i INT) begin DROP VIEW IF EXISTS report_vendor; CRÉER VUE report_vendor AS SELECT. .id_incoming; SELECT SUM (summa) FROM report_vendor WHERE id_vendor \u003d i; fin //
N'oubliez pas de supprimer la routine sum_vendor avant d'utiliser cette option, puis de la tester: 
Comme vous pouvez le voir, les requêtes complexes ou leur séquence sont vraiment plus faciles à former une fois dans une procédure stockée, puis à y faire référence, en spécifiant les paramètres nécessaires. Cela réduit considérablement le code et rend le travail avec les requêtes plus logique.
Incluez dans vos procédures la ligne - SET NOCOUNT ON:
Avec chaque instruction DML, le serveur SQL nous renvoie soigneusement un message contenant le nombre d'enregistrements traités. Cette information peut nous être utile lors du débogage du code, mais par la suite, ce sera complètement inutile. En prescrivant SET NOCOUNT ON, nous désactivons cette fonction. Pour les procédures stockées contenant plusieurs expressions ou \\ et boucles cette action peut donner une augmentation significative des performances, car la quantité de trafic sera considérablement réduite.
Transact-SQL
Utilisez le nom du schéma avec le nom de l'objet:
Eh bien, ici je pense que c'est clair. Cette opération indique au serveur où chercher les objets et au lieu de fouiller aléatoirement dans ses bacs, il saura immédiatement où il doit aller et quoi emporter. Avec un grand nombre de bases de données, de tables et de procédures stockées, il peut considérablement économiser notre temps et nos nerfs.
Transact-SQL
SELECT * FROM dbo.MyTable --C'est bien de faire ceci - Au lieu de SELECT * FROM MyTable - Et c'est mal de faire cela --Appeler EXEC dbo.MyProc - Encore bien - Au lieu de EXEC MyProc - Mauvais!
N'utilisez pas le préfixe "sp_" dans le nom de vos procédures stockées:
Si le nom de notre procédure commence par "sp_", SQL Server cherchera d'abord dans sa base de données master. Le fait est que ce préfixe est utilisé pour les procédures stockées internes personnelles du serveur. Par conséquent, son utilisation peut entraîner des coûts supplémentaires et même un résultat incorrect si une procédure portant le même nom que le vôtre se trouve dans sa base de données.
Utilisez IF EXISTS (SELECT 1) au lieu de IF EXISTS (SELECT *):
Pour rechercher un enregistrement dans une autre table, nous utilisons l'instruction IF EXISTS. Cette expression renvoie true si au moins une valeur est renvoyée par l'expression interne, peu importe "1", toutes les colonnes ou une table. Les données renvoyées, en principe, ne sont en aucun cas utilisées. Ainsi, pour compresser le trafic lors de la transmission de données, il est plus logique d'utiliser "1", comme illustré ci-dessous.
Pour la programmation de procédures stockées étendues, Microsoft fournit l'API ODS (Open Data Service) avec un ensemble de macros et de fonctions utilisées pour créer des applications serveur qui étendent les fonctionnalités de MS SQL Server 2000.
Les procédures stockées étendues sont des fonctions ordinaires écrites en C / C ++ à l'aide de l'API ODS et de l'API WIN32, conçues sous la forme d'une bibliothèque de liens dynamiques (dll) et conçues, comme je l'ai dit, pour étendre les fonctionnalités du serveur SQL. L'API ODS fournit au développeur un riche ensemble de fonctions qui permettent au client de transférer les données reçues de toute source de données externe sous la forme de jeux d'enregistrements ordinaires. En outre, la procédure stockée étendue peut renvoyer des valeurs via le paramètre qui lui est passé (paramètre OUTPUT).
Fonctionnement des procédures stockées étendues.
- Lorsqu'une application client appelle une procédure stockée étendue, la demande est transmise au format TDS via les bibliothèques réseau et Open Data Service au noyau MS SQL SERVER.
- SQL Server recherche la bibliothèque dll associée au nom de la procédure stockée étendue et la charge dans son contexte, si elle n'y a pas été chargée précédemment, et appelle la procédure stockée étendue implémentée en tant que fonction dans la dll.
- La procédure stockée étendue effectue les actions dont elle a besoin sur le serveur et transmet le jeu de résultats à l'application cliente à l'aide du service fourni par l'API ODS.
Caractéristiques des procédures stockées étendues.
- Les procédures stockées étendues sont des fonctions exécutées dans l'espace d'adressage MS SQL Server et dans le contexte de la sécurité du compte sous lequel le service MS SQL Server est exécuté;
- Une fois la dll de procédure stockée étendue chargée en mémoire, elle y reste jusqu'à ce que SQL Server soit arrêté ou jusqu'à ce que l'administrateur l'oblige à la décharger à l'aide de la commande:
DBCC DLL_name (GRATUIT). - Une procédure stockée étendue est exécutée de la même manière qu'une procédure stockée normale:
EXÉCUTER xp_extendedProcName @ param1, @ param2 OUTPUT
@ paramètre d'entrée param1
@ paramètre d'entrée / sortie param2
Étant donné que les procédures stockées étendues sont exécutées dans l'espace d'adressage du processus de service MS SQL Server, toute erreur critique qui se produit dans leur travail peut endommager le cœur du serveur, il est donc recommandé de tester minutieusement votre DLL avant de l'installer sur un serveur de production.
Création de procédures stockées étendues.
Procédure stockée étendue cette fonction a le prototype suivant:
SRVRETCODE xp_extendedProcName (SRVPROC * pSrvProc);
Paramètre pSrvProc un pointeur vers une structure SRVPROC qui est un handle pour chaque connexion client spécifique. Les champs de cette structure ne sont pas documentés et contiennent des informations que la bibliothèque ODS utilise pour gérer la communication et les données entre l'application serveur Open Data Services et le client. Dans tous les cas, vous n'avez pas besoin de vous référer à cette structure et, de plus, vous ne pouvez pas la modifier. Ce paramètre doit être spécifié lors de l'appel d'une fonction API ODS, je ne m'attarderai donc pas sur sa description à l'avenir.
L'utilisation du préfixe xp_ est facultative, mais il existe une convention pour commencer le nom d'une procédure stockée étendue de manière à souligner la différence par rapport à une procédure stockée normale, dont les noms, comme vous le savez, commencent par le préfixe sp_.
N'oubliez pas non plus que les noms de procédure stockée étendue sont sensibles à la casse. Souvenez-vous de cela lorsque vous appelez la procédure stockée étendue, sinon vous recevrez un message d'erreur au lieu du résultat attendu.
Si vous avez besoin d'écrire du code d'initialisation / de désinitialisation de dll, utilisez la fonction DllMain () standard pour cela. Si vous n'avez pas un tel besoin et que vous ne voulez pas écrire DLLMain (), le compilateur construira sa propre version de la fonction DLLMain (), qui ne fait rien, mais renvoie simplement TRUE. Toutes les fonctions appelées à partir de dll (c'est-à-dire les procédures stockées étendues) doivent être déclarées comme exportées. Si vous écrivez en MS Visual C ++, utilisez la directive __declspec (dllexport)... Si votre compilateur ne prend pas en charge cette directive, décrivez la fonction exportée dans la section EXPORTS du fichier DEF.
Donc, pour créer un projet, nous avons besoin des fichiers suivants:
- Le fichier d'en-tête Srv.h contient des descriptions des fonctions et des macros de l'API ODS;
- Opends60.lib est un fichier d'importation pour la bibliothèque Opends60.dll, qui implémente l'ensemble du service fourni par l'API ODS.
Declspec (dllexport) ULONG __GetXpVersion ()
{
return ODS_VERSION;
}
Lorsque MS SQL Server charge une DLL avec une procédure stockée étendue, il appelle d'abord cette fonction pour obtenir des informations sur la version de la bibliothèque utilisée.
Pour écrire votre première procédure stockée étendue, vous devez installer sur votre ordinateur:
MS SQL Server 2000 de n'importe quelle édition (j'ai Edition personnelle). Pendant le processus d'installation, assurez-vous de sélectionner l'option d'échantillon source
- MS Visual C ++ (j'ai utilisé la version 7.0), mais je sais que 6.0 fera l'affaire
L'installation de SQL Server -a est nécessaire pour tester et déboguer votre DLL. Le débogage sur le réseau est également possible, mais je n'ai jamais fait cela, et donc installé tout sur mon disque local... Microsoft Visual C ++ 7.0 Interprise Edition inclut l'Assistant DLL de procédure stockée étendue. En principe, il ne fait rien au-delà du naturel, mais génère uniquement un modèle pour une procédure stockée étendue. Si vous aimez l'assistant, vous pouvez l'utiliser. Je préfère tout faire avec des stylos, et donc je ne considérerai pas ce cas.
Maintenant au point:
- Démarrez Visual C ++ et créez un nouveau projet - Win32 Dynamic Link Library.
- Inclure le fichier d'en-tête dans le projet - #include
- Allez dans le menu Outils \u003d\u003e Options et ajoutez des chemins de recherche pour les fichiers d'inclusion et de bibliothèque. Si, lors de l'installation de MS SQL Server, vous n'avez rien changé, définissez:
C: Program FilesMicrosoft SQL Server80ToolsDevToolsInclude pour les fichiers d'en-tête;
- C: Program Files Microsoft SQL Server 80ToolsDevToolsLib pour les fichiers de bibliothèque.
- Spécifiez le nom du fichier de bibliothèque opends60.lib dans les options de l'éditeur de liens.
À ce stade, la phase préparatoire étant terminée, vous pouvez commencer à écrire votre première procédure stockée étendue.
Formulation du problème.
Avant de commencer la programmation, vous devez avoir une idée claire de par où commencer, quel devrait être le résultat final et comment y parvenir. Alors, voici la tâche technique pour nous:
Développez une procédure stockée étendue pour MS SQL Server 2000 qui reçoit une liste complète des utilisateurs enregistrés dans le domaine et la renvoie au client sous la forme d'un jeu d'enregistrements standard. Comme premier paramètre d'entrée, la fonction reçoit le nom du serveur contenant le répertoire de la base de données ( Active Directory), c'est-à-dire le nom du contrôleur de domaine. Si ce paramètre est NULL, une liste de groupes locaux doit être transmise au client. Le deuxième paramètre sera utilisé par la procédure stockée étendue pour renvoyer le résultat de réussite / échec (paramètre OUTPUT). Si la procédure stockée étendue réussit, il est nécessaire de transférer le nombre d'enregistrements renvoyés au jeu d'enregistrements client, si pendant l'opération, il n'a pas été possible d'obtenir les informations requises, la valeur du deuxième paramètre doit être définie sur -1, en signe d'échec.
Le prototype conditionnel de la procédure stockée étendue est le suivant:
xp_GetUserList (@NameServer varchar, @CountRec int OUTPUT);
Et voici le modèle de procédure stockée étendue que nous devons remplir avec du contenu:
#comprendre
#comprendre
#define XP_NOERROR 0
#define XP_ERROR -1
__declspec (dllexport) SERVRETCODE xp_GetGroupList (SRVPROC * pSrvProc)
{
// Vérifier le nombre de paramètres passés
// Vérification du type de paramètres passés
// Vérifier si le paramètre 2 est un paramètre OUTPUT
// Vérifie si le paramètre 2 est assez long pour stocker la valeur
// Récupère les paramètres d'entrée
// Obtenir une liste d'utilisateurs
// Envoie les données reçues au client sous la forme d'un jeu d'enregistrements standard
// Définit la valeur du paramètre OUTPUT
retour (XP_NOERROR);
}
Travailler avec des paramètres d'entrée
Dans ce chapitre, je ne souhaite pas disperser votre attention sur des éléments superflus, mais je souhaite me concentrer sur l'utilisation des paramètres passés à la procédure stockée étendue. Par conséquent, nous simplifierons quelque peu notre tâche technique et ne développerons que la partie qui fonctionne avec les paramètres d'entrée. Mais pas beaucoup de théorie au début
La première action que notre procédure stockée étendue doit effectuer est d'obtenir les paramètres qui lui ont été transmis lors de son appel. En suivant l'algorithme ci-dessus, nous devons faire ce qui suit:
Déterminez le nombre de paramètres passés;
- Assurez-vous que les paramètres transmis sont du type de données correct;
- Assurez-vous que le paramètre OUTPUT spécifié est suffisamment long pour stocker la valeur renvoyée par notre procédure stockée étendue.
- Obtenez les paramètres passés;
- Définissez les valeurs du paramètre de sortie à la suite de l'achèvement réussi / échec de la procédure stockée étendue.
Maintenant, regardons de plus près chaque point:
Détermination du nombre de paramètres passés à une procédure stockée étendue
Pour obtenir le nombre de paramètres passés, utilisez la fonction:
int srv_rpcparams (SRV_PROC * srvproc);
En cas de succès, la fonction renvoie le nombre de paramètres passés à la procédure stockée étendue. Si la procédure stockée étendue a été appelée sans paramètres, srv_rpcparams renverra -1. Les paramètres peuvent être passés par nom ou par position (sans nom). Dans tous les cas, vous ne pouvez pas mélanger ces deux méthodes. Une tentative de passer des paramètres d'entrée à la fonction par nom et par position en même temps entraînera une erreur et srv_rpcparams renverra 0.
Déterminer le type de données et la longueur des paramètres passés
Microsoft recommande d'utiliser la fonction srv_paramifo pour obtenir des informations sur le type et la longueur des paramètres passés. Cette fonction générique remplace les appels srv_paramtype, srv_paramlen, srv_parammaxlen, qui sont désormais obsolètes. Voici son prototype:
int srv_paraminfo (
SRV_PROC * srvproc,
int n,
BYTE * pbType,
ULONG * pcbMaxLen,
ULONG * pcbActualLen,
BYTE * pbData,
BOOL * pfNull);
pbType spécifie le numéro de série du paramètre. Le premier numéro de paramètre commence par 1.
pcbMaxLen un pointeur vers une variable dans laquelle la fonction stocke la valeur maximale de la longueur du paramètre. Cette valeur est déterminée par le type de données spécifique du paramètre passé, et nous l'utiliserons pour nous assurer que le paramètre OUTPUT est suffisamment long pour stocker les données transmises.
pcbActualLen pointeur vers la longueur réelle du paramètre passé à la procédure stockée étendue lors de l'appel. Si le paramètre passé a une longueur nulle et que l'indicateur pfNull est défini sur FALSE, alors (* pcbActualLen) \u003d\u003d 0.
pbData - pointeur vers le tampon pour lequel la mémoire doit être allouée avant d'appeler srv_paraminfo. La fonction place les paramètres d'entrée reçus de la procédure stockée étendue dans ce tampon. La taille du tampon en octets est égale à la valeur de pcbMaxLen. Si ce paramètre est défini sur NULL, les données ne sont pas écrites dans la mémoire tampon, mais la fonction renvoie correctement les valeurs * pbType, * pcbMaxLen, * pcbActualLen, * pfNull. Par conséquent, vous devez appeler srv_paraminfo deux fois: d'abord avec pbData \u003d NULL, puis, après avoir alloué la taille de mémoire requise pour un tampon égal à pcbActualLen, appelez srv_paraminfo une deuxième fois, en passant un pointeur vers le bloc de mémoire alloué à pbData.
pfNull pointeur vers un indicateur NULL. srv_paraminfo le définit sur TRUE si le paramètre d'entrée est NULL.
Vérifiez si le deuxième paramètre est un paramètre OUTPUT.
La fonction srv_paramstatus () est conçue pour déterminer l'état du paramètre passé:
int srv_paramstatus (
SRV_PROC * srvproc,
int n
);
n est le numéro du paramètre passé à la procédure stockée étendue lors de son appel. Je vous le rappelle: les paramètres sont toujours numérotés à partir de 1.
Srv_paramstatus utilise un bit zéro pour renvoyer une valeur. S'il est défini sur 1, le paramètre passé est un paramètre OUTPUT, s'il est défini sur 0, il s'agit d'un paramètre normal passé par valeur. Si la procédure stockée étendue a été appelée sans paramètre, la fonction renverra -1.
Réglage de la valeur du paramètre de sortie.
Le paramètre de sortie passé au magasin étendu peut recevoir une valeur à l'aide de la fonction srv_paramsetoutput. Ce nouvelle fonction remplace l'appel à la fonction srv_paramset, qui est désormais considérée comme obsolète, car ne prend pas en charge les nouveaux types de données introduits dans l'API ODS et les données de longueur nulle.
int srv_paramsetoutput (
SRV_PROC * srvproc,
int n,
BYTE * pbData,
ULONG cbLen,
BOOL fNull
);
pbData pointeur vers un tampon avec des données qui seront envoyées au client pour définir la valeur du paramètre de sortie.
cbLen la longueur du tampon de données envoyé. Si le type de données du paramètre OUTPUT transmis spécifie des données de longueur constante et n'autorise pas le stockage d'une valeur NULL (par exemple SRVBIT ou SRVINT1), la fonction ignore le paramètre cbLen. CbLen \u003d 0 indique des données de longueur nulle et fNull doit être défini sur FALSE.
fNull définissez ceci sur TRUE si le paramètre de retour doit être NULL et cbLen doit être 0, sinon la fonction échouera. Dans tous les autres cas, fNull \u003d FALSE.
En cas de succès, la fonction renvoie SUCCEED. Si la valeur de retour est FAIL, l'appel a échoué. Tout est simple et clair
Maintenant, nous en savons assez pour écrire notre première procédure stockée étendue, qui retournera une valeur via le paramètre qui lui est passé, que ce soit la chaîne Hello world! La version de débogage de l'exemple peut être téléchargée ici.
#comprendre
#define XP_NOERROR 0
#define XP_ERROR 1
#define MAX_SERVER_ERROR 20000
#define XP_HELLO_ERROR MAX_SERVER_ERROR + 1
void printError (SRV_PROC *, CHAR *);
#ifdef __cplusplus
extern "C" (
#fin si
SRVRETCODE __declspec (dllexport) xp_helloworld (SRV_PROC * pSrvProc);
#ifdef __cplusplus
}
#fin si
SRVRETCODE xp_helloworld (SRV_PROC * pSrvProc)
{
char szText \u003d "Bonjour le monde!";
BYTE bType;
ULONG cbMaxLen;
ULONG cbActualLen;
BOOL fNull;
/ * Détermine le nombre de passés au stockage étendu
procédure de paramétrage * /
si (srv_rpcparams (pSrvProc)! \u003d 1)
{
printError (pSrvProc, "Mauvais nombre de paramètres!");
retour (XP_ERROR);
}
/ * Obtenir des informations sur le type de données et la longueur des paramètres passés * /
si (srv_paraminfo (pSrvProc, 1, & bType, & cbMaxLen,
& cbActualLen, NULL et fNull) \u003d\u003d FAIL)
{
printError (pSrvProc,
"Impossible d'obtenir des informations sur les paramètres d'entrée ...");
retour (XP_ERROR);
}
/ * Vérifie si le paramètre OUTPUT passé est un paramètre * /
if ((srv_paramstatus (pSrvProc, 1) & SRV_PARAMRETURN) \u003d\u003d FAIL)
{
printError (pSrvProc,
"Le paramètre passé n'est pas un paramètre OUTPUT!");
retour (XP_ERROR);
}
/ * Vérifiez le type de données du paramètre passé * /
si (bType! \u003d SRVBIGVARCHAR && bType! \u003d SRVBIGCHAR)
{
printError (pSrvProc, "Mauvais type de paramètre passé!");
retour (XP_ERROR);
}
/ * Assurez-vous que le paramètre passé est suffisamment long pour stocker la chaîne retournée * /
si (cbMaxLen< strlen(szText))
{
printError (pSrvProc,
"Le paramètre passé n'est pas assez long pour stocker la chaîne retournée n!");
retour (XP_ERROR);
}
/ * Définit la valeur du paramètre OUTPUT * /
if (FAIL \u003d\u003d srv_paramsetoutput (pSrvProc, 1, (BYTE *) szText, 13, FALSE))
{
printError (pSrvProc,
"Je ne peux pas définir la valeur du paramètre OUTPUT ...");
retour (XP_ERROR);
}
srv_senddone (pSrvProc, (SRV_DONE_COUNT | SRV_DONE_MORE), 0, 1);
retour (XP_NOERROR);
}
void printError (SRV_PROC * pSrvProc, CHAR * szErrorMsg)
{
srv_sendmsg (pSrvProc, SRV_MSG_ERROR, XP_HELLO_ERROR, SRV_INFO, 1,
NULL, 0, 0, szErrorMsg, SRV_NULLTERM);
Srv_senddone (pSrvProc, (SRV_DONE_ERROR | SRV_DONE_MORE), 0, 0);
}
Les fonctions srv_sendmsg et srv_senddone n'ont pas été prises en compte. La fonction srv_sendmsg est utilisée pour envoyer des messages au client. Voici son prototype:
int srv_sendmsg (
SRV_PROC * srvproc,
int msgtype,
DBINT msgnum,
Classe DBTINYINT,
État DBTINYINT,
DBCHAR * rpcname,
int rpcnamelen,
DBUSMALLINT linum,
Message DBCHAR *,
int msglen
);
numéro de message msgnum;
classe - la gravité de l'erreur survenue. Les messages d'information ont une valeur de gravité inférieure ou égale à 10;
etat le numéro d'état d'erreur pour le message actuel. Ce paramètre fournit des informations sur le contexte de l'erreur qui s'est produite. Les valeurs valides sont comprises entre 0 et 127;
rpcname n'est actuellement pas utilisé;
rpcnamelen - actuellement non utilisé;
lin ici, vous pouvez spécifier le numéro de ligne du code source. Par cette valeur, plus tard, il sera facile d'établir où l'erreur s'est produite. Si vous ne souhaitez pas utiliser cette fonction, définissez la valeur de linum sur 0;
message est un pointeur vers la chaîne envoyée au client;
msglen définit la longueur en octets de la chaîne de message. Si cette chaîne est terminée par , la valeur de ce paramètre peut être définie sur SRV_NULLTERM.
Valeurs renvoyées:
- en cas de succès SUCCEED
- ÉCHEC en cas d'échec.
Dans le processus, la procédure stockée étendue doit régulièrement signaler son état à l'application cliente, c'est-à-dire envoyer des messages sur les actions effectuées. Voici à quoi sert la fonction srv_senddone:
int srv_senddone (
SRV_PROC * srvproc,
État DBUSMALLINT,
Informations sur DBUSMALLINT,
Compte DBINT
);
indicateur d'état de statut. La valeur de ce paramètre peut être définie à l'aide des opérateurs logiques ET et OU pour combiner les constantes indiquées dans le tableau:
Indicateur d'état Description
SRV_DONE_FINAL Le jeu de résultats actuel est final;
SRV_DONE_MORE Le jeu de résultats actuel n'est pas définitif, plus de données devraient être attendues;
SRV_DONE_COUNT Le paramètre count contient une valeur valide
SRV_DONE_ERROR Utilisé pour avertir lorsque des erreurs se produisent et se terminer immédiatement.
dans réservé, doit être réglé sur 0.
count est le nombre d'ensembles de données de résultats envoyés au client. Si l'indicateur d'état est défini sur SRV_DONE_COUNT, alors count doit contenir le nombre correct de jeux d'enregistrements envoyés au client.
Valeurs renvoyées:
- en cas de succès SUCCEED
- ÉCHEC en cas d'échec.
Installation de procédures stockées étendues sur MS SQL Server 2000
1.Copiez la bibliothèque de dll avec la procédure stockée étendue dans le répertoire binn sur la machine sur laquelle MS SQL Server est installé. Mon chemin est le suivant: C: Program FilesMicrosoft SQL ServerMSSQLBinn;
2. Enregistrez la procédure stockée étendue sur le serveur en exécutant le script suivant:
UTILISER Maître
EXÉCUTER SP_ADDEXTENDEDPROC xp_helloworld, xp_helloworld.dll
Testez le xp_helloworld en exécutant ce script:
DÉCLARER @Param varchar (33)
EXÉCUTER xp_helloworld @Param OUTPUT
SÉLECTIONNEZ @Param COMME OUTPUT_Param
Conclusion
Ceci conclut la première partie de mon article. Maintenant, je suis sûr que vous êtes prêt à faire face à notre mandat à 100%. Dans le prochain article, vous découvrirez:
- Types de données définis dans l'API ODS;
- Fonctionnalités de débogage des processus stockés étendus;
- Comment former des jeux d'enregistrements et les transférer vers l'application client;
- Nous examinerons de plus près les fonctions de l'API de gestion du réseau Active Directory requises pour obtenir une liste d'utilisateurs de domaine;
- Nous créerons un projet fini (nous mettrons en œuvre nos termes de référence)
J'espère vous revoir bientôt!
PS: exemples de fichiers à télécharger pour le studio 7.0
- Etudier les opérateurs décrivant les procédures stockées et les principes de transmission de leurs paramètres d'entrée et de sortie.
- Examinez la procédure de création et de débogage des procédures stockées sur MS SQL Server 2000.
- Concevoir cinq procédures stockées de base pour base de formation données "Bibliothèque".
- Préparez un rapport sur le travail effectué sous forme électronique.
1. Informations générales sur les procédures stockées
Procédure stockée Est un ensemble de commandes stockées sur le serveur et exécutées dans leur ensemble. Les procédures stockées sont un mécanisme par lequel vous pouvez créer des routines qui s'exécutent sur le serveur et sont contrôlées par ses processus. Ces routines peuvent être appelées par l'application appelante. Ils peuvent également être déclenchés par des règles d'intégrité des données ou des déclencheurs.
Les procédures stockées peuvent renvoyer des valeurs. Dans la procédure, vous pouvez comparer les valeurs saisies par l'utilisateur avec les informations prédéfinies dans le système. Les procédures stockées sont alimentées par de puissantes solutions matérielles SQL Server. Ils sont orientés base de données et travaillent en étroite collaboration avec SQL Server Optimizer. Cela vous permet d'obtenir grande productivité lors du traitement des données.
Vous pouvez transmettre des valeurs aux procédures stockées et en recevoir des résultats, et pas nécessairement liés à la feuille de calcul. La procédure stockée peut calculer les résultats à la volée.
Les procédures stockées sont de deux types: ordinaire et élargi... Les procédures stockées régulières sont un ensemble de commandes Transact-SQL, tandis que les procédures stockées étendues sont bibliothèques dynamiques (DLL). Ces procédures, contrairement aux procédures habituelles, ont le préfixe xp_. Le serveur dispose d'un ensemble standard de procédures étendues, mais les utilisateurs peuvent écrire leurs propres procédures dans n'importe quel langage de programmation. L'essentiel est d'utiliser l'interface de programmation SQL Serveur ouvert API Data Services... Les procédures stockées étendues ne peuvent être trouvées que dans la base de données principale.
Les procédures stockées régulières peuvent également être classées en deux types: systémique et douane... Les procédures système sont les procédures standard utilisées pour faire fonctionner le serveur; personnalisé - toutes les procédures créées par l'utilisateur.
1.1. Les avantages des procédures stockées
Dans le cas le plus général, les procédures stockées présentent les avantages suivants:
- Haute performance. C'est le résultat de l'emplacement des procédures stockées sur le serveur. Le serveur, en règle générale, est une machine plus puissante, donc le temps d'exécution de la procédure sur le serveur est beaucoup plus court que sur poste de travail... De plus, les informations de la base de données et la procédure stockée sont sur le même système, de sorte qu'il n'y a pratiquement pas de temps perdu à transférer des enregistrements sur le réseau. Les procédures stockées ont un accès direct aux bases de données, ce qui rend le travail avec les informations très rapide.
- L'avantage de la conception système dans une architecture client-serveur. Il consiste en la possibilité de création séparée du logiciel client et serveur. Cet avantage est essentiel au développement et peut réduire considérablement le temps nécessaire à la réalisation d'un projet. Le code qui s'exécute sur le serveur peut être développé séparément du code côté client. Dans ce cas, les composants côté serveur peuvent être partagés par les composants côté client.
- Niveau de sécurité. Les procédures stockées peuvent servir d'outil d'amélioration de la sécurité. Des procédures stockées peuvent être créées pour effectuer les opérations d'ajout, de modification, de suppression et d'affichage de listes, et ainsi prendre le contrôle de chaque aspect de l'accès aux informations.
- Renforcer les règles du serveur travaillant avec les données. C'est l'une des raisons les plus importantes pour l'utilisation du moteur de base de données intelligent. Les procédures stockées vous permettent d'appliquer des règles et d'autres logiques pour vous aider à contrôler les informations entrées dans le système.
Bien que SQL soit défini comme non procédural, SQL Server utilise des mots-clés liés au contrôle du flux de procédures. Ces mots-clés sont utilisés pour créer des procédures qui peuvent être enregistrées pour une exécution ultérieure. Les procédures stockées peuvent être utilisées à la place des programmes créés avec langues standard la programmation (comme C ou Visual Basic) et l'exécution d'opérations dans une base de données SQL Server.
Les procédures stockées sont compilées lors de la première exécution et stockées dans la table système de la base de données actuelle. Ils sont optimisés lors de leur compilation. Cela choisit la meilleure façon d'accéder aux informations de la table. Une telle optimisation prend en compte la position réelle des données dans la table, les index disponibles, la charge de la table, etc.
Les procédures stockées compilées peuvent améliorer considérablement les performances du système. Il est à noter, cependant, que les statistiques de données depuis le moment où une procédure est créée jusqu'à son exécution peuvent devenir obsolètes et les index peuvent devenir inefficaces. Bien qu'il soit possible de mettre à jour les statistiques et d'ajouter de nouveaux index plus efficaces, le plan d'exécution de la procédure a déjà été établi, c'est-à-dire que la procédure a été compilée et, par conséquent, la manière d'accéder aux données peut ne plus être efficace. Par conséquent, il est possible de recompiler les procédures à chaque appel.
D'autre part, la recompilation prendra du temps à chaque fois. Par conséquent, la question de l'efficacité de la recompilation d'une procédure ou de l'élaboration d'un plan pour son exécution à la fois est assez délicate et devrait être considérée séparément pour chaque cas particulier.
Les procédures stockées peuvent être exécutées sur l'ordinateur local ou sur un système SQL Server distant. Cela permet d'activer des processus sur d'autres machines et de travailler non seulement avec des bases de données locales, mais également avec des informations sur plusieurs serveurs.
Les programmes d'application écrits dans l'un des langages de haut niveau tels que C ou Visual Basic .NET peuvent également appeler des procédures stockées, ce qui fournit solution optimale sur l'équilibrage de charge entre le logiciel côté client et le serveur SQL.
1.2. Création de procédures stockées
L'instruction Create Procedure est utilisée pour créer une procédure stockée. Le nom de la procédure stockée peut comporter jusqu'à 128 caractères, y compris les caractères # et ##. Syntaxe de la définition de procédure:
CREATE PROC nom_sp [; nombre]
[(@ paramètre datatype) [\u003d valeur_par défaut]] [, ... n]
COMME
<Инструкции_SQL>
Considérez les paramètres de cette commande:
- Nom_procédure - nom de la procédure; doit respecter les règles relatives aux identifiants: sa longueur ne peut excéder 128 caractères; pour les procédures temporaires locales, # est utilisé devant le nom, et pour les procédures temporaires globales, ##;
- Number est un entier facultatif utilisé pour regrouper plusieurs procédures sous le même nom;
- @ paramètre data_type - une liste de noms de paramètres de procédure avec une indication du type de données correspondant pour chacun; il peut y avoir jusqu'à 2100 paramètres de ce type. NULL est autorisé comme valeur de paramètre. Tous les types de données peuvent être utilisés sauf texte, ntext et image. Le type de données Cursor peut être utilisé comme paramètre de sortie (mot-clé OUTPUT ou VARYING). Les paramètres avec le type de données Cursor ne peuvent être que des paramètres de sortie;
- VARYING est un mot clé spécifiant qu'un jeu de résultats est utilisé comme paramètre de sortie (utilisé uniquement pour le type Cursor);
- OUTPUT - indique que le paramètre spécifié peut être utilisé comme sortie;
- valeur par défaut - est utilisé lorsque le paramètre est omis lors de l'appel de la procédure; doit être constant et peut inclure des caractères de masque (%, _, [,], ^) et NULL;
- WITH RECOMPILE - mots-clés indiquant que SQL Server n'écrira pas le plan de procédure dans le cache, mais en créera un à chaque exécution;
- WITH ENCRYPTION sont des mots clés indiquant que SQL Server chiffrera la procédure avant d'écrire dans la table système Syscomments. Pour que le texte des procédures cryptées soit impossible à récupérer, il est nécessaire de supprimer les tuples correspondants de la table syscomments après le cryptage;
- POUR RÉPLICATION - mots clés indiquant que cette procédure est créée pour la réplication uniquement. Cette option est incompatible avec les mots clés WITH RECOMPILE;
- AS - le début de la définition du texte de la procédure;
- <Инструкции_SQL> - l'ensemble des instructions SQL valides, limité uniquement par la taille maximale de la procédure stockée - 128 Ko. Les instructions suivantes ne sont pas valides: ALTER DATABASE, ALTER PROCEDURE, ALTER TABLE, CREATE DEFAULT, CREATE PROCEDURE, ALTER TRIGGER, ALTER VIEW, CREATE DATABASE, CREATE RULE, CREATE SCHEMA, CREATE TRIGGER, CREITATE, VIEW, DISPASE INPUT, DROP DEFAULT, DROP PROCEDURE, DROP RULE, DROP TRIGGER, DROP VIEW, RESOTRE DATABASE, RESTAURER LE JOURNAL, RECONFIGURER, METTRE À JOUR LES STATISTIQUES.
Regardons un exemple de procédure stockée. Développons une procédure stockée qui compte et affiche le nombre de copies de livres actuellement dans la bibliothèque:
CREATE Procédure Count_Ex1
- la procédure de comptage du nombre d'exemplaires de livres,
- actuellement dans la bibliothèque,
- pas entre les mains des lecteurs
Comme
- définir une variable locale temporaire
Déclarer @N int
Sélectionnez @N \u003d count (*) à partir de l'exemple où Yes_No \u003d "1"
Sélectionnez @N
ALLER
Étant donné que la procédure stockée est un composant à part entière de la base de données, vous pouvez, comme vous l'avez déjà compris, créer une nouvelle procédure uniquement pour la base de données actuelle. Lorsque vous travaillez dans l'Analyseur de requêtes SQL Server, la définition de la base de données actuelle est effectuée avec une instruction Use suivie du nom de la base de données dans laquelle la procédure stockée doit être créée. Vous pouvez également sélectionner la base de données actuelle à l'aide de la liste déroulante.
Après avoir créé un procédures SQL Le serveur le compile et vérifie les routines exécutables. En cas de problème, la procédure est rejetée. Les erreurs doivent être corrigées avant la rediffusion.
SQL Server 2000 utilise la résolution de noms différée, donc si une procédure stockée contient un appel à une autre procédure non encore implémentée, un avertissement est émis, mais l'appel à la procédure inexistante est conservé.
Si vous laissez un appel à une procédure stockée non identifiée sur le système, l'utilisateur recevra un message d'erreur lorsqu'il tentera de l'exécuter.
Vous pouvez également créer une procédure stockée à l'aide de SQL Server Enterprise Manager:
Afin de vérifier la fonctionnalité de la procédure stockée créée, vous devez accéder à l'Analyseur de requêtes et démarrer la procédure d'exécution par l'opérateur EXEC<имя процедуры> ... Les résultats de l'exécution de la procédure créée sont indiqués sur la Fig. 4.

Figure: 4. Exécution de la procédure stockée dans l'Analyseur de requêtes

Figure: 5. Le résultat de l'exécution de la procédure sans opérateur d'affichage
1.3. Paramètres de procédure stockés
Les procédures stockées sont très puissantes, mais vous ne pouvez obtenir une efficacité maximale qu'en les rendant dynamiques. Le développeur doit pouvoir transmettre des valeurs à la procédure stockée avec laquelle elle fonctionnera, c'est-à-dire des paramètres. Voici les principes de base de l'utilisation des paramètres dans les procédures stockées.
- Un ou plusieurs paramètres peuvent être définis pour une procédure.
- Les paramètres sont utilisés comme emplacements de stockage nommés, tout comme les variables dans les langages de programmation tels que C, Visual Basic .NET.
- Le nom du paramètre doit être précédé du symbole @.
- Les noms de paramètres sont locaux par rapport à la procédure dans laquelle ils sont définis.
- Les paramètres sont utilisés pour transmettre des informations à une procédure lors de son exécution. Ils seront obsédés par ligne de commande après le nom de la procédure.
- Si la procédure comporte plusieurs paramètres, ils sont séparés par des virgules.
- Les types de données système ou définis par l'utilisateur sont utilisés pour déterminer le type d'informations transmises en tant que paramètre.
Vous trouverez ci-dessous la définition d'une procédure qui a un paramètre d'entrée. Modifions la tâche précédente et nous ne compterons pas toutes les copies de livres, mais uniquement les copies d'un certain livre. Nos livres sont identifiés de manière unique par leur ISBN unique, nous allons donc transmettre ce paramètre à la procédure. Dans ce cas, le texte de la procédure stockée changera et ressemblera à ceci:
Créer une procédure Count_Ex (@ISBN varchar (14))
Comme
Déclarer @N int
Sélectionnez @N
ALLER
Au démarrage de cette procédure d'exécution, il faut lui passer la valeur du paramètre d'entrée (Fig. 6).

Figure: 6. Procédure de démarrage avec passage de paramètres
Pour créer plusieurs versions de la même procédure avec le même nom, ajoutez un point-virgule et un entier après le nom de base. La procédure à suivre est illustrée dans l'exemple suivant, qui décrit comment créer deux procédures portant le même nom mais des numéros de version différents (1 et 2). Le numéro est utilisé pour contrôler la version en cours de cette procédure. Si aucun numéro de version n'est spécifié, la première version de la procédure est exécutée. Cette option n'apparaît pas dans l'exemple précédent, mais est néanmoins disponible pour votre application.
Les deux procédures utilisent l'instruction d'impression pour afficher un message identifiant la version. La première version compte le nombre d'exemplaires gratuits, et la seconde - le nombre d'exemplaires disponibles pour un livre donné.
Le texte des deux versions des procédures est donné ci-dessous:
CREATE Procédure Count_Ex_all; 1
(@ISBN varchar (14))
- la procédure de décompte des exemplaires gratuits d'un livre donné
Comme
Déclarer @N int
Sélectionnez @N \u003d count (*) à partir de l'exemple type où ISBN \u003d @ISBN et Yes_No \u003d "1"
Sélectionnez @N
--
ALLER
--
CREATE Procédure Count_Ex_all; 2
(@ISBN varchar (14))
- la procédure de décompte des exemplaires gratuits d'un livre donné
Comme
Déclarer @ N1 int
Sélectionnez @ N1 \u003d count (*) à partir de l'exemple type où ISBN \u003d @ISBN et Yes_No \u003d "0"
Sélectionnez @ N1
ALLER
Les résultats de l'exécution de la procédure avec différentes versions sont illustrés à la Fig. 7.

Figure: 7. Résultats du lancement différentes versions la même procédure stockée
Lors de l'écriture de plusieurs versions, n'oubliez pas les restrictions suivantes: puisque toutes les versions d'une procédure sont compilées ensemble, toutes les variables locales sont considérées comme partagées. Par conséquent, si cela est requis par l'algorithme de traitement, il est nécessaire d'utiliser différents noms de variables internes, ce que nous avons fait en nommant la variable @N avec le nom @ N1 dans la deuxième procédure.
Les procédures que nous avons écrites ne renvoient aucun paramètre, elles affichent simplement le nombre résultant. Cependant, le plus souvent, nous devons obtenir un paramètre pour un traitement ultérieur. Il existe plusieurs façons de renvoyer des paramètres à partir d'une procédure stockée. Le plus simple est d'utiliser l'opérateur RETURN. Cet opérateur renverra une seule valeur numérique. Mais nous devons spécifier un nom de variable ou une expression qui est assignée au paramètre retourné. Voici les valeurs réservées au système renvoyées par l'opérateur RETURN:
| Code | Valeur |
| 0 | C'est bon |
| -1 | Objet non trouvé |
| –2 | Erreur de type de données |
| –3 | Le processus est devenu une "impasse" |
| –4 | erreur d'accès |
| –5 | Erreur de syntaxe |
| –6 | Quelques erreurs |
| -7 | Erreur de ressource (pas d'espace) |
| –8 | Une erreur interne récupérable s'est produite |
| –9 | Limite système atteinte |
| -dix | Violation fatale de l'intégrité interne |
| –11 | Même |
| –12 | Détruire une table ou un index |
| –13 | Destruction de la base de données |
| –14 | Erreur matérielle |
Ainsi, pour ne pas contredire le système, nous ne pouvons renvoyer que des entiers positifs via ce paramètre.
Par exemple, nous pouvons modifier le texte de la procédure stockée précédemment écrite Count_ex comme suit:
Créer une procédure Count_Ex2 (@ISBN varchar (14))
Comme
Déclarer @N int
Sélectionnez @N \u003d count (*) dans Exemplar
Où ISBN \u003d @ISBN et YES_NO \u003d "1"
- retourne la valeur de la variable @N,
- si la valeur de la variable n'est pas définie, renvoie 0
Retour Coalesce (@N, 0)
ALLER
Nous pouvons maintenant obtenir la valeur de @N et l'utiliser pour un traitement ultérieur. Dans ce cas, la valeur de retour est affectée à la procédure stockée elle-même et pour l'analyser, vous pouvez utiliser le format suivant de l'instruction d'appel de procédure stockée:
Exec<переменная> = <имя_процедуры> <значение_входных_параметров>
Un exemple d'appel de notre procédure est illustré à la Fig. 8.

Figure: 8. Transmission de la valeur de retour de la procédure stockée à une variable locale
Les paramètres d'entrée des procédures stockées peuvent utiliser la valeur par défaut. Cette valeur sera utilisée si la valeur du paramètre n'a pas été spécifiée lors de l'appel de la procédure.
La valeur par défaut est spécifiée avec un signe égal après la description du paramètre d'entrée et son type. Considérez une procédure stockée qui compte le nombre d'exemplaires de livres d'une année d'émission donnée. L'année par défaut est 2006.
CRÉER UNE PROCÉDURE ex_books_now (@year int \u003d 2006)
- compter le nombre d'exemplaires de livres d'une année de parution donnée
COMME
Déclarer @N_books int
sélectionnez @N_books \u003d count (*) à partir de livres, exemplaire
où Books.ISBN \u003d exemplar.ISBN et YEARIZD \u003d @year
retourner coalesce (@N_books, 0)
ALLER
En figue. 9 montre un exemple d'appel de cette procédure avec et sans paramètre d'entrée.

Figure: 9. Appel d'une procédure stockée avec et sans paramètre
Tous les exemples d'utilisation de paramètres dans les procédures stockées décrits ci-dessus ne fournissent que des paramètres d'entrée. Cependant, les paramètres peuvent être émis. Cela signifie que la valeur du paramètre après la fin de la procédure sera transmise à celui qui a appelé cette procédure (autre procédure, déclencheur, lot de commandes, etc.). Naturellement, pour obtenir un paramètre de sortie, lors de l'appel, vous devez spécifier non pas une constante, mais une variable comme paramètre réel.
Notez que la définition d'un paramètre comme sortie dans une procédure ne vous oblige pas à l'utiliser comme tel. Autrement dit, si vous spécifiez une constante en tant que paramètre réel, aucune erreur ne se produira et elle sera utilisée comme paramètre d'entrée normal.
L'instruction OUTPUT est utilisée pour indiquer que le paramètre est un paramètre de sortie. Ce mot-clé est écrit après la description du paramètre. Lors de la description des paramètres des procédures stockées, il est souhaitable de spécifier les valeurs des paramètres de sortie après celles d'entrée.
Prenons un exemple d'utilisation des paramètres de sortie. Écrivons une procédure stockée qui, pour un livre donné, calcule le nombre total de ses copies dans la bibliothèque et le nombre de copies gratuites. Nous ne pourrons pas utiliser l'opérateur RETURN ici, car il ne renvoie qu'une seule valeur, nous devons donc définir les paramètres de sortie ici. Le texte de la procédure stockée peut ressembler à ceci:
CREATE Procédure Count_books_all
(@ISBN varchar (14), @all int sortie, @free int sortie)
- la procédure de calcul du nombre total d'exemplaires d'un livre donné
- et le nombre d'exemplaires gratuits
Comme
- compter le nombre total de copies
Sélectionnez @all \u003d count (*) à partir de l'exemple type où ISBN \u003d @ISBN
Sélectionnez @free \u003d count (*) à partir de l'exemple type où ISBN \u003d @ISBN et Yes_No \u003d "1"
ALLER
Un exemple de cette procédure est illustré à la Fig. Dix.

Figure: 10. Test d'une procédure stockée avec des paramètres de sortie
Comme mentionné précédemment, afin d'obtenir les valeurs des paramètres de sortie pour l'analyse, nous devons les définir avec des variables, et ces variables doivent être décrites par l'instruction Declare. La dernière instruction de sortie nous a permis d'afficher simplement les valeurs résultantes.
Les paramètres de la procédure peuvent même être des variables de type Cursor. Pour cela, la variable doit être décrite comme un type de données spécial VARYING, sans liaison avec les types de données système standard. De plus, il faut préciser qu'il s'agit d'une variable Cursor.
Écrivons une procédure simple qui répertorie les livres de notre bibliothèque. Dans ce cas, s'il n'y a pas plus de trois livres, alors nous affichons leurs noms dans le cadre de la procédure elle-même, et si la liste des livres dépasse un nombre spécifié, nous les transférons sous la forme d'un curseur vers le programme ou module appelant.
Le texte de la procédure ressemble à ceci:
CRÉER UNE PROCÉDURE GET3TITLES
(SORTIE VARIABLE DU CURSEUR @MYCURSOR)
- procédure d'impression des titres de livres avec curseur
COMME
- définir une variable locale de type Cursor dans la procédure
SET @MYCURSOR \u003d CURSEUR
POUR CHOISIR UN TITRE DISTINCT
À PARTIR DE LIVRES
- ouvrir le curseur
OUVRIR @MYCURSEUR
- nous décrivons les variables locales internes
DÉCLARER @TITLE VARCHAR (80), @CNT INT
--- définir l'état initial du compteur de livres
SET @CNT \u003d 0
- aller à la première ligne du curseur
- tant qu'il y a des lignes de curseur,
- c'est-à-dire, tandis que la transition vers nouvelle ligne correct
WHILE (@@ FETCH_STATUS \u003d 0) ET (@CNT<= 2) BEGIN
IMPRIMER @TITLE
RECHERCHE SUIVANT DE @MYCURSOR DANS @TITLE
- changer l'état du compteur de livres
SET @CNT \u003d @CNT + 1
FIN
IF @CNT \u003d 0 IMPRIMER "AUCUN LIVRE ADAPTÉ"
ALLER
Un exemple d'appel de cette procédure stockée est illustré à la Fig. Onze.

Dans la procédure d'appel, le curseur doit être déclaré en tant que variable locale. Ensuite, nous avons appelé notre procédure et lui avons passé le nom d'une variable locale de type Cursor. La procédure a commencé à fonctionner et nous a affiché les trois premiers noms, puis a passé le contrôle à la procédure appelante, et cette procédure a continué à traiter le curseur. Pour ce faire, elle a organisé une boucle While sur la variable globale @@ FETCH_STATUS, qui suit l'état du curseur, puis a vidé toutes les autres lignes du curseur dans la boucle.
Dans la fenêtre de sortie, nous voyons un espacement accru entre les trois premières lignes et les titres suivants. Cet intervalle montre simplement que le contrôle a été transféré à un programme externe.
Notez que la variable @TITLE, étant locale à la procédure, sera détruite lorsqu'elle sera terminée, elle est donc à nouveau déclarée dans le bloc appelant. La création et l'ouverture du curseur dans cet exemple se produisent dans une procédure, tandis que la fermeture, la destruction et le traitement supplémentaire sont effectués dans le bloc de commandes dans lequel la procédure est appelée.
Le moyen le plus simple d'afficher le texte de la procédure, de le modifier ou de le supprimer à l'aide de l'interface graphique d'Enterprise Manager. Cependant, vous pouvez également le faire à l'aide de procédures stockées système Transact-SQL spéciales. Dans Transact-SQL, une définition de procédure est affichée à l'aide de la procédure système sp_helptext et la procédure système sp_help affiche des informations de contrôle sur la procédure. Les procédures système sp_helptext et sp_help sont également utilisées pour afficher des objets de base de données tels que des tables, des règles et des paramètres par défaut.
Les informations sur toutes les versions d'une procédure, quel que soit le nombre, s'affichent immédiatement. La suppression de différentes versions de la même procédure stockée se produit également en même temps. L'exemple suivant montre comment les définitions des versions 1 et 2 de Count_Ex_all sont affichées lorsque son nom est spécifié en tant que paramètre de la procédure système sp_helptext (Figure 12).

Figure: 12. Affichage du corps d'une procédure stockée à l'aide d'une procédure stockée système
La procédure système SP_HELP affiche les caractéristiques et les paramètres de la procédure créée sous la forme suivante:
|
Created_datetime | |||||
|
2006-12-06 23:15:01.217 | |||||
|
Échelle | Classement Param_order | ||||
|
NUL | 1 | Cyrillic_General_CI_AS | |||
|
0 | 2 | NUL | |||
|
0 | 3 | NUL | |||
Essayez de décoder ces paramètres vous-même. De quoi parlent-ils?
1.4. Compiler une procédure stockée
L'avantage d'utiliser des procédures stockées pour exécuter un ensemble d'instructions Transact-SQL est qu'elles sont compilées la première fois qu'elles sont exécutées. Lors de la compilation, les instructions Transact-SQL sont converties de leur représentation symbolique d'origine en forme exécutable. Tous les objets auxquels on accède dans la procédure sont également convertis en une autre représentation. Par exemple, les noms de table sont convertis en ID d'objet et les noms de colonne sont convertis en ID de colonne.
Un plan d'exécution est créé de la même manière que pour l'exécution d'une seule instruction Transact-SQL. Ce plan contient, par exemple, des index utilisés pour lire les lignes des tables auxquelles la procédure accède. Le plan d'exécution de la procédure est stocké dans le cache et utilisé à chaque appel.
Remarque: Le cache de procédures peut être dimensionné de manière à contenir la plupart ou la totalité des procédures disponibles. Cela permet de gagner du temps pour régénérer le plan de traitement.
1.5. Recompilation automatique
En général, le plan d'exécution se trouve dans le cache de procédures. Cela vous permet d'augmenter les performances lors de son exécution. Cependant, dans certaines circonstances, la procédure se recompilera automatiquement.
- La procédure est toujours recompilée au démarrage de SQL Server. Cela se produit généralement après un redémarrage du système d'exploitation et la première fois que la procédure est exécutée après la création.
- Le plan d'exécution d'une procédure est toujours automatiquement recompilé si l'index de table auquel la procédure accède est supprimé. Étant donné que le plan actuel accède à un index qui n'existe plus pour lire les lignes de la table, un nouveau plan d'exécution doit être créé. Les requêtes de procédure ne s'exécuteront que si elles sont mises à jour.
- Le plan d'exécution est également compilé si un autre utilisateur travaille actuellement avec le plan dans le cache. Une copie individuelle du plan d'exécution est créée pour le deuxième utilisateur. Si la première copie du plan n'était pas occupée, il ne serait pas nécessaire d'en créer une seconde. Lorsque l'utilisateur termine l'exécution de la procédure, le plan d'exécution est disponible dans le cache pour un autre utilisateur disposant de l'autorisation d'accès appropriée.
- La procédure est automatiquement recompilée si elle est supprimée et recréée. Comme la nouvelle procédure peut différer de l'ancienne version, toutes les copies du plan d'exécution dans le cache sont supprimées et le plan est à nouveau compilé.
SQL Server s'efforce d'optimiser les procédures stockées en mettant en cache les procédures les plus utilisées. Par conséquent, l'ancien plan d'exécution chargé dans le cache peut être utilisé à la place du nouveau plan. Pour éviter ce problème, vous devez supprimer et recréer la procédure stockée ou arrêter et réactiver SQL Server. Cela effacera le cache de procédure et éliminera la possibilité de travailler avec l'ancien plan d'exécution.
La procédure peut également être créée avec l'option WITH RECOMPILE. Dans ce cas, il se recompilera automatiquement à chaque exécution. L'option WITH RECOMPILE doit être utilisée lorsque la procédure accède à des tables très dynamiques dont les lignes sont fréquemment ajoutées, supprimées ou mises à jour, car cela entraîne des modifications significatives des index définis pour les tables.
Si les procédures ne sont pas automatiquement recompilées, elles peuvent être forcées. Par exemple, si les statistiques utilisées pour déterminer si un index peut être utilisé dans une requête donnée ont été mises à jour, ou si un nouvel index a été créé, une recompilation forcée doit être effectuée. Pour forcer la recompilation, l'instruction EXECUTE utilise la clause WITH RECOMPILE:
EXECUTE nom_procédure;
COMME
<инструкции Transact-SQL>
AVEC RECOMPILE
Si la procédure fonctionne avec des paramètres qui contrôlent l'ordre de son exécution, utilisez l'option WITH RECOMPILE. Si les paramètres d'une procédure stockée peuvent déterminer la meilleure façon de l'exécuter, il est recommandé de générer un plan d'exécution à la volée, plutôt que d'en créer un la première fois que la procédure est appelée pour une utilisation sur tous les appels suivants.
Remarque: il est parfois difficile de déterminer s'il faut utiliser l'option WITH RECOMPILE lors de la création d'une procédure ou non. En cas de doute, il est préférable de ne pas utiliser cette option, car la recompilation de la procédure à chaque exécution fera perdre un temps CPU très précieux. Si, à l'avenir, vous devez recompiler lors de l'exécution de la procédure stockée, vous pouvez le faire en ajoutant la clause WITH RECOMPILE à l'instruction EXECUTE.
Vous ne pouvez pas utiliser l'option WITH RECOMPILE dans une instruction CREATE PROCEDURE contenant une option FOR REPLICATION. Cette option est utilisée pour créer une procédure qui est exécutée pendant le processus de réplication.
1.6. Imbrication de procédures stockées
Les procédures stockées peuvent appeler d'autres procédures stockées, mais il existe une limite au niveau d'imbrication. Le niveau d'imbrication maximal est de 32. Le niveau d'imbrication actuel peut être déterminé à l'aide de la variable globale @@ NESTLEVEL.
2. Fonctions définies par l'utilisateur (UDF)
MS SQL SERVER 2000 possède de nombreuses fonctions prédéfinies qui vous permettent d'effectuer diverses actions. Cependant, il peut toujours être nécessaire d'utiliser certaines fonctions spécifiques. Pour cela, à partir de la version 8.0 (2000), il est devenu possible de décrire les fonctions définies par l'utilisateur (UDF) et de les stocker comme un objet de base de données à part entière, avec des procédures stockées, des vues, etc.
L'utilisabilité des fonctions définies par l'utilisateur est évidente. Contrairement aux procédures stockées, les fonctions peuvent être intégrées directement dans une instruction SELECT et peuvent être utilisées à la fois pour récupérer des valeurs spécifiques (dans la clause SELECT) et en tant que source de données (dans la clause FROM).
Lorsque vous utilisez des UDF comme sources de données, leur avantage par rapport aux vues est que les UDF, contrairement aux vues, peuvent avoir des paramètres d'entrée avec lesquels vous pouvez influencer le résultat de la fonction.
Les fonctions définies par l'utilisateur peuvent être de trois types: fonctions scalaires, fonctions en ligne et fonctions multi-instructions renvoyant un résultat de table... Considérons tous ces types de fonctions plus en détail.
2.1. Fonctions scalaires
Les fonctions scalaires renvoient un seul résultat scalaire. Ce résultat peut être l'un des types décrits ci-dessus, à l'exception des types text, ntext, image et timestamp. C'est le type de fonction le plus simple. Sa syntaxe est la suivante:
RETURNS scalar_data_type
COMMENCER
corps_fonction
RETURN expression_ scalaire
FIN
- Le paramètre ENCRYPTION a déjà été décrit dans la section sur les procédures stockées;
- SCHEMABINDING - lie une fonction à un schéma. Cela signifie que vous ne pouvez pas supprimer les tables ou les vues sur lesquelles la fonction est basée sans supprimer ou modifier la fonction elle-même. Il est également impossible de changer la structure de ces tables si la partie mutable est utilisée par une fonction. Ainsi, cette option vous permet d'exclure des situations où la fonction utilise des tables ou des vues et que quelqu'un, à son insu, les a supprimées ou modifiées;
- RETURNS scalar_data_type - décrit le type de données renvoyé par la fonction;
- expression_calaire - une expression qui renvoie directement le résultat d'une fonction. Il doit être du même type que celui décrit après RETURNS;
- function_body est un ensemble d'instructions Transact-SQL.
Regardons des exemples d'utilisation de fonctions scalaires.
Créez une fonction qui choisit le plus petit des deux entiers donnés comme paramètres.
Laissez la fonction ressembler à ceci:
CREATE FUNCTION min_num (@a INT, @b INT)
RETOURS INT
COMMENCER
DÉCLARER @c INT
Si un< @b SET @c = @a
ELSE SET @c \u003d @b
RETOUR @c
FIN
Maintenant, exécutons cette fonction:
SELECT dbo.min_num (4, 7)
En conséquence, nous obtenons la valeur 4.
Vous pouvez utiliser cette fonction pour trouver la plus petite valeur parmi les colonnes du tableau:
SELECT min_lvl, max_lvl, min_num (min_lvl, max_lvl)
DE Emplois
Créons une fonction qui recevra un paramètre de type datetime en entrée et retournera la date et l'heure correspondant au début du jour spécifié. Par exemple, si le paramètre d'entrée est 09.20.03 13:31, le résultat sera 09.20.03 00:00.
CRÉER UNE FONCTION dbo.daybegin (@dat DATETIME)
RETURNS smalldatetime AS
COMMENCER
RETURN CONVERT (datetime, FLOOR (convert (FLOAT, @dat)))
FIN
Ici, la fonction CONVERT effectue la conversion de type. Tout d'abord, le type date-heure est converti en type FLOAT. Avec cette réduction, la partie entière est le nombre de jours, à compter du 1er janvier 1900, et la partie fractionnaire est le temps. Ensuite, l'arrondi au plus petit entier a lieu à l'aide de la fonction FLOOR et la conversion en type date-heure.
Vérifions l'action de la fonction:
SELECT dbo.daybegin (GETDATE ())
Ici, GETDATE () est une fonction qui renvoie la date et l'heure actuelles.
Les fonctions précédentes utilisaient uniquement des paramètres d'entrée dans le calcul. Cependant, vous pouvez également utiliser les données stockées dans la base de données.
Créons une fonction qui prendra deux dates comme paramètres: le début et la fin d'un intervalle de temps - et calculons le chiffre d'affaires total pour cet intervalle. La date de vente et la quantité seront tirées du tableau Ventes, et les prix des titres vendus dans le tableau Titres.
CRÉER UNE FONCTION dbo.SumSales (@datebegin DATETIME, @dateend DATETIME)
RETOUR D'ARGENT
COMME
COMMENCER
DÉCLARER @Sum Money
SELECT @Sum \u003d somme (t.price * s.qty)
RETOUR @Sum
FIN
2.2. Fonctions en ligne
Ce type de fonction renvoie non pas une valeur scalaire, mais une table, ou plutôt un ensemble de données. Cela peut être très pratique dans les cas où le même type de sous-requête est souvent exécuté dans différentes procédures, déclencheurs, etc. Ensuite, au lieu d'écrire cette requête partout, vous pouvez créer une fonction et l'utiliser à l'avenir.
Les fonctions de ce type sont encore plus utiles dans les cas où vous souhaitez que la table retournée dépende des paramètres d'entrée. Comme vous le savez, les vues ne peuvent pas avoir de paramètres, donc seules les fonctions en ligne peuvent résoudre ce genre de problème.
La particularité des fonctions inline est qu'elles ne peuvent contenir qu'une seule requête dans leur corps. Ainsi, les fonctions de ce type sont très similaires aux vues, mais peuvent en plus avoir des paramètres d'entrée. Syntaxe de la fonction en ligne:
CREATE FUNCTION [propriétaire.] Nom_fonction
([(@ parameter_name scalar_data_type [\u003d default_value]) [, ... n]])
TABLE DES RETOURS
REVENIR [(<запрос>)]
La définition de la fonction indique qu'elle renverra une table;<запрос> - c'est la requête dont le résultat sera le résultat de la fonction.
Écrivons une fonction similaire à la fonction scalaire du dernier exemple, mais retournant non seulement le résultat de la somme, mais également les lignes de vente, y compris la date de vente, le titre du livre, le prix, le nombre de pièces et le montant des ventes. Seules les ventes comprises dans la période spécifiée doivent être sélectionnées. Crypterons le texte de la fonction afin que d'autres utilisateurs puissent l'utiliser, mais ne puissent pas le lire et le corriger:
CREATE FUNCTION Sales_Period (@datebegin DATETIME, @dateend DATETIME)
TABLE DES RETOURS
AVEC CHIFFREMENT
COMME
REVENIR (
SELECT t.title, t.price, s.qty, ord_date, t.price * s.qty comme stoim
FROM Titles t REJOINDRE Sales s ON t.title_Id \u003d s.Title_ID
WHERE ord_date BETWEEN @datebegin et @dateend
)
Appelons maintenant cette fonction. Comme déjà mentionné, il ne peut être appelé que dans la clause FROM de l'instruction SELECT:
SELECT * FROM Sales_Period ("01.09.94", "13.09.94")
2.3. Fonctions multi-instructions renvoyant un résultat de table
Le premier type de fonction considéré vous a permis d'utiliser autant d'instructions Transact-SQL que vous le souhaitez, mais n'a renvoyé qu'un résultat scalaire. Le deuxième type de fonction peut renvoyer des tables, mais son corps ne représente qu'une seule requête. Les fonctions multi-opérateurs renvoyant un résultat de table vous permettent de combiner les propriétés des deux premières fonctions, c'est-à-dire qu'elles peuvent contenir de nombreuses instructions Transact-SQL dans le corps et renvoyer une table comme résultat. Syntaxe de la fonction multi-opérateur:
CREATE FUNCTION [propriétaire.] Nom_fonction
([(@ parameter_name scalar_data_type [\u003d default_value]) [, ... n]])
RETURNS @ result_variable_name TABLE
<описание_таблицы>
COMMENCER
<тело_функции>
REVENIR
FIN
- TABLE<описание_таблицы> - décrit la structure de la table retournée;
- <описание_таблицы> - contient une énumération de colonnes et de contraintes.
Regardons maintenant un exemple qui ne peut être exécuté qu'avec des fonctions de ce type.
Laissez-y un arbre de répertoires et de fichiers. Que toute cette structure soit décrite dans la base de données sous forme de tableaux (Fig. 13). En fait, nous avons ici une structure hiérarchique pour les répertoires, donc le diagramme montre la relation de la table Folders avec elle-même.

Figure: 13. Structure de la base de données pour décrire la hiérarchie des fichiers et des répertoires
Nous allons maintenant écrire une fonction qui prendra un identifiant de répertoire comme entrée et sortira tous les fichiers qui y sont stockés et dans tous les répertoires de la hiérarchie. Par exemple, si les catalogues Faculty1, Faculty2, etc. sont créés dans le catalogue de l'Institut, ils ont des catalogues de département, et chacun des catalogues contient des fichiers, puis lors de la spécification de l'identifiant du catalogue de l'Institut comme paramètre de notre fonction, une liste de tous les fichiers pour tous ces répertoires. Le nom, la taille et la date de création doivent être affichés pour chaque fichier.
Vous ne pouvez pas résoudre le problème à l'aide de la fonction en ligne, car SQL n'est pas conçu pour exécuter des requêtes hiérarchiques, une requête SQL ne peut donc pas être effectuée ici. La fonction scalaire ne peut pas non plus être appliquée, car le résultat doit être une table. Ici, une fonction multi-opérateurs qui retourne une table viendra à notre aide:
CRÉER UNE FONCTION dbo.GetFiles (@Folder_ID int)
RETURNS @files TABLE (Nom VARCHAR (100), Date_Create DATETIME, FileSize INT) AS
COMMENCER
DECLARE @tmp TABLE (Folder_Id int)
DÉCLARER @Cnt INT
INSERT INTO @tmp valeurs (@Folder_ID)
SET @Cnt \u003d 1
TANT QUE @Cnt<> 0 COMMENCER
INSÉRER DANS @tmp SELECT Folder_Id
FROM Dossiers f JOIN @tmp t ON f.parent \u003d t.Folder_ID
WHERE F.id NOT IN (SELECT Folder_ID FROM @tmp)
SET @Cnt \u003d @@ ROWCOUNT
FIN
INSERT INTO @Files (Nom, Date_Create, FileSize)
SELECT F.Name, F.Date_Create, F.FileSize
FROM Fichiers f JOIN Folders Fl on f.Folder_id \u003d Fl.id
JOIN @tmp t sur Fl.id \u003d t.Folder_Id
REVENIR
FIN
Ici, dans la boucle, tous les sous-répertoires à tous les niveaux d'imbrication sont ajoutés à la variable @tmp jusqu'à ce qu'il ne reste plus de sous-répertoires. Ensuite, la variable de résultat @Files stocke tous les attributs de fichier requis dans les répertoires répertoriés dans la variable @tmp.
Travaux d'auto-apprentissage
Vous devez créer et déboguer cinq procédures stockées à partir de la liste requise suivante:
Procédure 1. Augmentez la date d'échéance des copies d'un livre d'une semaine si la date d'échéance actuelle se situe entre trois jours avant la date actuelle et trois jours après la date actuelle.
Procédure 2. Compter le nombre d'exemplaires gratuits d'un livre donné.
Procédure 3. Vérification de l'existence d'un lecteur avec le nom et la date de naissance donnés.
Procédure 4. Saisie d'un nouveau lecteur, vérification de son existence dans la base de données et détermination de son nouveau numéro de carte de bibliothèque.
Procédure 5. Calcul de l'amende en termes monétaires pour les lecteurs débiteurs.
Brève description des procédures
Procédure 1. Augmentation de la date d'échéance des livres
Pour chaque enregistrement de la table des exemplaires, il est vérifié si la date d'échéance du livre se situe dans l'intervalle de temps spécifié. Si tel est le cas, la date de retour du livre est augmentée d'une semaine. Lors de l'exécution de la procédure, vous devez utiliser la fonction pour travailler avec des dates:
DateAdd (jour,<число добавляемых дней>, <начальная дата>)
Procédure 2. Compter le nombre d'exemplaires gratuits d'un livre donné
Le paramètre d'entrée de la procédure est ISBN - un chiffre de livre unique. La procédure renvoie 0 (zéro) si toutes les copies de ce livre sont entre les mains des lecteurs. La procédure renvoie la valeur N, égale au nombre de copies du livre actuellement entre les mains des lecteurs.
Si le livre avec l'ISBN donné n'est pas dans la bibliothèque, la procédure renvoie –100 (moins cent).
Procédure 3. Vérification de l'existence d'un lecteur avec le nom et la date de naissance donnés
La procédure renvoie le numéro du ticket du lecteur, si un lecteur avec de telles données existe, et 0 (zéro) dans le cas contraire.
Lorsque vous comparez la date de naissance, vous devez utiliser la fonction de conversion Convert () pour convertir la date de naissance, une variable de caractère de type Varchar (8) utilisée comme entrée de la procédure, en données de type datatime, qui sont utilisées dans la table Readers. Sinon, l'opération de comparaison ne fonctionnera pas lors de la recherche du lecteur donné.
Procédure 4. Saisie d'un nouveau lecteur
La procédure comporte cinq paramètres d'entrée et trois paramètres de sortie.
Paramètres d'entrée:
- Nom complet avec initiales;
- Adresse;
- Date de naissance;
- Téléphone fixe;
- Le téléphone fonctionne.
Paramètres de sortie:
- Numéro de carte de bibliothèque;
- Une indication indiquant si le lecteur a déjà été enregistré dans la bibliothèque (0 - n'était pas, 1 - était);
- Le nombre de livres que possède le lecteur.
Procédure 5. Calcul de l'amende en termes monétaires pour les lecteurs débiteurs
La procédure fonctionne avec un curseur qui contient une liste des numéros de carte de bibliothèque de tous les débiteurs. Dans le processus de travail, une table temporaire globale ## DOLG devrait être créée, dans laquelle pour chaque débiteur sa dette totale en termes monétaires sera inscrite pour tous les livres qu'il détenait plus longtemps que la période de remboursement. La compensation monétaire est calculée à 0,5% du prix par livre pour le jour du retard.
Demande de service

- captures d'écran (captures d'écran) confirmant les modifications apportées aux bases de données;
- le contenu des tables de la base de données nécessaires pour valider l'opération correcte;
- texte de procédure stocké avec commentaires
- le processus d'exécution d'une procédure stockée avec la sortie des résultats du travail.
Des tâches supplémentaires
Les procédures stockées supplémentaires suivantes concernent des travaux individuels.
Procédure 6. Compter le nombre de livres dans un domaine donné qui se trouvent actuellement dans la bibliothèque en au moins un exemplaire. Le domaine est passé en tant que paramètre d'entrée.
Procédure 7. Saisie d'un nouveau livre en indiquant le nombre d'exemplaires. Lorsque vous saisissez des copies d'un nouveau livre, assurez-vous de saisir leurs numéros de stock corrects. Réfléchissez à la façon dont vous pouvez le faire. Pour rappel, vous disposez des fonctions Max et Min qui vous permettent de trouver la valeur maximale ou minimale de tout attribut numérique à l'aide d'une requête Select.
Procédure 8. Constitution d'une table avec une liste de lecteurs débiteurs, c'est-à-dire ceux qui ont dû rendre des livres à la bibliothèque, mais qui ne sont pas encore revenus. Dans le tableau qui en résulte, chaque lecteur débiteur ne doit apparaître qu'une seule fois, quel que soit le nombre de livres qu'il doit. En plus du nom complet et du numéro de la carte de bibliothèque, l'adresse et le numéro de téléphone doivent être indiqués dans le tableau résultant.
Procédure 9. Recherche d'un exemplaire gratuit par le titre du livre donné. S'il existe une copie gratuite, la procédure renvoie le numéro d'inventaire de l'instance; sinon, la procédure renvoie une liste des lecteurs qui possèdent ce livre, en indiquant la date de retour du livre et le numéro de téléphone du lecteur.
Procédure 10. Liste des lecteurs qui ne détiennent actuellement aucun livre. Spécifiez le nom et le numéro de téléphone dans la liste.
Procédure 11. Affichage d'une liste de livres indiquant le nombre d'exemplaires de ce livre dans la bibliothèque et le nombre d'exemplaires gratuits pour le moment.
version imprimée
Dans ce tutoriel, vous apprendrez comment créer et supprimer des procédures dans SQL Server (Transact-SQL) avec syntaxe et exemples.
La description
Dans SQL Server, une procédure est un programme stocké dans lequel vous pouvez passer des paramètres. Il ne renvoie pas de valeur comme une fonction. Cependant, il peut renvoyer un état de réussite / échec à la procédure qui l'a appelé.
Créer une procédure
Vous pouvez créer vos propres procédures stockées dans SQL Server (Transact-SQL). Regardons de plus près.
Syntaxe
La syntaxe des procédures dans SQL Server (Transact-SQL) est la suivante:
CREATE (PROCEDURE | PROC) nom_procédure
[@paramètre type de données
[VARYING] [\u003d default] [OUT | OUTPUT | LECTURE SEULEMENT]
, @paramètre type de données
[VARYING] [\u003d default] [OUT | OUTPUT | LECTURE SEULEMENT]]
[WITH (ENCRYPTION | RECOMPILE | EXECUTE AS Clause)]
[POUR RÉPLICATION]
COMME
COMMENCER
section_exécutable
FIN;
Paramètres ou arguments
schema_name est le nom du schéma auquel appartient la procédure stockée.
nom_procédure est le nom pour affecter cette procédure dans SQL Server.
@parameter - un ou plusieurs paramètres sont transmis à la procédure.
type_schema_name est le schéma qui possède le type de données, le cas échéant.
Datatype est le type de données pour @parameter.
VARYING - Défini sur les paramètres du curseur lorsque le jeu de résultats est un paramètre de sortie.
default est la valeur par défaut à affecter au @paramètre.
OUT - Cela signifie que @parameter est un paramètre de sortie.
OUTPUT - Cela signifie que @parameter est un paramètre de sortie.
READONLY - Cela signifie que @parameter ne peut pas être écrasé par la procédure stockée.
ENCRYPTION - Cela signifie que la source de la procédure stockée ne sera pas enregistrée en tant que texte brut dans les vues système SQL Server.
RECOMPILE - Cela signifie que le plan de requête ne sera pas mis en cache pour cette procédure stockée.
EXECUTE AS - Définit le contexte de sécurité pour l'exécution de la procédure stockée.
POUR RÉPLICATION - Cela signifie que la procédure stockée est exécutée uniquement pendant la réplication.
Exemple
Examinons un exemple de création d'une procédure stockée dans SQL Server (Transact-SQL).
Voici un exemple simple de la procédure:
Transact-SQL
CRÉER UNE PROCÉDURE FindSite @site_name VARCHAR (50) OUT AS BEGIN DECLARE @site_id INT; SET @site_id \u003d 8; IF @site_id< 10 SET @site_name = "yandex.com"; ELSE SET @site_name = "google.com"; END;
CRÉER UNE PROCÉDURE FindSite @ nom_site VARCHAR (50) OUT COMMENCER DECLARE @ site_id INT; SET @ site_id \u003d 8; IF @ site_id< 10 SET @ site_name \u003d "yandex.com"; AUTRE SET @ site_name \u003d "google.com"; FIN; |
Cette procédure s'appelle FindSite. Il a un paramètre appelé @site_name, qui est un paramètre de sortie mis à jour en fonction de la variable @site_id.
Ensuite, vous pouvez faire référence à une nouvelle procédure stockée appelée FindSite comme suit.


