SQL - Lezione 15. Stored procedure. Parte 1
Di norma, lavoriamo con il database utilizzando le stesse query o un set di query consecutive. Le procedure memorizzate consentono di combinare una sequenza di richieste e memorizzarle sul server. Questo è uno strumento molto conveniente e ora lo vedrai. Cominciamo con la sintassi:CREATE PROCEDURE nome_procedura (parametri) inizio istruzioni fine
I parametri sono i dati che passeremo alla procedura quando viene chiamato e gli operatori sono le richieste effettive. Scriviamo la nostra prima procedura e assicuriamoci della sua convenienza. Nella lezione 10, quando abbiamo aggiunto nuovi record al database del negozio, abbiamo usato la query standard per aggiungere una vista:
INSERIRE I clienti (nome, e-mail) VALUE ("Sergey Ivanov", " [e-mail protetta]");
perché Useremo una richiesta simile ogni volta che avremo bisogno di aggiungere un nuovo acquirente, è del tutto appropriato metterlo sotto forma di una procedura:
CREATE PROCEDURE ins_cust (n CHAR (50), e CHAR (50)) inizia l'inserimento nel valore dei clienti (nome, e-mail) (n, e); fine
Nota come sono impostati i parametri: devi dare un nome a un parametro e indicarne il tipo, e nel corpo della procedura usiamo già i nomi dei parametri. Un avvertimento. Come ricordi, un punto e virgola indica la fine della richiesta e la invia per l'esecuzione, che in questo caso è inaccettabile. Pertanto, prima di scrivere una procedura, è necessario ridefinire il delimitatore con; su "//" in modo che la richiesta non venga inviata in anticipo. Questo viene fatto usando l'operatore DELIMITER //: 
Pertanto, abbiamo indicato al DBMS che i comandi ora dovrebbero essere eseguiti dopo //. Va ricordato che la ridefinizione del separatore viene eseguita solo per una sessione, ad es. durante la prossima sessione con MySql, il separatore diventerà di nuovo un punto e virgola e, se necessario, dovrà essere ridefinito di nuovo. Ora puoi posizionare la procedura:
CREATE PROCEDURE ins_cust (n CHAR (50), e CHAR (50)) inizia l'inserimento nel valore dei clienti (nome, e-mail) (n, e); fine //

Quindi, la procedura è stata creata. Ora, quando dobbiamo presentare un nuovo acquirente, è sufficiente per noi chiamarla, indicando i parametri necessari. Per chiamare la procedura memorizzata, viene utilizzato l'operatore CALL, dopo di che vengono indicati il \u200b\u200bnome della procedura e i suoi parametri. Aggiungiamo un nuovo acquirente alla nostra tabella Clienti:
call ins_cust ("Sychov Valery", " [e-mail protetta]")//

Concordo sul fatto che sia molto più semplice che scrivere ogni volta una richiesta completa. Controlliamo se la procedura funziona esaminando se un nuovo acquirente è apparso nella tabella Clienti:

Appare, la procedura funziona e funzionerà sempre, fino a quando non la elimineremo usando l'operatore DROP PROCEDURE nome_procedura.
Come indicato all'inizio della lezione, le procedure consentono di combinare una sequenza di query. Vediamo come è fatto. Ricorda nella lezione 11 che volevamo scoprire quanto il fornitore di "Print House" ci ha portato la merce? Per fare ciò, abbiamo dovuto utilizzare query nidificate, join, colonne calcolate e viste. E se vogliamo sapere quanto l'altro fornitore ci ha portato la merce? Dovrà fare nuove domande, associazioni, ecc. È più semplice scrivere una procedura memorizzata per questa azione una volta.
Sembrerebbe che il modo più semplice sia prendere la vista e la query già scritte nella Lezione 11, combinarla in una procedura memorizzata e rendere l'identificatore del provider (id_vendor) un parametro di input, come questo:
CREATE PROCEDURE sum_vendor (i INT) inizia CREATE VIEW report_vendor AS SELECT magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity * prices.price AS summa FROM magazine_incoming, prezzi WHERE magazine_incoming.id_product \u003d prices.id_product SELEZIONA id_incoming DA incoming DOVE id_vendor \u003d i); SELECT SUM (summa) FROM report_vendor; fine //
Ma questa procedura non funzionerà. Il fatto è quello le viste non possono utilizzare i parametri. Pertanto, dovremo modificare leggermente la sequenza delle richieste. Innanzitutto, creeremo una vista che visualizzerà l'identificatore del fornitore (id_vendor), l'identificatore del prodotto (id_product), la quantità (quantità), il prezzo (prezzo) e la somma (summa) dalle tre tabelle Consegna (in entrata), Giornale di consegna (magazine_incoming), Prezzi ( prezzi):
CREA VISUALIZZA report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity * prices.price AS summa FROM incoming, magazine_incoming, prezzi DOVE magazine_incoming.id_product \u003d prices.id_prodid AND magazine_incomingid .id_incoming;
E quindi creare una richiesta che somma gli importi di fornitura del fornitore di interesse per noi, ad esempio, con id_vendor \u003d 2:
Ora possiamo combinare queste due richieste in una procedura memorizzata, in cui il parametro di input sarà l'identificatore del provider (id_vendor), che verrà sostituito nella seconda richiesta, ma non nella vista:
CREATE PROCEDURE sum_vendor (i INT) inizia CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity * prices.price AS summa FROM in arrivo, magazine_incoming, prezzi WHERE magazine_incoming.id .id_product AND magazine_incoming.id_incoming \u003d incoming.id_incoming; SELEZIONA SOMMA (summa) DA report_vendor DOVE id_vendor \u003d i; fine //

Verificare il funzionamento della procedura, con diversi parametri di input:

Come puoi vedere, la procedura viene attivata una volta, quindi genera un errore che ci dice che la vista report_vendor esiste già nel database. Questo perché quando si accede alla procedura per la prima volta, viene creata una vista. Quando accede una seconda volta, tenta di nuovo di creare una vista, ma esiste già e quindi appare un errore. Per evitare ciò, sono possibili due opzioni.
Il primo è far uscire l'idea dalla procedura. Cioè, creeremo una vista una volta e la procedura farà riferimento solo ad essa, ma non la creerà. Ricorda di eliminare la procedura già creata e visualizzare:
PROCEDURA DROP sum_vendor // DROP VIEW report_vendor // CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity * prices.price AS summa FROM in arrivo, magazine_incoming_principal prezzi \u003d prices.id_product AND magazine_incoming.id_incoming \u003d incoming.id_incoming // CREATE PROCEDURE sum_vendor (i INT) inizio SELEZIONA SOMMA (summa) FROM report_vendor DOVE id_vendor \u003d i; fine //

Controlla il lavoro:
call sum_vendor (1) // call sum_vendor (2) // call sum_vendor (3) //
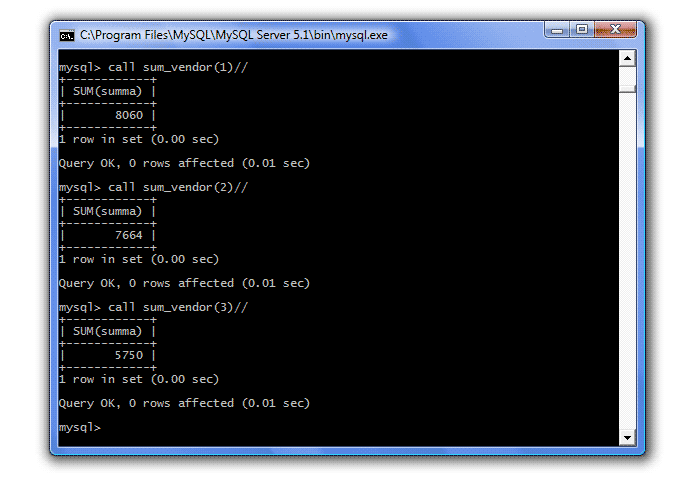
La seconda opzione è quella di aggiungere un comando direttamente nella procedura che eliminerà la vista, se esiste:
CREA PROCEDURA sum_vendor (i INT) inizia DROP VIEW IF EXISTS report_vendor; CREA VISUALIZZA report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity * prices.price AS summa FROM incoming, magazine_incoming, prezzi DOVE magazine_incoming.id_product \u003d prices.id_prodid AND magazine_incomingid .id_incoming; SELEZIONA SOMMA (summa) DA report_vendor DOVE id_vendor \u003d i; fine //
Prima di utilizzare questa opzione, non dimenticare di eliminare la procedura sum_vendor, quindi controllare l'operazione: 
Come puoi vedere, le query complesse o la loro sequenza è davvero più semplice emettere una volta in una procedura memorizzata e quindi accedervi, indicando i parametri necessari. Ciò riduce notevolmente il codice e rende più logico il lavoro con le query.
Includi la riga - SET NOCOUNT ON:
Con ogni espressione DML, SQL Server restituisce con attenzione un messaggio contenente il numero di record elaborati. Queste informazioni possono esserci utili durante il debug del codice, ma successivamente saranno completamente inutili. Scrivendo SET NOCOUNT ON, disabilitiamo questa funzione. Per le procedure memorizzate che contengono diverse espressioni o \\ e loop, questa azione può dare un significativo aumento delle prestazioni, poiché la quantità di traffico sarà significativamente ridotta.
Transact-SQL
Utilizzare il nome dello schema con il nome dell'oggetto:
Beh, penso sia chiaro. Questa operazione indica al server dove cercare gli oggetti e invece di rovistare casualmente tra i suoi contenitori, saprà immediatamente dove deve andare e cosa portare. Con un gran numero di database, tabelle e procedure memorizzate, può far risparmiare significativamente tempo e nervi.
Transact-SQL
SELEZIONA * DA dbo.MyTable - Qui è bene farlo - Invece di SELEZIONA * DA MyTable - Ed è male farlo - La procedura EXEC chiama dbo.MyProc - Ancora una volta, bene - Invece di EXEC MyProc - Cattivo!
Non utilizzare il prefisso "sp_" nel nome delle procedure memorizzate:
Se il nome della nostra procedura inizia con "sp_", SQL Server cercherà prima nel suo database principale. Il fatto è che questo prefisso viene utilizzato per le stored procedure del server interno personale. Pertanto, il suo utilizzo può comportare costi aggiuntivi e persino risultati errati se la procedura con lo stesso nome del tuo si trova nel suo database.
Utilizzare IF EXISTS (SELEZIONA 1) invece di IF EXISTS (SELEZIONA *):
Per verificare la presenza di un record in un'altra tabella, utilizziamo l'espressione IF EXISTS. Questa espressione restituisce true se almeno un valore viene restituito dall'espressione interna, non importa "1", tutte le colonne o la tabella. I dati restituiti, in linea di principio, non vengono utilizzati in alcun modo. Pertanto, è più logico utilizzare "1" per comprimere il traffico durante il trasferimento dei dati, come mostrato di seguito.
Per la programmazione di stored procedure estese, Microsoft fornisce all'API ODS (Open Data Service) un insieme di macro e funzioni utilizzate per creare applicazioni server che estendono le funzionalità di MS SQL Server 2000.
Le stored procedure estese sono funzioni ordinarie scritte in C / C ++ utilizzando l'API ODS e l'API WIN32, progettate come libreria a collegamento dinamico (dll) e progettate, come ho detto, per espandere la funzionalità del server SQL. L'API ODS fornisce allo sviluppatore un ricco set di funzioni che consentono di trasferire i dati al client ricevuti da qualsiasi origine dati esterna (origine dati) sotto forma di set di record ordinari. Inoltre, la stored procedure estesa può restituire valori tramite il parametro passato ad esso (parametro OUTPUT).
Come funzionano le stored procedure estese.
- Quando l'applicazione client chiama la stored procedure estesa, la richiesta viene trasmessa in formato TDS tramite la libreria di rete Net-Libraries e Open Data Service al kernel MS SQL SERVER.
- SQL Sever trova la libreria dll associata al nome della stored procedure estesa e la carica nel suo contesto, se non è stata precedentemente caricata lì, e chiama la stored procedure estesa, implementata come funzione all'interno della DLL.
- La stored procedure estesa esegue le azioni necessarie sul server e passa il set di risultati all'applicazione client utilizzando il servizio fornito dall'API ODS.
Funzionalità di stored procedure estese.
- Le stored procedure estese sono funzioni eseguite nello spazio degli indirizzi di MS SQL Server e nel contesto di sicurezza dell'account con cui è in esecuzione il servizio MS SQL Server;
- Dopo che la libreria dll con stored procedure estese è stata caricata in memoria, rimane lì fino all'arresto di SQL Server o fino a quando l'amministratore non la scarica in modo forzato utilizzando il comando:
DBCC DLL_name (GRATUITO). - Una stored procedure estesa viene avviata come una normale stored procedure:
EXECUTE xp_extendedProcName @ param1, @ param2 OUTPUT
@ parametro di input param1
@ parametro di input / output param2
Poiché le stored procedure estese vengono eseguite nello spazio degli indirizzi del processo di servizio di MS SQL Server, eventuali errori critici che si verificano nel loro funzionamento possono danneggiare il core del server, pertanto si consiglia di testare attentamente la DLL prima di installarla sul server di produzione.
Creare procedure memorizzate avanzate.
Una stored procedure estesa è una funzione che presenta il seguente prototipo:
SRVRETCODE xp_extendedProcName (SRVPROC * pSrvProc);
parametro pSrvProc un puntatore alla struttura SRVPROC, che è l'handle di ogni specifica connessione client. I campi di questa struttura non sono documentati e contengono informazioni utilizzate dalla libreria ODS per gestire la comunicazione e i dati tra l'applicazione del server Open Data Services e il client. In ogni caso, non è necessario accedere a questa struttura, e ancora di più, non è possibile modificarla. Questo parametro deve essere specificato quando si chiama una funzione API ODS, quindi in futuro non mi soffermerò sulla sua descrizione.
L'uso del prefisso xp_ è facoltativo, ma esiste un accordo per iniziare il nome della procedura memorizzata estesa in modo da enfatizzare la differenza rispetto alla normale procedura memorizzata, i cui nomi, come sapete, di solito vengono avviati con il prefisso sp_.
Va inoltre ricordato che i nomi delle stored procedure estese fanno distinzione tra maiuscole e minuscole. Non dimenticartene quando chiami la stored procedure estesa, altrimenti invece del risultato previsto, riceverai un messaggio di errore.
Se è necessario scrivere il codice di inizializzazione / deinizializzazione della dll, utilizzare la funzione DllMain () standard per questo. Se non si ha tale necessità e non si desidera scrivere DLLMain (), il compilatore assemblerà la sua versione della funzione DLLMain (), che non fa nulla, ma restituisce semplicemente VERO. Tutte le funzioni chiamate dalla dll (ovvero le stored procedure estese) devono essere dichiarate come esportate. Se stai scrivendo in MS Visual C ++ usa la direttiva __declspec (dllexport). Se il compilatore non supporta questa direttiva, descrivere la funzione esportata nella sezione ESPORTAZIONI nel file DEF.
Quindi, per creare un progetto, abbiamo bisogno dei seguenti file:
- File di intestazione Srv.h, contiene una descrizione delle funzioni e delle macro dell'API ODS;
- Opends60.lib è il file di importazione della libreria Opends60.dll, che implementa l'intero servizio fornito dall'API ODS.
Declspec (dllexport) ULONG __GetXpVersion ()
{
return ODS_VERSION;
}
Quando MS SQL Server carica la DLL con la stored procedure estesa, innanzitutto chiama questa funzione per ottenere informazioni sulla versione della libreria utilizzata.
Per scrivere la prima procedura memorizzata estesa, è necessario installare sul computer:
MS SQL Server 2000 di qualsiasi edizione (ho Personal Edition). Durante l'installazione, assicurarsi di selezionare l'opzione di esempio di origine
- MS Visual C ++ (ho usato la versione 7.0), ma so per certo che lo farà anche 6.0
L'installazione di SQL Server -a è necessaria per testare ed eseguire il debug della DLL. È anche possibile eseguire il debug in rete, ma non l'ho mai fatto, quindi ho installato tutto sul mio disco locale. L'edizione Microsoft Visual C ++ 7.0 di Interprise Edition viene fornita con la procedura guidata Extended Stored Procedure DLL. In linea di principio, non fa nulla al di là del naturale, ma genera solo un modello per una stored procedure estesa. Se ti piacciono i maghi, puoi usarlo. Preferisco fare tutto con le penne e quindi non prenderò in considerazione questo caso.
Ora al punto:
- Avviare Visual C ++ e creare un nuovo progetto - Libreria di collegamento dinamico Win32.
- Includi il file di intestazione nel progetto - #include
- Vai su Strumenti \u003d\u003e Opzioni e aggiungi percorsi di ricerca per includere e file di libreria. Se durante l'installazione di MS SQL Server non hai modificato nulla, specifica:
C: Programmi Microsoft SQL Server80ToolsDevToolsInclude per i file di intestazione;
- C: Programmi Microsoft SQL Server80ToolsDevToolsLib per i file di libreria.
- Specificare il nome del file di libreria opends60.lib nelle opzioni del linker.
A questo punto la fase preparatoria è completata, è possibile iniziare a scrivere la prima procedura memorizzata estesa.
Dichiarazione del problema.
Prima di iniziare la programmazione, devi avere un'idea chiara di dove iniziare, quale dovrebbe essere il risultato finale e come raggiungerlo. Quindi, ecco i termini di riferimento per noi:
Sviluppare una stored procedure estesa per MS SQL Server 2000, che riceve un elenco completo di utenti registrati nel dominio e lo restituisce al client sotto forma di un set di record standard. Come primo parametro di input, la funzione riceve il nome del server contenente la directory del database (Active Directory), ovvero il nome del controller di dominio. Se questo parametro è NULL, è necessario passare al client l'elenco dei gruppi locali. Il secondo parametro verrà utilizzato dalla stored procedure estesa per restituire il valore del risultato di un'operazione riuscita / non riuscita (parametro OUTPUT). Se la stored procedure estesa ha esito positivo, è necessario trasferire il numero di record restituiti al set di record del client, se durante il lavoro non è stato possibile ottenere le informazioni richieste, il valore del secondo parametro deve essere impostato su -1, come segno di errore.
Il prototipo condizionale della stored procedure estesa è il seguente:
xp_GetUserList (@NameServer varchar, @CountRec int OUTPUT);
Ed ecco un modello esteso di procedura memorizzata che dobbiamo riempire di contenuto:
#include
#include
#define XP_NOERROR 0
#define XP_ERROR -1
__declspec (dllexport) SERVRETCODE xp_GetGroupList (SRVPROC * pSrvProc)
{
// Controlla il numero di parametri passati
// Verifica il tipo di parametri passati
// Controlla se il parametro 2 OUTPUT è un parametro
// Controlla se il parametro 2 è abbastanza lungo per memorizzare il valore
// Ottieni parametri di input
// Ottieni un elenco di utenti
// Invia i dati ricevuti al client sotto forma di un set standard di record (set di record)
// Imposta il valore OUTPUT del parametro
ritorno (XP_NOERROR);
}
Lavora con i parametri di input
In questo capitolo, non voglio diffondere la tua attenzione su altre cose, ma voglio concentrarmi sul lavoro con i parametri passati alla procedura memorizzata estesa. Pertanto, semplificheremo in qualche modo i nostri termini di riferimento e svilupperemo solo quella parte di esso che funziona con i parametri di input. Ma all'inizio non molta teoria
La prima azione che deve eseguire la nostra stored procedure estesa è quella di ottenere i parametri che le sono stati passati al momento della chiamata. Seguendo l'algoritmo sopra riportato, dobbiamo eseguire le seguenti azioni:
Determinare il numero di parametri passati;
- Assicurarsi che i parametri passati abbiano il tipo di dati corretto;
- Assicurarsi che il parametro OUTPUT specificato sia di lunghezza sufficiente per memorizzare in esso il valore restituito dalla nostra procedura estesa memorizzata.
- Ottieni parametri trasferiti;
- Impostare i valori del parametro di output a seguito del completamento con esito positivo / negativo della procedura memorizzata estesa.
Ora considera in dettaglio ogni articolo:
Determinazione del numero di parametri passati alla stored procedure estesa
Per ottenere il numero di parametri passati, è necessario utilizzare la funzione:
int srv_rpcparams (SRV_PROC * srvproc);
In caso di completamento con esito positivo, la funzione restituisce il numero di parametri passati alla procedura memorizzata estesa. Se la stored procedure estesa è stata chiamata senza parametri, srv_rpcparams restituirà -1. I parametri possono essere passati per nome o per posizione (senza nome). In ogni caso, non è possibile mescolare questi due metodi. Tentare di passare i parametri di input alla funzione per nome e posizione contemporaneamente porterà a un errore e srv_rpcparams restituirà 0.
Definizione del tipo di dati e lunghezza dei parametri passati
Microsoft consiglia di utilizzare la funzione srv_paramifo per ottenere informazioni sul tipo e la lunghezza dei parametri passati. Questa funzione generica sostituisce le chiamate srv_paramtype, srv_paramlen, srv_parammaxlen, che ora sono obsolete. Ecco il suo prototipo:
int srv_paraminfo (
SRV_PROC * srvproc,
int n
BYTE * pbType,
ULONG * pcbMaxLen,
ULONG * pcbActualLen,
BYTE * pbData,
BOOL * pfNull);
pbType imposta il numero seriale del parametro. Il numero del primo parametro inizia con 1.
pcbMaxLen puntatore alla variabile in cui la funzione inserisce il valore massimo della lunghezza del parametro. Questo valore è determinato dal tipo di dati specifico del parametro passato e lo useremo per assicurarci che il parametro OUTPUT sia abbastanza lungo da salvare i dati trasmessi.
pcbActualLen Puntatore alla lunghezza effettiva del parametro passato alla stored procedure estesa quando chiamato. Se il parametro passato ha lunghezza zero e il flag pfNull è impostato su FALSE, allora (* pcbActualLen) \u003d\u003d 0.
pbData - un puntatore a un buffer per il quale è necessario allocare memoria prima di chiamare srv_paraminfo. In questo buffer, la funzione inserisce i parametri di input ricevuti dalla stored procedure estesa. La dimensione del buffer in byte è uguale a pcbMaxLen. Se questo parametro è impostato su NULL, i dati non vengono scritti nel buffer, ma la funzione restituisce correttamente i valori * pbType, * pcbMaxLen, * pcbActualLen, * pfNull. Pertanto, è necessario chiamare due volte srv_paraminfo: prima con pbData \u003d NULL, quindi, allocando la dimensione di memoria richiesta per il buffer pari a pcbActualLen, chiamare srv_paraminfo una seconda volta, passando un puntatore al blocco di memoria allocato in pbData.
pfNull puntatore a un flag NULL. srv_paraminfo lo imposta su TRUE se il valore del parametro di input è NULL.
Controllare se il secondo parametro OUTPUT è un parametro.
La funzione srv_paramstatus () viene utilizzata per determinare lo stato del parametro passato:
int srv_paramstatus (
SRV_PROC * srvproc,
int n
);
n numero di parametro passato alla stored procedure estesa quando chiamato. Lascia che te lo ricordi: i parametri sono sempre numerati da 1.
Per restituire un valore, srv_paramstatus utilizza il bit zero. Se è impostato su 1, il parametro passato è un parametro OUTPUT, se su 0, è un parametro ordinario passato per valore. Se la stored procedure estesa è stata chiamata senza parametri, la funzione restituirà -1.
Impostazione del valore del parametro di output.
È possibile passare un valore al parametro di output passato alla memoria estesa utilizzando la funzione srv_paramsetoutput. Questa nuova funzione sostituisce la chiamata della funzione srv_paramset, che ora è considerata obsoleta, perché non supporta nuovi tipi di dati introdotti nell'API ODS e dati di lunghezza zero.
int srv_paramsetoutput (
SRV_PROC * srvproc,
int n
BYTE * pbData,
ULONG cbLen,
BOOL fNull
);
pbData puntatore al buffer con i dati che verranno inviati al client per impostare il valore del parametro di output.
cbLen lunghezza del buffer dei dati inviati. Se il tipo di dati del parametro OUTPUT passato definisce dati di lunghezza costante e non consente la memorizzazione di valori NULL (ad esempio, SRVBIT o SRVINT1), la funzione ignora il parametro cbLen. Il valore cbLen \u003d 0 indica i dati di lunghezza zero e il parametro fNull deve essere impostato su FALSE.
fNull impostarlo su TRUE se il parametro restituito deve essere impostato su NULL, mentre il valore di cbLen deve essere 0, altrimenti la funzione fallirà. In tutti gli altri casi, fNull \u003d FALSE.
In caso di successo, la funzione restituisce SUCCEED. Se il valore restituito è FAIL, la chiamata non è andata a buon fine. Tutto è semplice e chiaro.
Ora sappiamo abbastanza per scrivere la nostra prima stored procedure estesa, che restituirà un valore attraverso il parametro passato ad essa. Sia, secondo la tradizione, questa sarà la stringa Hello world! La versione di debug dell'esempio può essere scaricata qui.
#include
#define XP_NOERROR 0
#define XP_ERROR 1
#define MAX_SERVER_ERROR 20000
#define XP_HELLO_ERROR MAX_SERVER_ERROR + 1
void printError (SRV_PROC *, CHAR *);
#ifdef __cplusplus
extern "C" (
#endif
SRVRETCODE __declspec (dllexport) xp_helloworld (SRV_PROC * pSrvProc);
#ifdef __cplusplus
}
#endif
SRVRETCODE xp_helloworld (SRV_PROC * pSrvProc)
{
char szText \u003d "Hello World!";
BYTE bType;
ULONG cbMaxLen;
ULONG cbActualLen;
BOOL fNull;
/ * Determinazione del numero di trasferiti in memoria estesa
procedura parametri * /
if (srv_rpcparams (pSrvProc)! \u003d 1)
{
printError (pSrvProc, "Numero di parametri non valido!");
ritorno (XP_ERROR);
}
/ * Ottenere informazioni sul tipo di dati e la lunghezza dei parametri passati * /
if (srv_paraminfo (pSrvProc, 1, & bType, & cbMaxLen,
& cbActualLen, NULL e & fNull) \u003d\u003d FAIL)
{
printError (pSrvProc,
"Impossibile ottenere informazioni sui parametri di input ...");
ritorno (XP_ERROR);
}
/ * Controlla se il parametro OUTPUT passato è un parametro * /
if ((srv_paramstatus (pSrvProc, 1) & SRV_PARAMRETURN) \u003d\u003d FAIL)
{
printError (pSrvProc,
"Il parametro passato non è un parametro OUTPUT!");
ritorno (XP_ERROR);
}
/ * Verifica il tipo di dati del parametro passato * /
if (bType! \u003d SRVBIGVARCHAR && bType! \u003d SRVBIGCHAR)
{
printError (pSrvProc, "Tipo di parametro non valido passato!");
ritorno (XP_ERROR);
}
/ * Assicurarsi che il parametro passato sia sufficientemente lungo da salvare la stringa restituita * /
if (cbMaxLen< strlen(szText))
{
printError (pSrvProc,
"È stato passato un parametro di lunghezza insufficiente per salvare n la stringa restituita!");
ritorno (XP_ERROR);
}
/ * Imposta il valore OUTPUT del parametro * /
if (FAIL \u003d\u003d srv_paramsetoutput (pSrvProc, 1, (BYTE *) szText, 13, FALSE))
{
printError (pSrvProc,
"Non riesco a impostare il valore OUTPUT del parametro ...");
ritorno (XP_ERROR);
}
srv_senddone (pSrvProc, (SRV_DONE_COUNT | SRV_DONE_MORE), 0, 1);
ritorno (XP_NOERROR);
}
void printError (SRV_PROC * pSrvProc, CHAR * szErrorMsg)
{
srv_sendmsg (pSrvProc, SRV_MSG_ERROR, XP_HELLO_ERROR, SRV_INFO, 1,
NULL, 0, 0, szErrorMsg, SRV_NULLTERM);
Srv_senddone (pSrvProc, (SRV_DONE_ERROR | SRV_DONE_MORE), 0, 0);
}
Le funzioni srv_sendmsg e srv_senddone sono rimaste non esaminate. La funzione srv_sendmsg viene utilizzata per inviare messaggi al client. Ecco il suo prototipo:
int srv_sendmsg (
SRV_PROC * srvproc,
int msgtype,
DBINT msgnum,
Classe DBTINYINT,
Stato DBTINYINT,
DBCHAR * rpcname,
int rpcnamelen,
DBUSMALLINT lino,
DBCHAR * messaggio,
int msglen
);
numero messaggio msgnum;
classe - la gravità dell'errore. I messaggi informativi hanno un valore di gravità inferiore o uguale a 10;
stato numero di stato dell'errore per il messaggio corrente. Questo parametro fornisce informazioni sul contesto dell'errore che si è verificato. I valori consentiti vanno da 0 a 127;
rpcname non è attualmente utilizzato;
rpcnamelen: attualmente non utilizzato;
linenum qui puoi specificare il numero di riga del codice sorgente. In base a questo valore, di conseguenza sarà facile determinare dove si è verificato l'errore. Se non si desidera utilizzare questa funzione, impostare il lino su 0;
puntatore a una stringa inviata al client;
msglen definisce la lunghezza in byte della stringa del messaggio. Se questa stringa termina con un carattere , il valore di questo parametro può essere impostato uguale a SRV_NULLTERM.
Valori di ritorno:
- in caso di successo SUCCEED
- se FAIL fallisce.
Durante il funzionamento, la procedura memorizzata estesa dovrebbe informare regolarmente l'applicazione client del suo stato, ad es. inviare messaggi sulle azioni completate. La funzione srv_senddone è pensata per questo:
int srv_senddone (
SRV_PROC * srvproc,
Stato DBUSMALLINT,
Informazioni DBUSMALLINT,
Conteggio DBINT
);
flag di stato. Il valore di questo parametro può essere impostato utilizzando gli operatori logici AND e OR per combinare le costanti indicate nella tabella:
Flag di stato Descrizione
SRV_DONE_FINAL Il set di risultati corrente è definitivo;
SRV_DONE_MORE Il set di risultati corrente non è definitivo, si aspetta una buona parte dei dati;
SRV_DONE_COUNT Il parametro count contiene il valore corretto.
SRV_DONE_ERROR Utilizzato per notificare errori e risoluzione immediata.
in riservato, deve essere impostato su 0.
conteggio Il numero di set di risultati inviati al client. Se il flag di stato è impostato su SRV_DONE_COUNT, il conteggio deve contenere il numero corretto di recordset inviati al client.
Valori di ritorno:
- in caso di successo SUCCEED
- se FAIL fallisce.
Installa le stored procedure avanzate su MS SQL Server 2000
1. Copiare la libreria dll con la stored procedure estesa nella directory binn sulla macchina con MS SQL Server installato. Ho questo percorso come segue: C: Program FilesMicrosoft SQL ServerMSSQLBinn;
2. Registrare la procedura memorizzata estesa sul server eseguendo il seguente script:
USO Master
ESEGUIRE SP_ADDEXTENDEDPROC xp_helloworld, xp_helloworld.dll
Prova xp_helloworld eseguendo il seguente script:
DECLARE @Param varchar (33)
ESEGUI xp_helloworld @Param OUTPUT
SELEZIONA @Param AS OUTPUT_Param
conclusione
Questa è la prima parte del mio articolo. Ora sono sicuro che sei pronto a far fronte al nostro mandato per il 100%. Nel seguente articolo imparerai:
- Tipi di dati definiti nell'API ODS;
- Funzionalità di debug di processi memorizzati avanzati;
- Come creare recordset e trasferirli nell'applicazione client;
- Esamineremo le funzioni dell'API di gestione della rete di Active Directory necessarie per ottenere un elenco di utenti del dominio;
- Creeremo un progetto finito (implementeremo i nostri termini di riferimento)
Spero - a presto!
PS: file di esempio per l'articolo di download per studio 7.0
- Studiare gli operatori sulla descrizione delle procedure memorizzate e sui principi di trasferimento dei loro parametri di input e output.
- Scopri come creare ed eseguire il debug di stored procedure su MS SQL Server 2000.
- Sviluppa cinque stored procedure di base per il database di training della libreria.
- Preparare una relazione sullo stato di avanzamento elettronicamente.
1. Informazioni generali sulle procedure memorizzate
Stored procedure È un insieme di comandi archiviati su un server ed eseguiti nel loro insieme. Le procedure memorizzate sono un meccanismo mediante il quale è possibile creare routine in esecuzione sul server e controllate dai suoi processi. Routine simili possono essere attivate dall'applicazione chiamante. Inoltre, possono essere attivati \u200b\u200bda regole che mantengono l'integrità dei dati o da trigger.
Le procedure memorizzate possono restituire valori. Nella procedura, è possibile confrontare i valori immessi dall'utente con le informazioni preinstallate nel sistema. Le procedure memorizzate sfruttano potenti soluzioni hardware di SQL Server. Sono orientati al database e lavorano a stretto contatto con SQL Server Optimizer. Ciò consente di ottenere prestazioni elevate durante l'elaborazione dei dati.
È possibile trasferire valori alle procedure memorizzate e ottenere risultati di lavoro da esse, e non necessariamente correlati al foglio di lavoro. Una procedura memorizzata può calcolare i risultati durante il funzionamento.
Esistono due tipi di stored procedure: normale e esteso. Le stored procedure regolari sono un insieme di comandi Transact-SQL, mentre le stored procedure estese sono rappresentate come librerie dinamiche (DLL). Tali procedure, a differenza di quelle ordinarie, hanno il prefisso xp_. Il server ha una serie standard di procedure avanzate, ma gli utenti possono scrivere le proprie procedure in qualsiasi linguaggio di programmazione. La cosa principale è usare l'interfaccia di programmazione API Open Data Services di SQL Server. Le stored procedure estese possono essere solo nel database master.
Le stored procedure convenzionali possono anche essere suddivise in due tipi: sistema e costume. Le procedure di sistema sono procedure standard che servono al funzionamento del server; utente: qualsiasi procedura creata dall'utente.
1.1. Vantaggi delle procedure memorizzate
Nel caso più generale, le stored procedure presentano i seguenti vantaggi:
- Ad alte prestazioni. È il risultato della posizione delle procedure memorizzate sul server. Il server, di regola, è una macchina più potente, quindi il tempo di esecuzione della procedura sul server è molto più breve rispetto alla workstation. Inoltre, le informazioni dal database e la procedura memorizzata si trovano nello stesso sistema, quindi praticamente non ci vuole tempo per trasferire i record sulla rete. Le procedure memorizzate hanno accesso diretto ai database, il che rende molto veloce il lavoro con le informazioni.
- Il vantaggio di sviluppare un sistema in un'architettura client-server. Consiste nella possibilità di creare separatamente software client e server. Questo vantaggio è la chiave dello sviluppo e, grazie ad esso, è possibile ridurre significativamente il tempo necessario per completare il progetto. Il codice in esecuzione sul server può essere sviluppato separatamente dal codice lato client. Inoltre, i componenti lato server possono essere condivisi dai componenti lato client.
- Livello di sicurezza. Le procedure memorizzate possono fungere da strumento per migliorare la sicurezza. È possibile creare procedure memorizzate che eseguono le operazioni di aggiunta, modifica, eliminazione e visualizzazione di elenchi e quindi ottenere il controllo su ciascun aspetto dell'accesso alle informazioni.
- Rafforzare le regole del server per lavorare con i dati. Questo è uno dei motivi più importanti per l'utilizzo del motore di database intelligente. Le procedure memorizzate consentono di applicare regole e altre logiche per aiutare a controllare le informazioni immesse nel sistema.
Sebbene SQL sia definito come non procedurale, SQL Server utilizza parole chiave correlate al controllo dell'avanzamento delle procedure. Queste parole chiave vengono utilizzate per creare procedure che è possibile salvare per un'esecuzione successiva. È possibile utilizzare procedure memorizzate anziché programmi creati utilizzando linguaggi di programmazione standard (ad esempio C o Visual Basic) ed eseguendo operazioni nel database di SQL Server.
Le procedure memorizzate vengono compilate al primo avvio e memorizzate nella tabella di sistema del database corrente. Durante la compilazione, sono ottimizzati. In questo caso, viene selezionato il modo migliore per accedere alle informazioni sulla tabella. Tale ottimizzazione tiene conto della posizione effettiva dei dati nella tabella, degli indici disponibili, del caricamento della tabella, ecc.
Le stored procedure compilate possono migliorare significativamente le prestazioni del sistema. Tuttavia, vale la pena notare che le statistiche dei dati dal momento in cui la procedura è stata creata fino al momento della sua esecuzione possono diventare obsolete e gli indici possono diventare inefficaci. E sebbene sia possibile aggiornare le statistiche e aggiungere nuovi indici più efficienti, il piano per l'esecuzione della procedura è già stato elaborato, ovvero la procedura è stata compilata e, di conseguenza, il modo di accedere ai dati potrebbe non essere più efficace. Pertanto, è possibile ricompilare le procedure con ogni chiamata.
D'altra parte, ci vorrà del tempo per ricompilare ogni volta. Pertanto, la questione dell'efficacia della ricompilazione di una procedura o di un piano unico per la sua attuazione è piuttosto delicata e dovrebbe essere considerata separatamente per ciascun caso specifico.
Le stored procedure possono essere eseguite sul computer locale o su un sistema SQL Server remoto. Ciò consente di attivare i processi su altre macchine e di lavorare non solo con database locali, ma anche con informazioni su più server.
Le applicazioni scritte in uno dei linguaggi di alto livello, come C o Visual Basic .NET, possono anche chiamare stored procedure, che fornisce una soluzione ottimale per il bilanciamento del carico tra il software lato client e il server SQL.
1.2. Creazione di stored procedure
Per creare una procedura memorizzata, viene utilizzata l'istruzione Crea procedura. Il nome della procedura memorizzata può contenere fino a 128 caratteri, inclusi i caratteri # e ##. Sintassi della definizione della procedura:
CREATE PROC procedure_name [; numero]
[(parametro @ data_type) [\u003d default_value]] [, ... n]
AS
<Инструкции_SQL>
Considera le opzioni per questo comando:
- Nome_procedura - nome della procedura; deve rispettare le regole per gli identificatori: la sua lunghezza non può superare 128 caratteri; per le procedure temporanee locali, il segno # viene utilizzato prima del nome e per le procedure temporanee globali - i segni ##;
- Numero: un numero intero opzionale utilizzato per raggruppare diverse procedure sotto un unico nome;
- @ parametro tipo di dati - un elenco di nomi di parametri di procedura con un'indicazione del tipo di dati corrispondente per ciascuno; Possono esserci fino a 2100 parametri di questo tipo. NULL può essere usato come valore di parametro. È possibile utilizzare tutti i tipi di dati tranne text, ntext e image. È possibile utilizzare il tipo di dati Cursor come parametro di output (parola chiave OUTPUT o VARYING). I parametri con il tipo di dati Cursor possono essere solo parametri di output;
- VARYING - una parola chiave che determina che il set di risultati viene utilizzato come parametro di output (utilizzato solo per il tipo di cursore);
- OUTPUT - indica che il parametro specificato può essere utilizzato come output;
- dEFAULT_VALUE - utilizzato quando il parametro viene omesso quando si chiama la procedura; deve essere costante e può includere caratteri maschera (%, _, [,], ^) e un valore NULL;
- WITH RECOMPILE: parole chiave che indicano che SQL Server non scriverà il piano della procedura nella cache, ma lo creerà ogni volta che viene eseguito;
- WITH ENCRYPTION - Parole chiave che indicano che SQL Server crittograferà la procedura prima di scrivere nella tabella di sistema Syscomments. Affinché il testo delle procedure crittografate sia impossibile da recuperare, è necessario dopo la crittografia rimuovere le tuple corrispondenti dalla tabella dei sistemi;
- PER LA RISPOSTA - Parole chiave che mostrano che questa procedura è creata solo per la replica. Questa opzione non è compatibile con le parole chiave WITH RECOMPILE;
- AS - inizio della definizione del testo della procedura;
- <Инструкции_SQL> - una serie di istruzioni SQL valide, limitate solo dalla dimensione massima della procedura memorizzata - 128 Kb. Le seguenti affermazioni non sono valide: ALTER DATABASE, ALTER PROCEDURE, ALTER TABLE, CREATE DEFAULT, CREATE PROCEDURE, ALTER TRIGGER, ALTER VIEW, CREATE DATABASE, CREATE RULE, CREATE SCHEMA, CREATE TRIGGER, CREATE VIEW, DISPEKT DISK DROP DEFAULT, PROCEDURA DROP, DROP REGLE, DROP TRIGGER, DROP VIEW, RESOTRE DATABASE, RESTORE LOG, RECONFIGURE, UPDATE STATISTICS.
Considera un esempio di una procedura memorizzata. Svilupperemo una procedura memorizzata che conta e visualizza il numero di libri che sono attualmente in biblioteca:
CREATE Procedura Count_Ex1
- la procedura per contare il numero di copie di libri,
- attualmente in biblioteca,
- e non nelle mani dei lettori
come
- imposta la variabile locale temporanea
Dichiara @N int
Seleziona @N \u003d count (*) da Exemplar Where Yes_No \u003d "1"
Seleziona @N
GO
Poiché la procedura memorizzata è un componente di database completo, come già capito, è possibile creare una nuova procedura solo per il database corrente. Durante l'esecuzione in SQL Server Query Analyzer, il database corrente viene installato mediante l'istruzione Use, seguita dal nome del database in cui deve essere creata la procedura memorizzata. È inoltre possibile selezionare il database corrente utilizzando l'elenco a discesa.
Dopo aver creato una procedura memorizzata sul sistema, SQL Server la compila e controlla le routine in esecuzione. In caso di problemi, la procedura viene respinta. Gli errori devono essere corretti prima di ritrasmettere.
SQL Server 2000 utilizza la risoluzione dei nomi ritardata, quindi se la procedura memorizzata contiene una chiamata a un'altra procedura non ancora implementata, viene visualizzato un avviso, ma la chiamata alla procedura inesistente viene salvata.
Se si lascia il sistema con una procedura memorizzata non specificata, l'utente riceverà un messaggio di errore quando tenterà di eseguirlo.
È inoltre possibile creare una procedura memorizzata utilizzando SQL Server Enterprise Manager:
Per verificare l'operatività della procedura memorizzata creata, è necessario accedere a Query Analyzer e avviare la procedura per l'esecuzione da parte dell'operatore EXEC<имя процедуры> . I risultati del lancio della procedura da noi creata sono presentati in Fig. 4.

Fig. 4. Eseguire la procedura memorizzata in Query Analyzer

Fig. 5. Il risultato della procedura senza operatore schermo
1.3. Parametri della procedura memorizzata
Le procedure memorizzate sono uno strumento molto potente, ma la massima efficienza può essere raggiunta solo rendendole dinamiche. Lo sviluppatore dovrebbe essere in grado di passare valori alla procedura memorizzata con cui funzionerà, ovvero parametri. Di seguito sono riportate le linee guida di base per l'utilizzo dei parametri nelle stored procedure.
- È possibile definire uno o più parametri per la procedura.
- I parametri vengono utilizzati come posizioni di memorizzazione dei dati denominate, proprio come le variabili nei linguaggi di programmazione come C, Visual Basic .NET.
- Il nome del parametro è necessariamente preceduto dal simbolo @.
- I nomi dei parametri sono locali nella procedura in cui sono definiti.
- I parametri vengono utilizzati per trasmettere informazioni alla procedura durante la sua esecuzione. Rimangono bloccati sulla riga di comando dopo il nome della procedura.
- Se la procedura ha diversi parametri, sono separati da virgole.
- Per determinare il tipo di informazioni trasmesse come parametro, vengono utilizzati i tipi di dati di sistema o utente.
La seguente è una definizione di una procedura che ha un parametro di input. Cambieremo il compito precedente e considereremo non tutte le copie dei libri, ma solo le copie di un certo libro. I nostri libri sono identificati in modo univoco da un unico codice ISBN, quindi passeremo questo parametro alla procedura. In questo caso, il testo della procedura memorizzata cambierà e sarà simile al seguente:
Crea procedura Count_Ex (@ISBN varchar (14))
come
Dichiara @N int
Seleziona @N
GO
Quando si avvia questa procedura per l'esecuzione, è necessario passargli il valore del parametro di input (Fig. 6).

Fig. 6. Avvio della procedura con passaggio di un parametro
Per creare più versioni della stessa procedura con lo stesso nome, inserire un punto e virgola e un numero intero dopo il nome principale. Come fare questo è mostrato nel seguente esempio, che descrive la creazione di due procedure con lo stesso nome, ma con numeri di versione diversi (1 e 2). Il numero viene utilizzato per controllare la versione in esecuzione di questa procedura. Se non viene specificato un numero di versione, viene eseguita la prima versione della procedura. Questa opzione non è mostrata nell'esempio precedente, ma è comunque disponibile per l'applicazione.
Per stampare un messaggio che identifica la versione, entrambe le procedure utilizzano l'istruzione print. La prima versione considera il numero di copie gratuite, e la seconda - il numero di copie disponibili per questo libro.
Il testo di entrambe le versioni delle procedure è riportato di seguito:
CREATE Procedura Count_Ex_all; 1
(@ISBN varchar (14))
- procedura per contare le copie gratuite di un determinato libro
come
Dichiara @N int
Seleziona @N \u003d count (*) da Exemplar Where ISBN \u003d @ISBN e Yes_No \u003d "1"
Seleziona @N
--
GO
--
CREATE Procedura Count_Ex_all; 2
(@ISBN varchar (14))
- procedura per contare le copie gratuite di un determinato libro
come
Dichiara @ N1 int
Seleziona @ N1 \u003d count (*) da Exemplar Where ISBN \u003d @ISBN e Yes_No \u003d "0"
Seleziona @ N1
GO
I risultati della procedura con diverse versioni sono mostrati in Fig. 7.

Fig. 7. Risultati dell'esecuzione di versioni diverse della stessa procedura memorizzata
Quando si scrivono più versioni, è necessario ricordare le seguenti restrizioni: poiché tutte le versioni della procedura sono compilate insieme, tutte le variabili locali sono considerate comuni. Pertanto, se ciò è richiesto dall'algoritmo di elaborazione, è necessario utilizzare nomi diversi di variabili interne, cosa che abbiamo fatto nominando la variabile @N con il nome @ N1 nella seconda procedura.
Le procedure che abbiamo scritto non restituiscono un singolo parametro, ma visualizzano semplicemente il numero risultante. Tuttavia, molto spesso è necessario ottenere un parametro per un'ulteriore elaborazione. Esistono diversi modi per restituire i parametri da una procedura memorizzata. Il più semplice è usare l'operatore di ritorno RITORNO. Questo operatore restituirà un singolo valore numerico. Ma dobbiamo specificare il nome o l'espressione della variabile assegnata al parametro restituito. Di seguito sono riportati i valori restituiti dall'istruzione RETURN riservata dal sistema:
| codice | valore |
| 0 | Va tutto bene |
| 1 | Oggetto non trovato |
| 2 | Errore del tipo di dati |
| 3 | Il processo è diventato vittima di "Deadlock" |
| 4 | Errore di accesso |
| 5 | Errore di sintassi |
| 6 | Qualche errore |
| 7 | Errore con risorse (nessuno spazio) |
| 8 | Si è verificato un errore interno corretto |
| 9 | È stato raggiunto il limite di sistema. |
| 10 | Violazione fatale dell'integrità interna |
| 11 | Stessa cosa |
| 12 | Distruzione di tabella o indice |
| 13 | Distruzione del database |
| 14 | Errore hardware |
Pertanto, per non contraddire il sistema, possiamo restituire solo numeri interi positivi attraverso questo parametro.
Ad esempio, possiamo modificare il testo di una stored procedure Count_ex precedentemente scritta come segue:
Crea procedura Count_Ex2 (@ISBN varchar (14))
come
Dichiara @N int
Seleziona @N \u003d count (*) da Exemplar
Dove ISBN \u003d @ISBN e YES_NO \u003d "1"
- restituisce il valore della variabile @N,
- se il valore della variabile non è definito, restituisce 0
Coalesce di ritorno (@N, 0)
GO
Ora possiamo ottenere il valore della variabile @N e usarlo per ulteriori elaborazioni. In questo caso, il valore restituito viene assegnato alla procedura memorizzata stessa e per analizzarlo è possibile utilizzare il seguente formato dell'operatore di chiamata della procedura memorizzata:
Exec<переменная> = <имя_процедуры> <значение_входных_параметров>
Un esempio di chiamata alla nostra procedura è mostrato in Fig. 8.

Fig. 8. Passaggio del valore restituito della procedura memorizzata a una variabile locale
I parametri di input per le stored procedure possono utilizzare il valore predefinito. Questo valore verrà utilizzato se il valore del parametro non è stato specificato durante la chiamata della procedura.
Il valore predefinito viene specificato tramite il segno di uguale dopo la descrizione del parametro di input e del suo tipo. Si consideri una procedura memorizzata che conta il numero di copie di libri di un determinato anno di rilascio. L'anno di rilascio predefinito è il 2006.
CREATE PROCEDURE ex_books_now (@year int \u003d 2006)
- contare il numero di copie di libri di un determinato anno di uscita
AS
Dichiara @N_books int
seleziona @N_books \u003d count (*) dai libri, esempio
dove Books.ISBN \u003d exemplar.ISBN e YEARIZD \u003d @year
coalesce di ritorno (@N_books, 0)
GO
In fig. La Figura 9 mostra un esempio di chiamata a questa procedura con e senza un parametro di input.

Fig. 9. Richiamo di una procedura memorizzata con e senza un parametro
Tutti gli esempi precedenti sull'uso dei parametri nelle stored procedure hanno fornito solo parametri di input. Tuttavia, i parametri possono essere emessi. Ciò significa che il valore del parametro dopo il completamento della procedura verrà trasferito a chi ha chiamato questa procedura (a un'altra procedura, trigger, pacchetto di comandi, ecc.). Naturalmente, al fine di ottenere il parametro di output, quando si chiama, è necessario specificare non una costante, ma una variabile come parametro effettivo.
Si noti che la definizione di un parametro come output in una procedura non obbliga a usarlo come tale. Cioè, se si specifica una costante come parametro effettivo, non si verificherà alcun errore e verrà utilizzata come parametro di input normale.
L'istruzione OUTPUT viene utilizzata per indicare che il parametro è in uscita. Questa parola chiave è scritta dopo la descrizione del parametro. Quando si descrivono i parametri delle stored procedure, è preferibile impostare i valori dei parametri di output dopo l'input.
Prendi in considerazione un esempio usando i parametri di output. Scriveremo una procedura memorizzata che per un determinato libro calcola il numero totale di copie nella libreria e il numero di copie gratuite. Non è possibile utilizzare qui l'operatore di ritorno RITORNO, poiché restituisce solo un valore, quindi è necessario definire qui i parametri di output. Il testo della stored procedure potrebbe essere simile al seguente:
CREATE Procedura Count_books_all
(@ISBN varchar (14), @all int output, @free int output)
- procedura per il calcolo del numero totale di copie di un determinato libro
- e il numero di copie gratuite
come
- calcolo del numero totale di copie
Seleziona @all \u003d count (*) da Exemplar Where ISBN \u003d @ISBN
Seleziona @free \u003d count (*) da Exemplar dove ISBN \u003d @ISBN e Yes_No \u003d "1"
GO
Un esempio di questa procedura è mostrato in Fig. 10.

Fig. 10. Test di una procedura memorizzata con parametri di output
Come accennato in precedenza, al fine di ottenere i valori dei parametri di output per l'analisi, dobbiamo impostarli come variabili e queste variabili devono essere descritte dall'operatore Declare. L'ultima istruzione di output ci ha permesso di visualizzare semplicemente i valori risultanti.
I parametri della procedura possono anche essere variabili del tipo Cursore. Per questo, la variabile deve essere descritta come uno speciale tipo di dati VARYING, senza riferimento ai tipi di dati di sistema standard. Inoltre, è necessario indicare che si tratta di una variabile di tipo Cursore.
Scriveremo la procedura più semplice che visualizza un elenco di libri nella nostra biblioteca. Inoltre, se non ci sono più di tre libri, visualizziamo i loro nomi nel quadro della procedura stessa e se l'elenco dei libri supera un numero specificato, li trasferiamo sotto forma di cursore sul programma o modulo chiamante.
Il testo della procedura è il seguente:
CREA PROCEDURA GET3TITLES
(@MYCURSOR CURSOR VARIAZIONE USCITA)
- procedura per la stampa di titoli di libri con un cursore
AS
- definire una variabile locale di tipo Cursore nella procedura
SET @MYCURSOR \u003d CURSOR
PER SELEZIONARE IL TITOLO DISTINCT
DAI LIBRI
- apri il cursore
APERTO @MYCURSOR
- descriviamo le variabili locali interne
DECLARE @TITLE VARCHAR (80), @CNT INT
--- imposta lo stato iniziale del contatore del libro
SET @CNT \u003d 0
- vai alla prima riga del cursore
- mentre ci sono linee del cursore,
- cioè, mentre la transizione verso una nuova linea è corretta
WHILE (@@ FETCH_STATUS \u003d 0) AND (@CNT<= 2) BEGIN
STAMPA @TITLE
PASSA SUCCESSIVO DA @MYCURSOR IN @TITLE
- cambia lo stato del contatore del libro
SET @CNT \u003d @CNT + 1
END
SE @CNT \u003d 0 STAMPA "NESSUN LIBRO ADATTO"
GO
Un esempio di chiamata a questa procedura memorizzata è mostrato in Fig. 11.

Nella procedura di chiamata, il cursore deve essere descritto come una variabile locale. Quindi abbiamo chiamato la nostra procedura e le abbiamo passato il nome di una variabile locale di tipo Cursore. La procedura ha iniziato a funzionare e ha visualizzato i primi tre nomi sullo schermo, quindi ha trasferito il controllo alla procedura di chiamata e ha continuato a elaborare il cursore. Per fare ciò, ha organizzato un ciclo di tipo While sulla variabile globale @@ FETCH_STATUS, che tiene traccia dello stato del cursore, e quindi nel ciclo ha visualizzato tutte le altre linee del cursore.
Nella finestra di output, vediamo un intervallo aumentato tra le prime tre righe e i nomi successivi. Questo intervallo mostra solo che il controllo viene trasferito a un programma esterno.
Si noti che la variabile @TITLE, essendo locale alla procedura, verrà distrutta dopo il suo completamento, pertanto viene nuovamente dichiarata nel blocco che chiama la procedura. La creazione e l'apertura del cursore in questo esempio si verificano nella procedura e la chiusura, la distruzione e l'elaborazione aggiuntiva vengono eseguite nel blocco comandi in cui viene chiamata la procedura.
Il modo più semplice è visualizzare il testo della procedura, modificarlo o eliminarlo utilizzando l'interfaccia grafica di Enterprise Manager. Ma puoi farlo con le stored procedure di sistema speciali Transact-SQL. In Transact-SQL, la definizione della procedura viene visualizzata utilizzando la procedura di sistema sp_helptext e la procedura di sistema sp_help consente di visualizzare informazioni di controllo sulla procedura. Le routine di sistema sp_helptext e sp_help vengono anche utilizzate per visualizzare oggetti di database come tabelle, regole e impostazioni predefinite.
Le informazioni su tutte le versioni di una procedura, indipendentemente dal numero, vengono visualizzate immediatamente. L'eliminazione di versioni diverse della stessa procedura memorizzata si verifica contemporaneamente. L'esempio seguente mostra come vengono visualizzate le definizioni delle versioni 1 e 2 della procedura Count_Ex_all quando il suo nome viene specificato come parametro della procedura di sistema sp_helptext (Fig. 12).

Fig. 12. Visualizzazione del testo della procedura memorizzata utilizzando una procedura memorizzata dal sistema
La procedura di sistema SP_HELP visualizza le caratteristiche e i parametri della procedura creata nel seguente formato:
|
Created_datetime | |||||
|
2006-12-06 23:15:01.217 | |||||
|
scala | Fascicolazione Param_order | ||||
|
NULL | 1 | Cyrillic_General_CI_AS | |||
|
0 | 2 | NULL | |||
|
0 | 3 | NULL | |||
Prova a decrittografare questi parametri da solo. Di cosa stanno parlando?
1.4. Compilare una procedura memorizzata
Il vantaggio dell'utilizzo di stored procedure per eseguire un set di istruzioni Transact-SQL è che vengono compilate alla prima esecuzione. Durante la compilazione, le istruzioni Transact-SQL vengono convertite dalla loro rappresentazione originale in forma eseguibile. Anche gli oggetti a cui si accede nella procedura vengono convertiti in una rappresentazione alternativa. Ad esempio, i nomi delle tabelle vengono convertiti in identificatori di oggetti e i nomi di colonna in identificatori di colonna.
Un piano di esecuzione viene creato come per l'esecuzione di una singola istruzione Transact-SQL. Questo piano contiene, ad esempio, indici utilizzati per leggere le righe dalle tabelle a cui accede la procedura. Il piano di esecuzione della procedura viene archiviato nella cache e viene utilizzato ogni volta che viene chiamato.
Nota: la dimensione della cache delle procedure può essere determinata in modo che possa contenere la maggior parte o tutte le procedure disponibili per l'esecuzione. Ciò consente di risparmiare il tempo necessario per rigenerare il piano di trattamento.
1.5. Ricompilazione automatica
In genere, il piano di esecuzione si trova nella cache delle procedure. Ciò consente di aumentare le prestazioni quando viene eseguita. Tuttavia, in alcune circostanze, la procedura viene ricompilata automaticamente.
- La procedura viene sempre ricompilata all'avvio di SQL Server. Ciò si verifica in genere dopo il riavvio del sistema operativo e durante la prima esecuzione della procedura dopo la creazione.
- Il piano di esecuzione di una procedura viene sempre ricompilato automaticamente se l'indice della tabella a cui fa riferimento la procedura viene eliminato. Poiché il piano corrente fa riferimento a un indice della tabella che non esiste già, è necessario creare il nuovo piano di esecuzione. Le richieste per la procedura verranno eseguite solo se viene aggiornato.
- La compilazione del piano di esecuzione si verifica anche se un altro utente sta attualmente lavorando con questo piano di cache. Viene creata una singola copia del piano di esecuzione per il secondo utente. Se la prima copia del piano non fosse stata presa, non sarebbe stato necessario crearne una seconda. Quando l'utente completa la procedura, il piano di esecuzione è disponibile nella cache per un altro utente con l'autorizzazione di accesso appropriata.
- La procedura viene ricompilata automaticamente se viene eliminata e ricreata. Poiché la nuova procedura può differire dalla versione precedente, tutte le copie del piano di esecuzione nella cache vengono eliminate e il piano viene nuovamente compilato.
SQL Server mira a ottimizzare le stored procedure memorizzando nella cache le procedure più utilizzate. Pertanto, al posto del nuovo piano è possibile utilizzare il vecchio piano di esecuzione caricato nella cache. Per evitare questo problema, è necessario eliminare e ricreare la procedura memorizzata oppure arrestare e riattivare SQL Server. Ciò cancellerà la cache delle procedure ed eliminerà la possibilità di lavorare con il vecchio piano di esecuzione.
È inoltre possibile creare una procedura con l'opzione WITH RECOMPILE. In questo caso, verrà automaticamente ricompilato ad ogni esecuzione. L'opzione WITH RECOMPILE dovrebbe essere utilizzata nei casi in cui la procedura accede a tabelle molto dinamiche le cui righe vengono spesso aggiunte, eliminate o aggiornate, poiché ciò porta a cambiamenti significativi negli indici definiti per le tabelle.
Se la procedura non viene ricompilata automaticamente, può essere forzata. Ad esempio, se le statistiche utilizzate per determinare se l'indice può essere utilizzato in questa query vengono aggiornate o se viene creato un nuovo indice, è necessario eseguire una ricompilazione forzata. Per forzare una ricompilazione, l'istruzione EXECUTE utilizza la clausola WITH RECOMPILE:
EXECUTE procedure_name;
AS
<инструкции Transact-SQL>
CON RICOMPILE
Se la procedura funziona con parametri che controllano l'ordine della sua esecuzione, utilizzare l'opzione WITH RECOMPILE. Se i parametri della procedura memorizzata sono in grado di determinare il modo migliore per eseguirla, si consiglia di creare un piano di esecuzione nel processo di lavoro e di non crearlo quando si chiama la procedura per la prima volta da utilizzare in tutte le chiamate successive.
Nota: a volte è difficile determinare se utilizzare l'opzione WITH RECOMPILE durante la creazione di una procedura o meno. In caso di dubbio, è meglio non utilizzare questa opzione, poiché la ricompilazione della procedura ad ogni esecuzione comporterà la perdita di tempo CPU molto prezioso. Se in futuro è necessario ricompilare quando si esegue la procedura memorizzata, è possibile farlo aggiungendo la clausola WITH RECOMPILE all'istruzione EXECUTE.
Non è possibile utilizzare l'opzione WITH RECOMPILE in un'istruzione CREATE PROCEDURE contenente l'opzione FOR REPLICATION. Questa opzione viene utilizzata per creare una procedura che viene eseguita durante il processo di replica.
1.6. Nidificazione di stored procedure
Nelle stored procedure è possibile richiamare altre stored procedure, tuttavia esiste una limitazione al livello di annidamento. Il livello massimo di annidamento è 32. L'attuale livello di annidamento può essere determinato utilizzando la variabile globale @@ NESTLEVEL.
2. Funzioni definite dall'utente (UDF)
In MS SQL SERVER 2000, ci sono molte funzioni predefinite che consentono di eseguire una varietà di azioni. Tuttavia, potrebbe essere sempre necessario utilizzare alcune funzioni specifiche. Per questo, a partire dalla versione 8.0 (2000), è diventato possibile descrivere le funzioni definite dall'utente (User Defined Functions, UDF) e memorizzarle come oggetto di database completo, insieme a stored procedure, viste, ecc.
L'usabilità delle funzioni definite dall'utente è ovvia. A differenza delle procedure memorizzate, le funzioni possono essere incorporate direttamente nell'istruzione SELECT e utilizzarle entrambe per ottenere valori specifici (nella sezione SELECT) e come origine dati (nella sezione FROM).
Quando si utilizza UDF come origini dati, il vantaggio rispetto alle rappresentazioni è che UDF, a differenza delle rappresentazioni, può avere parametri di input che possono essere utilizzati per influenzare il risultato della funzione.
Le funzioni definite dall'utente possono essere di tre tipi: funzioni scalari, funzioni incorporate e funzioni multi-operatore che restituiscono un risultato di tabella. Consideriamo tutti questi tipi di funzioni in modo più dettagliato.
2.1. Funzioni scalari
Le funzioni scalari restituiscono un singolo risultato scalare. Questo risultato può essere di qualsiasi tipo sopra descritto, ad eccezione dei tipi text, ntext, image e timestamp. Questo è il tipo più semplice di funzione. La sua sintassi è la seguente:
RESI tipo_data scalare
BEGIN
telo_funktsii
INVIO scalar_expression
END
- Il parametro ENCRYPTION è già stato descritto nella sezione sulle procedure memorizzate;
- SCHEMABINDING - Associa una funzione a uno schema. Ciò significa che non sarà possibile eliminare le tabelle o le viste in base alle quali viene creata la funzione senza eliminare o modificare la funzione stessa. Non è inoltre possibile modificare la struttura di queste tabelle se la parte variabile viene utilizzata dalla funzione. Pertanto, questa opzione consente di escludere situazioni in cui la funzione utilizza alcune tabelle o viste e qualcuno, non conoscendola, le ha cancellate o modificate;
- RESI tipo_data scalare - descrive il tipo di dati restituiti dalla funzione;
- skalyarnoe_vyrazhenie - un'espressione che restituisce direttamente il risultato della funzione. Deve essere dello stesso tipo di quello descritto dopo RESI;
- function_body è un insieme di istruzioni Transact-SQL.
Consideriamo esempi di utilizzo di funzioni scalari.
Creare una funzione che selezionerà il più piccolo dei due numeri interi immessi nell'input come parametri.
Lascia che la funzione assomigli a questo:
CREATE FUNCTION min_num (@a INT, @b INT)
RESI INT
BEGIN
DECLARE @c INT
IF @a< @b SET @c = @a
ELSE SET @c \u003d @b
Ritorna @c
END
Eseguiamo questa funzione:
SELEZIONA dbo.min_num (4, 7)
Di conseguenza, otteniamo il valore 4.
È possibile utilizzare questa funzione per trovare il più piccolo tra i valori della colonna della tabella:
SELEZIONA min_lvl, max_lvl, min_num (min_lvl, max_lvl)
DA Jobs
Creiamo una funzione che riceverà un parametro di tipo datetime come input e restituirà la data e l'ora corrispondenti all'inizio del giorno specificato. Ad esempio, se il parametro di input è 20/09/03 13:31, il risultato sarà 20/09/03 00:00.
CREA FUNZIONE dbo.daybegin (@dat DATETIME)
RESI smalldatetime AS
BEGIN
INVIO RITORNO (datetime, FLOOR (convert (FLOAT, @dat)))
END
Qui, la funzione CONVERT esegue la conversione del tipo. Innanzitutto, il tipo di data e ora viene trasmesso al tipo FLOAT. Con tale riduzione, la parte intera è il numero di giorni che contano dal 1 ° gennaio 1900 e la parte frazionaria è il tempo. Quindi l'arrotondamento su un numero intero più piccolo si verifica utilizzando la funzione FLOOR e il cast su un tipo data-ora.
Controlla l'azione della funzione:
SELEZIONA dbo.daybegin (GETDATE ())
Qui GETDATE () è una funzione che restituisce la data e l'ora correnti.
Le funzioni precedenti utilizzavano solo i parametri di input nel calcolo. Tuttavia, è possibile utilizzare i dati memorizzati nel database.
Creiamo una funzione che prenderà due date come parametri: l'inizio e la fine dell'intervallo di tempo - e calcoliamo le entrate totali delle vendite per questo intervallo. La data e la quantità delle vendite saranno prese dalla tabella Vendite, mentre i prezzi delle pubblicazioni vendute saranno presi dalla tabella Titoli.
CREATE FUNCTION dbo.SumSales (@datebegin DATETIME, @dateend DATETIME)
RESI Denaro
AS
BEGIN
DECLARE @Sum Money
SELEZIONA @Sum \u003d sum (t.price * s.qty)
RITORNO @Sum
END
2.2. Funzioni integrate
Questo tipo di funzione restituisce di conseguenza non un valore scalare, ma una tabella o piuttosto un set di dati. Ciò può essere molto utile nei casi in cui lo stesso tipo di subquery viene spesso eseguito in procedure, trigger diversi, ecc. Quindi, invece di scrivere questa query ovunque, è possibile creare una funzione e utilizzarla in un secondo momento.
Funzioni di questo tipo sono ancora più utili nei casi in cui è necessario che la tabella restituita dipenda dai parametri di input. Come sapete, le viste non possono avere parametri, quindi solo le funzioni incorporate possono risolvere questo tipo di problema.
Una caratteristica delle funzioni incorporate è che possono contenere solo una richiesta nel loro corpo. Pertanto, funzioni di questo tipo sono molto simili alle rappresentazioni, ma possono inoltre avere parametri di input. Sintassi della funzione integrata:
CREATE FUNCTION [proprietario.] Nome_funzione
([(@ parametro_name scalar_ data_type [\u003d default_value]) [, ... n]])
TABELLA DI RESI
RITORNO [(<запрос>)]
La definizione della funzione indica che restituirà una tabella;<запрос> - questa è la query il cui risultato di esecuzione sarà il risultato della funzione.
Scriveremo una funzione simile alla funzione scalare dell'ultimo esempio, ma restituendo non solo un risultato sommario, ma anche linee di vendita, tra cui la data di vendita, il nome del libro, il prezzo, il numero di pezzi e l'ammontare della vendita. Dovrebbero essere selezionate solo le vendite che rientrano in un determinato periodo di tempo. Crittografiamo il testo della funzione in modo che altri utenti possano utilizzarlo, ma non possano leggerlo e correggerlo:
CREATE FUNCTION Sales_Period (@datebegin DATETIME, @dateend DATETIME)
TABELLA DI RESI
CON ENCRYPTION
AS
RITORNO (
SELEZIONA t.title, t.price, s.qty, ord_date, t.price * s.qty come stoim
DA Titoli t ISCRIVITI Vendite s ON t.title_Id \u003d s.Title_ID
DOVE ord_date TRA @datebegin e @dateend
)
Ora chiama questa funzione. Come già accennato, puoi chiamarlo solo nella sezione FROM dell'istruzione SELECT:
SELEZIONA * DA Sales_Period ("01.09.94", "13.09.94")
2.3. Funzioni multi-operatore che restituiscono un risultato di tabella
Il primo tipo di funzione considerata ci ha permesso di utilizzare quante più istruzioni possibili in Transact-SQL, ma ha restituito solo il risultato scalare. Il secondo tipo di funzione potrebbe restituire tabelle, ma il suo corpo rappresenta solo una query. Le funzioni multi-operatore che restituiscono un risultato di una tabella consentono di combinare le proprietà delle prime due funzioni, ovvero possono contenere molte istruzioni Transact-SQL nel corpo e restituire una tabella come risultato. La sintassi della funzione multioperatore:
CREATE FUNCTION [proprietario.] Nome_funzione
([(@ parametro_name scalar_ data_type [\u003d default_value]) [, ... n]])
RITORNI @ result_variable_name TABELLA
<описание_таблицы>
BEGIN
<тело_функции>
RITORNO
END
- TABELLA<описание_таблицы> - descrive la struttura della tabella restituita;
- <описание_таблицы> - contiene un elenco di colonne e restrizioni.
Consideriamo ora un esempio che può essere eseguito solo utilizzando funzioni di questo tipo.
Lascia che ci sia un albero di directory e i file in esse contenuti. Lascia che questa intera struttura sia descritta nel database sotto forma di tabelle (Fig. 13). In effetti, qui abbiamo una struttura gerarchica per le directory, quindi il diagramma mostra la relazione della tabella Cartelle con se stessa.

Fig. 13. Struttura del database per la descrizione della gerarchia di file e directory
Ora scriviamo una funzione che prenderà un identificatore di directory all'ingresso e mostrerà tutti i file che sono memorizzati in esso e in tutte le directory nella gerarchia. Ad esempio, se i cataloghi dell'istituto hanno creato le directory Faculty1, Faculty2, ecc., Contengono le directory dei dipartimenti e ogni directory contiene i file, quindi quando si specifica l'ID Institute come parametro della nostra funzione, un elenco di tutti i file per tutti queste directory. Per ogni file, devono essere visualizzati il \u200b\u200bnome, la dimensione e la data di creazione.
È impossibile risolvere il problema utilizzando la funzione inline, poiché SQL non è progettato per eseguire query gerarchiche, quindi non è necessario eseguire una sola query SQL. Neanche la funzione scalare può essere applicata, poiché il risultato deve essere una tabella. Qui verremo in soccorso e troveremo una funzione multi-operatore che restituisce una tabella:
CREA FUNZIONE dbo.GetFiles (@Folder_ID int)
RETURNS @files TABLE (Nome VARCHAR (100), Date_Create DATETIME, FileSize INT) AS
BEGIN
DECLARE @tmp TABLE (Folder_Id int)
DECLARE @Cnt INT
INSERT INTO @tmp valori (@Folder_ID)
SET @Cnt \u003d 1
MENTRE @Cnt<> 0 INIZIA
INSERISCI IN @tmp SELECT Folder_Id
FROM Cartelle f JOIN @tmp t ON f.parent \u003d t.Folder_ID
DOVE F.id NON IN (SELEZIONA Folder_ID FROM @tmp)
SET @Cnt \u003d @@ ROWCOUNT
END
INSERT INTO @Files (Name, Date_Create, FileSize)
SELECT F.Name, F.Date_Create, F.FileSize
File FROM f UNISCITI Cartelle Fl on f.Folder_id \u003d Fl.id
ISCRIVITI @tmp t su Fl.id \u003d t.Folder_Id
RITORNO
END
Qui, in un ciclo, tutte le sottodirectory a tutti i livelli di annidamento vengono aggiunte alla variabile @tmp fino a quando non rimangono più sottodirectory. Quindi, tutti gli attributi necessari dei file che si trovano nelle directory elencate nella variabile @tmp vengono scritti nella variabile di risultato @Files.
Compiti per lavoro indipendente
È necessario creare ed eseguire il debug di cinque procedure memorizzate dal seguente elenco richiesto:
Procedura 1. Aumentare la scadenza per la consegna delle copie del libro di una settimana se la scadenza corrente è compresa tra tre giorni e la data corrente a tre giorni dopo la data corrente.
Procedura 2. Conteggio del numero di copie gratuite di un determinato libro.
Procedura 3. Verifica dell'esistenza di un lettore con un dato cognome e data di nascita.
Procedura 4. Inserimento di un nuovo lettore con verifica della sua esistenza nel database e determinazione del suo nuovo numero di tessera della biblioteca.
Procedura 5. Calcolo dell'ammenda in termini monetari per i lettori-debitori.
Breve descrizione delle procedure
Procedura 1. Proroga della scadenza per i libri
Per ogni voce nella tabella Exemplar, viene verificato se la data di consegna del libro rientra nell'intervallo di tempo specificato. In tal caso, la data di ritorno del libro viene aumentata di una settimana. Quando si esegue la procedura, è necessario utilizzare la funzione per lavorare con le date:
DateAdd (giorno,<число добавляемых дней>, <начальная дата>)
Procedura 2. Conteggio del numero di copie gratuite di un determinato libro
Il parametro di input per la procedura è ISBN, un codice univoco del libro. La procedura restituisce 0 (zero) se tutte le copie di questo libro sono nelle mani dei lettori. La procedura restituisce un valore N pari al numero di copie di libri che sono attualmente nelle mani dei lettori.
Se il libro con il codice ISBN specificato non è nella libreria, la procedura restituisce –100 (meno cento).
Procedura 3. Verifica dell'esistenza di un lettore con un dato cognome e data di nascita
La procedura restituisce un numero di tessera della biblioteca se esiste un lettore con tali dati e 0 (zero) in caso contrario.
Quando si confronta la data di nascita, è necessario utilizzare la funzione di conversione Convert () per convertire la data di nascita - una variabile di carattere di tipo Varchar (8), utilizzata come parametro di input della procedura, in dati di tipo datatime, che vengono utilizzati nella tabella Readers. Altrimenti, l'operazione di confronto durante la ricerca di questo lettore non funzionerà.
Procedura 4. Immissione di un nuovo lettore
La procedura ha cinque parametri di input e tre di output.
Parametri di input:
- Nome completo con iniziali;
- indirizzo;
- Data di nascita;
- Telefono di casa;
- Il telefono funziona.
Parametri di uscita:
- Numero della tessera della biblioteca;
- Un segno di se il lettore era stato precedentemente registrato nella libreria (0 - non era, 1 - era);
- Il numero di libri che sono elencati dal lettore.
Procedura 5. Calcolo dell'ammenda in termini monetari per i lettori debitori
La procedura funziona con un cursore che contiene un elenco di numeri di tessere della biblioteca di tutti i debitori. Nel processo di lavoro, dovrebbe essere creata una tabella temporanea globale ## DOLG, in cui per ciascun debitore verrà inserito il suo debito totale in termini monetari per tutti i libri che ha detenuto per un lungo periodo di rendimento. La compensazione in contanti è calcolata allo 0,5% del prezzo per libro per il giorno di ritardo.
Ordine di lavoro

- copie di schermate (schermate) che confermano le modifiche apportate al database;
- il contenuto delle tabelle del database necessarie per confermare il corretto funzionamento;
- testo della procedura memorizzata con commenti;
- il processo di avvio di una procedura memorizzata con l'output del lavoro.
Compiti aggiuntivi
Le seguenti procedure memorizzate aggiuntive sono per singole attività.
Procedura 6. Conteggio del numero di libri in una determinata area tematica che sono attualmente nella biblioteca in almeno una copia. L'area tematica viene passata come parametro di input.
Procedura 7. Inserire un nuovo libro che indica il numero di copie. Quando si inseriscono copie di un nuovo libro, non dimenticare di inserire i numeri di inventario corretti. Pensa a come farlo. Ti ricordo che hai funzioni Max e Min che ti consentono di trovare il valore massimo o minimo di qualsiasi attributo numerico usando lo strumento Seleziona query.
Procedura 8. Formare una tabella con un elenco di lettori debitori, cioè quelli che avrebbero dovuto restituire libri in biblioteca, ma non sono ancora tornati. Nella tabella risultante, ogni lettore di debitori dovrebbe apparire una sola volta, indipendentemente da quanti libri deve. Oltre al nome completo e al numero della tessera della biblioteca nella tabella risultante, è necessario specificare l'indirizzo e il numero di telefono.
Procedura 9. Cercare una copia gratuita per un determinato titolo di libro. Se esiste un'istanza libera, la procedura restituisce il numero di inventario dell'istanza; in caso contrario, la procedura restituisce un elenco di lettori che dispongono di questo libro, indicando la data di restituzione del libro e il numero di telefono del lettore.
Procedura 10. Elencare i lettori che al momento non tengono in mano un singolo libro. Nell'elenco indicare il nome e il numero di telefono.
Procedura 11. Visualizzazione di un elenco di libri che indica il numero di copie di questo libro nella biblioteca e il numero di copie gratuite al momento.
Versione di stampa
In questo tutorial imparerai come creare ed eliminare le procedure in SQL Server (Transact-SQL) con sintassi ed esempi.
descrizione
In SQL Server, una procedura è un programma memorizzato in cui è possibile passare parametri. Non restituisce un valore come funzione. Tuttavia, può riportare lo stato di esito positivo / negativo alla procedura che lo ha causato.
Creare una procedura
È possibile creare le proprie procedure memorizzate in SQL Server (Transact-SQL). Diamo un'occhiata più da vicino.
sintassi
Sintassi delle procedure in SQL Server (Transact-SQL):
CREATE (PROCEDURE | PROC) nome_procedura
[@parameter datatype
[VARYING] [\u003d default] [OUT | USCITA | READONLY]
, @parameter tipo di dati
[VARYING] [\u003d default] [OUT | USCITA | READONLY]]
[WITH (ENCRYPTION | RECOMPILE | EXECUTE AS Clause)]
[PER LA REPLICAZIONE]
AS
BEGIN
executable_section
END;
Parametri o argomenti
schema_name è il nome dello schema a cui appartiene la procedura memorizzata.
procedure_name è il nome a cui assegnare questa procedura in SQL Server.
@parametro: uno o più parametri vengono passati alla procedura.
type_schema_name è uno schema che possiede un tipo di dati, se applicabile.
Tipo di dati è il tipo di dati per @parameter.
VARYING - impostato per i parametri del cursore quando il set di risultati è un parametro di output.
default - il valore predefinito da assegnare al parametro @parameter.
OUT: significa che @parameter è il parametro di output.
OUTPUT - questo significa che @parameter è il parametro di output.
READONLY - questo significa che @parameter non può essere sovrascritto da una procedura memorizzata.
ENCRYPTION: ciò significa che l'origine della procedura memorizzata non verrà salvata come testo normale nelle viste di sistema di SQL Server.
RICOMPILE: ciò significa che il piano di query non verrà memorizzato nella cache per questa procedura memorizzata.
ESEGUI AS: imposta il contesto di sicurezza per l'esecuzione della procedura memorizzata.
PER LA RISPOSTA - Ciò significa che la procedura memorizzata viene eseguita solo durante la replica.
esempio
Si consideri l'esempio della creazione di una procedura memorizzata in SQL Server (Transact-SQL).
Di seguito è riportata una semplice procedura di esempio:
Transact-SQL
CREA PROCEDURA TrovaSite @nome_sito VARCHAR (50) OUT COME INIZIA DECLARE @site_id INT; SET @site_id \u003d 8; IF @site_id< 10 SET @site_name = "yandex.com"; ELSE SET @site_name = "google.com"; END;
CREA PROCEDURA FindSite @ nome_sito VARCHAR (50) OUT BEGIN DECLARE @ site_id INT; SET @ site_id \u003d 8; IF @ site_id< 10 SET @ site_name \u003d "yandex.com"; ELSE SET @ site_name \u003d "google.com"; END; |
Questa procedura si chiama FindSite. Ha un parametro chiamato @site_name, che è un parametro di output che viene aggiornato in base alla variabile @site_id.
È quindi possibile fare riferimento alla nuova procedura memorizzata denominata FindSite come segue.