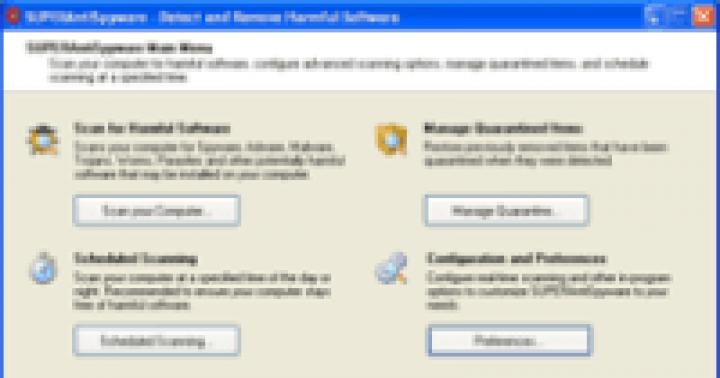
PHP regexp — это мощный алгоритм сопоставления шаблонов, которое может быть выполнено в одном выражении. Регулярные выражения PHP используют арифметические операторы (такие как +, -, ^ ) для создания сложных выражений.
Для чего используются регулярные выражения:
- Регулярные выражения упрощают идентификацию строковых данных путем вызова одной функции. Это экономит время при составлении кода;
- При проверке введенных пользователем данных, таких как адрес электронной почты, домен сайта, номер телефона, IP-адрес ;
- Выделение ключевых слов в результатах поиска;
- Регулярные выражения могут использоваться для идентификации тегов и их замены.
Регулярные выражения в PHP
PHP содержит встроенные функции, которые позволяют работать с регулярными выражениями. Теперь рассмотрим часто используемые функции регулярных выражений PHP .
- preg_match — используется для выполнения сопоставления с шаблоном строки. Она возвращает true , если совпадение найдено, и false , если совпадение не найдено;
- preg_split — используется для разбивки строки по шаблону, результат возвращается в виде числового массива;
- preg_replace – используется для поиска по шаблону и замены на указанную строку.
Ниже приведен синтаксис функций регулярных выражений, таких как preg_match , preg_split или PHP regexp replace :
«имя_функции»
— это либо preg_match
, либо preg_split
, либо preg_replace
.
«/…/»
— косые черты обозначают начало и конец регулярного выражения.
«‘/шаблон/"»
— шаблон, который нам нужно сопоставить.
«объект»
— строка, с которой нужно сопоставлять шаблон.
Теперь рассмотрим практические примеры использования упомянутых выше функций.
Preg_match
В первом примере функция preg_match используется для выполнения простого сопоставления шаблоном для слова guru в заданном URL-адресе .
В приведенном ниже коде показан вариант реализации данного примера:
Рассмотрим ту часть кода, которая отвечает за вывод «preg_match (‘/ guru /’, $ my_url)» .
«preg_match(…)»
— функция PHP match regexp
.
«‘/Guru/"»
— шаблон регулярного выражения.
«$My_url»
— переменная, содержащая текст, с которым нужно сопоставить шаблон.
Preg_split
Рассмотрим другой пример, в котором используется функция preg_split .
Мы возьмем фразу и разобьем ее на массив; шаблон предназначен для поиска единичного пробела:
Preg_replace
Рассмотрим функцию preg_replace , которая выполняет сопоставление с шаблоном и заменяет найденный результат другой строкой.
Приведенный ниже код ищет в строке слово guru . Он заменяет его кодом css , который задает цвет фона:
Guru", $text); echo $text; ?>
Метасимволы
В приведенных выше примерах использовались простые шаблоны. Метасимволы позволяют выполнять более сложные сопоставления шаблонов PHP regexp , такие как проверка адреса электронной почты. Рассмотрим часто используемые метасимволы.
| Метасимвол | Описание | Пример |
| . | Обозначает любой единичный символ, кроме символа новой строки. | /./ — все, что содержит один символ. |
| ^ | Обозначает начало строки, не включая символ /. | /^PH/ — любая строка, которая начинается с PH. |
| $ | Обозначает шаблон в конце строки. | /com$/ — guru99.com,yahoo.com и т.д. |
| * | Обозначает любое количество символов, ноль или больше. | /com*/ — computer, communication и т.д. |
| + | Требуется вхождение перед метасимволом символа (ов) хотя бы один раз. | /yah+oo/ — yahoo. |
| Символ экранирования. | /yahoo+.com/ — воспринимает точку, как дословное значение. | |
| […] | Класс символов. | // — abc. |
| a-z | Обозначает строчные буквы. | /a-z/ — cool, happy и т.д. |
| A-Z | Обозначает заглавные буквы. | /A-Z/ — WHAT, HOW, WHY и т.д. |
| 0-9 | Обозначает любые цифры от 0 до 9. | /0-4/ — 0,1,2,3,4. |
Теперь рассмотрим сложный PHP regexp пример, в котором проверяется валидность адреса электронной почты:
Результат: адрес электронной почты [email protected] является валидным.
Пояснение шаблона «+@+.{2,5}$/] «
«‘/…/"»
начинает и завершает регулярное выражение.
«^»
соответствует любым буквам в нижнем или верхнем регистре, цифрам от 0 до 9 и точкам, подчеркиваниям или тире.
«+@»
соответствует символу @
, за которым следуют буквы в нижнем или верхнем регистре, цифры от 0 до 9 или дефисы.
«+.{2,5}$/»
указывает точку, используя обратную косую черту, затем должны следовать любые буквы в нижнем или верхнем регистре, количество символов в конце строки должно быть от 2 до 5.
Регулярные выражения — очень полезный инструмент для разработчиков. Регулярные выражения позволяют проверять правильность текста, искать и изменять его.
В этой статье собраны некоторые очень полезные выражения, с которыми часто приходится работать.
Введение в регулярные выражения
При первом знакомстве с регулярными выражениями может показаться, что их сложно понять и применять. На самом деле все проще, чем кажется. Перед тем как приступить к рассмотрению сложных примеров, разберем основы:
Функции для работы с регулярными выражениями в PHP
Проверка домена
Проверка на правильное доменное имя.
$url = "http://example.com/"; if (preg_match("/^(http|https|ftp)://(*(?:.*)+):?(d+)?/?/i", $url)) { echo "Ok."; } else { echo "Wrong url."; }
Подсветка слов в тексте
Очень полезное регулярное выражение для . Пригодится для поиска.
$text = "Sample sentence, regex has become popular in web programming. Now we learn regex. According to wikipedia, Regular expressions (abbreviated as regex or regexp, with plural forms regexes, regexps, or regexen) are written in a formal language that can be interpreted by a regular expression processor"; $text = preg_replace("/b(regex)b/i", "1", $text); echo $text;
Подсветка результатов поиска в WordPress
Как уже было сказано, предыдущий пример очень полезен при . Применим его к WordPress. Откройте файл search.php, найдите функцию the_title(). Замените её следующим:
Echo $title;
Теперь, перед этой строкой вставьте код:
\0", $title); ?>
Откройте файл style.css . Добавьте в него строку:
Strong.search-excerpt { background: yellow; }
Получить все изображения из HTML документа
Если вам когда-нибудь понадобиться найти все изображения на HTML странице, вам пригодится следующий код. С его помощью можно легко создать загрузчик изображений, используя .
$images = array(); preg_match_all("/(img|src)=("|")[^"">]+/i", $data, $media); unset($data); $data=preg_replace("/(img|src)("|"|="|=")(.*)/i","$3",$media); foreach($data as $url) { $info = pathinfo($url); if (isset($info["extension"])) { if (($info["extension"] == "jpg") || ($info["extension"] == "jpeg") || ($info["extension"] == "gif") || ($info["extension"] == "png")) array_push($images, $url); } }
Удаление повторяющихся слов (не зависимо от регистра)
$text = preg_replace("/s(w+s)1/i", "$1", $text);Удаление повторяющихся знаков препинания
Похоже на предыдущее, только удаляет знаки препинания.
$text = preg_replace("/.+/i", ".", $text);
Нахождение XML/HTML тега
Простая функция, которая принимает два аргумента: тег, который необходимо найти, и строка, содержащая XML или HTML.
Function get_tag($tag, $xml) { $tag = preg_quote($tag); preg_match_all("{<".$tag."[^>]*>(.*?)."}", $xml, $matches, PREG_PATTERN_ORDER); return $matches;
Нахождение XML/HTML тега с определенным значением атрибута
Функция похожа на предыдущую, но появляется возможность указать атрибут тега. Например: Function get_tag($attr, $value, $xml, $tag=null) {
if(is_null($tag))
$tag = "\w+";
else
$tag = preg_quote($tag);
$attr = preg_quote($attr);
$value = preg_quote($value);
$tag_regex = "/<(".$tag.")[^>]*$attr\s*=\s*".
"(["\"])$value\\2[^>]*>(.*?)<\/\\1>/"
preg_match_all($tag_regex,
$xml,
$matches,
PREG_PATTERN_ORDER);
return $matches;
}
Функция позволяет находить или проверять правильность шестнадцатеричных кодов цвета.
$string = "#555555";
if (preg_match("/^#(?:(?:{3}){1,2})$/i", $string)) {
echo "example 6 successful.";
}
Данный код найдет и выведет на экран текст между тегами
$fp = fopen("http://www.catswhocode.com/blog","r");
while (!feof($fp)){
$page .= fgets($fp, 4096);
}
$titre = eregi(" Многие сайты работают на веб-сервере Apache. Если ваш сайт тоже работает на тако сервере, то следующие регулярки могут пригодиться.
//Logs: Apache web server
// Успешные доступы к html файлам. Полезно для подсчета показов страниц.
"^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+[((?#date and time)[^]]+)]s+"(?:GET|POST|HEAD) ((?#file)/[^ ?"]+?.html?)??((?#parameters)[^ ?"]+)? HTTP/+"s+(?#status code)200s+((?#bytes transferred)[-0-9]+)s+"((?#referrer)[^"]*)"s+"((?#user agent)[^"]*)"$"
//Logs: Apache web server
//404 ошибки
"^((?#client IP or domain name)S+)s+((?#basic authentication)S+s+S+)s+[((?#date and time)[^]]+)]s+"(?:GET|POST|HEAD) ((?#file)[^ ?"]+)??((?#parameters)[^ ?"]+)? HTTP/+"s+(?#status code)404s+((?#bytes transferred)[-0-9]+)s+"((?#referrer)[^"]*)"s+"((?#user agent)[^"]*)"$"
}
Это регулярное выражение проверяет строку по пунктам: строка должна содержать не менее 6 букв, цифр, подчеркиваний и тире. Строка должна содержать хотя бы одну заглавную букву, строчную и цифру.
"A(?=[-_a-zA-Z0-9]*?)(?=[-_a-zA-Z0-9]*?)(?=[-_a-zA-Z0-9]*?)[-_a-zA-Z0-9]{6,}z"
Если вы используете WordPress вам может пригодиться функция, которая получит все изображения из поста и покажет их. Для использования данного кода, скопируйте его в файлы своей темы.
post_content;
$szSearchPattern = "~ Эта функция также есть в WordPress, она позволяет автоматически заменить текстовые смайлы на картинки.
$texte="A text with a smiley:-)";
echo str_replace(":-)"," ) я показал вам пример использования регулярных выражений для нахождения определенных кусков исходного кода страницы. Сейчас же мы с вами научимся писать их самостоятельно. Данный навык поможет писать , очищать текст от ненужных фрагментов, искать нужные части в больших объемах текста и так далее. По крайней мере, в предыдущих уроках мы пользовались именно ими. Вернее, вместо preg_match был preg_match_all, но это по сути тоже самое, только последний не прерывает поиск после первого нахождения. То есть, если использовать preg_match, то мы не найдем все вхождения, а лишь только первое. Выбор в какой ситуации какую функцию использовать довольно простой. Нужно заменить — используем replace, как в случае когда нам нужно было удалить ненужные части кода страницы, помните?
$page = preg_replace("/^]/i", "", $page);
$page = preg_replace("/ Первый параметр функции — регулярка, определяющая Что мы ищем. Второй — на что заменяем. Третий — Где ищем. Следовательно, здесь мы брали переменную $page и присваивали ей результат функции preg_replace где искали все input type=checkbox, а также открывающиеся и закрывающиеся label. Заменяли их на », то есть просто удаляли. Надеюсь тут все ясно. К разбору самого выражения (первого параметра функции) мы перейдем чуть позже. Preg_match_all("/ Первым параметром опять же является регулярка, чтобы найти все ссылки, которые, естественно заключены в тег «a» (если не дружите с html разметкой, то почитайте ). Второй — переменная в которой содержится текст, по которому будет происходить поиск. Третьим параметром поставлена переменная, в которую помещается результат — $ok. После этого лишь остается пройтись по всем нужным элементам $ok, чтобы достать нужные нам ключевые лова. Отдельно нужно сказать, что на выходе мы получаем многомерный массив. Именно поэтому мы выводили его таким сложным способом: $ok[$j]. Чтобы посмотреть структуру массива воспользуйтесь функцией ниже и вы все поймете. Print_r($ok);
Вот, вроде бы, с функциями, которые мы использовали для работы, разобрались. Теперь остается только научиться писать эти самые регулярные выражения, которые являются первым параметром каждого из этих методов. Переходим к самому важному. Для начала разберем основные конструкции. У выражений есть опции. Они задаются одной буквой и пишутся в конце, перед ними ставится слеш. Кроме этого поддерживаются следующие метасимволы:
/^]/i
Первый и последний слеши «/» показывают, что внутри них идет регулярное выражение. При этом, после последнего мы поставили «i», это опция, как в первой таблице — не учитывать регистр. Внутри слешей сама регулярка. Она начинается со знака меньше и тега input, а также все, что идет потом, до знака точки — простой текст, который нужно искать. А вот сама точка, и символы после нее — это уже интереснее. В данном случае, конструкция «.*?» означает любую последовательность символов. То есть, если объединить просто текст и данную конструкцию, то мы выберем весь текст после первого вхождения и до конца. Чтобы остановиться нужно встретить либо закрывающийся html тег «больше», либо символ начала новой строки. Эта конструкция как раз нам и дает такую возможность: Символы в квадратных скобках как бы соединены логическим ИЛИ. Концом является знак «больше» ИЛИ начало строки. Давайте разберем еще одно, чтобы все закрепить. Им мы искали ссылки:
/ Читаем выражение. Опять же, сначала отбрасываем слеши и опции. Флаги «uis» понятны, за исключением «u», который я не описывал — он показывает, что мы используем кодировку Юникод. Остается не так много. Началом является тег «a», который открывается, затем идет класс который обозначает НЕ больше или меньше (открывающий и закрывающийся html теги), то есть любые символы в данном случае. К классу добавляется «+?», которые означают, что этот класс будет присутствовать 1 или большее число раз (но хотя бы 1 раз точно). И потом идет закрывающийся html тег для тега «a». Внутри ссылки есть текст, который задается группой Ведь мы не знаем что там будет за текст, поэтому определяем такую группу. И в конце закрывающийся тег «a»: Обратите внимание, что слеш мы экранируем с помощью обратного слеша, чтобы он воспринимался как простой текст. Фух. Тема действительно достаточно сложная, тут нужна практика. Возможно я что-то делаю не вполне оптимально и можно составить другие, более правильные регулярные выражения, но я такой же самоучка как и вы, поэтому не судите строго, а лучше поделитесь своими вариантами в комментариях. Также, если что-то не понятно — комментарии и страница контактов к вашим услугам. Регулярные выражения
(сокращенно — regex
) представляют собой последовательности символов, которые формируют шаблоны поиска. В основном они используются в шаблонах сопоставления со строками. Краткая история PHP
включает в себя три основные функции для работы с PCRE
— preg_match
, preg_match_all
и preg_replace
. Сравнение соответствия
Выражение возвращает 1
, если соответствие установлено, 0
— если нет, и false
— если возникает ошибка: int preg_match (string $pattern,
string $subject [,
array &$matches [,
int $flags = 0 [,
int $offset = 0
]]]) Регулярного выражения пример, который возвращает количество найденных совпадений: int preg_match_all (string $pattern,
string $subject [,
array &$matches [,
int $flags = PREG_PATTERN_ORDER [,
int $offset = 0
]]]) Замена
Выражение возвращает замененную строку или массив (на основе объекта $subject
): mixed preg_replace (mixed $pattern,
mixed $replacement,
mixed $subject [,
int $limit = -1 [,
int $count
]]) Регулярные выражения в JavaScript
выглядят почти так же, как и в PHP
. Сравнение соответствия
Возвращает массив совпадений или null
, если совпадений не найдено: string.match(RegExp); Замена
Регулярное выражение, которое возвращает строку с выполненными заменами: string.replace(RegExp, replacement); Рассмотрим пример, в котором нужно найти адреса электронной почты в базе кода. Наша цель: Аналоговые сокеты
Регулярные выражения состоят из двух типов символов: Представьте себе входные строки как болты, а шаблон — как набор разъемов для них (в соответствующем порядке). Специальные символы
При проверке регулярных выражений нужно знать, как работают специальные символы: Совпадение со всеми символами, кроме новых строк. Если хотите проверить на соответствие точке, и только точке — , на соответствие буквам, цифрам и нижнему подчеркиванию — w
Совпадение с символами внутри скобок. Поддерживает диапазоны. Некоторые примеры: Звездочка обозначает 0 или более символов. Соответствие 1 или более символам. Фигурные скобки {}. Минимальное и максимальное значения. Некоторые примеры синтаксиса регулярных выражений: Добавим все это, чтобы получить регулярное выражение для адресов электронной почты: /+@+(.+)*/i
preg_match_all("/+@+(.+)*/i",
$input_lines,
$output_array); Задача
: убедиться, что вводимые данные — это то, что мы ожидаем. Цель 1
: /[^w$.]/ Цель 2: /^{1,2}$/
Регулярные выражения подходят для поиска элементов, но вам нужно знать, что именно вы ищете. Многие случаи лучше обрабатывать с помощью функции PHP filter_var
. Например, проверка адреса электронной почты должна выполняться с помощью встроенных фильтров PHP
: filter_var("[email protected]",
FILTER_VALIDATE_EMAIL) Регулярные выражения в конце строки используют анкоры: ^
— указывает начало строки. if (!preg_match("%^{1,2}$%", $_POST["subscription_frequency"])) {
$isError = true;
} [^abc]
— все, кроме a
, b
или c
, включая новые строки. Пример, который обеспечивает ввод только буквенно-цифровых символов, тире, точки, подчеркивания: if (preg_match("/[^0-9a-z-_.]/i", $productCode)) {
$isError = true;
} Наиболее распространенными функциями PCRE
для выполнения поиска и замены являются preg_replace()
и preg_replace_callback()
. Но есть также preg_filter()
и preg_replace_callback_array()
, которые делают почти то же самое. Обратите внимание, что функция preg_replace_callback_array()
доступна, начиная с PHP7
. $subject = "I want to eat some apples.";
echo preg_replace("/apple|banana|orange/", "fruit", $subject); Результат
I want to eat some fruits. Если в регулярном выражении есть подшаблоны (в круглых скобках
), можно заменить $N
или N
(где N
является целым числом > = 1
), это называется «обратная ссылка». $subject = "7/11";
echo preg_replace("/(d+)/(d+)/", "$2/$1", $subject); Результат
$subject = "2001-09-11";
echo preg_replace("/(d+)-(d+)-(d+)/", "$3/$2/$1", $subject); Результат
$subject = "Please visit https://php.earth/doc for more articles.";
echo preg_replace("#(https?://([^s./]+(?:.[^s./]+)*[^s]*))#i",
"$2",
$subject); Результат
Please visit php.earth/doc for more articles. Иногда нужно выполнить сложный поиск и замену, например, при фильтрации/проверке перед заменой. В этой ситуации может пригодиться preg_replace_callback()
. Чаще всего регулярные выражения используются в Perl в операторах поиска и замены, таких как s//
, m/
, операторах связки =~
или !=
и т.д. Как правило все эти операторы имеют схожие опции такие как: Обычно все эти опции обозначают как "/x". Их можно использовать даже внутри шаблонов, используя новую конструкцию (?...) Регулярные выражения или шаблоны (pattern) то же самое, что и regexp процедуры в Unix. Выражения и синтаксис заимствованы из свободно распространяемых процедур V8 Генри Спенсера (Henry Spencer), там же они подробно и описаны. В шаблонах используются следующие метасимволы (символы обозначающие группы других символов) часто называемые egrep - стандартом: Метасимволы имеют модификаторы (пишутся после метасимвола): Во все других случаях фигурные скобки считаются обычными (регулярными) символами. Таким образом "*" эквивалентна {0,} , "+" - {1,} и "?" - {0,1}. n и m не могут быть больше 65536. По умолчанию действие метасимволов "жадно" (greedy). Совпадение распространяется столько раз, сколько возможно, не учитывая результат действия следующих метасимволов. Если вы хотите "уменьшить их аппетит", то используйте символ "?". Это не изменяет значение метасимволов, просто уменьшает распространение. Таким образом: Шаблоны работают так же, как и двойные кавычки, поэтому в них можно использовать `\` - символы (бэкслэш-символы): Дополнительно в Perl добавлены следующие метасимволы: Обратите внимание, что все это "один" символ. Для обозначения последовательности применяйте модификаторы. Так: Кроме того существуют мнимые метасимволы. Обозначающие не существующие символы в месте смены значения. Такие как: Граница слова (\b) - это мнимая точка между символами \w и \W. Внутри класса символов "\b" обозначает символ backspace (стирания). Метасимволы \A
и \Z
- аналогичны "^" и "$", но если начало строки "^" и конец строки "$" действуют для каждой строки в многострочной строке, то \A
и \Z
обозначают начало и конец всей многострочной строки. Если внутри шаблона применяется группировка (круглые скобки), то номер подстроки группы обозначается как "\цифра". Заметьте, что за шаблоном в пределах выражения или блока эти группы обозначаются как "$цифра". Кроме этого существуют дополнительные переменные: Пример:
$s = "Один 1 два 2 и три 3";
if ($s =~ /(\d+)\D+(\d+)/)
{
print "$1\n"; # Результат "1"
print "$2\n"; # "2"
print "$+\n"; # "2"
print "$&\n"; # "1 два 2"
print "$`\n"; # "Один "
print "$"\n"; # " и три 3"
}
Perl версии 5 содержит дополнительные конструкции шаблонов: Пример:
$s = "1+2-3*4";
if ($s =~ /(\d)(?=-)/) # Найти цифру за которой стоит "-"
{
print "$1\n"; # Результат "2"
}
else
{
print "ошибка поиска\n";
}
(?!шаблон)- "заглядывание" вперед по отрицанию: Пример:
$s = "1+2-3*4";
if ($s =~ /(\d)(?!\+)/) # Найти цифру за которой не стоит "+"
{
print "$1\n"; # Результат "2"
}
else
{
print "ошибка поиска\n";
}
(?ismx) - "внутренние" модификаторы. Удобно применять в шаблонах, где например нужно внутри шаблона указать модификатор. Правила регулярного выражения. (regex)
Нахождение шестнадцатеричных кодов цвета
Нахождение заголовка страницы
Парсинг логов Apache
Замена двойных кавычек на фигурные
preg_replace("B"b([^"x84x93x94rn]+)b"B", "?1?", $text);
Проверка сложности пароля
WordPress: Получение изображений поста с помощью регулярного выражения
]* />~";
// Run preg_match_all to grab all the images and save the results in $aPics
preg_match_all($szSearchPattern, $szPostContent, $aPics);
// Check to see if we have at least 1 image
$iNumberOfPics = count($aPics);
if ($iNumberOfPics > 0) {
// Now here you would do whatever you need to do with the images
// For this example the images are just displayed
for ($i=0; $i < $iNumberOfPics ; $i++) {
echo $aPics[$i];
};
};
endwhile;
endif;
?>
Преобразование смайлов в картинки
 ",$texte);
",$texte);
Эта тема довольно непроста, но я постараюсь в краткой форме осветить самые важные моменты. Не знаю насколько это у меня получится, но надеюсь польза от урока будет.
Итак, начнем с того, что для работы с регулярными выражениями в PHP существует несколько функций, но чаще всего используются три:
Был и пример использования preg_match_all, который пригодился для поиска всех ссылок в оставшемся тексте. Ссылки нам тогда понадобились потому, что именно в них были заключены ключевые слова, которые мы парсили. Вот что было:Как же писать регулярки

Метасимволы, в свою очередь, могут иметь модификаторы:
Что же, теперь можем перейти к разбору наших регулярок из прошлого урока. Опираясь на таблички выше попробуем понять, что же у нас есть. Вот выражение:
Вот и все выражение, в нем мы задали условие начала, середину и условие окончания. Не трудно, правда? Вот иллюстрация для пущей наглядности:
Общее использование регулярных выражений в PHP
Общее использование регулярных выражений в JavaScript
Особенности регулярных выражений в JavaScript
Принципы составления шаблонов регулярных выражений
o — соответствует любым a, b или c.
o прописные буквы.
o любая цифра.
o — соответствует любому буквенному символу в нижнем или верхнем регистре.
Опционально? Соответствие 0 или 1.
Звездочка *.
o {1,} не менее 1.
o {1,3} от 1 до 3.
o {1,64} от 1 до 64.
Как это выглядит в PHP
:
Использование регулярного выражения для валидации
Когда не стоит использовать регулярное выражение для проверки?
Валидация с помощью регулярных выражений
$
— знак доллара, который указывает конец строки.Исключенные классы символов
Поиск и замена
Заменить слова в списке
Перестановка двух чисел
Изменение форматирования даты
Простой пример замены URL-адреса в теге
\t
- символ табуляции
\n
- новая строка
\r
- перевод каретки
\а
- перевод формата
\v
- вертикальная табуляция
\a
- звонок
\e
- escape
\033
- восьмеричная запись символа
\x1A
- шестнадцатеричная
\c[
- control символ
\l
- нижний регистр следующего символа
\u
- верхний регистр -//-
\L
- все символы в нижнем регистре до \E
\U
- в верхнем -//-
\E
- ограничитель смены регистра
\Q
- отмена действия как метасимвола