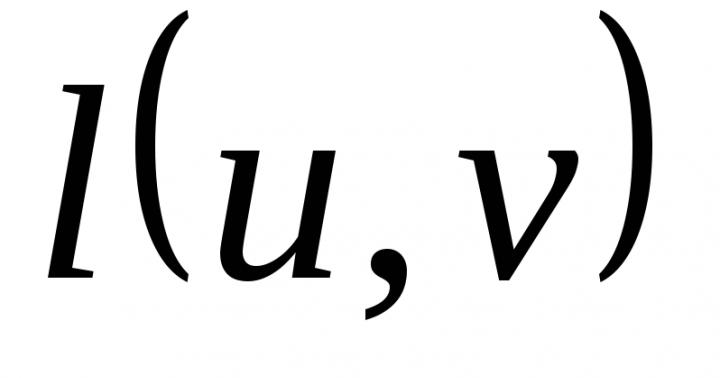W szkołach, aby zbadać podstawy algorytmicznego, t. N. język algorytmiczny szkolny (treningowy język algorytmiczny), Używając słów zrozumiały słowa w języku rosyjskim. W przeciwieństwie do większości języków programowania, język algorytmiczny nie jest przymocowany do architektury komputera, nie zawiera części związanych z urządzeniem maszynowym.
Przykłady.
Algorytm na języku algorytmicznym jest na ogół napisany w formularzu:
alg. Nazwa algorytmu (argumenty i wyniki) dano. Warunki stosowania algorytmu potrzebujemy Cel wykonania algorytmu nach. Opis wartości pośrednich | Sekwencja komunikacyjna (algorytm ciała) kon.W nagraniach algorytmu słowa kluczowe zwykle podkreślają albo przydzielone przez pogrubione czcionki. Wcięcie użyto do podświetlenia bloków logicznych, a słowa parowania początku i końca bloku były podłączone do funkcji pionowej.
Przykład obliczania suma kwadratów:
alg. Kwadratowe sumy ( arg dobrze n, skaleczenie dobrze S) dano. |. N\u003e 0. potrzebujemy |. S \u003d 1 * 1 + 2 * 2 + 3 * 3 + ... + n * n nach. dobrze I |. wejście n; S: \u003d 0 | nC. Dla I od 1 do N | |. S: \u003d S + I * I | kc. | wynik "S \u003d", s kon.E-warsztat.
Aby wzmocnić teoretyczne badanie programowania zgodnie z językiem algorytmicznym, specjaliści z Uniwersytetu Moskiewskiego w 1985 roku utworzyli edytor kompilatora "E-warsztat" ("E" - na cześć Yershova), umożliwiając wprowadzenie, edytowanie i wykonywanie programów na języku algorytmicznym.
W 1986 r. Wydano zestaw światów edukacyjnych (wykonawców) na e-warsztat: "Robot", "rysownik", "Twitch", "Werethe", co ułatwia wprowadzenie koncepcji algorytmu. "E-warsztat" został wdrożony na komputerach: Yamaha, Corvette, UKNC i rozpowszechniono.
Ten język programowania był stale sfinalizowany, a opis późniejszej wersji "E-warsztat" w podręczniku z 1990 roku. System programowania "KUMIR" ("Zestaw do światów szkoleniowych"), wspierający ten podręcznik, został opublikowany w Enterprise Info w 1990 roku. Język tego systemu jest również nazywany "idolem".
W 1995 r. Kumir został rekomendowany przez Ministerstwo Edukacji Federacji Rosyjskiej jako głównego materiału edukacyjnego na kursie "Podstawy informatyki i maszyn komputerowych" na podstawie podręcznika A. G. Kushnirenko, G.V. Lebedeva i R.a. Svoren. .
Krytyka
Należy jednak zauważyć, że język algorytmiczny w przypadku braku części łączących go z architektury komputera bezpośrednio, mimo to, odnosząc się do języków podobnych do algoli, niejawne uczy uczniów, aby polegać na tle architektury maszyn w tle-Neumanovsk. (Architektura von Neumanan jest praktyczną realizacją wcześniejszego pomysłu mając maszynę do Turing. Oprócz idei turowania istnieją inne pomysły. Najpopularniejsze z nich ma nazwę lambda-brudulus: Alunzo Chechch pracowała na nią. Lisp Samochód to architektura oparta na Lambda -Question.)
Spinki do mankietów
- A. P. Ershov. Język algorytmiczny w szkole podstawowych informacji i urządzeń informatycznych. 05/05/1985.
- Forum na językach i rozwoju rosyjskich programowania
Fundacja Wikimedia. 2010.
Oglądaj, co jest "rosyjski język algorytmiczny" w innych słownikach:
Język algorytmiczny jest formalnym językiem używanym do nagrywania, wdrożenia lub badania algorytmów. Każdy język programowania jest językiem algorytmicznym, ale nie cały język algorytmiczny jest odpowiedni do użytku jako język ... ... Wikipedia
Termin ten ma inne wartości, patrz Smok (Wartości). Przykładowy schemat Algorytm blokowy w Dragon Dragon Dragon Dragon (przyjazny rosyjski język algorytmiczny, który zapewnia wizualność) wizualną ... Wikipedia
Termin ten ma również inne znaczenia, patrz język algorytmiczny. Język algorytmiczny edukacyjny jest formalnym językiem używanym do nagrywania, wdrażania i algorytmów studiów. W przeciwieństwie do większości języków programowania, nie związany z ... Wikipedia
Język algorytmiczny (również język rosyjski algorytmiczny, raadise) język programowania używany do nagrywania i badania algorytmów. Studiując informatykę w szkołach, aby zbadać fundamenty algorytmizacji, t. N. Algorytmiczny ... ... Wikipedia
Język programowania języka szkoleniowego zaprojektowany do programowania specjalistów szkoleniowych. Taki język musi spełniać główne wymagania: prostota. Łatwiej będzie, tym szybciej przybysza zostanie zapalona. Cechy takiego ... Wikipedia
Przykład blok diagramu Smok Dragon Dragon Smoke Scheme (przyjazny język algorytmiczny rosyjski, który zapewnia wizualność) język algorytmiczny wizualny, stworzony w ramach programu Buran Space. Rozwój tego języka ... Wikipedia
Część algorytmu alg. przed słowem nach. zwany tytułem, a część zawarta między słowami nach. i kon. - Algorytm ciała.
W zdaniu alg. Po nazwie algorytm w nawiasach, charakterystyki (arg, CR) i typ wartości (niematerialne, sim, lite, log) są wskazane dla wszystkich zmiennych wejściowych (argumentów) i wyjściowych (wyników).
Opisanie tablic (tabele) używany jest słowo serwisowe patka, Uzupełniane parami brzegowymi dla każdego indeksu elementów tablicy.
Przykłady ofert alg.:
obszar objętości i cylindrów w obiekcie (Arg Mane R, H, Cut V, S)
alg korzenie SMB (Arg Mana A, B, C, Cut Mee X1, X2, Res Lite T)
alg Exclude Element (Arg Complex N, Arg Dres Tab a)
alg Diagonal (Arg Complex N, Karta komunikacji ARG A, CRA oświetlona OTVET)
Gatunki słowa dano. i potrzebujemy Nie obowiązkowe. Zaleca się rejestrowanie stwierdzeń opisujących stan środowiska algorytmu wykonawczego, na przykład:
Wymiana ALLEG (ARG LIT STR1, STR2, ARG Crop Croping) Dano | Str1 i str2 str2 długość | Wszędzie w linii tekstowej Str1 zastąpiona STR2
Alg Numer Maxima (Arg Cover N, Arg Mest Tab a, Resh K) Dana | N\u003e 0Anado | K - liczba maksymalnych elementów w tabeli A
Odporność alga (Arg Mane R1, R2, Arg Complex N, Cole R) Dange | N\u003e 5, R1\u003e 0, R2\u003e 0ANADO | R - Rezystancja schematu
Tutaj w zdaniach dano. i potrzebujemy Po znaku "|" Uwagi są rejestrowane. Komentarze można umieścić na końcu dowolnego ciągu. Nie są przetwarzane przez tłumacza komputerowego, ale znacząco ułatwiają zrozumienie algorytmu.
Drużyny szkolne Programowanie Aya
Operator aplikacji.. Używane do obliczania wyrażeń i przypisywania ich wartości zmiennych. Ogólny widok operatora: A: \u003d B, gdzie znak ": \u003d" oznacza działanie przypisania, tj. Polecenie zastąpienie dawnej wartości zmiennej A, stojąc po lewej stronie, na obliczonej wartości wyrażenia po prawej stronie.
Na przykład, a: \u003d (B + C) * SIN (PI / 4);
i: \u003d i + 1 .
Dla wejście i wyjście Dane używane zespoły
· wejście Nazwy zmiennych
· wynik Nazwy zmiennych, wyrażeń, tekstów.
Dla Rozgałęzienie Algorytm używa poleceń jeśli i wybór.
Dla organizacji cykle. - Drużyny dla i aż doOpisane poniżej.
Przykład zapisu algorytmu w języku szkolnym.
Kwadraty Alg (Arg n., lekarstwo S.) Dano |. N\u003e 0Anado | S \u003d 1 * 1 + 2 * 2 + 3 * 3 + ... + n * Nach jA. Wejście n.; S. : =0 nC.dla i od 1 do n s : \u003d S + I * I kc. Wniosek "S \u003d", SKON
Język algorytmiczny edukacyjny jest środkiem do nagrywania algorytmów w postaci, pośrednim między algorytmem nagrania na naturalnym (ludzkim) języku i napisać komputer (język programowania).
Zalety algorytmicznego języka edukacyjnego obejmują jego prostotę, a także fakt, że algorytm jest rejestrowany w języku rosyjskim z pewną ograniczoną liczbą słów, których znaczenie i sposób konsumpcji jest ściśle określony. Te słowa nazywane są oficjalnymi słowami.
Aby przydzielić oficjalne słowa między innymi języka, podkreślają je podczas pisania.
Rekord algorytmu w języku algorytmicznym edukacyjnym składa się z nagłówka i korpusu algorytmu. Ciało algorytmu jest między słowami kluczowymi nach. i kon. I reprezentuje sekwencję poleceń algorytmowych. Tytuł zawiera nazwę algorytmu, odzwierciedlając jej zawartość, listę danych źródłowych (argumentów) i wyników.
Znakiem nagłówka algorytmu jest słowo kluczowe alg..
Tak więc algorytm nagrany w języku algorytmicznym edukacyjnym ma następujący formularz:
alg. algorytm tytułu.
arg lista danych źródłowych
skaleczenie lista wyników
sekwencja poleceń algorytmu
Studiowanie języka algorytmicznego szkolnego jest wskazane rozpoczęcie od zespołu przydziału, jest jedną z głównych zespołów.
Jest tak napisany:
<переменная> := <выражение>
Znak ": \u003d" brzmi "przypisać".
W przypadku, gdy wartość jest przypisana do wartości, zawiera również prawą stronę polecenia, następuje:
1) Wartość wyrażenia zapisanego po prawej stronie polecenia przypisywania jest obliczana przy użyciu bieżących wartości wszystkich wartości zawartych w tym wyrażeniu;
2) Zmienna jest przypisana nowa obliczona wartość bieżąca. W tym przypadku wcześniejsza wartość zmiennej jest zniszczona.
W związku z tym polecenie B: \u003d A + B oznacza, że \u200b\u200bwartość zmiennej A i uzyskanego wyniku staje się nową bieżącą wartością wartości B, dodaje się do poprzedniej wartości bieżącej wartości B.
Ten przykład ilustruje trzy podstawowe właściwości przypisania:
1) dopóki zmienna zostanie przypisana wartość, pozostaje ona nie zdefiniowana;
2) Wartość przypisana do zmiennej jest w niej przechowywana do czasu wykonania następnego przypisania tej zmiennej;
3) Nowa wartość przypisana do zmiennej zastępuje jej poprzednią wartość.
Zapoznajmy się z podstawowymi strukturami, zacznijmy od takiej operacji jako "Śledź". Tworzy sekwencję działań po drugim:
akcja 1.
działanie 2.
. . . . . . . . .
działanie N.
Następnie rozważ podstawową strukturę "Oddział". Zapewnia w zależności od wyniku weryfikacji warunku (tak lub nie) wyboru jednej z alternatywnych ścieżek algorytmu. Każda ze ścieżek prowadzi do ogólnego wyjścia, więc praca algorytmu będzie kontynuowana niezależnie od tego, której ścieżka zostanie wybrana. Struktura gałęzi istnieje w czterech głównych opcjach:
1. Jeśli coś;
jeśli stan: schorzenie
że działania
2. Jeśli coś - inaczej;
jeśli stan: schorzenie
że akcje 1.
inaczej działania 2.
wybór
dlawarunek 1: Akcje 1
dlawarunek 2: Akcje 2
. . . . . . . . . . . .
dla warunek N: Działania n
{inaczejdziałania n + 1}
I wreszcie, podstawowa struktura cyklu przy użyciu języka algorytmicznego szkolnego będzie wygląda tak.
Ministerstwo Edukacji Federacji Rosyjskiej Perm Krajowej Politechniki
Departament Technologii Informacyjnych i systemów zautomatyzowanych
Vikentheva O. L.
Abstrakcyjne wykłady na kursie "Lęki algorytmiczne i programowanie" (Podstawy języka C ++, I Semester)
Wprowadzenie
Pierwszy semestr omawia podstawowe projekty języka C i podstawowej technologii programowania (programowanie strukturalne).
Programowanie strukturalne to technologia tworzenia programów, które pozwala nam przestrzegać pewnych zasad w celu zmniejszenia czasu rozwoju i liczby błędów, a także ułatwiać możliwość modyfikacji programu.
1.1. Algorytm i program.
Algorytm jest dokładnym zamówieniem, który określa proces obliczeniowy pochodzący z zmiennych danych początkowego do wyniku końcowego, tj. Jest to receptura do osiągnięcia celu.
Połączenie środków i zasad reprezentacji algorytmu w formie maszyny obliczeniowej nazywane jest językiem programowania, algorytm zarejestrowany w tym języku nazywa się programem.
Po pierwsze, algorytm działań jest zawsze rozwijany, a następnie napisano w jednym z języków programowania. Tekst programu jest przetwarzany przez specjalne programy serwisowe - tłumacz. Języki programowania są językami sztucznymi. Z języków naturalnych różnią się one ograniczoną liczbą "słów" i bardzo surowych zasad poleceń rejestrowania (operatorów). Połączenie tych wymagań tworzy składnię języka programowania, a znaczenie każdego projektu jest jego semantyka.
1.2. Algorytm odróżnienia
1. Masystor: algorytm należy zastosować nie do jednego zadania, a do całej klasy podobnych problemów (algorytm do rozwiązywania równania kwadratowego należy rozwiązać nie jeden równania, ale wszystkie równania kwadratowe).
2. Skuteczność: Algorytm powinien prowadzić do wyniku wyniku dla określonej liczby etapów (w podziale 1 do 3, uzyskuje się okresową frakcję 0,33333 (3), aby osiągnąć wynik końcowy, konieczne jest określenie dokładności Uzyskanie tej frakcji, na przykład do 4 znaku dziesiętnego).
3. Definicja (determinizm) - każde działanie algorytmu powinno być zrozumiałe dla jego wykonawcy (instrukcje dla instrumentu krajowego w języku japońskim dla osoby, która nie mówi po japońsku, nie jest algorytmem, ponieważ nie ma własności deterministycznej).
4. Dystrybutowość - proces musi być opisany przy użyciu niepodzielnego
operacje wykonywane przy każdym kroku (tj. Kroki nie można podzielić na mniejsze kroki).
Algorytmy mogą być reprezentowane w następujących formach:
1) słowny opis algorytmu.
2) graficzny opis algorytmu.
3) korzystanie z języka programowania algorytmicznego
1.2. Kompilatory i tłumacze
Z tekst opisujący wcześniej skompilowany algorytm jest tworzony przy użyciu języka programowania. Aby uzyskać program pracujący, musisz przetłumaczyć ten tekst do sekwencji poleceń procesora, która jest wykonywana za pomocą specjalnych programów, które nazywane są tłumacze. Tłumacze Istnieją dwa typy: kompilatory i tłumacze. Kompilator tłumaczy tekst modułu źródłowego do kodu maszyny, który nazywa się modułem obiektu dla jednego procesu ciągłego. Jednocześnie najpierw przegląda tekst źródłowy programu w poszukiwaniu błędów składniowych. Interpreter wykonuje oryginalny moduł programu w trybie operatora dla operatora,
przeniesienie pracy, tłumacząc każdy operator do języka maszyny.
1.3. Programowanie
Różne typy procesorów mają inny zestaw poleceń. Jeśli język programowania koncentruje się na określonym typie procesora i uwzględnia jego funkcje, nazywa się to językiem programowania niskiego poziomu. Najniższym językiem jest język asemblera, który po prostu reprezentuje każdą komendę kodu maszyny w postaci specjalnych symboli symbolicznych, które nazywa się mnemonics. Wykorzystanie języków niskiego poziomu, bardzo wydajne i kompaktowe programy są tworzone, ponieważ deweloper uzyskuje dostęp do wszystkich możliwości procesora. Dlatego Instrukcje Zestawy do różnych modeli procesorów są również inne, a każdy model procesora odpowiada jej językowi asemblera, a program zapisany na niej można go stosować tylko w tym środowisku. Podobne języki służą do pisania małych aplikacji, urządzeń sterowników itp.
Języki programowania wysokiego szczebla nie uwzględniają specyfiki określonych architektur komputerowych, dzięki czemu programy utworzone na poziomie tekstu źródłowego są łatwo przenoszone na inne platformy, jeśli tworzone są dla nich odpowiednich tłumaczy. Rozwój programów w językach wysokiego szczebla jest znacznie łatwiejszy niż na językach maszynowych.
Języki wysokiego poziomu to:
1. Fortran - pierwszy skompilowany język stworzony w50. XX wiek. Wdrożył szereg najważniejszych koncepcji programowania. W tym języku powstał ogromną liczbę bibliotek, począwszy od kompleksów statystycznych i kończących satelitów, więc nadal jest stosowany w wielu organizacjach.
2. COBOL - skompilowany język obliczeń gospodarczych i rozwiązańzadania biznesowe opracowane na początku lat 60-tych. W COBOL, bardzo silne sposoby pracy z dużymi ilościami danych przechowywanych na nośnikach zewnętrznych zostały wdrożone.
3. Pascal - utworzony na końcuLata 70. Swiss Mathematics Niklaus Virut specjalnie do programowania szkoleniowego. Pozwala opracować myślenie algorytmiczne, zbudować krótki, dobrze czytelny program, wykazuje główne techniki algorytmizacji, jest również dobrze nadaje się do wdrażania dużych projektów.
4. Baisik - został stworzony60s również do programowania uczenia się. Dla niego są kompilatory i tłumacze, jest jednym z najpopularniejszych języków programowania.
5. Si - został utworzony w latach 70. był pierwotnie nie traktowany jako język programowania masowego języka. Zaplanowano zastąpienie asemblera, aby móc tworzyć te same wydajne i krótkie programy, ale nie zależą od określonego procesora. Jest w dużej mierze podobny do Pascala i ma dodatkowe możliwości pracy z pamięcią. Napisano wiele zastosowanych i systemów systemowych, a także system operacyjny UNIX.
6. C ++ - Rozszerzenie obiektów języka SI stworzonego przez Biarny Sturastrup w 1980 roku.
7. Java to język, który został stworzony przez słońce na początku90s oparty na C ++. Został zaprojektowany, aby uprościć rozwój aplikacji na C ++, wykluczając z niego możliwości niskiego poziomu. Główną cechą języka jest to, że jest on skompilowany nie w kodzie maszyny, ale w kodzie bajtu niezależnego od platformy (każde polecenie zajmuje jedno bajt). Kod ten można wykonać za pomocą tłumacza - wirtualnej maszyny Java (JVM).
2. Struktura programu na C ++
Program w SI ma następującą strukturę: dyrektywy preprocesora
. . . . . . . . .
# Dyrektywy preprocesor Funkcja A ()
operatorzy funkcjonują ()
operatorzy.
void main () // funkcja, z jaką rozpoczyna się wykonanie programu
opisy
zadania
funkcja pusty operator.
złożony
przejście
Dyrektywy wstępne Preprocessor - Kontroluj konwersję tekstu Programu przed ich kompilacją. Program źródłowy przygotowany na SI w formie pliku tekstowego przechodzi 3 etapy:
1) transformacja preprocesora tekstu;
2) kompilacja;
3) układ (edycja połączeń lub montaż).
Po tych trzech etapach utworzy się kod programu wykonywalnego. Zadanie jest prepro-
cessor - transformacja tekstu programu przed skompilowaniem. Zasady przetwarzania przedprocesji definiuje programista za pomocą dyrektyw preprocesor. Dyrektywa zaczyna się od #. Na przykład,
1) #define - wskazuje zasady wymiany w tekście. #Define zero 0.0.
Oznacza, że \u200b\u200bkażde użycie w programie zero zostanie wymienione.
2) #include.< имя заголовочного файла> - Ma być zawarte w tekście programu tekstowego z katalogu "Pliki nagłówka" dostarczonego z standardowymi bibliotekami. Każda funkcja biblioteki C ma odpowiedni opis w jednym z plików nagłówka. Lista plików nagłówka jest określona przez język standardowy. Korzystanie z dyrektywy obejmującej nie łączy odpowiedniego standardowego śliniaka
lyoteta, ale pozwala tylko wstawić opis programu opisu z określonego pliku nagłówka. Połączenie kodów bibliotek prowadzi się na etapie układu, tj. Po kompilacji. Chociaż pliki nagłówka zawierają wszystkie opisy standardowych funkcji, tylko te funkcje używane w programie są zawarte w kodzie programu.
Po wykonaniu preprocesorkiwania przetwarzania w tekście programu, nie ma jednej dyrektywy przed preprocesora.
Program jest zestawem opisów i definicji i składa się z zestawu funkcji. Wśród tych funkcji należy zawsze być funkcją o nazwie głównej. Bez niego nie można wykonać programu. Przed nazwą funkcji informacje są umieszczone na typ wartości zwracanej przez funkcję (typ wyniku). Jeśli funkcja nic nie zwraca, określono typ pustki: Void Main (). Każda funkcja, w tym główna, powinna mieć zestaw parametrów, może być pusty, a następnie w nawiasach wskazuje (void).
Funkcja funkcji jest umieszczona za funkcją nagłówka. Funkcja ciała jest sekwencją definicji, opisów i operatorów wykonywalnych zamkniętych w nawiasach kręconymi. Każda definicja, opis lub operator kończy się średnikiem.
Definicje - Przedstawiono obiekty (obiekt jest nazwanym obszarem pamięci, specjalny przypadek obiektu - zmiennej) wymagana do reprezentowania danych w danych przetwarzalnych. Przykład jest
int y \u003d 10; // Nazwa Float X Constant; //zmienna
Opisy - Powiadom kompilatora właściwości i nazw obiektów i funkcji opisanych w innych częściach programu.
Operatorzy - definiują działania programu na każdym etapie jego wykonania
Przykładowy program na C:
#Zawierać.
Pytania kontrolne.
1. Jakie części są programem C ++?
2. W jaki sposób definicja różni się od ogłoszenia?
3. Wymień kroki, aby utworzyć program wykonywalny w C ++.
4. Co to jest preprocesor?
5. Jaka jest dyrektywa przed preprocesorem? Utwórz przykłady dyrektyw preprocesora.
6. Zrób program, który drukuje tekst "Mój pierwszy program na C ++"
2. Podstawowe narzędzia C ++ 2.1. Język sost
W dowolnym języku naturalnym można wybrać cztery główne elementy: symbole, słowa, frazy i sugestie. Język algorytmiczny zawiera również takie elementy, tylko słowa nazywane są LEXEMES (struktury podstawowe), frazy - wyrażenia, oferty - operatorzy. LEXEMES są utworzone z symboli, wyrażeń z leksykawców i symboli, operatorów z wyrażeń i symboli exing (Rys. 1.1)
Figa. 1.1. Skład języka algorytmicznego, elementy języka algorytmicznego to:
Identyfikatory to nazwy programów C. Laty łacińskie, cyfry i znak podkreślenia mogą być używane w identyfikatorze. Kapitał i małe litery różnią się, na przykład Prog1, Prog1 i Prog1 są trzema różnymi identyfikatorami. Pierwszy znak powinien być literą lub podkreśleniem (ale nie figura). Spacje w identyfikatorach nie są dozwolone.
Klucz (zarezerwowany) słowa to słowa, które mają specjalną wartość kompilatora. Nie mogą być używane jako identyfikatory.
- Znaki operacji to jeden lub więcej znaków określających działanie na operandach. Operacje są podzielone na bezary, binarny i ternar w liczbie operandów uczestniczących w tej operacji.
Stałe są niezmiennymi wartościami. Istnieją liczby całkowite, prawdziwe, symboliczne i ciągłe stałe. Kompilator podkreśla stałą jako LEXEME (elementarna konstrukcja) i odnosi go do jednego z typów zgodnie z jego wyglądem.
Oddziela - wsporniki, punkt, ikony przestrzeni przecinkowej.
2.1.1. Stałe w C ++
Stała jest lexema reprezentującym obraz stałego numerycznego, ciągów lub wartości symbolicznej.
Stałe są podzielone na 5 grup:
Cały;
- prawdziwy (pływający punkt);
Katalogowany;
Symboliczny;
Strunowy.
Kompilator podkreśla Lex i odnosi go do określonej grupy, a następnie
trzy grupy do określonego typu na formę nagrywania w tekście programu i wartości numerycznej.
Stałe mogą być dziesiętne, oktalne i szesnastkowe. Stała dziesiętna jest definiowana jako sekwencja cyfr dziesiętnych, która zaczyna się nie od 0, jeśli nie jest to 0 (przykłady: 8, 0, 192345). Stała osadowa jest stałą, że zawsze zaczyna się od 0. W 0 podąża za numery kadrowymi (przykłady: 016 - wartość dziesiętna 14, 01). Stałe szesnastkowe są sekwencją liczb szesnastkowych, które poprzedzają znaki 0x lub 0x (przykłady: 0ha, 0x00f).
W w zależności od wartości całego stałego kompilatorana różne sposoby przedstawią to
w pamięć komputerowa (tj. Kompilator pomoże odpowiedniego stałej ilości danych).
Prawdziwe stałe mają inną formę wewnętrznej prezentacji w pamięci komputera. Kompilator rozpoznaje takie stałe zgodnie z ich formą. Prawdziwe stałe mogą mieć dwie formy formularzy: ze stałym punktem i punktem zmiennym. Stały punkt stały: [figury]. [Figurki] (Przykłady: 5.7, 0001, 41.). Widok stałej stałej punktu zmiennoprzecinkowego: [Figury] [.] [Figury] E | E [+ |] [Figury] (Ważny: 0.5E5, .11e-5, 5E3). W nagraniu stałych stałych, albo części całej, lub ułamkową, albo kropka dziesiętnego, albo znak wykładniczym z wskaźnikiem w zakresie, może zostać obniżona.
Elionowane stałe są wprowadzane za pomocą słowa kluczowego Enum. Są to wspólne całe stałe, które są unikalne i wygodne w użyciu oznaczenie są przypisane. Przykłady: Enum (jeden \u003d 1, dwa \u003d 2, trzy \u003d 3, cztery \u003d 4);
enum (zero, jeden, dwa, trzy) - Jeśli w definiowaniu wymienionych stałych znaków pominiętych \u003d i wartości numeryczne, wartości zostaną przypisane domyślnym. W tym przypadku, sam lewy identyfikator otrzyma wartość 0, a każdy kolejny zwiększy się o 1.
enum (dziesięć \u003d 10, trzy \u003d 3, cztery, pięć, sześć);
enum (niedziela, poniedziałek, wtorek, środa, czwartek, piątek, sawy
Symboliczne stałe są jednym lub dwoma znakami zamkniętymi w apostrofach. Symboliczne stałe składające się z jednego symbolu mają rodzaj char i zajmować jeden bajt w pamięci, stałe znaków składający się z dwóch znaków mają typ int i zajmować dwa bajty. Sekwencje począwszy od znaku nazywane są menedżerami, są używane:
- Aby reprezentować znaki, które nie mają graficznego wyświetlacza, na przykład:
A - sygnał dźwiękowy,
b - Wróć do jednego kroku, n - tłumaczenie rzędowe,
T - karta pozioma.
- Do prezentacji postaci: "? , "(", ").
- Do prezentacji znaków z kodeksami szesnastkowymi lub kadrowymi (073, 0xF5).
Stała ciągowa jest sekwencją znaków zamkniętych w cytatach.
Wewnątrz wierszy można również użyć znaków sterujących. Na przykład: "nnoving ciąg",
"N" Algorytmiczne języki programowania wysokiego poziomu "".
2.2. Rodzaje danych w C ++
Dane są wyświetlane w programie na całym świecie. Celem programu jest przetwarzanie danych. Różne typy danych są przechowywane i przetwarzane na różne sposoby. Typ danych określa:
1) wewnętrzna prezentacja danych w pamięci komputera;
2) wiele wartości, które mogą podjąć wartości tego typu;
3) operacje i funkcje, które można zastosować do danych tego typu.
W w zależności od wymagań zadania programista wybiera typ obiektów programowych. Rodzaje C ++ można podzielić na proste i kompozytowe. Proste typy obejmują typy, które charakteryzują się jedną wartością. W C ++ zdefiniowano 6 prostych typów danych:
int (całość)
char (symbol)
wchar_t (symbol zaawansowany) bool (logiczny) pływak (prawdziwy)
podwójny (prawdziwy z podwójną dokładnością)
Istnieją 4 specyfikacje typu określające wewnętrzną reprezentację i zakres standardowych typów
krótki (krótki) długa (długa) podpisana (znak)
niepodpisany (niecznoba)
2.2.1. Wpisz int.
Wartości tego typu są liczbami całkowitymi.
Wielkość typu INT nie jest określona przez standard, ale zależy od komputera i kompilatora. Dla 16-bitowego procesora przypisywane są 2 bajty, na 32-bitowe - 4 bajty.
Jeśli krótki specyfikator stoi przed intem, a następnie 2 bajty podano liczbie, a jeśli długi spekulacyjny, a następnie 4 bajty. Od liczby przypisanych do obiektu pamięci wiele ważnych wartości, które mogą otrzymać obiekt, zależy:
krótki INT - Zajmuje zatem 2 bajty, ma zasięg -32768 .. + 32767;
długie int - szeregi 4 bajtów ma zatem zakres -2 147 483 648 648. + 2 147 483 647
Typ Int pokrywa się z krótkim typem INT na 16-bitowych komputerach i z długim Int 32-bitowym komputerem.
Podpisane i niepodpisane modyfikatory wpływa również na zestaw dopuszczalnych wartości, które obiekt może przyjmować:
nieodpowiedziany krótki int - zatem 2 bajty ma zakres 0.65536; Unsigned Long Int - Ranks 4 bajtów ma zatem zakres 0. + 4 294 967
2.2.2. Wpisz Char.
Wartości tego typu są elementy ostatecznego zamówionego zestawu znaków. Każda postać jest umieszczona zgodnie z numerem zwanym kodem symbolu. Pod wielkością bajtu symbolu 1 jest podany. Rodzaj znaku może być używany z podpisanymi i niepodpisanymi specyfikatorami. W tym podpisanym typie znaku można przechowywać wartości w zakresie od -128 do 127. Podczas korzystania z niepodpisanego typu znaków, wartości mogą mieścić się w zakresie od 0 do 255. Kod ASCII jest używany do kodowania ( American Standard Code Foe International Interchange). Symbole z kodami od 0 do 31 są usługi i mają niezależną wartość tylko w instrukcjach we / wy.
Wartości typu Char są również używane do przechowywania liczb z określonego zakresu
2.2.3. Wpisz Wchar_t.
Zaprojektowany do pracy z zestawem znaków do kodowania, który nie wystarczy 1 bajt, taki jak Unicode. Rozmiar tego typu, z reguły odpowiada typowi krótko. Stałe stałe tego typu są rejestrowane z prefiksem L: L "String # 1".
2.2.4. Typ Bool.
Typ Boola nazywa się logiczną. Jego wartości mogą podjąć prawdziwe i fałszywe wartości. Wewnętrzna forma reprezentacji FAŁSZA wynosi 0, każda inna wartość jest interpretowana jako prawdziwa.
2.2.5. Typy pływających punktów.
Wewnętrzna reprezentacja liczby rzeczywistej składa się z 2 części: Mantissa i zamówienia. W komputerze kompatybilnym z IBM wielkość typu pływaka jest zajmowane przez 4 bajty, z których jedno wyładowanie jest pobierane pod znakiem Mantissa, 8 wyładowani w ramach zamówienia i 24 - pod Mantissa.
Wartości typów podwójnych 2 bajtów 8 bajtów, 11 i 52 odprowadzane są odpowiednio w zamówieniu i Mantissa. Długość Mantissa określa dokładność liczby i długość jego zasięgu.
Jeśli przed podwójną nazwą jest długi opis, a następnie bajty podano pod wielkością.
2.2.6. Typ pustki
DO główne typy odnoszą się również do typu pustki wielu wartości tego typu -
2.3. Zmienne
Zmienna w C ++ jest nazwaną obszarem pamięci, w której przechowywane są dane. Zmienna ma nazwę i wartość. Nazwa służy do odnoszenia się do obszaru pamięci, w której przechowywana jest wartość. Przed użyciem każda zmienna musi być opisana. Przykłady:
Ogólny widok opisu opisu:
[Klasa pamięci] Wpisz nazwę [Inicjator];
Klasa pamięci może przyjmować wartości: auto, zewnętrzne, statyczne, rejestrować. Klasa pamięci określa żywotność i zakres zmiennej. Jeśli klasa pamięci nie została wyraźnie określona, \u200b\u200bkompilator określa jego na podstawie kontekstu reklam. Czas życia może być trwały - podczas wykonywania programu lub tymczasowego - podczas bloku. Zakres - część tekstu programu, z którego zakładamy zwykły dostęp do zmiennej. Zwykle zakres widoczności pokrywa się z obszarem działania. Ponadto w przypadku, gdy jest zmienna w bloku wewnętrznym o tej samej nazwie.
Const - wskazuje, że ta zmienna nie może zostać zmieniona (o nazwie stała). Podczas opisywania można przypisać zmienną wartość początkowa (inicjalizacja). Klasy pamięci:
auto -Automatyczna zmienna lokalna. Spektakl Auto można określić tylko przy określaniu obiektów blokowych, na przykład w funkcji ciała. Ta pamięć zmiennej jest zwolniona na wejściu do urządzenia i zostanie zwolniony podczas wyjścia. Poza blokiem, takie zmienne nie istnieją.
extern jest zmienną globalną, w innym miejscu programu (w innym pliku lub udział w tekście). Służy do tworzenia zmiennych dostępnych we wszystkich plikach programowych.
statyczne jest zmienną statyczną, istnieje tylko w granicach pliku, w którym zdefiniowano zmienną.
rejestr jest podobny do AUTO, ale pamięć jest przydzielana w rejestrach procesorów. Jeśli nie ma takiej możliwości, zmienne są przetwarzane jako auto.
int a; // Globalna zmienna Void Główna () (
int b; // zmienna lokalna
extern Int X; // zmienna X jest zdefiniowana w innym miejscu statyczna int C; // Lokalna zmienna statyczna A \u003d 1; // przypisanie zmiennej globalnej
int a; // zmienna lokalna a
a \u003d 2; // przypisanie zmiennej lokalnej :: a \u003d 3; // przypisanie zmiennej globalnej
int x \u003d 4; // definicja i inicjalizacja x
W przykładzie zmienna A jest określana poza wszystkimi blokami. Obszar działania zmiennej A jest cały program, z wyjątkiem tych wierszy, w których używany jest zmienna lokalna. Zmienne B i C - Lokalne, obszar ich widoczności jest blokiem. Życie życia: Pamięć pod b jest zwolniony podczas wprowadzania bloku (ponieważ domyślnie klasa automatycznej pamięci) jest zwolniona podczas wyjścia. Zmienna z (statyczna) istnieje, gdy program działa.
Jeśli przy określaniu wartości początkowej zmienne nie są wyraźnie określone, a następnie resetowanie kompilatorów Global i statyczne zmienne. Zmienne automatyczne nie są inicjowane ..
Nazwa zmiennej powinna być unikalna w swojej dziedzinie działania.
Opis zmiennej można zakończyć lub jako reklama lub jako definicja. AD zawiera informacje o klasie pamięci i rodzaju zmiennej, definicji wraz z tymi informacjami wskazuje na przydzielanie pamięci. W przykładzie zewnętrznego INT X; - ogłoszenie i reszta - definicje.
2.4.Same Operacje w C ++
Oznaki operacji zapewniają tworzenie wyrażeń. Wyrażenia składają się z operandów, objawów operacji i wsporników. Każdy operand jest z kolei ekspresja lub prywatny przypadek wyrażeń jest stała lub zmienna.
Operacje UNELARY.
& uzyskiwanie adresu operanda.
* Odwołaj się do adresu (zakres)
- uNILARY MINUS, zmienia znak operandu arytmetycznego
++ Zwiększenie według jednego:
operacja prefiksu - zwiększa operand do jego użycia
operacja postfix zwiększa operand po użyciu |
|
int a \u003d (m ++) + n; // a \u003d 4, m \u003d 2, n \u003d 2 |
|
int b \u003d m + (++ n); // a \u003d 3, m \u003d 1, n \u003d 3 |
|
redukcja na jednostkę: |
|
operacja prefiksu - zmniejsza operand do jego użycia |
|
operacja Postfix zmniejsza operand po użyciu |
|
rozmiar obliczania (w bajtach) dla obiektu tego typu |
|
ma operand. |
|
ma dwie formy |
|
rozmiar wyrażenia |
|
sizeof (float) // 4 |
|
sizeof (1.0) //8, t. Prawdziwe stałe domyślne |
|
|
Algopitis jest dokładnym i zrozumiałym przykładem artysty, aby spełnić sekwencję działań mających na celu rozwiązanie zadania. Nazwa "Algorytm" wystąpiła z łacińskiej formy nazwy Matematyki Azji Środkowej Al-Khorezmi - Algorytmi. Algorytm jest jedną z podstawowych koncepcji informatyki i matematyki. Wykonawca algorytmu jest jakiś abstrakcyjny lub prawdziwy (techniczny, biologiczny lub biotechniczny) system zdolny do wykonywania działań przepisanych przez algorytm. Artysta HampetavePiz: podstawowe działania; system zespołu; Absolwent (lub środowisko) to "siedlisko" artysty. Zatwierdzimy, że czytanie artysty z podręcznika szkolnego jest to nieskończone pole komórek. Ściany i komórek morskich są również częścią skrzyżowania. I ich pozytywne i stanowisko samego wyglądu ustanawiają stan podboju medium. Każdy wykonawca może wykonywać polecenia tylko z określonej listy zdefiniowanej - wykonawcy systemów poleceń. Dla każdego polecenia należy określić warunki (ponieważ Państwa instrukcji można wykonać) i opisuje wyniki polecenia. Zastosuj, polecenie "VVEPS" można wykonać, jeśli nie ma ściany powyżej. Jej wynik jest przesunięciem w jednej komórce w jednej komórce. Po wywołaniu polecenia wykonawca składa się z odpowiedniego działania podstawowego. Występują awarie wykonawcze, jeśli polecenie jest wywoływane w stanie niedopuszczalnym stanu stanu. Zwykle wykonawca nie zna nic o celu pojawienia się algo. Wykonuje wszystkie polecenia otrzymane bez zadawania pytań "dlaczego" i "dlaczego". W informatyce uniwersalny wykonawca algorytmów jest komputerem. Główne właściwości algorytmów są następujące: Zrozumiałość dla artysty - I.e. Wykonawca algorytmu powinien wiedzieć, jak go wykonać. Dyskrecja (przerwa, oddzielność) - I.e. Algoporty powinny otrzymać zadanie postępu jako sekwencyjnego wykonania następujących (lub bardziej oderwanych) kroków (kroków). Obowiązki - I.e. Każdy algorytm musi być jasny, jednoznaczny i nie opuszczać miejsc dla postępu. Dzięki tej właściwości wykonanie algorytmu jest obsługiwane mechanicznie i nie ma żadnych dodatkowych instrukcji ani informacji o zadaniu. Figura (lub kończyna). Ta właściwość polega na tym, że algorytm musi spróbować wypróbować zadanie ostatniej liczby kroków. Masażeństwo. Oznacza to, że algorytm zadania jest w formie ogólnej, tj. Musi być kucyk dla pewnej klasy zadań, które są tylko w danych źródłowych. W tym przypadku początkowe dane mogą być spożywane z określonego obszaru, który nazywa się obszarem algorytmu. W praktyce najczęściej występują następujące formy reprezentacji algorytmów: słowne (pisanie w języku naturalnym); grafika (obrazy z symboli graficznych); pseudocodes (pół-sformalizowane opisy algorytmów na warunkowym języku algorytmicznym, w tym zarówno elementy języka programowania, jak i frazy języka naturalnego, ogólnie przyjętych notacji matematycznej itp.); oprogramowanie (teksty w językach programowania). Werbalny sposób na rekordowy algorytmy jest opisem kolejnych etapów przetwarzania danych. Algorytm jest ustawiony w dowolnej prezentacji w języku naturalnym. Na przykład. Zapisz algorytm do znalezienia największego ogólnego rozdzielacza (węzła) dwóch numerów naturalnych. Algorytm może być następujący: ustaw dwie liczby; jeśli liczby są równe, a następnie weź dowolną z nich jako odpowiedź i zatrzymaj, w przeciwnym razie kontynuuj wykonanie algorytmu; określić więcej liczb; wymień więcej spośród różnicy w większym i mniejszym wśród liczb; powtórz algorytm z kroku 2. Opisany algorytm ma zastosowanie do dowolnych liczb naturalnych i powinien prowadzić do rozwiązania zadania. Upewnij się, że algorytm jest określany przy użyciu tego algorytmu największą wspólną dzielnik liczb 125 i 75. Metoda słowna nie jest szeroko rozpowszechniona z następujących powodów: takie opisy są ściśle nieformalizowane; cierpią na weryfikację zapisów; dostosuj dwuznaczność interpretacji poszczególnych przepisów. Graficzna metoda reprezentowania algorytmów jest bardziej kompaktowa i wizualna w porównaniu do słownego. Dzięki reprezentacji graficznej algorytm jest przedstawiony jako sekwencja połączonych bloków funkcjonalnych, z których każdy odpowiada wdrażaniu jednego lub więcej działań. Taka reprezentacja graficzna nazywana jest schematem algorytmu lub diagramu blokowego. Na schemacie blokowym każdy rodzaj działania (wejście danych początkowej, obliczanie wartości wyrażeń, warunki testowania, zarządzanie powtórzeniem, koniec przetwarzania itp.) Odpowiada kształt geometryczny reprezentowany jako symbol bloku. Symbole bloków są połączone liniami przejściowymi, które określają priorytet działania. Tabela 1 przedstawia najczęściej używane znaki. Blok procesu służy do wyznaczania działania lub sekwencji działań, które zmieniają wartość, formę reprezentacji lub umiejscowienie danych. Aby poprawić widoczność obwodu, kilka oddzielnych jednostek przetwarzania można łączyć w jeden blok. Prezentacja poszczególnych operacji jest dość wolna. Blok "Rozwiązanie" służy do wyznaczania przejść kontroli sterowania. W każdym bloku "Rozwiązanie" należy wskazać pytanie, stan lub porównanie, które określa. Jednostka "Modyfikacja" służy do organizowania struktur cyklicznych. (Modyfikacja słów oznacza modyfikację, transformację). Wewnątrz bloku, parametr cyklu jest rejestrowany, dla którego jego wartość początkowa jest określona, \u200b\u200bwarunek graniczny i etap zmiany wartości parametru dla każdego powtórzenia. Blok "predefiniowany proces" służy do wskazania odwołań do algorytmów pomocniczych, istniejących autonomicznie w postaci niektórych niezależnych modułów oraz odwoływanie się do podprogramów bibliotecznych. Pseudokodka jest systemem symboli i zasad przeznaczonych do jednolitego zapisu algorytmów. Zajmuje pośrednie miejsce między językami naturalnymi i formalnymi. Z jednej strony jest blisko zwykłego języka naturalnego, więc algorytmy można nagrać na nim i czytać jako zwykły tekst. Z drugiej strony, niektóre formalne projekty i symbole matematyczne są stosowane w pseudokodzie, co przynosi rekord algorytmu do ogólnie przyjętego rekordu matematycznego. Pseudokod nie podjęła ścisłych zasad składowych do rejestracji poleceń związanych z językami formalnymi, co ułatwia rejestr algorytmu na etapie jego projektu i umożliwia korzystanie z szerszego zestawu poleceń przeznaczonych do abstrakcyjnego artysty. Jednakże pseudokod ma zwykle niektóre projekty związane z językami formalnymi, co ułatwia przejście przed pisaniem do pseudokodu do nagrywania algorytmu w języku formalnym. W szczególności w pseudokodzie, a także w językach formalnych, istnieją oficjalne słowa, których znaczenie jest określane raz i dla wszystkich. Wyróżniają się w drukowanym tekście z odważną czcionką, a w podkreślonym tekście odręcznym. Nie ma pojedynczej lub formalnej definicji pseudo-formacji, dlatego możliwe są różne pseudokody, charakteryzujące się zestawem słów usługowych i podstawowych (podstawowych) struktur. Przykładem pseudokodki jest językiem algorytmicznym szkolnym w notacji rosyjskiej (szkoła (szkoła), opisana w samouczku A.G. Kushnirenko i in. "Podstawy informatyki i obliczenia", 1991. Ten język będzie nazywany po prostu "językiem algorytmicznym" w przyszłości. Główne słowa usługi Ogólny widok algorytmu: algorytm nazwy alg (argumenty i wyniki) warunki stosowania algorytmu konieczne jest wykonanie algorytmu nCH \u200b\u200bOpis wartości pośrednich |. Sekwencja komunikacyjna (algorytm ciała) Część algorytmu ze słowa Alg do słowa NCH nazywana jest tytułem, a część zawarta między słowami początku a organami algorytmem. W zdaniu Alg Po nazwisku algorytmu w nawiasach, charakterystyki (Arg, CR) i rodzaj wartości (dla argumentu, 1, lite lub log) (dla argumentów) oraz zmiennych wyjściowych (wyników) . Opisując tablice (tabele), używany jest słowo usługi, uzupełnione parami brzegowymi dla każdego indeksu elementów tablicy. Przykłady ofert Alg: obszar objętości i cylindrów w obiekcie (Arg Mane R, H, Cut V, S) alg korzenie SMB (Arg Mana A, B, C, Cut Mee X1, X2, Res Lite T) alg Exclude Element (Arg Complex N, Arg Dres Tab a) alg Diagonal (Arg Complex N, Karta komunikacji ARG A, CRA oświetlona OTVET) Oferty są podane i niekoniecznie. Zaleca się rejestrowanie stwierdzeń opisujących stan środowiska algorytmu wykonawczego, na przykład: wymiana aleg (Arg Lit Str1, Str2, Tekst Crasus Crop Crop) dano |. Str1 i Str2 Długość substytucji zbiegają jest to konieczne | Wszędzie w linii tekstowej Str1 zastąpiona STR2 aLG Liczba Maxima (Arg Cover N, Arg Tab A, RESH K) dano |. N\u003e 0. jest to konieczne | K - liczba maksymalnych elementów w tabeli A oporność Alg (Arg Mane R1, R2, Arg Complex N, Com R) dano |. N\u003e 5, R1\u003e 0, R2\u003e 0 jest to konieczne | R - Rezystancja schematu Tutaj w zdaniach są podane i konieczne po znaku "|" Uwagi są rejestrowane. Komentarze można umieścić na końcu dowolnego ciągu. Nie są one przetwarzane przez tłumacza, ale znacząco ułatwiają zrozumienie algorytmu. Algorytmy mogą być reprezentowane jako niektóre struktury składające się z oddzielnych elementów podstawowych (I.e. Basic). Naturalnie, z tym podejściem do algorytmów, badanie podstawowych zasad ich projektu powinno rozpocząć się od badania tych podstawowych elementów. Dla ich opisu będziemy wykorzystywać język algorytmów i języka algorytmicznego szkolnego. Logiczna struktura dowolnego algorytmu można przedstawić z kombinacją trzech podstawowych struktur: podążać rozgałęzienie Charakterystyczną cechą podstawowych struktur jest obecność jednego wejścia i jednego wyjścia. Wpisz słowa kluczowe. Dzwon.Są ci, którzy przeczytali tę wiadomość przed tobą. Subskrybuj odbieranie artykułów świeżych. |