Jaki jest semantyczny rdzeń witryny? Semantyczny rdzeń (zwany dalej SIA.) - jest to połączenie słów kluczowych i zwrotów, przez które zasoby promuje w wyszukiwarkach i wskazują na przynależność strony do pewnego temat.
W przypadku pomyślnej promocji w wyszukiwarkach, słowa kluczowe muszą być prawidłowo pogrupowane i rozpowszechniane za pomocą stron witryny i w pewnym formularzu, aby zawierać w meta-opisie (,, Słowa kluczowe), jak również w nagłówkach H1-H6. Jednocześnie niemożliwe jest pozwolenie na wymianę, aby nie "odlecieć" do Baden-Baden.
W tym artykule staramy się spojrzeć na pytanie nie tylko z technicznego punktu widzenia, ale także spojrzeć na problem z oczami właścicieli biznesu i marketerów.
Co dzieje się zebrać?
- Dłoń - Być może dla małych stron (do 1000 słów kluczowych).
- Automatyczny - Programy nie zawsze poprawnie określają kontekst wniosku, więc mogą wystąpić problemy z dystrybucją słów kluczowych na stronach.
- Półautomatyczny - Zwroty i częstotliwość są gromadzone automatycznie, dystrybucja fraz i wyrafinowania występuje ręcznie.
W naszym artykule rozważymy półautomatyczne podejście do stworzenia jądra semantycznego, ponieważ jest najbardziej skuteczny.
Ponadto podczas opracowywania dwóch typowych przypadków:
- dla witryny z gotową strukturą;
- na nową stronę.
Bardziej korzystna jest druga opcja, ponieważ możliwe jest, aby idealna struktura witryny w wyszukiwarce.
Jaki jest proces sporządzania?
Praca nad tworzeniem jądra semantycznego jest podzielona na następujące kroki:
- Przydział obszarów, dla których strona się poruszy.
- Zbieraj słowa kluczowe, analizę podobnych żądań i wskazówek wyszukiwania.
- Parasowanie częstotliwości, "puste" żądania.
- Clustering (grupowanie) żądania.
- Dystrybucja żądań na stronach stron (opracowywanie idealnej struktury witryny).
- Zalecenia do użycia.
Im lepiej tworzysz jądro witryny, a jakość w tym przypadku oznacza szerokość i głębokość badania semantyki, potężniejszy i niezawodny przepływ ruchu wyszukiwania może być w stanie wysłać do witryny i większej przyciągania klientów .
Jak zrobić rdzeń semantyczny
Rozważmy więc każdy przedmiot z różnymi przykładami bardziej szczegółowo.
W pierwszym kroku ważne jest określenie, które towary i usługi obecne na stronie będą poruszać się w wyszukiwaniu Yandex i Google.
Przykład numer 1. Załóżmy, że na tej stronie znajdują się dwa kierunki usług: naprawa komputerów w domu i szkolenia ze słowem / exel w domu. W tym przypadku zdecydowano, że szkolenie nie jest już na żądanie, więc nie ma sensu promować, co oznacza zbieranie semantyki na nim. Inny ważny punkt, musisz zebrać nie tylko żądania "Naprawa komputerów w domu", ale również "Naprawa laptopów, naprawy PC" i inni.
Przykład numer 2. Firma zajmuje się niską konstrukcją. Ale jednocześnie buduje tylko drewniane domy. W związku z tym żądania i semantyka w kierunkach "Budowa domów z betonu napowietrzonego"lub "Budowa domów z cegły"nie możesz zbierać.
Kolekcja semantyki
Spojrzymy na dwa główne źródła słów kluczowych: Yandex i Google. Opowiemy, jak zbierać semantykę za darmo i krótko przewidywać płatne usługi, które pozwalają przyspieszyć i zautomatyzować ten proces.
W Yandex kolekcja fraz kluczowych odbywa się z Yandex. Usługa Avordstat i Google poprzez statystyki żądań w Google AdWords. Jeśli masz dodatkowe źródła semantyki, możesz użyć danych Yandex Webmaster Data i Metrics Yandex, Google Webmaster i Google Analytics.
Zbieranie słów kluczowych z Yandex.sordstat
Kolekcja żądań z Vordstat można uznać za darmo. Aby wyświetlić tę usługę, potrzebujesz tylko konta w Yandex. Więc idź do wordstat.yandex.ru.i wprowadź słowo kluczowe. Rozważmy przykład zbierania semantyki do wypożyczalni samochodów.

Co widzimy w tym zrzucie ekranu?
- Lewa kolumna. Główna prośba i jego różne odmiany "Ogon."Naprzeciwko każdego zapytania kosztuje numer pokazujący, ile tego żądania generał Został używany przez różnych użytkowników.
- Prawa kolumna. Wnioski są podobne do głównego i wskaźników ich ogólnej częstotliwości. Tutaj widzimy, że osoba, która chce wynająć samochód, z wyjątkiem prośby "wypożyczalnia samochodów",można użyć "Wynajem samochodu", "Wynajem samochodów", "Wynajem samochodów"i inni. Są to bardzo ważne dane, aby zwrócić uwagę, aby nie przegapić żadnego wniosku.
- Regionalność i historia. Wybierając jedną z możliwych opcji, możesz sprawdzić rozkład żądań według regionu, liczbę żądań w oddzielnym regionie lub mieście, a także tendencję do zmian w czasie lub z zmianą roku.
- Urządzeniaz którego złożono wniosek. Przełączanie kart, można dowiedzieć się, które urządzenia najczęściej szukają.
Sprawdź różne opcje dla kluczowych fraz, a odebrane dane są przymocowane do tabeli Exel lub w tabelach Google. Dla wygody zainstaluj wtyczkę Pomocnik Yandex WordStat. Po jego instalacji Plusy pojawią się obok fraz wyszukiwania, po kliknięciu, do którego zostaną skopiowane, nie będzie konieczne, aby przydzielić i włożyć wskaźnik częstotliwości ręcznie.
Zbieraj słowa kluczowe z Google AdWords
Niestety, Google ma otwarte źródło zapytań wyszukiwania z wskaźnikami częstotliwości, więc konieczne jest działanie tutaj przez obejście. I dla tego potrzebujemy konta roboczego w Google AdWords.
Rejestrujemy konto w Google AdWords i uzupełnić saldo dla najniższej możliwej kwoty - 300 rubli (na nieaktywnym koncie budżetu konta wyświetlane są przybliżone dane). Po tym przejdziemy do "narzędzi" - "harmonogram Hasło".

Nowa strona zostanie otwarta w "Wyszukiwanie nowych słów kluczowych na karcie frazy, witryny lub kategorii" wprowadź słowo kluczowe.

Przewiń w dół, naciśnij "Uzyskaj opcje" i zobacz w przybliżeniu takie zdjęcie.

- Główna prośba i przeciętne zapytania miesięcznie. Jeśli konto nie zostało zapłacone, zobaczysz przybliżone dane, czyli średnią liczbę żądań. Jeśli istnieją środki na koncie, pojawi się dokładne dane, a także dynamika zmiany częstotliwości wprowadzonego klucza.
- Słowa kluczowe na temat znaczenia. Jest to tak samo jak podobne żądania do Yandex WordStat.
- Pobieranie danych. To narzędzie jest wygodne, ponieważ można pobrać dane.
Patrzyliśmy na pracę z dwoma głównymi źródłami statystyk na zapytaniach wyszukiwania. Teraz zwróćmy się do automatyzacji tego procesu, ponieważ kolekcja semantyki ręcznie trwa zbyt wiele czasu.
Programy i usługi do zbierania słów kluczowych
Kluczowy kolektor.
Program jest zainstalowany na komputerze. Program obejmuje konta robocze z miejsca, w którym zostaną zebrane statystyki. Poniżej znajduje się nowy projekt i folder słów kluczowych.
Wybierz "kolekcję wsadowej słów z lewej kolumny Yandex.wordstat", wprowadź żądania, dla których gromadzi dane.

W zrzucie zrzutu ekranu został wprowadzony, w rzeczywistości, w rzeczywistości, aby uzyskać bardziej kompletny uśmiech, jest dodatkowo konieczne, aby zebrać wszystkie opcje zapytań ze znaczkami samochodowymi i zajęciami. Na przykład "BMW do wynajmu", "Kup Toyota po prawej stronie odkupienia", "Wynajem SUV" i tak dalej.
Slobel.
Darmowy analog Poprzedni program. Można to uznać za plus - nie ma potrzeby płacenia i minus - program ma znacznie przycięte funkcjonalność.
Aby zbierać słowa kluczowe, działania są takie same.
Rush-analytics.ru.
Serwis internetowy. Jego główną zaletą - nie musisz nic pobierać i instalować. Zarejestrowałem się i używam. Usługa jest wypłacana, ale podczas rejestracji na Twoim koncie istnieje 200 monet, co jest wystarczająco dość, aby zebrać małe semantyki (do 5000 żądań) i rozwiązywać częstotliwość.
Minus - kolekcja semantyki tylko z Wordstat.
Sprawdź częstotliwość słów kluczowych i żądań

I znowu zauważ zmniejszenie liczby żądań. Idziemy dalej i wypróbujemy kolejną formę słowa tej samej prośby.

Należy zauważyć, że w liczbie pojedynczej, ta prośba szuka znacznie mniejszej liczby użytkowników, co oznacza, że \u200b\u200bpoczątkowy wniosek dla nas jest bardziej priorytetowy.
Takie manipulacje muszą być wykonane za pomocą każdego słowa i frazy. Zapytania te, w których końcowa częstotliwość jest zerowa (przy użyciu cytatów i wykrzyknik), są przesiane, ponieważ "0" - sugeruje, że nikt nie wprowadza takich żądań, a te prośby są tylko częścią innych. Znaczenie przygotowania jądra semantycznego jest wybranie żądań, które wykorzystują ludzi do wyszukiwania. Wszystkie żądania są następnie umieszczane w tabeli Exel, są zgrupowane przez znaczenie i są rozprowadzane za pośrednictwem stron witryny.

W ręku nie jest to po prostu prawdziwe, więc w Internecie istnieje wiele usług, płatnych i bezpłatnych, co pozwala to zrobić automatycznie. Dajemy kilka:
- megaindex.com;
- rush-analytics.ru;
- narzędzia.pixelplus.ru.;
- key-Collector.ru.
Usuń żądania niecelowe
Po poszukiwaniu słów kluczowych należy usunąć niepotrzebne. Jakie zapytania można usunąć z listy?
- wnioski o nazwy firm konkurencyjnych (możesz opuścić b);
- prośby o towary lub usługi, których nie sprzedajesz;
- Żądania, w których określono obszar lub obszar, w którym nie działa.
Clustering (grupowanie) Wnioski o stronę witryny
Istotą tego etapu jest połączenie podobnych wniosków do klastrów podobnych, a następnie określają, które strony będą się poruszać. Jak zrozumieć, które prośby o promowanie jednej strony i co innego?
1. według rodzaju żądania.
Wiemy już, że każdy jest podzielony na kilka gatunków, w zależności od celu wyszukiwania:
- komercyjne (Kupię, Sprzedaż, Zamówienie) - Przejdź do stron lądowania, strony kategorii towarów, karty towarów, strony z usługami, stronami cenowymi;
- informacje (gdzie, jak, dlaczego, dlaczego) - artykuły, tematy forów, kierując odpowiedź na pytanie;
- nawigacja (telefon, adres, marka) - Strona z kontaktami.
Jeśli wątpisz, jaki rodzaj żądania wprowadź swój ciąg wyszukiwania i analizuj wydawanie. W przypadku prośby handlowej będzie więcej stron z sugestią usług, na temat informacji.
Także jest. Większość prośby handlowych jest geo-zależna, ponieważ ludzie głównie zaufają firmom w swoim mieście.
2. Logika zapytania.
- "Kup iPhone X" i "iPhone X Cena" - musisz promować jedną stronę, jak w pierwszej i drugiej sprawy, ten sam produkt jest wyszukiwany, a bardziej szczegółowe informacje o tym;
- "Kup iPhone" i "Kup iPhone X" - musisz promować różne strony, ponieważ w pierwszej prośbie mamy do czynienia z wspólnym wnioskiem (nadaje się do kategorii produktu, gdzie znajdują się iPhony), aw drugim użytkownik jest Szukasz konkretnego produktu, a ten wniosek dotyczy Promowanie karty towarów;
- "Jak wybrać dobry smartfon" - to żądanie jest bardziej logiczne, aby promować artykuł o blogu z odpowiednią nazwą.
Wyświetl wyniki wyszukiwania na nich. Jeśli sprawdź, które strony z różnych witryn znajdują się zapytania "Budowa domów z barze" i "Budowa domów z cegły", a następnie w 99% przypadków są to różne strony.
4. Automatyczne grupowanie z oprogramowaniem i refinementem ręcznym.
Pierwsze i drugie metody doskonale nadają się do przygotowania semantycznego rdzenia małych stron, w których zebrano maksymalnie 2-3 tysiąc słów kluczowych. Dla dużych uśmiechniętych (od 10 000 do nieskończoności prośby), potrzebujesz pomocy maszyn. Oto kilka programów i usług, które umożliwiają wykonywanie kasetanizacji:
- KeyAssistant - Assistant.Contentmonster.ru;
- semparser.ru;
- just-Magic.org;
- rush-analytics.ru;
- narzędzia.pixelplus.ru.;
- key-Collector.ru.
Po zakończeniu klastrowania automatycznego konieczne jest sprawdzenie wyniku pracy programu w ręku i jeśli wystąpiono błędy - poprawne.
Przykład: Program może wysłać następujące żądania do jednego klastra: "Odpoczynek w Soczi 2018 Hotel" i "odpoczynek w Soczi 2018 Hotel Breeze" - W pierwszym przypadku użytkownik poszukuje różnych opcji zakwaterowania, aw drugim, konkretnym hotelu .
Aby wykluczyć występowanie takich niedokładności, konieczne jest ręczne sprawdzenie wszystkiego, a gdy zostanie wykryte błędy, edytuj.
Co dalej? Po sporządzaniu jądra semantycznego?
Na podstawie zebranego jądra semantycznego, wtedy:
- tworzymy idealną strukturę (hierarchia) witryny, z punktu widzenia wyszukiwarek;
lub W koordynacji z klientem zmieniamy strukturę starej strony; - piszemy zadania techniczne w celu napisania tekstu, biorąc pod uwagę, że gromada żądań, które będą promowane na tych stronach;
lub Uwzględniamy stare artykuły teksty na stronie.
To wygląda tak.

W każdym klastrze żądania tworzymy stronę na stronie i definiujemy to miejsce w strukturze witryny. Najbardziej popularne prośby są promowane na najwyższe strony w hierarchii zasobów, mniej popularne znajdują się pod nimi.
I dla każdej z tych stron zebraliśmy zapytania, które je promowujemy. Następnie napisz TK Copywriters, aby wykonać tekst dla tych stron.
Zadania techniczne dla Copywriter
Podobnie jak w przypadku struktury witryny, opisujemy ten etap ogólnie. Tak więc zadanie techniczne tekstu:
- liczba znaków bez przestrzeni;
- tytuł strony;
- napisy (jeśli są);
- lista słów (na podstawie naszego jądra), która powinna być w tekście;
- wymóg wyjątkowości (zawsze wymaga 100% wyjątkowości);
- Żądany styl tekstu;
- inne wymagania i życzenia w tekście.
Pamiętaj, że nie muszę próbować promować jedną stronę +100500 żądań, limit 5-10 + ogon, w przeciwnym razie otrzymasz zakaz na pokonanie i czołganie się z gry na górze.
Wynik
Kompilacja semantycznego rdzenia witryny jest żmudna i ciężka praca, która musi zostać wypłacona szczególnie szczególnie szczególnie uwagi, ponieważ jest to, że opiera się na dalszej promocji witryny. Postępuj zgodnie z prostą instrukcją podaną w tym artykule i działa.
- Wybierz kierunek promocji.
- Zbierz wszystkie możliwe prośby z Yandexa i Google (używaj specjalnych programów i usług).
- Sprawdź częstotliwość żądań i pozbyć się pacyfikatorów (które mają częstotliwość - 0).
- Usuń żądania niecelowe - usługi i towary, których nie sprzedajesz, wniosek o wzmiankę o konkurentach.
- Uformuj klastry żądania i rozpowszechniać je przez strony.
- Utwórz idealną strukturę witryny i wykonaj TK na wypełnianie witryny.
Kernel semantyczny jest ładnym tematem, prawda? Dziś naprawimy to razem, zbierając semantykę w tej lekcji!
Nie wierz? - Spójrz na siebie - wystarczy, żeby jechać do Yandex lub Google frazy semantyczny rdzeń witryny. Myślę, że dzisiaj naprawię ten denerwujący błąd.
Ale w rzeczywistości, co ona jest dla ciebie - doskonała semantyka? Możesz myśleć, że na głupie pytanie, ale w rzeczywistości jest całkowicie Nehall, tylko większość właścicieli internetowych i właścicieli witryn uważa, że \u200b\u200bmogą zrobić jądra semantyczne i że każdy uczeń radzi sobie z tym wszystkim, tak, oni sami próbują uczyć innych ... Ale w rzeczywistości wszystko jest o wiele trudniejsze. Kiedyś mnie zapytałem - co powinienem zrobić na początku? - strona i treść lub sSE Kernel.i poprosił osobę, która nie uważa się za nowicjusza w CEO. To jest pytanie i dał mi zrozumieć złożoność i dwuznaczność tego problemu.
Rdzeń semantyczny jest podstawą podstawy - pierwsza komora, która stoi przed i uruchomieniem dowolnej kampanii reklamowej w Internecie. Wraz z tym semantyka witryny jest najbardziej energicznym procesem, który będzie wymagał dużo czasu, ale z większym podziękowaniami w każdym razie.
Cóż ... Utwórzmy jego razem!
Mała przedmowa
Aby utworzyć pole semantyczne witryny, będziemy potrzebować jednego jedynego programu - Kluczowy kolektor.. Na przykładzie kolekcjonera zdecyduję się na przykład zbieranie małej grupy. Oprócz płatnego programu znajdują się także bezpłatne analogi, takie jak slobel i inni.
Semantyki zebrane w kilku podstawowych etapach, wśród których należy przeznaczyć:
- burza mózgów - analiza podstawowych fraz i szkolenia parsowania
- parsowanie - rozbudowa podstawowych semantyki na podstawie Vordstat i innych źródeł
- otwarcie - upuszczanie po parsowaniu
- analiza - analiza częstotliwości, sezonowości, konkurencji i innych ważnych wskaźników
- wyrafinowanie - Grupowanie, Separacja nukleuszów wyrażeń handlowych i informacyjnych
Najważniejsze etapy zbierania i zostaną omówione poniżej!
Wideo - Kompilacja jądra semantycznego konkurentów
Burza mózgów podczas tworzenia jądra semantycznego - mózg
Na tym etapie jest to konieczne na uwadze, aby dokonać wyborusemantyczny rdzeń witryny i pojawia się jak najwięcej fraz w naszym obiekcie. Więc uruchom kolektor Kay i wybierz parsowanie WordStat., jak pokazano na zrzucie ekranu:

Mamy małe okno, w którym musisz wprowadzić maksymalne frazy na naszym obiekcie. Jak już powiedziałem, W tym artykule utworzymy przykład zestaw fraz dla tego blogaWięc frazy mogą być następujące:
- sEO Blog.
- sEO Blog.
- blog o SEO.
- blog o SEO.
- awans
- awans projekt
- awans
- awans
- promocja blogów.
- blog Promocja
- promocja bloga
- blog Promocja
- artykuły promocyjne
- aktywowana promocja.
- miraliinki.
- pracuj w Sape.
- kupowanie linków
- zakup linków
- optymalizacja
- optymalizacja strony
- optymalizacja wewnętrzna
- niezależna promocja
- jak promować zasób
- jak promować swoją witrynę
- jak same promować stronę
- jak same promować stronę
- niezależna promocja
- bezpłatna promocja
- bezpłatna promocja.
- optymalizacja wyszukiwarki
- jak promować witrynę w Yandex
- jak promować witrynę w Yandex
- promocja pod Yandex.
- promocja w ramach Google.
- promocja w Google.
- indeksowanie
- indekacja przyspieszenia
- wybierz stronę Donor.
- donor Checkout.
- promocja Postov.
- za pomocą postów.
- promocja bloga
- algorytm Yandex.
- zaktualizuj TITZ.
- wyszukaj aktualizację bazy danych.
- updent Yandex.
- linki na zawsze
- wieczne odniesienia
- wynajem linki
- odnośnik wynajmu
- linki z miesięczną płatnością
- kompilacja jądra semantycznego
- tajemnice Promocja.
- tajemnice Promocja.
- sEO SEO.
- optymalizacja tajemnic
Myślę, że wystarczy, a także lista z podłogi strony;) \u200b\u200bw ogóle pomysł jest tym, że na pierwszym etapie musisz przeanalizować nasz branżę, aby zmaksymalizować i wybrać tyle fraz odzwierciedlających temat witryny. Chociaż jeśli nie przegapiłeś niczego na tym etapie - nie rozpaczaj - umplified frazy będą musiały pojawić się na następujących etapachPo prostu muszę zrobić dużo dodatkowej pracy, ale nic strasznego. Bierzemy naszą listę i skopiujemy do Key Collector. Następnie kliknij przycisk - Pule z Yandex.wordstat.:
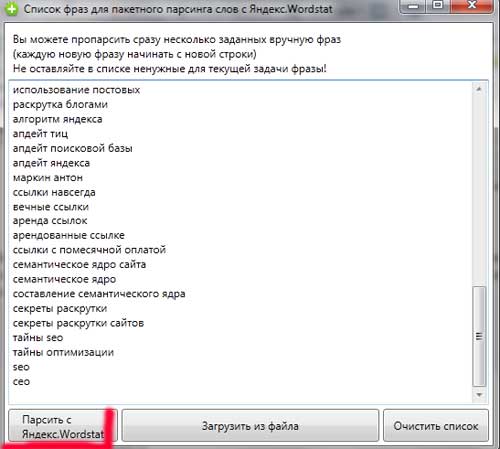
Parsowanie może trwać sporo czasu, więc powinieneś być cierpliwy. Kernel semantyczny zwykle prowadzi się do 3-5 dni, a pierwszy dzień pójdziesz do przygotowania podstawowego jądra semantycznego i parsowania.
O tym, jak pracować z zasobem, jak wybrać słowa kluczowe napisałem szczegółową instrukcję. I możesz dowiedzieć się o promocji witryny na żądaniach NF.
Ponadto powiem, że zamiast burzy mózgów, możemy skorzystać z semantyki konkurentów z jednym z wyspecjalizowanych usług, na przykład Spywords. W interfejsie tej usługi po prostu wpisujemy potrzebujesz słowa kluczowego i zobaczyć głównych konkurentów, którzy są obecni w tej frazie na górze. Ponadto semantyka witryny dowolnego konkurenta może być całkowicie rozładowana z tą usługą.

Następnie możemy wybrać dowolny z nich i wyciągnąć swoje żądania, które pozostaną od śmieci i wykorzystania jako podstawowe semantyki do dalszego parsowania. Albo możemy to zrobić jeszcze łatwiejsze i używać.
Czyszczenie semantyki
Jak tylko wordstat parsuje się w pełni - nadszedł czas, aby odciąć jądro semantyczne. Ten etap jest bardzo ważny, więc powinniśmy wziąć to z należytą uwagą.
Więc skończyło się, że mój parsowanie, ale okazały się frazy WieleDlatego słowa słów może zabrać od nas za dużo. Dlatego przed przystąpieniem do definicji częstotliwości konieczne jest wytworzenie pierwotnego czyszczenia słów. Zrobimy to w kilku etapach:
1. Filtruj zapytania z bardzo niską częstotliwością
Aby to zrobić, opiera się na symbol sortowania w częstotliwości i zacznij wyodrębniać wszystkie żądania, które mają częstotliwości poniżej 30:
Myślę, że z tym elementem możesz łatwo poradzić sobie.
2. Usuń nie nadaje się do żądań znaczenia
Istnieją takie zapytania, które mają wystarczającą częstotliwość i niską konkurencję, ale oni w ogóle nie nadają się do naszego tematu. Takie klucze muszą zostać usunięte przed sprawdzeniem dokładnych celów klucza, ponieważ Sprawdź, czy może zająć dużo czasu. Usuniemy takie klucze, które będziemy ręcznie. Więc na mój blog, byli niepotrzebni:
kursy optymalizacji w wyszukiwarkach sprzedaż witryny promocyjnej.
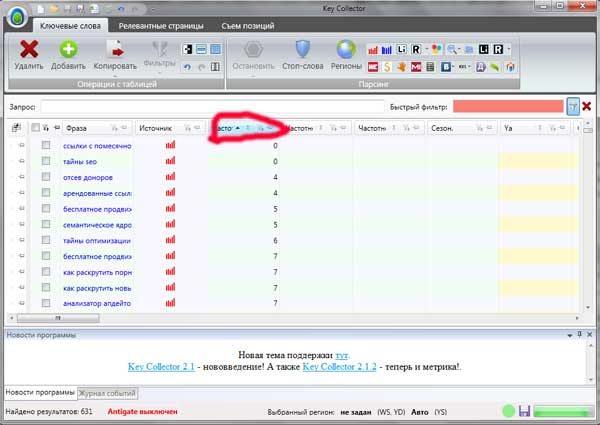
Analiza jądra semantycznego
Na tym etapie musimy określić dokładną częstotliwość naszych kluczy, dla których trzeba kliknąć symbol lupy, jak pokazano na obrazie:

Proces jest dość długi, więc możesz iść do herbaty)
Gdy sprawdzenie zakończyło się sukcesem - konieczne jest kontynuowanie sprzątania naszego jądra.
Proponuję usunąć wszystkie klucze z częstotliwością mniej niż 10 prośbami. Na blogu usuwam wszystkie żądania, które mają wartości powyżej 1000, ponieważ nadal nie planuję takich żądań.
Eksport i grupowanie jądra semantycznego
Nie myśl, że ten etap będzie ostatnim. Ani trochę! Teraz musimy przenieść wynikową grupę, aby exel dla maksymalnej widoczności. Następnie sortujemy przez strony, a następnie zobaczymy wiele niedociągnięć, których korekta, z którymi zajmiemy się.
Eksportowane semantyki witryny w Exel jest całkowicie łatwe. Aby to zrobić, wystarczy kliknąć odpowiedni znak, jak pokazano na obrazie:
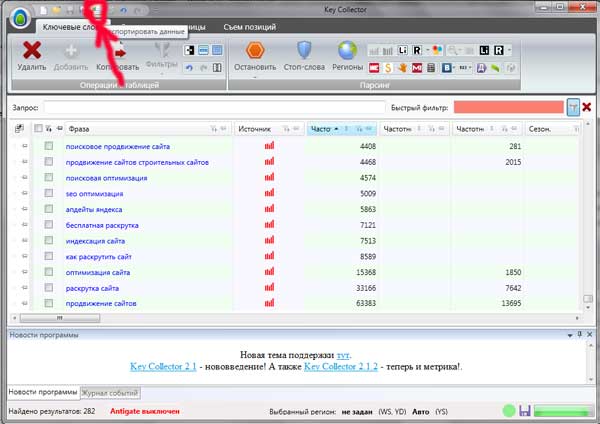
Po wprowadzeniu do Exel zobaczymy następujące zdjęcie:
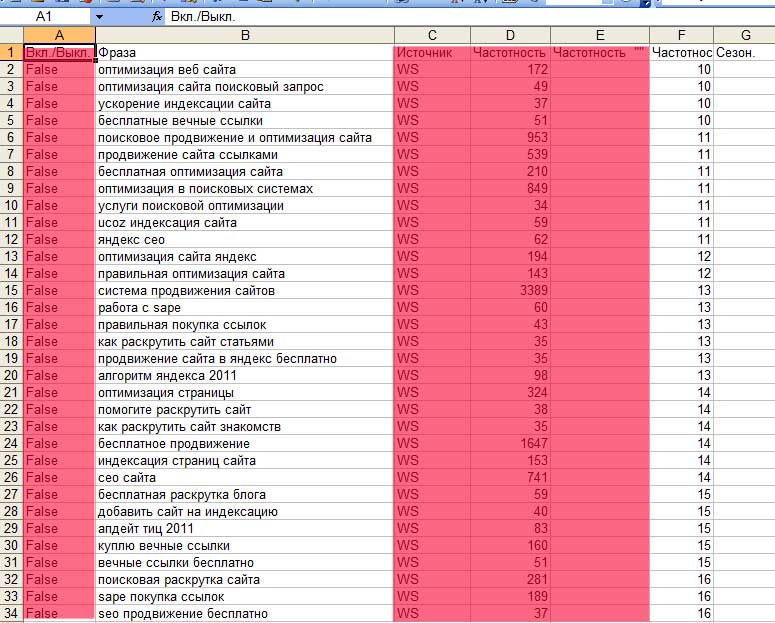
Kolumny oznaczone czerwonym należy usunąć. Następnie utwórz kolejną tabelę w Exel, gdzie zostanie zamknięty końcowy jądro semantyczne.
Nowa tabela będzie 3 kolumny: URL.strony, fraza kluczowa i to częstotliwość. Jako adres URL wybierz lub już istniejącą stronę lub stronę, która zostanie zaprojektowana w perspektywie. Zacznijmy, wybierzmy klucze na główną stronę mojego blogu:

Po wszystkich manipulacjach widzimy poniższy obraz. I natychmiast sugeruje kilka wniosków:
- takie zapytania o częstotliwości, potrzebne, aby mieć znacznie większy ogon z mniejszych fraz częstotliwości niż widzimy
- News SEO.
- nowy klucz naczynił, który nie zajęliśmy wcześniej - artykuły CEO.. Trzeba przeanalizować ten klucz
Jak powiedziałem, nie ma żadnego klucza do ukrycia. Następnym krokiem dla nas będzie burzy mózgów tych trzech fraz. Po brainstormingu powtarzamy wszystkie kroki zaczynające się od pierwszego pierwszego elementu dla tych kluczy. Wszyscy jesteśmy dla ciebie zbyt długi i żmudny, ale jest to - kompilacja semantycznego jądra jest bardzo odpowiedzialna i żmudna praca. Ale kompetentnie skomponowana sekta znacznie pomogą w promowaniu witryny i może bardzo zaoszczędzić budżet.
Po wszystkich wpływie udało nam się uzyskać nowe klucze na stronę główną tego blogu:
- najlepszy blog SEO.
- news SEO.
- artykuły SEO.
I kilka innych. Myślę, że technika jest dla ciebie zrozumiała.
Po tych wszystkich manipulacjach zobaczymy, które strony naszego projektu muszą zostać zmienione () i jakie nowe strony muszą dodać. Większość kluczy znaleziony przez nas (z częstotliwością do 100, a czasami znacznie wyższa) może być łatwo promowana sama.
Końcowy odlew
Zasadniczo rdzeń semantyczny jest prawie gotowy, ale jest inny dość ważny punkt, który pomoże nam zauważalnie poprawić naszą grupę ustanawiającej. Za to potrzebujemy Seopult.
* W rzeczywistości można użyć dowolnej z podobnych usług, które pozwalają nauczyć konkurencji według słów kluczowych, na przykład mutagen!
Tworzymy inny stół w Exel i skopiujemy tylko nazwy kluczy (kolumna średnia). Nie spędzać dużo czasu, skopiuję tylko klucze na główną stronę blogu:

Następnie sprawdź koszty uzyskania jednego przejścia do naszych słów kluczowych:
Koszt przejścia na niektóre frazy przekroczyły 5 rubli. Takie frazy muszą być wykluczone z naszego jądra.

Być może twoje preferencje będą nieco inne, wtedy możesz wykluczyć tańsze frazy lub odwrotnie. W swojej sprawie usunąłem 7 fraz.
Pomocna informacja!
w zależności od przygotowania jądra semantycznego, z koncentracją na badaniach słów kluczowych najbardziej niskiej konkurencji.
Jeśli masz sklep internetowy - czytać , gdzie jest opisany, w jaki sposób można użyć rdzenia semantycznego.
Klastrowanie jądra semantycznego
Jestem pewien, że wcześniej miałeś go usłyszeć to słowo jako stosowane do Promocji wyszukiwania. Wyraźmy to, jakiego rodzaju bestii jest tak i dlaczego jest potrzebny przy promowaniu witryny.
Klasyczny model promocji wyszukiwania wygląda tak:
- Wybór i analiza zapytań wyszukiwania
- Grupowanie zapytań na stronach stron (stron docelowych)
- Przygotowanie tekstów SEO do stron lądowania na podstawie grupy zapytań dla tych stron
Aby ułatwić i poprawić drugi etap na liście powyżej i służy jako klastrowy. W istocie klastra jest metodą oprogramowania, która służy do uproszczenia tego etapu podczas pracy z dużą semantyką, ale wszystko nie jest tak proste, jak może się wydawać na pierwszy rzut oka.
Aby lepiej zrozumieć teorię klastrowania, powinieneś zrobić małą wycieczkę do historii SEO:
Dosłownie kilka lat temu, kiedy termin klastrowy nie zwrócił na każde rogu - Sieny, w przytłaczającej większości przypadków, pogrupowanej przez semantyki z rękami. Ale przygniąc ogromną semantykę w 1000, 10 000, a nawet 100.000 wniosków, procedura ta zmieniła się w prawdziwą ciekawę dla zwykłej osoby. A następnie metodologia grupy semantyki zaczęła się wszędzie korzystać (a dziś wiele wykorzystuje to podejście). Semantyczna technika grupowania polega na łączeniu w jedną grupę zapytań o relacjach semantycznych. Jako przykład - żądania "Kupić pralkę" i "Kupić pralkę do 10 000" połączonych w jedną grupę. I wszystko będzie dobrze, ale ta metoda zawiera szereg krytycznych problemów i ich zrozumienia konieczne jest wprowadzenie nowego terminu w naszej narracji, a mianowicie - " prośba intencyjna”.
Najprostszym sposobem opisania tego terminu może być jako potrzeba użytkownika, jego pragnienie. Intovent nie jest niczym więcej niż pragnieniem użytkownika wprowadzającego zapytanie do wyszukiwania.
Podstawą grupy semantyki jest zebranie w jednej grupie wniosków o tym samym zamiarze lub tak blisko, jak to możliwe intensywność, a tutaj pojawia się 2 interesujące funkcje, a mianowicie:
- To samo zamiar może mieć kilka wniosków, które nie mają żadnej bliskości semantycznej, na przykład - "Serwis samochodowy" i "Zarejestruj się"
- Wnioski, które mają absolutną bliskość semantyczną, mogą zawierać radykalnie różne intensyza, na przykład, sytuacja podręcznika jest "telefon komórkowy" i "telefonami komórkowymi". W jednym przypadku użytkownik chce kupić telefon, aw innym, aby obejrzeć film
Więc grupowanie semantyki w semantycznej korespondencji nie uwzględnia intensywności żądań. A grupy opracowane w ten sposób nie pozwolą Ci napisać tekst, który wpadnie na górę. W czasie grupowania ręcznego wyeliminowania tego nieporozumienia, faceci z zawodem "Primne SEO specjalisty" został przeanalizowany ręcznie.
Istotą klastrowania jest porównaniem utworzonego emisji wyszukiwarki w poszukiwaniu prawidłowości. Z tej definicji należy natychmiast złożyć notatkę dla siebie, że sama klastrowa nie jest prawdą w ostatniej instancji, ponieważ utworzona emisja może nie ujawnić w pełni intencyjnej (w bazie Yandex może być po prostu witryną, która prawidłowo łączyła żądania Grupa).
Mechanika klastra jest prosta i wygląda tak:
- System naprzemiennie wprowadza wszystkie złożone do niego wszystkie wnioski i pamięta wyniki góry
- Po alternatywnym wejściem żądań i utrzymania wyników system szuka skrzyżowania w ekstradycji. Jeśli ta sama witryna jest tym samym dokumentem (strona witryny) znajduje się na górze natychmiast na kilku żądaniach, a następnie teoretycznie teoretycznie można łączyć w jedną grupę
- Stało się to istotnym takim parametrem, co grupa grupowania, która mówi do systemu, jak długo muszą być przecięcia, które żądania mogą być dodawane do jednej grupy. Na przykład, siłę grupowania 2 oznacza, że \u200b\u200bco najmniej dwie skrzyżowania powinny być obecne w ekstradycji 2 minut. Również łatwiejsze - co najmniej dwie strony dwóch różnych witryn powinny być obecne jednocześnie na pierwszej po jednym i kolejnym żądaniu. Przykład poniżej.
- Podczas grupowania dużych semantyki logika linków między wnioskami jest istotna, na podstawie której istnieją 3 podstawowe typy klastrowania: miękki, środkowy i twardy. Nadal będziemy rozmawiać o typach klastrów w następujących zapisach tego pamiętnika.
Cześć wszystkim! Po utrzymaniu bloga lub witryny treści zawsze istnieje potrzeba tworzenia jądra semantycznego na stronie, klastra lub artykułu. Dla wygody i systemu lepiej pracować z jądrem semantycznym zgodnie z ugruntowanym schemacją.
W tym artykule rozważymy:
- w jaki sposób zbiór jądra semantycznego do pisania artykułu;
- jakie usługi mogą być używane;
- jak pasować do kluczy do artykułu;
- moje doświadczenie wyboru osobistego.
Jak zbierać jądro semantyczne online
- Przede wszystkim musimy użyć usługi z Yandex -. Tutaj zrobimy wstępną próbkę możliwych kluczy.
W tym artykule zbieram Xia na ten temat: "Jak położyć laminat". Podobnie możesz użyć tej instrukcji na temat przygotowań jądra semantycznego dla dowolnego tematu.
- Jeśli nasz artykuł znajduje się na temacie "Jak położyć laminat", wprowadzimy to wniosek o uzyskanie informacji o częstotliwości wordstat.yandex.ru..
Jak widać, oprócz żądania docelowego, upadliśmy wiele podobnych żądań zawierających frazę "Laminat"Tutaj możesz zasiać wszystkie niepotrzebne, wszystkie klucze, które nie będą brane pod uwagę w naszym artykule. Na przykład nie będziemy pisać na podobnych tematach, takich jak "Ile warto umieścić laminatu", "Laminat przeliczany" sneorycznie " itp.
Pozbyć się wielu świadomie nieustannych zapytań, zalecam użycie operator "-" (minus).
- Zastępujemy minus i po wszystkich słowach nie są tematem.

- Teraz przydzielimy wszystko, co pozostaje i kopiować prośby o notatnik lub słowo.

- Wstawiając wszystko do pliku Word, działa w oczach i usuń wszystko, co nie zostanie ujawnione w naszym artykule, jeśli znaleziono fałszywe żądania, wtedy będziesz w stanie sprawdzić kombinację kluczy do obecności w dokumencie. Ctrl + F.Okno otwiera (panel boczny po lewej stronie), gdzie wprowadzamy żądane słowa.
Pierwsza część pracy jest zakończona, teraz możesz sprawdzić nasz obrabiany przedmiot z jądra semantycznego Yandex do czyszczenia częstotliwości, operator cytatów pomoże nam.
Jeśli słowa nie wystarczą, łatwo jest robić prawo do WordStat, zastępując frazę w cytatach i znalezienie czystej częstotliwości (Cytaty pokazują, ile żądań było zawartości tego konkretnego wyrażenia, bez dodatkowych słów). A jeśli, jak w naszym przykładzie semantycznego rdzenia artykułu lub strony, okazało się wiele słów, lepiej jest zautomatyzować tę pracę przy użyciu usługi mutagena.
Aby pozbyć się liczb Użyj następujących kroków za pomocą dokumentu Word.
- Ctrl + A. - Podświetlenie całej zawartości dokumentu.
- Ctrl + H. - Wywołuje okno, aby zastąpić znaki.
- Substytut w pierwszej linii ^ # i naciśnij "Wymień wszystko" Ta kombinacja usunie wszystkie numery z naszego dokumentu.
Uważaj za pomocą kluczy zawierających liczby, powyższe działania mogą zmienić klucz.
Wybór / artykuły jądra semantycznego online
Pisałem szczegółowo o służbie. Tutaj będziemy nadal uczyć się przygotowania jądra semantycznego.
- Idziemy na stronę i używamy tego programu, aby skompilować jądro semantyczne nie spotkałem lepszej alternatywy.
- Po pierwsze, Otoce Clean Częstotliwość dla tej przepustki "Parser Wordstat" → "masy parsowanie"

- Włóż wszystkie nasze wybrane słowa z dokumentu w oknie Parser (Ctrl + C i Ctrl + V) i wybierz "Częstotliwość WordStat" w cytatach.

Ta automatyzacja procesów jest warta razem 2 kopiejek dla frazy! Jeśli wybierzesz jądro semantyczne dla sklepu internetowego, to podejście zaoszczędzi ci czas na piosenka Penny!
- Kliknij, aby sprawdzić czek i, z reguły, 10-40 sekund (w zależności od liczby słów) można pobrać słowa o częstotliwości w cytatach.
- Plik wyjściowy ma rozszerzenie. CSV otwiera się do programu Excel. Zaczynamy filtrować dane, aby jądro semantyczne online.

- Kończymy trzecią kolumnę, jest potrzebny do ustawienia konkurencji (następny krok).
- Umieściliśmy filtr dla wszystkich trzech kolumn.
- Filtruj "malejącą" kolumnę "częstotliwość".
- Wszystko ma częstotliwość poniżej 10 - Usunięto.
Mamy listę kluczowąktóre mogą być używane w tekście artykułu, ale najpierw trzeba je sprawdzić na konkurencję. W końcu, jeśli ten temat jest pusty w Internecie wzdłuż i w poprzek, czy sens ma sens do napisania tego klucza do tego klucza? Prawdopodobieństwo, że nasz artykuł będzie pójść na górę, bardzo mały!
- Aby sprawdzić konkurencję Online jądro semantyczne Przejdź do "Konkurs".

- Zaczynamy sprawdzać każde żądanie, a wartość konkurencji jest podstawiona w odpowiedniej kolumnie w naszym pliku Excel.
Koszt Sprawdza jeden kluczowy fraza 30 kopigek.
Po pierwszym uzupełnieniu salda 10 bezpłatnych czeków będzie dostępny codziennie.
Aby określić frazy, które warto napisać artykuł weź najlepszy współczynnik częstotliwości.
Pisanie artykułu to:
- częstotliwość co najmniej 300;
- konkurencja nie jest wyższa niż 12 (lepsza mniej).
Sporządzanie jądra semantycznego online stosując frazy niskiej konkurencji Daj ci ruch. Jeśli masz nową stronę, nie pojawi się natychmiast natychmiast będzie musiał poczekać od 4 do 8 miesięcy.
Prawie każdy obiekt, można znaleźć SC i RF z niską konkurencją od 1 do 5, w takich klawiszach naprawdę dziennie otrzymują od 50 odwiedzających.
Aby skupić żądania jądra semantycznego, pomogą Ci dokonać odpowiedniej struktury witryny.
Gdzie wstawić jądro semantyczne w tekście
Po zbieraniu jądra semantycznego na stronie nadszedł czas, aby wprowadzić frazy kluczowe do tekstu, a oto kilka zaleceń dla początkujących, a ci, którzy "nie wierzą" w istnienie ruchu wyszukiwania.
Zasady podpisywania tekstu słów kluczowych
- Klucz wystarczy, aby użyć 1 czasu;
- słowa mogą być nachylone przypadkami, zmień miejsca;
- możesz rozcieńczyć frazy innymi słowy, cóż, gdy wszystkie frazy kluczowe są rozcieńczone i czytelne;
- możesz usunąć / zastąpić przyimki i słowa pytania (takie jak i tak dalej);
- możesz wstawić do znaków zwrotów "-" i ":"
na przykład:
Jest klucz: "Jak umieścić laminat własnymi rękami" W tekście może wyglądać tak: "... Aby położyć deski laminatu własnymi rękami, których potrzebujemy ..." lub tak "Każdy, kto próbował umieścić laminat własnymi rękami ...".
Niektóre frazy zawierają już inneNa przykład fraza:
"Jak położyć laminat własnymi rękami w kuchni" zawiera już kluczową frazę "Jak umieścić laminat własnymi rękami". W tym przypadku może pominąć drugi, ponieważ jest już obecny w tekście. Ale jeśli jest kilka kluczy, Lepiej jest używać go w tekście lub w tytule, lub w opisie.
- jeśli niemożliwe jest wepchnięcie frazy w tekście, a następnie odejść, nie rób tego (co najmniej dwa frazy mogą być używane w tytule i opisie i nie napisuj je do treści artykułu);
- Przed, Jedna fraza jest tytułem artykułu (najgęstsza częstotliwość i konkurencja)Język webmasters jest H1, to fraza wystarczy, aby użyć raz w treści tekstu.
Przeciwwskazania do Pisma Świętego Klucze
- niemożliwe jest oddzielenie klucza frazy przecinka (tylko w skrajnych przypadkach) lub punkcie;
- niemożliwe jest wprowadzenie klucza do tekstu w formie bezpośredniej, aby nie będzie oczywiście naturalnie (nie czytelny);
Tytuł i opis strony
Tytuł i opis. - Jest to opis nagłówka i strony, nie są widoczne w artykule, Yandex i Google pokazują je podczas badania użytkownika.
Zasady mowy:
- tytuł i opis powinien być "dziennikarski", to jest atrakcyjne dla przejścia;
- aby zawierać tekst tematyczny (odpowiedni zapytanie), ponieważ pasuje do tytułu i w opisie fraz kluczowych (rozcieńczonych).
Generał wymagania symboli w wtyczce Wszystko w jednym pakiecie SEONastępujące:
- Tytuł - 60 znaków (w tym spacje).
- Opis - 160 znaków (w tym spacje).
Sprawdź na plagiatowi swoje tworzenie lub uzyskane od Ciebie.
W tym celu, co zrobić z semantycznym rdzeniem po kompilacji. Podsumowując, podzielę własne doświadczenie.
Po skompilowaniu jądra semantycznego zgodnie z instrukcjami - moje doświadczenie
Możesz myśleć, że jestem dla ciebie smutny, coś nie jest wiarygodne. Tak więc, aby nie być bezzasadni, jest to zrzut ekranu statystyk na ostatni, (ale nie jedyny) rok tej strony, jak udało mi się odbudować blog i zacznij odbierać ruch.
To szkolenie jest przygotowaniem jądra semantycznego, choć długo, ale skuteczne, ponieważ w miejscu budującej główne właściwe podejście i cierpliwość!
Jeśli masz jakieś pytania lub masz krytykę, napisz komentarz, będę zainteresowany, także podziel się swoim doświadczeniem!
W kontakcie z
Kernel semantyczny (SIA) jest zestawem słów kluczowych, zapytania, zwroty wyszukiwania, dla których musisz promować swoją witrynę, aby przejść do odwiedzających użytkowników z wyszukiwarki. Kompilacja jądra semantycznego jest drugim etapem, po utworzeniu witryny na hostingu. Pochodzi z kompetentnie skomponowanych XI, ile lepszy ruch będzie na twojej stronie.
Potrzeba przygotowania rdzenia semantycznego to kilka punktów.
Po pierwsze, umożliwia opracowanie bardziej wydajnej strategii Promocji wyszukiwania, ponieważ mistrz Web Mistrz dokonuje jądra semantycznego dla swojego projektu, będzie jasną ideą, jakie metody wyszukiwania Promocja będzie musiała złożyć wniosek Jego strona decyduje o kosztach poszukiwania promocji, która silnie zależy od poziomu konkurencji z kluczowych fraz w wydaniu usług wyszukiwania.
Po drugie, jądro semantyczne umożliwia wypełnienie zasobu o lepszej zawartości, czyli treści, które będą dobrze zoptymalizowane dla żądań kluczowych. Na przykład, jeśli chcesz utworzyć witrynę o stretch sufitach, a następnie jądro semantyczne należy wybrać "odpychanie" z tego słowa kluczowego.
Ponadto kompilacja jądra semantycznego oznacza definicję częstotliwości wykorzystania słów kluczowych przez użytkowników wyszukiwarek, co umożliwia określenie systemu wyszukiwania, w którym musisz zwrócić większą uwagę na promocję żądania.
Konieczne jest również zauważenie pewnych zasad kompilacji jądra semantycznego, które muszą być przestrzegane, aby móc tworzyć wysokiej jakości i wydajny SIA.
Tak więc w składzie jądra semantycznego należy włączyć wszystkie możliwe żądania kluczowych, dla których można promować witrynę, z wyjątkiem tych żądań, które nie mogą przynieść zasobu przynajmniej niewielkiej ilości ruchu. Dlatego jądro semantyczne powinno obejmować słowa kluczowe o wysokiej częstotliwości (HF), medium (s) i Żądania niskiej częstotliwości (LF).
Warunkowo, te wnioski można podzielić w ten sposób: LF - do 1000 wniosków miesięcznie, SCH - od 1000 do 10 000 wniosków miesięcznie, HF - ponad 10.000 wniosków miesięcznie. Konieczne jest uwzględnienie faktu, że na różnych przedmiotach figury te mogą się znacznie różnić (w niektórych szczególnie wąskich tematach, maksymalna częstotliwość żądań nie przekracza 100 żądań miesięcznie).
Wnioski o niskiej częstotliwości są po prostu konieczne do wykonania struktury jądra semantycznego, ponieważ każdy młody zasób ma możliwość awansowania w wyszukiwarkach, przede wszystkim na nich (i bez zewnętrznej promocji witryny - napisał artykuł poniżej Żądanie NF, wyszukiwarka została indeksowana, a Twoja strona wyszukiwarki po kilku tygodniach może być na górze).
Konieczne jest również obserwowanie zasady strukturyzacji jądra semantycznego, który jest to, że wszystkie słowa kluczowe witryny muszą być łączone w grupy nie tylko ich częstotliwości, ale także stopień podobieństwa. Pozwoli to lepiej optymalizować treści, na przykład, aby zoptymalizować niektóre teksty dla kilku żądań.
Również w strukturze semantycznego rdzenia wielu witryn wskazane jest włączenie takich rodzajów żądań jako synonimiczne żądania, zapytanie slangu, redukcję słów i tak dalej.
Oto wyraźny przykład tego, w jaki sposób można zwiększyć frekwencję witryny przez jednego, pisząc zoptymalizowane artykuły, które obejmują konto i dużą liczbę żądań LF:
1. Miejsce męskich przedmiotów. Chociaż jest bardzo rzadko aktualizowany (na cały czas, został opublikowany trochę więcej niż 25 artykułów), ale dzięki dobrze wybranym żądaniom zyskuje coraz więcej frekwencji. Witryna w ogóle nie kupiła linków!

W tej chwili wzrost obecności zawieszony, ponieważ opublikowano tylko 3 artykuły.
2. Miejsce kobiecego tematu. Początkowo nie opublikowano na nim artykuły zoptymalizowane. Latem skompilowano semantyczny rdzeń, który składał się z zapytań z bardzo niską konkurencją (jak zebrać podobne żądania, powiem poniżej). Zgodnie z tymi wnioskami napisano odpowiednie artykuły i kilka odniesień zostało nabytych na zasoby tematyczne. Wyniki takiego promocji można zobaczyć poniżej: 
3. Miejsce osób medycznych. Nisza medyczna została wybrana z większą ilością lub mniej odpowiedniej konkurencji i opublikowano ponad 200 artykułów do pysznych wniosków z dobrymi ofertami (w Internecie, termin "oferta" oznaczają koszt jednego tranzytu użytkownika na łącze reklamowe). Linki zaczęły kupować w lutym, gdy strona wynosiła 1,5 miesiąca. Do tej pory, głównie ruch pochodzi z Google, Yandex nie został jeszcze uwzględniony na zakupione linki.

Jak widać, wybór jądra semantycznego odgrywa kluczową rolę w promowaniu witryny. Nawet z małym budżetem lub ogólnie nie jest możliwe tworzenie witryny ruchu, która przyniesie Twoje zyski.
Wybór zapytań wyszukiwania
Wybierz żądania jądra semantycznego w następujący sposób:
Korzystanie z bezpłatnych usług statystyk zapytania Google Wyszukaj, Yandex lub Rambler
Ze specjalnym oprogramowaniem lub usługą online (bezpłatną lub płatną).
Po przeanalizowaniu stron internetowych konkurentów.
Wybór zapytań wyszukiwania za pomocą wyszukiwarki Google Statystyki, Yandex lub Rambler
Natychmiast chcę cię ostrzec, że usługi te pokazują niezupełnie dokładne informacje na temat liczby zapytań wyszukiwania miesięcznie.
Na przykład jesteś na życzenie "Plastic Windows" Wyświetl 4-stronę wyników wyszukiwania, a następnie usługa statystyczna pokaże, że wniosek ten został szukany za nie 1 i 4 razy, ponieważ jest uważany za nie tylko pierwszy numer wydawania, Ale wszystkie następne, które są uważane za oglądane użytkownika. Dlatego w praktyce liczby rzeczywiste będą nieco niższe niż wykazujące różne usługi.
Aby określić dokładną liczbę przejść, najlepiej, oczywiście, zostanie podkreślony przez statystyki obecności konkurentów, którzy są w Top-10 (Liveinternet albo Male, jeśli jest otwarty). W ten sposób możliwe będzie zrozumienie, ile ruchu przyniesie żądanie, które jesteś zainteresowany.
Możesz także liczyć na to, ile odwiedzających przyniesie Ci tę prośbę, w zależności od pozycji, którą witryna zajmie w wynikach wyszukiwania. W ten sposób zmieni się CTR (Coeff. Kliknięta) witryny na różnych pozycjach na górze:

Rozważmy żądanie "! Naprawa! Apartamenty, region" Moskwa i region ":

W tym przypadku, jeśli Twoja witryna zajmie 5 miejsce w ekstradycji, to wniosek przyniesie Ci około 75 odwiedzających miesięcznie (6%), 4 miejsce (8%) - 100 poz. / Miesięcznie, 3 miejsce (11% ) - 135 POS / na miesiąc, 2 miejsce (18%) - 223 poz. / Miesięcznie. i pierwsza pozycja (28%) - 350 odwiedzających miesięcznie.
CTR może być również dotknięty przy użyciu jasnego fragmentu, zwiększając tym samym obecność na ten wniosek. Jak poprawić fragment i co można czytać.
Statystyki zapytania wyszukiwania Google
Wcześniej statystyki zapytania wyszukiwania Google, często używane, ponieważ przede wszystkim przeniósł się do tej wyszukiwarki. Wtedy wystarczyło zoptymalizować artykuł, kupując go jak najwięcej różnorodne prolete linki (bardzo ważne jest, aby te linki są naturalne i linki przejściowych odwiedzających) i voila - jesteś na górze!
Teraz w Google sytuacja jest taka, że \u200b\u200bnie jest znacznie łatwiejsze do poruszania się w nim niż w Yandex. Dlatego musisz zwrócić większą uwagę zarówno na pisanie, jak i projektowanie (!) Artykułów i kupować linki do witryny.
Chcę też zwrócić twoją uwagę na następny fakt:
W Rosji Yandex cieszy się największą popularnością (Yandex - 57,7%, Google - 30,6%, Mail.ru - 8,9%, Rambler -1.5%, Nigmy / Ask.com - 0,4%), więc jeśli się poruszasz w tym kraju, Najpierw kolejka jest warta nawigacji Yandex.
Na Ukrainie sytuacja wygląda inaczej: Google - 70-80%, Yandex - 20-25%. Dlatego ukraińscy webmastery muszą skupić się na promocji w Google.
Aby skorzystać z żądań Google, przejdź do
Rozważmy przykład wyboru słów kluczowych dla niektórych witryn kulinarnych.
Przede wszystkim musisz wprowadzić główne żądanie, na podstawie którego opcje słowa kluczowego zostaną wybrane dla przyszłego semantycznego rdzenia witryny. Wszedłem do prośby "Jak gotować".
Następny krok - wybierz rodzaj zgodności. Istnieją 3 rodzaje zgodności: szerokości, frazy i dokładne. Radzę wybrać dokładną, ponieważ ta opcja będzie funkcjonować najdokładniejsze informacje na żądanie. A teraz wyjaśnię dlaczego.
Szeroka zgodność oznacza, że \u200b\u200bstatystyki pokazów zostanie pokazane we wszystkich słowach, które są w tym żądaniu. Na przykład, dla żądania "plastikowe okna" zostanie pokazane dla wszystkich słów, w których słowo "plastikowe" i słowo "Windows" (plastikowe, okno, kupić okna, kupić żaluzje dla okien, okna PVC). Krótko mówiąc, będzie dużo "śmieci".
Zgodność frazowa oznacza, że \u200b\u200bstatystyki zostaną pokazane dla słów precyzyjnie w kolejności, w której są określone. Wraz z określoną frazą słów, inne słowa mogą być obecne w zapytaniu. W przypadku prośby o "plastikowe okna" słowa "niedrogie plastikowe okna" zostaną uwzględnione, "plastikowe okna Moskwa", "Ile plastikowych okien" są "itp" itd.

Jesteśmy najbardziej zainteresowani rysunkiem "Liczba żądań miesięcznych (Regiony docelowe)" i "Przybliżona cena za kliknięcie" (jeśli zamierzamy opublikować reklamy AdSense na stronach witryn).
Mówiąc statystyki Yandex.
Używam statystyk zapytania o zapytań niemal każdego dnia, ponieważ jest on prezentowany w bardziej dogodnym formularzu niż jego analog w Google.
Jedynym minusem WordStat jest to, że nie znajdziesz w IT Rodzaje zgodności, nie zapisuj wybranych zapytań do komputera, nie będziesz mógł dowiedzieć się ceny kliknięcia itp.
Aby uzyskać dokładniejsze wyniki, musisz użyć specjalnych operatorów, z którymi możesz wyjaśnić żądania, które nas interesują. Lista operatorów, które znajdziesz na tym.
Jeśli po prostu wejdziesz na zapytanie "Jak gotować" w Vordstat, otrzymujemy następujące statystyki:

Jest to równe, jeśli wybraliśmy "szerszą zgodność" w AdWords.
Jeśli wprowadzisz tę samą prośbę, ale już w cytatach, otrzymamy bardziej dokładne statystyki (analogowa zgodność frazy w AdWords):

Cóż, aby uzyskać statystyki tylko dla określonego zapytania, musisz użyć operatora "!": "! Jak przygotuj"

Aby uzyskać jeszcze dokładniejsze wyniki, musisz określić region, w którym znajduje się strona:

Również w górnym panelu Wordstat ma narzędzia, z którymi można zobaczyć statystyki określonego żądania przez regiony, miesiąc i tydzień. Przy okazji, przy okazji, jest bardzo wygodna do analizy statystyki żądań sezonowych.
Na przykład, analizując żądanie "Jak gotować", możesz dowiedzieć się, co cieszy się najbardziej popularnym w grudniowym miesiącu (nie jest zaskakujące - wszystko przygotowuje się do nowego roku):

Szukaj statystyk zapytania Rambler
Natychmiast chcę ostrzec, że statystyki żądania Rackell coraz częściej tracą swoje znaczenie co roku (przede wszystkim wiąże się z niską popularnością tej wyszukiwarki). Dlatego najprawdopodobniej nie musisz z tym pracować.


W adstancie nie musisz wprowadzać żadnych operatorów - natychmiast podaje częstotliwość żądania w przypadku, w którym została wprowadzona. Również w nim znajdują się oddzielne statystyki żądań częstotliwości dla pierwszej strony wyników wyszukiwania i dla wszystkich stron wydawania, w tym pierwszego.
Wybór zapytań wyszukiwania ze specjalnym oprogramowaniem lub usługami online
Rookee może nie tylko promować Twoje prośby, ale może również pomóc w tworzeniu semantycznego rdzenia witryny.
Za pomocą Rookee można łatwo wybrać jądro semantyczne dla swojej witryny, można w przybliżeniu przewidzieć liczbę wizyt na wybranych żądaniach i koszcie ich awansu na górę.
Wybór żądań Korzystanie z programu Word Word Word
Jeśli zamierzasz stworzyć SIA (jądro semantyczne) na bardziej profesjonalnym poziomie, lub będziesz musiał znaleźć statystyki Google w Google.Dords, Rambler.adstat, Social Network VKontakte, różnych agregatorów odniesienia itp., Radzę ci natychmiast Zakup kolektora Kay.
Jeśli chcesz zrobić duży jądro semantyczne, ale nie chcesz wydawać pieniędzy na zakup płatnych programów, najlepszą opcją w tym przypadku będzie programem programu Word (przeczytaj informacje o programie tutaj). Jest "młodszym bratem" Kay Collector i pozwala zbierać Xia, na podstawie statystyk żądań dla Yandex.wordstat.
Instalowanie programu Word.
Pobierz archiwum za pomocą programu.
Upewnij się, że archiwum jest odblokowany. Aby to zrobić, we właściwościach pliku (w menu kontekstowym wybierz "Właściwości") naciśnij przycisk "Unlock" / "Unblock", jeśli jest obecny.
Rozpakuj zawartość archiwum.
Uruchom plik wykonywalny Sloveb.exe
Utwórz nowy projekt:

Wybierz żądany region (Regiony przycisków Yandex.wordstat):

Zapiszemy zmiany.
Kliknij przycisk "Yandex.wordstat Left"
W razie potrzeby ustaw "Zatrzymaj słowa" (słowa, które nie powinny być zawarte w naszym jądrze semantycznym). Zatrzymaj słowa mogą być takimi słowami: "Za darmo" (jeśli sprzedajesz coś na swojej stronie), "Forum", "Wikipedia" (jeśli masz własną stronę informacji, na której nie ma forum), "Porn", "Seks "(Cóż, wszystko jest jasne tutaj) itd.
Teraz musisz ustawić początkową listę słów, na podstawie której Xia zostanie skompilowana. Zróbmy jądro dla firmy, która jest zaangażowana w montaż sufitów stretch (w Moskwie).
Wybierając dowolne jądro semantyczne, przede wszystkim, musisz dokonać klasyfikacji tematu tematu.
W naszym przypadku sufity stretch można sklasyfikować zgodnie z następującymi kryteriami (podobnymi wygodnymi kartami wywiadowczych, które robię w programie MindJet MindManager):

Przydatne porady: Z jakiegoś powodu bardzo wielu webmasterów zapomnieć o nazwach małych osad w rdzeniu semantycznym.
W naszym przypadku, w Xia możliwe byłoby uwzględnienie nazw obszarów zainteresowań Moskwy i miast regionu Moskwy. Nawet jeśli w tych słowach kluczowych ("Sufity napięcia Golitsyno", "Stretch Sufity aprenevka" itp.) Bardzo niewiele wniosków miesięcznie, nadal muszą pisać co najmniej jeden mały artykuł, w tytule, którego byłby pożądany klucz. Takie artykuły nie muszą promować, ponieważ najczęściej, zgodnie z tymi wnioskami, będzie bardzo niska konkurencja.
10-20 takich artykułów, a Twoja witryna stabilnie będzie miało kilka dodatkowych zamówień z tych miast.
Naciśnij przycisk "Left Column Yandex.wordstat" i wprowadź żądane żądania:

Kliknij przycisk "Pass". W rezultacie otrzymujemy tę listę żądań:

Wyciągamy wszystkie niepotrzebne zapytania, które nie nadają się na temacie witryny (na przykład "stretch sufity z własnymi rękami" - to zapytanie przyniesie pewien ruch, ale nie przyniesie nam klientów, którzy zamówią instalację sufity). Przydzielymy te prośby i usuniemy, że w przyszłości nie spędzamy czasu na ich analizę.
Teraz musisz wyjaśnić częstotliwość dla każdego z kluczy. Kliknij przycisk "Zbierz częstotliwość"! ""

Teraz mamy następujące informacje: żądanie, jego ogólną i dokładną częstotliwość.
Teraz, oparta na uzyskanej częstotliwości, musisz ponownie rozważyć wszystkie żądania i usunąć niepotrzebne.
Niepotrzebne prośby są pytaniami:
Dokładna częstotliwość ("!") Bardzo niski (w temacie wybranym przeze mnie, w zasadzie, musisz przejść przez każdego odwiedzającego, więc odrzucę prośby o częstotliwość miesięczną mniej niż 10). Gdyby nie było motywu budynku, ale powiedzmy, niektórzy generalnie tematyczne, możesz bezpiecznie odciąć żądania tej częstotliwości poniżej 50-100 miesięcznie.
Stosunek wspólnej i dokładnej częstotliwości przekracza bardzo duże. Na przykład żądanie "Kupić sufity naprężenia" (1335/5) można natychmiast usunąć, ponieważ jest to "żądanie zapytania".
Wnioski o bardzo dużą konkurencję muszą również zostać usunięte, trudno będzie awansować (zwłaszcza jeśli masz młodą witrynę i mały budżet na promocję). Taka prośba, w naszym przypadku, jest "stretch sufitów". Ponadto, najczęściej te pytania składają się z 3.4 i więcej słów są bardziej skuteczne - przynoszą więcej osób docelowych.
Oprócz słowa, istnieje kolejny doskonały program dla wygodnej automatycznej kolekcji, analizy i przetwarzania statystyk słów kluczowych słów kluczowych Yandex.direct.
Pytań wyszukiwania wiadomości
W takim przypadku nie jest tworzony co do zwykłego projektu treści. Dla witryny informacyjnej, przede wszystkim, musisz podświetlić nagłówki, na których zostaną opublikowane wiadomości:

Potem musisz wybrać żądania dla każdej z sekcji. Oczekiwane są żądania wiadomości i nie oczekiwano.
Przy pierwszym rodzaju żądań przewidziano powód informacyjny. Najczęściej możesz nawet dokładnie określić datę, kiedy jest powitalny popularności żądania. Może to być jakieś wakacje (Nowy Rok, 9 maja, 8 marca, 23 lutego, Dzień Niepodległości, Konstytucja Dzień, święta Kościelne), wydarzenie (wydarzenia muzyczne, koncerty, filmowców, konkursy sportowe, wybory prezydenckie).
Przygotuj takie żądania z góry i określ przybliżoną objętość ruchu w tym przypadku może być używać
Nie zapomnij również zobaczyć statystyk obecności Twojej witryny (jeśli już pomijałeś dowolne wydarzenie) i witryny konkurentów (jeśli ich statystyki są otwarte).
Drugi rodzaj zapytań jest mniej przewidywalny. Należą do nich Aktualności: Cataclysms, katastrofy, wszelkie wydarzenia w rodzinach znanych osób (narodziny / ślub / śmierć), wyjście nie ogłoszonego oprogramowania itp. W tym przypadku wystarczy być jednym z pierwszych Opublikuj tę wiadomość.
Aby to zrobić, nie wystarczy monitorować wiadomości w Google i Yandex - w tym przypadku witryna będzie tylko jednym z tych, którzy po prostu przedrukowali to wydarzenie. Bardziej wydajną metodą, która pozwala zgrać Big Kush - po czym następuje zagraniczne witryny. Wysłany przez tę wiadomość Jednym z pierwszych w Runet, oprócz ton ruchu, który umieści serwer na hostingu, zdobądź wiele linków zwrotnych do swojej witryny.
Wnioski o tematy "Kino" można również przypisać pierwszym typie (oczekiwane żądania). W tym przypadku, w tym przypadku data premiery filmowej jest znana z góry, skrypt filmowy jest w przybliżeniu znany, jego aktorzy. Dlatego musisz przygotować stronę z wyprzedzeniem, na którym pojawi się film, dodaj tam przyczepę na chwilę. Możesz także publikować na stronie wiadomości o filmie, jego aktorów. Ta taktyka pomoże Ci zająć najwyższe stanowiska w wyszukiwarkach z wyprzedzeniem i prowadzi odwiedzających stronę przed jego premierą.
Chcesz wiedzieć, jakie prośby teraz w trend lub przewidują znaczenie swojego obiektu w przyszłości? Następnie użyj usług, które dostarczają informacji o trendach. Pozwala na wiele operacji analizy: porównywanie trendów wyszukiwania na kilka wniosków, analiza regionów geograficznych żądania, przeglądając obecnie najgorętsze trendy, przeglądając odpowiednie rzeczywiste zapytania, wyniki eksportu w formacie CSV, możliwość subskrybowania kanału RSS na gorąco trendy itp.
Jak przyspieszyć kolekcję jądra semantycznego?
Myślę, że wszyscy, którzy natknęli się na kolekcję jądra semantycznego, pojawiła się myśl: "Jak długo idę parsowanie, zmęczony przechodzeniem i grupami tysięcy tych wniosków!". To normalne. Czasami go też mam. Zwłaszcza, gdy musisz przenikać i uporządkować, co składa się z kilkudziesięciu tysięcy wniosków.
Przed rozpoczęciem paczki zdecydowanie radzę podzielić wszystkie prośby o grupy. Na przykład, jeśli masz przedmiot witryny "Dom budowy", złamaj go na fundamencie, ścianach, oknach, drzwiach, dachu, okablowaniu, ogrzewania itp. Po prostu będzie dużo łatwiejsze do przejścia i żądania grupy, gdy oni znajdują się w małej grupie i są połączone przez określony wąski motyw. Jeśli po prostu nalisz wszystko w jednym stosie, będziesz miał nierealistyczną ogromną listę, do której przetwarzanie odbędzie się nie jeden dzień. I tak, traktując całą listę uśmiechniętych w małych krokach, nie tylko lepiej opracowanie wszystkich próśb, ale także będziesz mógł zamówić artykuł z Copywriters do już zebranych kluczy równolegle.
Proces zbierania jądra semantycznego jest prawie zawsze zaczyna się od automatycznych parsowania zapytań (dla tego używam kolektora Kay). Ręcznie można również zbierać, ale jeśli pracujemy z dużą liczbą żądań, nie widzę punktu spędzenia cennego czasu na tej rutynowej pracy.
Jeśli pracujesz z innymi programami, najprawdopodobniej będziesz dostępny do pracy z serwerami proxy. Pozwala to na przyspieszenie procesu parsowania i zabezpieczyć IP z Banna w wyszukiwarkach. Szczerze mówiąc, nie jest to bardzo przyjemne, gdy trzeba w pełni spełnić zamówienie, a twój adres IP z powodu częstego odwołania do usługi statystyki Google / Yandex na jeden dzień. Tutaj w tym przypadku i przyjdź do serwerów proxy Rescue.
Osobiście, w tej chwili nie używam ich do jednego prostego powodu - są one stale bantas, znalezienie wysokiej jakości proxy nie są takie proste, a nawet po raz kolejny płacę za nich pieniądze Nie mam pragnienia. Dlatego znalazłem alternatywną metodę zbierania SIA, który kilkakrotnie przyspieszył ten proces.
W przeciwnym razie będziesz musiał szukać innych witryn do analizy.
W większości przypadków witryny zamykają tę statystykę, dzięki czemu można użyć statystyk punktów wejściowych.
W rezultacie będziemy mieli statystyki najczęściej odwiedzanych stron. Idź do nich, odpowiadamy główne prośby, które zostały zoptymalizowane, a już na nich zbieramy SIA.
Nawiasem mówiąc, jeśli witryna ma statystyki w wyszukiwanych frazach, możesz łatwiej pracować i zbierać żądania za pomocą kolektora Kei (wystarczy wprowadzić adres witryny i kliknąć przycisk "Uzyskaj dane"):

Drugim sposobem na analizę witryny konkurenta jest analiza swojej strony.
Istnieje widżet "najbardziej popularnych artykułów" (lub coś w ten sposób) na niektórych zasobach. Czasami najpopularniejsze artykuły są wybierane na podstawie liczby komentarzy, czasami - w oparciu o liczbę poglądów.

W każdym razie posiadanie listy najpopularniejszych artykułów przed własnymi oczami, możesz dowiedzieć się, jakiego rodzaju prośby jeden lub inny artykuł został napisany.
Trzecia droga - użyj narzędzi. Zwykle został stworzony, aby przeanalizować witryny zaufania, ale szczerze, uważa za zaufanie bardzo źle. Ale co może zrobić dobrze - więc jest przeanalizowanie żądań stron internetowych konkurentów.
Wprowadź adres dowolnej witryny (nawet z zamkniętymi statystykami!) I naciśnij przycisk Sprawdź zaufania. Na dole strony zostanie wyświetlone statystyki widoczności witryny według słów kluczowych:
Widoczność witryny w wyszukiwarkach (słowa kluczowe)

Jedyny minus - te żądania nie mogą być eksportowane, musisz skopiować wszystko ręcznie.
Czwarty sposób - korzystanie z usług i.

Dzięki nim możesz zdefiniować wszystkie wnioski, za pomocą których strona zajmuje pozycje w 100 najlepszych w obu wyszukiwach. Możliwe jest eksportowanie pozycji i żądania formatu XLS, ale nie mogłem otworzyć tego pliku na żadnym z komputerów.

Cóż, ostatnim sposobem na znalezienie kluczowych słów konkurentów - z
Przeanalizujmy na przykład "House of Bruus" na przykład. W zakładce "Analiza konkurencji" wprowadź to żądanie (jeśli chcesz przeanalizować określoną witrynę, wystarczy wprowadzić swój adres URL do tego pola).
W rezultacie uzyskujemy informacje o częstotliwości żądania, liczby reklamodawców w każdej z wyszukiwarek (a jeśli są reklamodawcy, istnieje pieniądze w tej niszy) i średni koszt kliknięcia Google i Yandex:

Możesz również zobaczyć wszystkie ogłoszenia w Yandex.direct i Google AdWords:


Ale wygląda na szczyt każdego z PS. Możesz kliknąć dowolną z domen i zobaczyć wszystkie żądania, za pomocą których znajduje się na górze i wszystkie jego reklamy kontekstowe:

Istnieje inny sposób na analizę żądań konkurentów, o których niewielu ludzi wiedzą - za pomocą Ukraińskiej Służby
Nazywałbym go "ukraińską wersją Spywords", ponieważ są one bardzo podobne do funkcjonalności. Jedyną różnicą znajduje się w bazie danych, istnieją kluczowe frazy, które szukają użytkowników ukraińskich. Więc jeśli pracujesz w UA-Nete, ta usługa będzie Ciebie bardzo, przy okazji!
Analiza konkurencji żądań
Tak więc złożone są wnioski. Teraz musisz analizować konkurencję dla każdego z nich, aby zrozumieć, jak trudny lub inny słowo kluczowe zostanie promowane.
Osobiście, ja, kiedy tworzę nową stronę, najpierw spróbować pisać artykuły do \u200b\u200bzapytań, dzięki której niska konkurencja. Pozwoli to na krótki czas iz minimalnymi inwestycjami, aby przynieść witrynę do całkiem dobrej frekwencji. Przynajmniej w takich przedmiotach, jak konstrukcja, medycyna może zostać wydana w 500-1000 odwiedzających w ciągu 2,5 miesiąca. O tematyńskich motywach w milczeniu.
Zobaczmy, jak analizować konkurencję z ręczną i automatyczną drogą.
Ręczny sposób analizy konkurencji
Wyszukiwanie żądanych słów kluczowych w wyszukiwaniu i zobacz T0P-10 (i jeśli to konieczne, T0P-20), które są w wynikach wyszukiwania.
Najbardziej podstawowe parametry, do których musisz oglądać:
Liczba głównych stron na górze (jeśli promujesz stronę wewnętrzną stroną, a na szczycie konkurentów, główne strony są głównie zlokalizowane, wtedy, najprawdopodobniej nie będziesz mógł ich wyprzedzić);
Liczba kierunków słów kluczowych bezpośrednich na stronach tytułów.
Zgodnie z takimi żądaniami jako "Promocja witryny", "Jak schudnąć", "Jak zbudować dom", jest niezrealizowany wysoki konkurs (wiele głównych stron w górnej części bezpośredniego wpisu słów kluczowych w tytule), więc ty nie powinien się nad nimi ruszyć. Ale jeśli przejdziesz na życzenie "Jak zbudować dom bloków piankowych z własnymi rękami z piwnicą", wtedy będziesz miał więcej szans na górę. Dlatego też ponownie skupiając się na tym, czego potrzebujesz, aby przejść na żądania składać się z 3 i więcej słów.
Ponadto, jeśli przeanalizujesz wydawanie w Yandex, możesz zwrócić uwagę na witryny TITZ (tym wyższe, najtrudniej, aby je wyprzedzić, ponieważ wysoki TITZ najczęściej wskazuje dużą masę referencyjną witryny), niezależnie od tego, czy są one w katalogu Yandex (Witryny z katalogu Yandex mają duże zaufanie), jego wiek (witryny związane z wiekiem w wyszukiwarkach, takich jak więcej).
Jeśli przeanalizujesz najlepsze strony w Google, zwróć uwagę na te same parametry, które napisałem powyżej, tylko w tym przypadku, zamiast dyrektora Yandex, będzie katalog DMOZ, a zamiast wskaźnika TIC pojawi się wskaźnik PR (Jeśli witryna stron strony ma PR od 3 do 10, aby je wyprzedzić, nie będzie łatwe).
Radzę przeanalizować witryny za pomocą wtyczki. Pokazuje wszystkie informacje o stronie konkurenta:

Automatyczna droga do analizy konkurencji zapytania
Jeśli istnieje wiele żądań, możesz użyć programów, które sprawią, że wszystkie prace dla ciebie setki razy. W takim przypadku możesz użyć słowa lub kolektora Kei.
Wcześniej analizując konkurentów, użyłem wskaźnika "Kei" (stawka konkursowa). Ta funkcja znajduje się w Kay Collector i słowo.
Słowo wskaźnik Kei po prostu pokazuje całkowitą liczbę witryn w wydaniu tego lub innego żądania.
W tym względzie Kay Collector ma przewagę, ponieważ ma możliwość określenia formuły do \u200b\u200bobliczenia parametru Kei. Aby to zrobić, przejdź do ustawień programu - Kei:

W "Formuła obliczeniowego Formula Kei 1" Wkładka:
(Kei_yandexmainpagesCount * kei_yandexmainpagesCount * kei_yandexmainpagesCount) + (kei_yandextekstlexount * kei_yandextekstlexCount * key_yandextititlescount)
W polu "Kalkulacja Formula Kei 2" Wkładka:
(Key_googlemainpagesCount * key_googlemainpagesCount * key_googlemainpagesCount) + (key_googletitlescount * key_googoletscount * key_googletitlescount)
Ta formuła uwzględnia liczbę głównych stron w wydaniu danego słowa kluczowego i liczby stron w TOP-10, w którym ta kluczowa fraza jest zawarta na stronach tytułów. W ten sposób możesz uzyskać więcej lub mniej obiektywnych danych konkurencji dla każdego żądania.
W tym przypadku, tym mniej Kei, tym lepiej. Najlepsze słowa kluczowe będą z Kei \u003d 0 (jeśli w nich, oczywiście, będzie przynajmniej jakiś ruch).
Kliknij przyciski zbierania danych dla Yandex i Google:

Następnie kliknij ten przycisk:

W Kei 1 i Kei 2 kolumna 2 pojawi się na żądaniach Kei dla Yandex i Google
odpowiednio. Sortuj żądania, zwiększając kolumnę Kei 1:

Jak widać, wśród wybranych wniosków są takie, których promocja nie powinna być szczególnie szczególnymi problemami. W mniej konkurencyjnych temach, aby przynieść Top-10 takich żądań, wystarczy, aby napisać dobry zoptymalizowany artykuł. A jednocześnie nie będziesz musiał kupić zewnętrznych linków do swojej promocji!
Jak powiedziałem powyżej, wcześniej używałem wskaźnika Kei. Teraz, aby ocenić konkurencję, wystarczy, żebym otrzymał liczbę głównych stron na górze i liczbę wpisów słów kluczowych na stronie tytułowej. W Kay Collector znajduje się podobna funkcja:


Po tym, sortuję zapytania na "Liczba głównych stron w PS Yandex" i wyglądam tak, że ten parametr nie ma więcej niż 2 głównych stron w górnej części i kilku wpisów w nagłówkach. Po pod każdym względem zostaną sporządzone, zmniejszam parametry filtra. Zatem pierwsze publikowanie artykułów w ramach wniosków NK zostaną opublikowane, a drugi - w ramach wniosków SC i VC.
Po tym, jak wszystkie najciekawsze zapytania są gromadzone i zgrupowane razem (powiem grupie poniżej), kliknij przycisk "Eksportuj dane" i zapisz je do pliku. W pliku eksportu zazwyczaj włączam następujące parametry: częstotliwość Yandex z "!" W danym regionie liczba głównych stron witryn i liczby celów słów kluczowych w nagłówkach.
WSKAZÓWKA: Kay Collector Czas Czasami nie słusznie wskazuje liczbę żądań w nagłówkach. Dlatego pożądane jest dodatkowo wprowadzać te żądania w Yandex i ręcznie spojrzeć na emisję.
Ocena konkurencyjności zapytań wyszukiwania może być również używany za darmo
Wnioski grupowe
Po wybraniu wszystkich żądań przychodzi, nadszedł czas, aby dość nudna i monotonna praca na grupowaniu wniosków. Proszę podjąć podobne zapytania, które można łączyć w jedną małą grupę i promować w jednej stronie.
Na przykład, jeśli masz takie prośby na liście: "Jak nauczyć się być wyrywaniem", "Jak nauczyć się nacisnąć w domu", nauczyć się naciskać dziewczynę ". Takie żądania można łączyć w jedną grupę i napisz jeden duży zoptymalizowany artykuł pod nim pod nim.
Aby przyspieszyć proces grupowy, postępuj zgodnie z analizą słów kluczowych w częściach (na przykład, jeśli masz stronę fitness, a następnie podczas parsowania, rozkładamy grupy, w których uwzględnimy wnioski związane z szyją, ręce, z powrotem , piersi, prasa, nogi itp.). To znacznie ułatwi twoją pracę!
Jeśli otrzymane grupy będą zawierać niewielką liczbę zapytań, możesz zostać na tym. A kiedy skończysz, nadal okazuje się kilka kilkunastu, a nawet setki żądań, możesz wypróbować następujące metody.
Pracuj z słowami stoppal
W Kay wybór jest możliwość określenia słów zatrzymujących, które można wykorzystać do oznaczania niechcianych słów kluczowych w otrzymanej tabeli zapytania. Takie żądania są zwykle usuwane z jądra semantycznego.
Oprócz usunięcia niechcianych żądań, ta funkcja może być również używana do wyszukiwania wszystkich niezbędnych słów dla danego klucza.
Podaj żądany klucz:

Tabela przydzieli wszystkie określone słowa kluczowe:

Nosimy je na nową kartę i już istnieją ręcznie z wszystkimi żądaniami.
Filtracja pola "frazy"
Możesz znaleźć wszystkie określone słowa kluczowe w ustawieniach filtrowania dla pola "frazy".
Spróbujmy znaleźć wszystkie prośby, które słowo "bary" obejmuje:

W rezultacie otrzymujemy:

Narzędzie "Analiza grup"
Jest to najbardziej wygodne narzędzie do grupowania zwrotów i ich dalszego filtrowania ręcznego.
Przejdź do karty "Data" - "Analiza grupowa":

I to jest wyświetlane, jeśli otworzysz dowolną z tych grup:

Zauważając dowolną grupę zwrotów w tym oknie, jednocześnie zaznaczasz lub strzelaj do znaku frazą w stole głównym ze wszystkimi żądaniami.
W każdym razie bez ręcznie robionego nie możesz tego zrobić. Ale dzięki Kay Collector, część pracy (i nie mała!) Już się skończył i jest co najmniej trochę, ale ułatwia proces opracowywania miejsca SIA.
Po ręcznym obrażeniu wszystkich żądań powinieneś uzyskać następujące informacje:

Jak znaleźć niską konkurencyjną dochodową niszę?
Przede wszystkim musisz zdecydować, jak zarobisz na swojej stronie internetowej. Wielu początkujących webmasterów robi jeden i ten sam głupi błąd - najpierw tworzą witryny na ten temat, które lubią (na przykład po zakupie iPhone'a lub IPADa, każdy natychmiast biegnie, aby wykonać następną witrynę "Tematy Apple"), a następnie rozpocząć Aby zrozumieć, że konkurencja w tej niszy jest bardzo wysoka i włamać się do pierwszych miejsc ich govaritycznego będą praktycznie nierealistyczne. Lub wykonaj witrynę kulinarną, ponieważ lubią gotować, a potem rozumieją horrorem, że nie wiedzą, jak zarabiać taki ruch.
Przed utworzeniem dowolnej witryny natychmiast zdecyduj, w jaki sposób zarabiasz projekt. Jeśli masz tematy rozrywki, najprawdopodobniej reklama Teaser będzie odpowiednia dla Ciebie. W przypadku niszów komercyjnych (w których coś na sprzedaż), kontekstualna i baner reklama będzie idealnie pasowała.
Natychmiast chcę cię zniechęcić do tworzenia witryn wspólnych tematów. Witryny, na których wszystko o wszystkim jest napisane, nie jest tak łatwe do promowania, ponieważ szczyty od dawna są zaangażowane w słynne portale zaufania. Będzie opłacalne, aby utworzyć wąską stronę, która w krótkim czasie będzie overminić wszystkich konkurentów i będzie konsolidować na szczycie przez długi czas. Rozmawiam z tobą z osobistego doświadczenia.
Moje wąsknoskopie obiektów medycznych po 4 miesiącach po jego stworzeniu zajmuje pierwsze miejsca w Google i Yandex, przy jednoczesnym wyprzedzaniu największych lekarskich portalów ogólnych.
Uzdotematyczne strony promują łatwiejsze i szybsze!
Odwróćmy się do wyboru komercyjnej niszy dla witryny, w której zarobę na reklamę kontekstową. Na tym etapie musisz przestrzegać 3 kryteriów:

Ocena konkurencji w pewnej niszy, korzystam z wyszukiwania w regionie Moskwy, w konkurencji IT jest zwykle wyższa. Aby to zrobić, określ w ustawieniach regionów na koncie w Yandex "Moskwa":
Wyjątkiem jest przypadki, gdy strona jest wykonywana w ramach konkretnego regionu - wtedy musisz oglądać konkurentów w tym regionie.
Główne oznaki niskiej konkurencji w ekstradycji są następujące:
Brak pełnoprawnych odpowiedzi na przypisane żądanie (nieistotna emisja).
Na górze nie ma więcej niż 2-3 stron głównych (nazywane są również "kagankami"). Więcej "Murd" oznacza, że \u200b\u200bcała strona jest celowo porusza się pod tym żądaniem. Wewnętrzna strona Twojej witryny w tym przypadku będzie promować znacznie trudniejsze.
Niedokładne frazy w fragmencie mówią, że wyszukiwanie informacji o konkurentach witryn są po prostu brakuje lub ich strony nie są zoptymalizowane pod tym żądaniem.
Niewielka liczba głównych portali tematycznych. Jeśli na wielu prośbach z przyszłości na górze jest wiele dużych portali i witryn wąskich satelitarnych, musisz zrozumieć, że nisza jest już utworzona, a konkurencja jest tam bardzo wysoka.
Ponad 10 000 wniosków miesięcznie dla podstawowej częstotliwości. To kryterium oznacza, że \u200b\u200bnie powinieneś zbyt wiele, aby "wąski" przedmiotu witryny. Nisza powinna mieć wystarczającą ilość ruchu, na którym możesz zarobić w kontekście. Dlatego na głównym wniosku w wybranym temacie powinno być co najmniej 10 000 wniosków miesięcznie na Vordstatu (bez cytatów i regionów regionu!). W przeciwnym razie będziesz musiał rozszerzyć mały temat.
Również w przybliżeniu oszacowanie liczby ruchu w niszy można wykorzystać przez statystyki obecności witryn, które zajmują pierwsze stanowiska na górze. Jeśli te statystyki są z nimi zamknięte, a następnie użyj
Większość doświadczonych MFA-Shnikov szuka niszów do swoich stron w ten sposób, ale za pomocą serwisu lub programu Finder Micro Niche.
Ten ostatni, przy okazji pokazuje parametr SOC (0-100 - zapytanie zostanie wydane tylko na optymalizacji wewnętrznej, 100-2000 - średniej konkurencji). Możesz bezpiecznie wybrać żądania od SOC mniej niż 300.
Na ekranie poniżej widać nie tylko częstotliwość żądań, ale także średnia cena kliknięcia, pozycje witryny na żądaniach:

Istnieje również przydatny układ jako "potencjalni nabywcy reklamy":

Możesz także wpisać żądanie, które Cię interesuje i przeanalizujesz i żądania podobne do niego:

Jak widać, masz cały obraz na twarzy, pozostaje tylko po to, by sprawdzić konkurencję dla każdego z żądań i wybrać najciekawsze z nich.

Oceniamy koszty ofert dla żyta
Teraz spójrzmy, jak potrzebujesz przeanalizować koszty ofert na witryny RFING.
Idziemy wprowadzić zainteresowane żądania:

W rezultacie otrzymujemy:

Uwaga! Patrzymy na wskaźnik gwarantowanych pokazów! Prawdziwa przybliżona cena kliknięcia będzie 4 razy mniej niż ta pokazana przez usługę.
Okazuje się, jeśli przynosisz na najwyższej stronie o leczeniu zapalenia zatok, a odwiedzający kliknie reklamę, a następnie koszt 1 kliknięcia reklamy będzie równy 12 rubli (1,55 / 4 \u003d 0,39 $).
Jeśli wybierzesz region "Moskwa i region", oferty będą jeszcze wyższe.
Dlatego tak ważne jest, aby wziąć pierwsze miejsca na górze w tym regionie.
Należy pamiętać, że podczas analizy żądań nie trzeba brać pod uwagę prośby handlowe (na przykład "kupić tabelę"). W przypadku projektów treści należy przeanalizować i promować żądania informacji ("Jak zrobić stół z własnymi rękami", "jak wybrać tabelę do biura", "Gdzie kupić tabelę" itp.).
Gdzie szukać zapytań, aby wybrać niszę?
1. Włącz burza mózgów, napisz wszystkie swoje zainteresowania.
2. Napisz, co Cię inspiruje w życiu (może to być jakiś sen, lub związek, styl życia itp.).
3. Rozejrzyj się i zapisz wszystkie rzeczy, które Cię otaczają (umieść wszystko w notebooku w dosłownym sensie: długopis, żarówka, tapeta, sofa, krzesło, obrazy).
4. Jaki masz działalność? Może pracujesz w fabryce za maszyną lub w szpitalu lekarz? Wpisz do notebooka wszystkie rzeczy, których używasz w pracy.
5. Co masz dobrze? Zapisz i to.
6. Sprawdź reklamy w gazetach, czasopismach, ogłoszeniu na stronach, spam na pocztę. Być może one oferują coś ciekawego, co możesz zrobić witrynę.
Znajdź tam strony z udziałem 1000-3000 osób dziennie. Spójrz na temat tych witryn i zapisz najbardziej zapytania o częstotliwości, które przynoszą ruch. Być może jest coś ciekawego.
Podam wybór jednej niszy wąską niszę.
Więc interesowałem się taką chorobą, jak "Obcas Spur". Jest to bardzo wąski mikroskop, który można wykonać małą witrynę na 30 stron. Idealnie doradzam, aby szukać szerszych niszów, które mogą być wykonane przez 100 lub więcej stron.
Otwieramy i sprawdzamy częstotliwość tego żądania (w ustawieniach regionu nie wskazuje nic!):

Doskonały! Częstotliwość głównego żądania wynosi ponad 10 000. Jest ruch w tej niszy.
Teraz chcę sprawdzić konkurencję na prośbie, przez które zostaną promowane na stronie ("Obcina Leczenie Spur", "Leczenie Heel Shpori", "Obcasę, jak traktować")
Włączyłem do Yandex, określam w regionie Ustawienia "Moskwa" i to właśnie dostaję:

Na górze znajduje się wiele wewnętrznych stron policji medycznych tematycznych, aby wyprzedzić, że nie będziemy dla nas trudno (tak się stanie, nie wcześniej niż 3-4 miesiące) i jest twarz 1 witryny, która jest zaostrzona Tematem leczenia szpilki ostrogi.
Strona internetowa WNOPA to 10-stronicowe govarityczne (które, choć PR \u003d 3) z udziałem w 500 gości. Ta strona może być również wyprzedzana, jeśli dokonasz lepszej witryny i promować stronę główną na tym żądaniu.
Po przeanalizowaniu góry dla każdego wniosku można stwierdzić, że ten mikronom nie jest jeszcze zajęty.
Teraz pozostaje ostatni etap - sprawdzanie ofert.
Idźmy i wejdź do naszych prośby (nie musisz wybierać regionu, ponieważ nasza strona odwiedzi ludzi rosyjskojęzycznych z całego świata)
Teraz znajduję średnią arytmetyczną wszystkich wskaźników gwarantowanych pokazów. Okazuje się 0,812 $. Wskaźnik ten jest podzielony przez 4, przychodzi średnio 0,2 $ (6 rubli) za 1 kliknięcie. W przypadku pacjentów medycznych jest to zasadniczo normalny wskaźnik, ale jeśli chcesz, znajdziesz tematy i najlepsze oferty.
Czy powinienem wybrać podobną niszę na stronie? To jest rozwiązanie. Szukałbym szersze nisze, w których byłoby bardziej ruchu i najlepsza wartość klikania.
Jeśli naprawdę chcesz znaleźć dobre tematy, zdecydowanie radzę wykonać następny krok!
Zrób znak z następującymi kolumnami (określałem dane w przybliżeniu):

W dniu, w którym należy napisać co najmniej 25 próśb! Wydaj na poszukiwanie niszę od 2 do 5 dni, a na końcu będzie od tego, co wybrać!
Wybór niszy jest jednym z najważniejszych kroków w tworzeniu witryny, a jeśli reagujesz na niego negocjować, możesz założyć, że w przyszłości po prostu wyrzucasz swój czas i pieniądze.
Jak napisać właściwy zoptymalizowany artykuł
Kiedy piszę artykuł zoptymalizowany na każde żądanie, pierwsze i najważniejsze, że uważa, że \u200b\u200bjest to przydatna i interesująca witryna. Plus, staram się wydać tekst, aby miło było czytać. W moim zrozumieniu idealnie urządzony tekst powinien zawierać:
1. Jasna spektakularna pozycja. To pierwszy tytuł przede wszystkim przyciąga użytkownika podczas przeglądania strony wyników wyszukiwania. Zauważ, że tytuł musi być całkowicie istotny dla tego, co jest zapisane w tekście!
2. Brak "wody" w tekście. Myślę, że kilka kocha, kiedy co może być napisane w 2 słowach, przedstawia kilka arkuszy tekstu.
3. Uprość akapity i sugestie. Więc że tekst jest łatwiejszy, abyś był łatwiejszy, należy złamać duże oferty, które są umieszczone w jednej linii. Uprościć złożoną prędkość. Nie na próżno we wszystkich gazetach i czasopismach tekst jest publikowany przez małe propozycje w kolumnach. Tak więc czytelnik lepiej postrzegać tekst, a jego oczy nie są tak szybko zmęczone.
Akapity w tekście nie powinny być również duże. Tekst najlepiej jest być postrzegany, w którym występują alternatywnie małych i średnich akapitów. Idealny będzie akapit, który składa się z 4-5 linii.
4. Użyj napisów w tekście (H2, H3, H4). Osoba potrzebuje 2 sekundy na otwartą stronę "Skanuj" i zdecyduj się go odczytać, czy nie. W tym czasie przebiega przez stronę i podkreśla najważniejsze elementy, które pomagają mu zrozumieć, co jest wydawane w tekście. Napisy są dokładnie narzędziem, z którym można podłączyć uwagę użytkownika.
Tego że tekst jest ustrukturyzowany, łatwiejszy w percepcji, użyj jednego napisu dla każdego 2-3 akapitów.
Należy pamiętać, że te znaczniki muszą być używane w kolejności (z H2 do H4). Na przykład:
To właśnie nie musisz robić:
<И3>Podtytuł<И3>
<И3>Podtytuł<И3>
<И2>Podtytuł<И2>
A więc możesz:
<И2>Podtytuł<И2>
<И3>Podtytuł<И3>
<И4>Podtytuł<И4>
Możesz być również wykonany w następujący sposób:
<И2>Jak pompa naciśnij<И2>
<И3>Jak pompować prasę w domu<И3> <И3>Jak pompować prasę na poziomym barze<И3> <И2>Jak pompować bicepsy<И2> <И3>Jak pompować bicepsy bez symulatorów<И3>
W tekstach należy zminimalizować słowa kluczowe (nie więcej niż 2-3 razy, w zależności od rozmiaru artykułu). Tekst powinien być jak najbardziej naturalny!
Zapomnij o alokacji słów kluczowych w tłustym i kursywym. Jest to wyraźny znak przytłaczający i Yandex, naprawdę nie lubi. Wybierz tylko ważne sugestie, myśli, pomysły (w tym samym czasie, spróbuj mieć klucz do klucza).
5. Używaj wyraźnych i ponumerowanych list we wszystkich swoich tekstach, cytaty (nie mylisz z cytatami i aforyzmami znanych ludzi! Noszą tylko ważne myśli, pomysły, wskazówki), zdjęcia (z napełnionymi atrybutami alt, tytuł i podpis). Wstaw ciekawe tematyczne filmy do artykułu, jest bardzo dobrze dotknięty czasem trwania odwiedzających pozostanie na stronie.
6. Jeśli artykuł jest bardzo duży, ma sens przy pomocy zawartości i kotwicy linków, aby nawigację w tekście.
Po wykonaniu wszystkich niezbędnych zmian w tekście ponownie przejdź na nią przez twoje oczy. Czy trudno je przeczytać? Może niektóre sugestie muszą zrobić jeszcze mniej? Czy musisz zmienić czcionkę do bardziej czytelnego?
Dopiero po tym, jak jesteś zadowolony ze wszystkich zmian w tekście, możesz wypełnić tytuł, opis i słowa kluczowe i wysyłać go do publikacji.
Wymagania dotyczące tytułu
Tytuł (Tald) jest nagłówkiem w fragmence, który jest wyświetlany w wynikach wyszukiwania. Tytuł tytułu i tytuł w artykule (który jest przydzielony przez tag
) Musi różnić się od siebie, a jednocześnie muszą spełniać główne słowo kluczowe (lub wiele kluczy).Wymagania dotyczące opisu.
Opis powinien być jasny, interesujący. Musi krótko przekazać znaczenie artykułu i nie zapomnieć o niezbędnych słów kluczowych.
Wymagania dla słów kluczowych.
Wpisz tutaj promocyjne słowa kluczowe przez przestrzeń. Nie więcej niż 10 sztuk.
Tak więc, jak piszę zoptymalizowane artykuły.
Przede wszystkim wybieram prośby, które zostaną wykorzystane w artykule. Na przykład podejmiemy podstawową żądanie "Jak nauczyć się zapisywać". Jedź go w Wordstat.yandex.ru

Wordstat przyniósł 14 próśb. Spróbuję użyć większości z nich w artykule w artykule (wystarczy wspomnieć każde słowo kluczowe). Słowa kluczowe mogą być nachylone, zmienione przez miejsca, zastępują synonimy, aby robić jak najwięcej. Wyszukiwarki, zrozumienie rosyjskiego (zwłaszcza Yandex), doskonale rozpoznają synonimy i weź je pod uwagę podczas rankingu.
Rozmiar artykułu staram się określić średnią wielkość artykułów z góry.
Na przykład, jeśli w pierwszej 10 znajduje się 7 witryn, których rozmiar tekst jest zasadniczo 4000-7,000 znaków, a 3 witryny, które ten wskaźnik jest bardzo niski (lub wysoki), ostatnie 3 po prostu nie zwracam uwagę.
Oto przybliżona struktura HTML artykułu zoptymalizowanego przez żądanie "Jak nauczyć się nacisnąć":
……………………………
Jak dowiedzieć się, jak naciskać 100 lub więcej niż 2 miesiące
……………………………
Co powinno być potężne?
……………………………
Codzienny reżim
……………………………
……………………………
Program treningowy
Niektórzy optymalizatory doradzają obowiązkowe, aby wprowadzić główny klucz do pierwszego akapitu. Zasadniczo jest to skuteczna metoda, ale jeśli masz 100 artykułów na stronie, w każdym z których w pierwszym akapicie pojawi się promocyjny wniosek, może mieć nieprzyjemne konsekwencje.
W każdym przypadku radzimy, abyś nie mieszkał na jednym konkretnym schemacie, eksperymentowaniu, eksperymencie i eksperymencie ponownie. I pamiętaj, jeśli chcesz stworzyć witrynę, która pokocha roboty wyszukiwania, sprawiają, że kochany przez prawdziwych ludzi!
Jak zwiększyć frekwencję witryny za pomocą prostej manipulacji z przepełnieniem?
Myślę, że każdy z was widział różnorodne schematy transfinkingowe na stronach, a ja jestem bardziej niż pewny siebie, że nie przywiązałeś dużej wagi do tych schematów. I na próżno. Spójrzmy na pierwszy schemat transfinkujący, który jest większość witryn. Na tym jednak nadal brakuje linków z stron internetowych do domu, ale nie jest to tak ważne. Ważne jest, aby w tym przypadku strona główna waga będzie miała rubryki strony (które najczęściej nie poruszają się i zamykają z indeksowania w Robots.txt!) I głównej strony witryny. Strony z nagraniami w tym przypadku mają najmniejszą wagę:

A teraz myślemy logicznie: Optimizers, którzy są zaangażowani w promowanie projektów treści, są promowane przede wszystkim które strony? To prawda - strony z rekordami (w naszym przypadku, jest to trzeci poziomy). Dlaczego więc promowanie witryny według czynników zewnętrznych (linki), czy tak często zapominamy o nie mniej ważnych - czynniki wewnętrzne (poprawne transfinkowanie)?
A teraz spójrzmy na schemat, w którym wewnętrzne strony będą miały większą wagę:

Można to osiągnąć, po prostu dostosowując przepływ wagi z stron najwyższego poziomu, na stronie niższego, trzeciego poziomu. Nie zapominamy również, że strony wewnętrzne będą dodatkowo pompowane przez linki zewnętrzne w innych witrynach.
Jak skonfigurować podobny strumień wagi? Bardzo proste - z nofollowami Noindex Tagami.
Spójrzmy na witrynę, w której musisz pompować strony wewnętrzne:
Na stronie głównej (1 poziom): Wszystkie wewnętrzne linki są otwarte dla indeksowania, linki zewnętrzne są zamknięte przez NOFollow Noindex, link do karty witryny jest otwarty.
Na stronach z nagłówkami (2 poziom): Aby indeksować, linki do stron z rekordami (trzeci poziom) oraz na mapie witryny, wszystkie inne linki (domowe, rubryki, etykiety, zewnętrzne) są zamknięte przez NOFollow Noindex.
Na stronach z rekordami (poziom 3D): Otwórz linki do strony tego samego, trzeciego poziomu i na mapie witryny, wszystkie inne linki (dom, rubryki, etykiety, zewnętrzne) Zamknij Via NOFollow Noindex.
Po dokonaniu takiego transfinokacji mapa witryny otrzymała największą wagę, która równomiernie dystrybuowana na wszystkich stronach wewnętrznych. Wewnętrzne strony z kolei były znacząco młotkiem. Strona główna i stronę Nagłówki mają najmniejszą wagę, którą właściwie chciałem osiągnąć.
Waga strony Sprawdzę za pomocą programu. Pomaga wizualnie zobaczyć dystrybucję wagi statycznej na stronie, skup się na stronach prognostandardowych, a tym samym podniesienie jego witryny w wydaniu wyszukiwarek, znacznie oszczędzając budżet na zewnętrznych odniesieniach.
I teraz, chodźmy na najciekawsze - wyniki podobnego eksperymentu.
Motyw żeński. Zmiany dystrybucji wagi na stronie zostały wykonane w styczniu tego roku. Taki eksperyment przyniósł +1000 do udziału:

Witryna w filtrze Google, więc baza danych wzrosła tylko w Yandex:

Na zaraniu ruchu w maju miesiącu nie zwracaj uwagi, to jest sezonowość (maj
Wakacje).
2. Drugą witryną przedmiotu, zmiany zostały również wykonane w styczniu:


Ta strona jest jednak stale aktualizowana, a linki są kupowane.
TK dla Copywriters do pisania artykułów
Tytuł artykułu:jak mogą być przydatne zielenie?
Wyjątkowość: nie niższy niż 95% przez etxt
Rozmiar artykułu: 4 000-6 000 znaków bez spacji
Słowa kluczowe:
co jest przydatne dla Greens - główny klucz
przydatne zielenie
przydatne właściwości zieleni
korzystać z Greens.
Wymagania dotyczące artykułu:
Głównym słowem kluczowym (jest wskazany najpierw na liście) nie musi być w pierwszym akapicie, po prostu powinien spotkać się w pierwszej połowie tekstu !!!
Jest zabronione: Grupa Słowa kluczowe w częściach tekstu, musisz rozpowszechniać słowa kluczowe na całym tekście.
Słowa kluczowe muszą być podświetlone pogrubione (konieczne jest, abyś był wygodniejszy, aby sprawdzić zamówienie)
Słowa kluczowe muszą być zgodne z harmonijnie (dlatego konieczne jest użycie nie tylko bezpośredniego wpisu kluczy, ale mogą być również skłonne, aby zmienić słowa w miejscach, użyj synonimów itp.)
Użyj napisów w tekście. W napisach staraj się nie używać bezpośredniego wprowadzania słów kluczowych. Zrób tytułowe napisy dla każdego artykułu, jak to możliwe!
W tekście użyj nie więcej niż 2-3 bezpośrednich wpisów głównego żądania!
Jeśli artykuł musi użyć słów kluczowych "Co jest przydatne", a "Im większe zieleń dla osoby", a następnie pisząc drugi słowo kluczowe, automatycznie używasz pierwszego. Oznacza to, że nie ma specjalnej potrzeby pisać 2 razy większy od klucza, jeśli ma już wpis inny klucz.
Witaj, drogi witryna czytników blogów. Chcę zrobić kolejną okazję na temat "Kolekcja Susyadera". Po pierwsze, jak powinno być, a wtedy wiele praktyk może być nieco niezdarna w mojej wydajności. Tak, teksty. Chodzić z oczami z zawiązanymi oczami w poszukiwaniu powodzenia, byłem zmęczony rokiem po rozpoczęciu tego bloga. Tak, było "udane uderzenie" (intuicyjne zgadywanie często zadawanych wyszukiwarek zapytania) i był pewien ruch z wyszukiwarek, ale chciałem pokonać cel za każdym razem (przynajmniej do zobaczenia).
Potem chciała więcej - automatyzacji procesu zbierania żądań i odkryć "pacyfikatorów". Z tego powodu doświadczenie jest doświadczeniem z Kasonem (i jego niezwiązanym młodszym bratem) i innym artykułem na ten temat. Wszystko było świetne, a nawet po prostu wspaniałe, dopóki nie zdałem sobie sprawę, że jest jeden bardzo ważny punkt, który pozostaje zasadniczo za kulisami - prośbą o rozproszenie artykułów.
Aby napisać oddzielny artykuł w ramach oddzielnego wniosku, jest uzasadnione albo w wysoce konkurencyjnych temachach, albo w bardzo opłacalnym. W przypadku infositów jest to pełne nonsensów, a zatem musisz połączyć zapytania na jednej stronie. W jaki sposób? Intuicyjnie, tj. Ponownie ślepo. Ale nie wszystkie prośby idą na jednej stronie i mają przynajmniej hipotetyczną szansę na pójście na szczyt.
Właściwie, dziś zostanie omówiony na automatyczny klastrowanie jądra semantycznego przez Keassort (załamanie żądań stron i na nowe miejsca istnieje również konstrukcja na podstawie struktury, tj. Sekcje, kategorie). Cóż, a proces zbierania żądań odbędzie się dla każdego strażaka (w tym nowe narzędzia).
Który z jądra semantycznego jest najważniejszym montażem?
Kolekcja wniosków (fundamentów jądra semantycznego) na przyszłość lub już istniejąca witryna jest procesem jest dość interesująca (dla kogoś, tak jak oczywiście) i wdrożone może być kilka sposobów, których wyniki można następnie łączyć w jeden Duża lista (skręcony duplikat, usuwanie smoczki w słowach stóp).
Na przykład, możesz ręcznie zacząć przerażać WordStat, a oprócz go do podłączenia KeCikelector (lub jego nieodnośnej wersji bezpłatnej). Jednak wszystko jest świetne, gdy jesteś mniej lub bardziej zaznajomiony z tematem i znasz kluczy, do których możesz polegać na (zbieranie ich pochodnych i podobnych prośby z prawej kolumny WordStat).
W przeciwnym razie (tak, aw każdym razie nie przeszkadza) będzie możliwe rozpoczęcie od narzędzi "szlifowania grubego". Na przykład, Serpstat. (W głównym prodvigator), co pozwala dosłownie "robić" konkurentom dla słów kluczowych, których używasz (patrz). Istnieją inne podobne usługi "Robbing Competitors" (Spywords, Keys.SO), ale jestem "upieczony" dokładnie do dawnego stopnia.
W końcu jest darmowa klamerka, która pozwala bardzo szybko rozpocząć żądania montażu. Możesz także zamówić prywatną rozładunek bazy danych Monster AHREFS i ponownie zdobądź klucze konkurentów. Ogólnie rzecz biorąc, warto rozważyć wszystko, co może przynieść co najmniej tolialną przydatną do promocji promocji przyszłej promocji, która nie jest tak trudna do czyszczenia i łączenia w jedną dużą (często nawet ogromną listę).
Wszystko to (w ogólnych warunkach, oczywiście), rozważmy trochę niższe, ale w końcu zawsze wstaje główne pytanie - co zrobic nastepnie. W rzeczywistości strasznie dzieje się po prostu podejść do tego, co otrzymaliśmy w rezultacie (przez waląc kilkanaście innych konkurentów i screamers na niewolującym Kasonie). Głowę może wybuchnąć od próby przerwy wszystkich tych żądań (słów kluczowych) na niektórych stronach przyszłości lub już istniejącej witryny.
Jakie żądania odniosą sukces na jednej stronie, a co nawet nie próbują zjednoczyć? Naprawdę trudne pytanie, które wcześniej zdecydowałem się wyłącznie w intuicyjnie, za analizę wydawania Yandexa (lub Google) dla tematu "i jak tam z konkurentami" ręcznie ubojem, a opcje automatyzacji nie natknęły się. Cóż, na razie. Tak samo, takie narzędzie "nawiedziane" i dzisiaj zostanie omówione w ostatniej części artykułu.
To nie jest usługa online, ale rozwiązanie oprogramowania, które dystrybuuje, które możesz pobrać Na stronie głównej oficjalnej strony (wersja demo).

Dlatego nie ma ograniczeń na temat liczby próśb odzyskiwalnych - ile potrzebujesz, tak bardzo i proces (istnieje jednak niuanse w gromadzeniu danych). Wersja płatna kosztuje mniej niż dwa tysiące, co dotyczy rozwiązanych zadań, możesz powiedzieć, na nic (IMHO).
Ale o technicznej stronie Keassort, porozmawiamy tuż poniżej, a tutaj chciałbym powiedzieć o sobie zasada, która pozwala podzielić listę słów kluczowych (prawie każda długość) na klastrach, tj. Zestaw słów kluczowych, które można pomyślnie wykorzystać na jednej stronie witryny (optymalizować tekst, nagłówki i masę referencyjną pod nimi - stosować magię SEO).
Gdzie mogę narysować informacje? Kto powie ci, że "płonie", ale co nie będzie działać niezawodnie? Oczywiście najlepszą radą będzie sama wyszukiwarka (w naszym przypadku Yandex, jako magazyn żądań komercyjnych). Wystarczy spojrzeć na dużą ilość wydawania danych (na przykład, w celu przeanalizowania pierwszej 10) we wszystkich tych żądaniach (z zebranej listy przyszłych semilar) i zrozumiałe jest, że udało Ci się pomyślnie połączyć na jednej stronie. Jeśli ten trend jest powtarzany kilka razy, możemy mówić o wzorach, a na podstawie go można ją pobić klucze do klastrów.
Keyassort umożliwia ustawienie "Rigor" w ustawieniach, z którymi skupiska zostaną utworzone (wybierz klawisze, których można użyć na jednej stronie). Na przykład, dla handlu, ma sens, aby dokręcić wymagania wyboru, ponieważ ważne jest uzyskanie gwarantowanego wyniku, choć z nieco dużym wydatkowaniem na pisanie tekstów do większej liczby klastrów. W przypadku witryn informacyjnych możesz odwrotnie, aby dokonać pewnego relaksu, dzięki czemu masz mniejszy wysiłek, aby uzyskać potencjalnie większy ruch (z nieco dużym ryzykiem "braku spalania"). Jak to zrobić ponownie rozmawiać.
A co robić, jeśli masz już stronę z grupą artykułów, ale chcesz rozwiń istniejący Seedro. I optymalizuj już dostępne artykuły w większej liczbie kluczy, aby zminimalizować wysiłki (trochę przesuwania kluczy akcentowych), aby uzyskać ruch do ruchu? Ten program i to pytanie podaje odpowiedź - możesz poprosić o istniejące strony, w których istniejące strony są już zoptymalizowane, aby utworzyć klaster z dodatkowymi żądaniami, które są dość skutecznie promowane (na jednej stronie) kompetencji do wydawania. Co ciekawe, okazuje się ...
Jak zmontować pulę żądań dla tematu potrzebujesz?
Każde jądro semantyczne rozpoczyna się w rzeczywistości od zbierania ogromnej liczby żądań, z których większość zostanie odrzucona. Ale główną rzeczą jest to, że na początkowym etapie uderzyli w to "pereł", które zostaną utworzone, a poszczególne strony przyszłości lub już istniejącej witryny zostaną utworzone i zaliczki. Na tym etapie najprawdopodobniej najważniejsze jest zdobycie znacznie więcej lub mniej odpowiednich zapytań i nie przegapić niczego, a pacyfikatory są wtedy łatwe do odcięcia.
Pojawia się uczciwe pytanie i jakie narzędzia do tego użycia? Jest jedna jednoznaczna i bardzo poprawna odpowiedź - inna. Im większy tym lepszy. Jednak te najbardziej metody zbierania jądra semantycznego, prawdopodobnie warto wymienić i dawać ogólne oceny i zalecenia dotyczące ich użycia.
- Yandex Wordstat. A jego analogi w innych wyszukiwarkach - początkowo te narzędzia były przeznaczone dla tych, którzy umieszczają reklamy kontekstowe, aby mogli zrozumieć, jak popularne zwroty wyszukiwarki są tak popularne. Cóż, jasne jest, że sostery są również używane przez te instrumenty i bardzo pomyślnie. Mogę polecić przełączenie za pomocą artykułu w artykule, a także artykuł wspomniany na samym początku niniejszej publikacji (będzie przydatny dla początkujących).

Z wad wody można zauważyć:
- Potężnie wiele ręcznie robionych (automacja jest zdecydowanie wymagana i zostanie uznana za nieco niższa), oba przełamując frazy oparte na kluczu i przełamując przez odpytań asocjacyjnych z prawej kolumny.
- Ograniczenie wydawania WordStat (zapytania 2000, a nie więcej) może stać się problemem, dla niektórych fraz (na przykład "praca") jest niezwykle mała i tęsknimy z rodzajem niskiej częstotliwości, a czasami nawet w połowie - Pytania, które mogą przynieść dobry ruch i dochód (po wszystkim brakuje wielu). Konieczne jest, aby "odkształcić wiele" lub użyć alternatywnych metod (na przykład baz danych słów kluczowych, z których będziemy przyjrzeć się poniżej - podczas gdy jest bezpłatny!).
- Caicollector. (i jego wolny młodszy brat Slovoeb.) - Kilka lat temu pojawienie się tego programu było po prostu "zbawienie" dla wielu pracowników sieciowych (a teraz jest dość trudno sobie wyobrazić bez QC). Tekst piosenki. Kupiłem CC przez dwa lub trzy lata temu, ale używałem ich od siły przez kilka miesięcy, ponieważ program jest związany z dławikiem (farsz przedziałowy) i zmienia mnie kilka razy w roku. Ogólnie rzecz biorąc, posiadanie licencji na QC, którego używam SE - dlatego przynosę zbyt leniwy.

Możesz przeczytać szczegóły w artykule "". Oba programy pomogą Ci zbierać żądania i po prawej stronie, a z lewej kolumny WordStat, a także wskazówki wyszukiwania na potrzebnych wyrażeniach kluczy. Wskazówki odbywa się z ciągów wyszukiwania, gdy zaczniesz wpisywać żądanie. Użytkownicy często bez wykończenia zestawu Po prostu wybierz najbardziej odpowiednią opcję z tej listy. Ceany tej firmie żądano i używać takich żądań w optymalizacji, a nawet.
CK i SE pozwalają na natychmiastowe wybieranie bardzo dużej puli żądań (choć może być konieczne, aby zająć dużo czasu lub kupować limity XML, ale o tym jest nieco niższe) i jest łatwy do podeszwych pacyfikatorów Przykład, sprawdzanie częstotliwości zwrotów podjętych w cytatach (naucz meczu, jeśli nie rozumiesz, jakiego przemówienia - linki na początku publikacji) lub zadawanie listy słów (szczególnie istotnych dla handlu). Potem całą pulę żądań można łatwo eksportować do programu Excel, aby uzyskać dalsze działanie lub do pobrania do Keyassort (Clusterizer), który zostanie omówiony poniżej.
- Serpstat. (i inne podobne usługi) - pozwala przedstawić ul. swojej witryny, aby uzyskać listę konkurentów do wydania Yandexa i Google. Dla każdego z tych konkurentów możliwe będzie uzyskanie pełnej listy słów kluczowych, dla których udało im się przebić i osiągnąć pewne wysokości (uzyskać ruch z wyszukiwarek). Tabela podsumowania będzie zawierać częstotliwość wyrażenia, witryny witryny na nim na górze i kilka innych różnych użytecznych i niezbyt informacji.

Nie tak dawno temu, użyłem niemal najdroższego planu taryfy Serpstata (ale tylko jeden miesiąc) i udało mi się wyjść na ten czas w Excelu niemal Gigabajty o różnych przylotnikach. Zebrałem nie tylko klucze konkurentów, ale także tylko basen prośby o zainteresowany mnie w kluczowych frazach, a także zebrał półomer najbardziej udanych stron swoich konkurentów, które wydaje mi się bardzo ważne. Jedna zła rzecz - teraz nie znajdziem czasu, aby zbliżyć się do przetwarzania wszystkich tych nieocenialnych informacji. Ale możliwe jest, że Keyassort nadal będzie usunąć rozłączenie przed przetworzeniem monstrualnej mahuiny.
- Bukvilk. - Darmowa baza słów kluczowych w własnej skorupy oprogramowania. Wybór kluczowych czorów wymaga podzielonego drugiego (rozładunek do minuty Excel). Ile milionów słów nie pamięta, ale opinie o niej (w tym moje) są po prostu świetne, a co najważniejsze, to wszystko jest bogactwo za darmo! Prawda, dystrybucja programu waży 28 koncertów, w postaci podzielonej, baza zajmuje ponad 100 GB na dysku twardym, ale to wszystkie małe rzeczy w porównaniu z prostotą i szybkością prośby o pulę żądań.

Ale główną zaletą jest to nie tylko stawka zbierania bezpieczeństwa bezpieczeństwa w porównaniu z WordStat i Kasonem. Najważniejsze jest to, że nie ma żadnych ograniczeń na temat linii 2000 dla każdego wniosku, co oznacza, że \u200b\u200bnie ma żadnych LF, a nad LF od nas nie zostaną uwzględnione. Oczywiście częstotliwość można wyjaśnić, aby zostać wyjaśniona przez to samo QC i na słowach w nim, aby przeprowadzić egzaminator, ale główne zadanie Bundlera działa świetnie. To prawda, że \u200b\u200bsortowanie kolumn nie działa dla niego, ale zachowując pulę prośby o Excel, można posortować jako eleganckie.
Prawdopodobnie, co najmniej kilka "poważnych" narzędzi katedry basenu prośbnych dadzą ci w komentarzach i pomyślnie je pożyczyłem ...
Jak czyścić zebrane zapytania wyszukiwania z "Dusties" i "Garbage"?
Lista uzyskana w wyniku powyższej manipulacji prawdopodobnie będzie bardzo duża (jeśli nie jest ogromna). Dlatego przed przesłaniem go do klastra (będziemy mieli Keyassort) ma sens, aby lekko oczyścić. Aby to zrobić, na przykład pulę żądań, może być rozładowana do kecikelekeser i usuń:
- Wnioski o zbyt niskiej częstotliwości (osobiście łamę częstotliwość w cytatach, ale bez wykrzykników). Który próg wyboru rozwiązania Ciebie, a pod wieloma względami zależy to od obiektu, konkurencyjności i rodzaju zasobów, który zamierza nasiona.
- W przypadku żądań komercyjnych ma sens, korzystanie z listy słów zatrzymań (typ, "wolny", "Pobierz", "Esej", a także na przykład nazwy miast, itp.) Aby usunąć Fakt, że nie doprowadzi do miejsca ukierunkowanych nabywców (odciąć zamrażacze, szukając informacji, a nie towarów, studni i mieszkańców innych regionów).
- Czasami ma sens, aby kierować się wskaźnikiem konkurencji na temat tego żądania w ekstradycji. Na przykład na życzenie "Plastic Windows" lub "Klimatyzatory", nie można nawet krzyczeć - awaria została wykonana z wyprzedzeniem i w 100% gwarancji.
Powiedz mi, że jest to zbyt łatwe w słowach, ale trudno jest w rzeczywistości. I tutaj nie jest. Dlaczego? A ponieważ jeden drogi człowiek (Michail Shakin) nie żałował czasu i nagrał wideo ze szczegółowymi opis metod czyszczenia zapytań wyszukiwania w kluczowym kolektorze:
Dziękujemy za to, ponieważ te pytanie jest znacznie łatwiejsze i wyraźniejsze, aby pokazać, co opisać w artykule. Ogólnie rzecz biorąc, bo wierzę w ciebie ...
Konfigurowanie klastra nasion Keyassort dla Twojej witryny
Właściwie zaczyna się najciekawszy. Teraz ta cała ogromna lista kluczowa będzie musiała jakoś podzielić (rozpraszać) na poszczególnych stronach swojej przyszłości lub już istniejącej witryny (którą chcesz znacząco poprawić pod względem postępu ruchu). Nie będę powtórzyć i porozmawiam o zasadach i złożoności tego procesu, dlaczego to napisałem pierwszą część tego.
Więc nasza metoda jest dość prosta. Idziemy na oficjalną stronę internetową Keyassort i pobierz wersję demoAby wypróbować program do zęba (różnica między demo z pełnej wersji jest niezdolność do rozładunku, a następnie chcesz wyeksportować zebraną sadlock), a już obejście może być wypłacane i płatne (1900 rubli - niewiele, mało na nowoczesne rzeczywistość). Jeśli chcesz natychmiast rozpocząć pracę nad rdzeniem, co nazywa się "na Castovik", lepiej wybrać pełną wersję z możliwością eksportu.
Sam program KeiysSort nie jest w stanie zbierać kluczy (to jest właściwie, a nie jego prerogatywny), a zatem będą potrzebne do pobrania ich. Możesz to zrobić na cztery sposoby - ręcznie (prawdopodobnie, jest sens, aby uciekać się do tej metody, aby dodać niektóre z już znanych głównych kolekcji kluczowych), a także trzy opakowania do importowania kluczy:
- w formacie TCT - gdy musisz zaimportować tylko listę kluczy (każdy na oddzielnej linii pliku TCT i).
- oprócz dwóch opcji formatu exeline: z parametrami potrzebujesz w przyszłości lub ze zebranymi witrynami z TOP10 dla każdego klucza. Ten ostatni może przyspieszyć proces klastrowania, ponieważ program Keyasort nie musi analizować siebie do zbierania tych danych. Jednak ulle z TOP10 muszą być świeże i dokładne (można uzyskać taką wersję listy, na przykład w kecikeletser).
Tak, co ci mówię - lepiej widzieć raz:
W każdym przypadku, początkowo nie zapomnij utworzyć nowego projektu w tym samym menu "Plik", a tylko wtedy stanie się jedynie niedrogą funkcją importową:

Uruchommy w ustawieniach programu (korzyść z nich jest nieco), ponieważ dla różnych typów witryn może być optymalne różne ustawienia. Otwórz kartę "Serwis" - "Ustawienia programu" I możesz natychmiast przejść do karty "Klastralizacja":

Tu najważniejsze jest, być może wybór rodzaju klastra, którego potrzebujesz. Program może korzystać z dwóch zasad, dla których żądania łączy się na grupy (klastry) są twarde i miękkie.
- Ciężko - wszystkie prośby, które spadły w jedną grupę (nadają się do promocji na jednej stronie) muszą być połączone na jednej stronie w wymaganej liczbie konkurentów z góry (liczba ta jest ustawiona w "mocy linii" linii ").
- Miękkie - wszystkie wnioski, które spadły w jedną grupę, będą częściowo spotykać się na jednej stronie od pożądanej liczby konkurentów i wierzchołków (liczba ta jest również ustawiona w grupie "Siła grupowania").
Jest dobry obraz. Żywo wszystko to ilustruje:

Jeśli nie jest jasne, nieważne, ponieważ jest to tylko wyjaśnienie zasady, i nie jesteśmy dla nas ważni, ale praktyka, która mówi, że:
- Ciężka kasetryzacja jest lepsza do ubiegania się o miejsca komercyjne. Ta metoda zapewnia wysoką dokładność, dzięki czemu prawdopodobieństwo wejścia na górę na jednej stronie witryny witryny będzie wyższe (przy odpowiednim podejściu do optymalizacji tekstu i jej promocji), chociaż same wnioski są mniej w klastrze, a Dlatego same klastry są więcej (więcej będzie musiał stworzyć i promować).
- Miękka kasetryzacja ma sens do korzystania z witryn informacyjnychW przypadku artykułów zostanie uzyskany przy wysokiej pełni kompletności (będzie w stanie odpowiedzieć na liczbę podobną w rozumieniu żądań użytkownika), co jest również uwzględniane w rankingu. A same strony będą mniejsze.
Innym ważnym, moim zdaniem, kleszcz jest kleszczem w polu "Użyj zwrotów znaczników". Dlaczego to może to potrzebować? Zobaczmy.
Załóżmy, że masz już stronę, ale strony na nim zostały zoptymalizowane, nie pod pulą żądań, ale dla jednego lub tego basenu uważasz za wystarczającą ilość luzem. W tym samym czasie, wszyscy serce chce rozszerzyć Seyedro nie tylko dodając nowe strony, ale także poprzez poprawę już istniejących stron (nadal łatwiej jest w realizacji). Potrzebujesz więc dla każdej takich stron, aby zapobiec sedro "do kompletnego".
To jest to, czego potrzebujesz tego ustawienia. Po jego aktywacji naprzeciwko każdej frazy na liście żądań można umieścić kleszcz. Znajdziesz tylko te główne prośby, które już zoptymalizowałeś istniejące strony swojej witryny (jedną na stronę), a program KeAssort będzie zbudować klastry wokół nich. Właściwie wszyscy. Czytaj więcej "Dym" w tym filmie:
Inny ważny (dla prawidłowego działania programu) ustawienie mieszka na karcie "Kolekcja danych z Yandex XML". Możesz przeczytać w artykule. Jeśli krótko, Soshery stale analizują wydawanie Yandex i wydawanie WordStat, tworząc nadmierne obciążenie jego mocy. W celu ochrony wprowadzono CAPTCHA, a także specjalny dostęp XML do XML, gdzie CAPTCHA nie osiągnie i zniekształca danych na weryfikowanych klawiszy. Prawda, liczba takich kontroli dziennie będzie ściśle ograniczona.
Od czego zależy liczbę dedykowanych limitów? Z jak Yandex będzie ocenił twój. Możesz przejść na ten link (w tej samej przeglądarce, gdzie jesteś zalogowany w YA.VEBMASTER). Na przykład wygląda tak:

Nadal jest harmonogram dystrybucji limitów o porę dnia, co jest również ważne. Jeśli prośby muszą być dużo wlewa, a limity nie wystarczą, nie stanowi problemu. Można je kupić. Nie Yandex, oczywiście, bezpośrednio, a ci, którzy mają te limity, ale ich nie potrzebują.
Mechanizm Yandex XML umożliwia przesyłanie limitów, a wymiany związane z pośrednikami pomagają wszystkim zautomatyzować. Na przykład, na Xmlproxy. Możesz kupić limity tylko dla 5 rubli na 1000 żądań, które widzisz, nie dość drogie.
Ale nie jest ważne, ponieważ kupiłeś limity nadal płynąć do Ciebie na "konto", ale aby ich użyć w Keyassort, musisz przejść do karty " Oprawa"I skopiuj długą link do pola" URL na żądania "(nie zapomnij kliknąć" bieżącego IP "i kliknij przycisk" Zapisz ", aby połączyć klawisz do komputera):

Następnie wkładaj to tylko UL do okna za pomocą ustawień KeAssort w polu "URL do zapytania":

Właściwie, wszystko, z ustawieniami KeAssort, jest zakończone - możesz rozpocząć klastrowanie jądra semantycznego.
Klugowe frazy kluczowe w Keyassort
Mam więc nadzieję, że wszyscy jesteście ustawione (wybrałeś pożądany typ klastrowania, podłączony lub zakupionych limitów z Yandex XML), zajmować się sposobami importowania listy z żądaniami, i z powodzeniem cały ten przypadek został przeniesiony do Keyssort. Co dalej? A potem najciekawsze jest rozpoczęcie gromadzenia danych (witryny witryn TOP10 na każdym żądaniu) i kolejne klastrowanie całej listy na podstawie tych danych i tworzonych ustawień.
Tak więc na początek kliknij przycisk "Zbieraj dane" Oczekujemy od kilku minut do kilku godzin, podczas gdy program trwa blaty na wszystkich prośbach z listy (niż są więcej, tym dłuższe czekać):

Mam trzysta prośby (jest to małe jądro do serii artykułów na temat pracy w Internecie) udało się około minuty. Po czym już możesz zmiana bezpośrednio do skasowaniaTen sam przycisk jest dostępny na pasku narzędzi KeAssort. Ten proces jest bardzo szybki i dosłownie po kilku sekundach otrzymałem cały zestaw rolek (grup) urządzonych w formie zainwestowanych list:

Szczegółowe informacje na temat korzystania z interfejsu programu, a także o tworzenie klastrów dla istniejących stron witryny Zobacz lepiej w filmie, ponieważ jest tak wyraźniejszy:
Chcieliśmy wszystkie, dostaliśmy i zauważamy - na pełnym automatowi. Lepoty.
Chociaż, jeśli utworzysz nową stronę, z wyjątkiem klastrowania jest bardzo ważne zwróć uwagę na przyszłą strukturę witryny (Określ sekcje / kategorie i rozpowszechniać klastry na przyszłe strony). Co dziwne, ale jest dość wygodne do zrobienia w Keyassort, ale prawda nie jest już automatycznie, ale w trybie ręcznym. W jaki sposób?
Łatwiej będzie jeszcze raz zobaczyć - wszystko rozprzestrzenia się dosłownie przed oczami prostego przeciągania klastrów z lewego okna programu po prawej:
Jeśli kupiłeś program, możesz wyeksportować uzyskane jądro semantyczne (i w rzeczywistości strukturę przyszłej witryny) w programie Excel. Ponadto na pierwszej karcie z żądaniami możliwe będzie działanie jako pojedyncza lista, a struktura zostanie już zapisana na sekundę, którą skonfigurowałeś w Keyasort. Bardzo, bardzo wygodny.
Cóż, bez względu na to, jak. Gotowy do omówienia i usłyszenia swojej opinii na temat kolekcji siewników na stronie.
Powodzenia! Do niejednoznacznych spotkań na stronie internetowej na blogu
Możesz być zainteresowany
VPODSKAZKE - Nowa usługa w celu rozwiązania monitów w wyszukiwarkach SE Ranking - najlepsza usługa monitorowania usług dla początkujących i profesjonalistów w SEO Zbieranie pełnego jądra semantycznego w Toppoolozorze, różnorodność sposobów wyboru słów kluczowych i stron grupujących Praktyka zbierania jądra semantycznego w ramach SEO od profesjonalisty - jak to dzieje się w obecnej rzeczywistości 2018 Optymalizacja czynników behawioralnych bez oszukiwania SEO Powersite - Audytor strony internetowej, Tracker Rank i zewnętrzny (SEO Spyglass, LinkAssistant) Optymalizacja witryny Wybór słów kluczowych w Yandex Wordstat - Analiza statystyk Ręcznie i za pomocą SloveB lub Key Collector  SERPSTAT - Przegląd narzędzi "Monitorowanie pozycji", "klastrowania" i "analityki tekstowej"
SERPSTAT - Przegląd narzędzi "Monitorowanie pozycji", "klastrowania" i "analityki tekstowej"


