SQL - Lekcja 15. Procedury składowane. Część 1
Z reguły współpracujemy z bazą danych przy użyciu tych samych zapytań lub zestawu kolejnych zapytań. Procedury przechowywane pozwalają łączyć sekwencję żądań i przechowywać je na serwerze. To bardzo wygodne narzędzie i teraz je zobaczysz. Zacznijmy od składni:UTWÓRZ PROCEDURĘ nazwa_procedury (parametry) początek instrukcji koniec
Parametry to dane, które przekażemy do procedury po jej wywołaniu, a operatory to rzeczywiste żądania. Napiszmy pierwszą procedurę i zadbajmy o jej wygodę. W lekcji 10, kiedy dodaliśmy nowe rekordy do bazy danych sklepu, użyliśmy standardowego zapytania, aby dodać widok:
INSERT INTO klientów (imię i nazwisko, adres e-mail) WARTOŚĆ („Siergiej Iwanow”, „ [chroniony e-mailem]");
Ponieważ Użyjemy podobnego żądania za każdym razem, gdy musimy dodać nowego nabywcę, całkiem właściwe jest umieszczenie go w formie procedury:
UTWÓRZ PROCEDURĘ ins_cust (n CHAR (50), e CHAR (50)) rozpocznij wstawianie do klientów (nazwa, adres e-mail) wartość (n, e); koniec
Zwróć uwagę na sposób ustawiania parametrów: musisz nadać parametrowi nazwę i wskazać jego typ, aw treści procedury już używamy nazw parametrów. Jedno zastrzeżenie. Jak pamiętacie, średnik oznacza koniec żądania i wysyła go do wykonania, co w tym przypadku jest niedopuszczalne. Dlatego przed napisaniem procedury należy ponownie zdefiniować separator za pomocą; na „//”, aby żądanie nie zostało wysłane z wyprzedzeniem. Odbywa się to za pomocą operatora DELIMITER //: 
Dlatego wskazaliśmy DBMS, że polecenia powinny być teraz wykonywane po //. Należy pamiętać, że redefinicja separatora odbywa się tylko dla jednej sesji, tj. podczas następnej sesji z MySql separator ponownie stanie się średnikiem i, jeśli to konieczne, będzie musiał zostać ponownie zdefiniowany. Teraz możesz umieścić procedurę:
UTWÓRZ PROCEDURĘ ins_cust (n CHAR (50), e CHAR (50)) rozpocznij wstawianie do klientów (nazwa, adres e-mail) wartość (n, e); koniec //

Procedura została utworzona. Teraz, gdy musimy wprowadzić nowego nabywcę, wystarczy, że zadzwonimy do niej, wskazując niezbędne parametry. Do wywołania procedury składowanej służy operator CALL, po czym wskazana jest nazwa procedury i jej parametry. Dodajmy nowego kupującego do naszej tabeli Klientów:
wywołanie ins_cust („Sychov Valery”, „ [chroniony e-mailem]")//

Zgadzam się, że jest to o wiele łatwiejsze niż pisanie pełnego wniosku za każdym razem. Sprawdźmy, czy procedura działa, sprawdzając, czy w tabeli Klienci pojawił się nowy nabywca:

Pojawiło się, procedura działa i zawsze będzie działać, dopóki nie usuniemy jej za pomocą operatora DROP PROCEDURE nazwa_procedury.
Jak stwierdzono na początku lekcji, procedury pozwalają łączyć sekwencję zapytań. Zobaczmy, jak to się robi. Pamiętasz, jak w lekcji 11 chcieliśmy dowiedzieć się, ile dostawca „Drukarni” przyniósł nam? Aby to zrobić, musieliśmy użyć zagnieżdżonych zapytań, złączeń, kolumn obliczeniowych i widoków. A jeśli chcemy wiedzieć, ile drugi dostawca przyniósł do nas? Będą musiały tworzyć nowe zapytania, skojarzenia itp. Łatwiej jest napisać procedurę składowaną dla tego działania raz.
Wydaje się, że najłatwiej jest wziąć widok i zapytanie napisane już w lekcji 11, połączyć je w procedurę składowaną i uczynić identyfikator dostawcy (id_vendor) parametrem wejściowym, jak poniżej:
UTWÓRZ PROCEDURĘ sum_vendor (i INT) rozpocznij UTWÓRZ PODGLĄD raport_vendor JAKO WYBIERZ magazyn_wjazd.id_produkt, magazyn_wchodzący. Ilość, ceny. cena, magazyn_wychodzący. ilość * ceny. cena AS summa Z magazynu_wjazd, ceny GDZIE magazyn_wjazd.id_produkt \u003d ceny. Produkt WYBIERZ id_incoming od przychodzącego WHERE id_vendor \u003d i); SELECT SUM (summa) FROM report_vendor; koniec //
Ale ta procedura nie zadziała. Chodzi o to, że widoki nie mogą używać parametrów. Dlatego będziemy musieli nieco zmienić sekwencję żądań. Najpierw stworzymy widok, który wyświetli identyfikator dostawcy (id_vendor), identyfikator produktu (id_product), ilość (ilość), cenę (cenę) i sumę (summa) z trzech tabel Dostawa (przychodzące), Dziennik dostawy (nadchodzące czasopismo), Ceny ( ceny):
UTWÓRZ WIDOK report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity * prices.price AS summa FROM przychodzący, magazine_incoming, ceny WHERE magazine_incoming.id_product \u003d ceny.id_product AND magazine_incoming .id_incoming
A następnie utwórz żądanie, które sumuje kwoty dostaw dostawcy będącego przedmiotem zainteresowania, na przykład za pomocą id_vendor \u003d 2:
Teraz możemy połączyć te dwa żądania w procedurę składowaną, w której parametrem wejściowym będzie identyfikator dostawcy (id_vendor), który zostanie podstawiony w drugim żądaniu, ale nie w widoku:
CREATE PROCEDURE sum_vendor (i INT) rozpocznij CREATE VIEW report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.price, magazine_incoming.quantity * prices.price AS summa Z przychodzących, magazine_incoming, ceny WHERE magazine_incoming.id .id_product AND magazine_incoming.id_incoming \u003d incoming.id_incoming; SELECT SUM (summa) FROM report_vendor GDZIE id_vendor \u003d i; koniec //

Sprawdź działanie procedury przy różnych parametrach wejściowych:

Jak widać, procedura jest uruchamiana raz, a następnie wyświetla błąd, informując nas, że widok report_vendor już istnieje w bazie danych. Dzieje się tak, ponieważ po otwarciu procedury po raz pierwszy tworzy widok. Podczas uzyskiwania dostępu po raz drugi próbuje ponownie utworzyć widok, ale już istnieje i dlatego pojawia się błąd. Aby tego uniknąć, możliwe są dwie opcje.
Pierwszym jest wyciągnięcie pomysłu z procedury. Oznacza to, że raz utworzymy widok, a procedura będzie się do niego odwoływała, ale nie będzie go tworzyć. Pamiętaj, aby usunąć już utworzoną procedurę i wyświetlić:
PROCEDURA DROP sum_vendor // DROP VIEW report_vendor // UTWÓRZ WIDOK report_vendor JAKO WYBIERAM incoming.id_vendor, magazine_incoming.id_product, magazine_incoming.quantity, prices.cice, magazine_incoming.quantity * prices.price AS summa FROM przychodzący, czasopismo_wstępne ceny \u003d price.id_product AND magazine_incoming.id_incoming \u003d incoming.id_incoming // CREATE PROCEDURE sum_vendor (i INT) rozpocząć SELECT SUM (summa) OD report_vendor GDZIE id_vendor \u003d i; koniec //

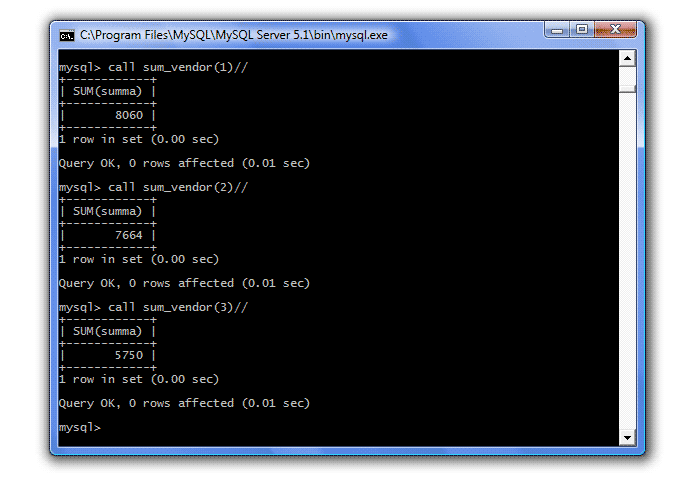
Sprawdź pracę:
call sum_vendor (1) // call sum_vendor (2) // call sum_vendor (3) //
Drugą opcją jest dodanie polecenia bezpośrednio do procedury, która usunie widok, jeśli istnieje:
UTWÓRZ PROCEDURĘ sum_vendor (i INT) rozpocznij DROP VIEW JEŚLI ISTNIEJE report_vendor; UTWÓRZ WIDOK report_vendor AS SELECT incoming.id_vendor, magazine_incoming.id_product, magazine_incoming. Ilość .id_incoming SELECT SUM (summa) FROM report_vendor GDZIE id_vendor \u003d i; koniec //
Przed użyciem tej opcji nie zapomnij usunąć procedury sum_vendor, a następnie sprawdź operację: 
Jak widać, złożone zapytania lub ich sekwencje są naprawdę prostsze w wydaniu raz w procedurze składowanej, a następnie dostęp do niej, wskazując niezbędne parametry. To znacznie zmniejsza kod i sprawia, że \u200b\u200bpraca z zapytaniami jest bardziej logiczna.
Uwzględnij wiersz - USTAW NOCOUNT NA:
Przy każdym wyrażeniu DML serwer SQL ostrożnie zwraca komunikat zawierający liczbę przetworzonych rekordów. Informacje te mogą być dla nas przydatne podczas debugowania kodu, ale później będą całkowicie bezużyteczne. Pisząc SET NOCOUNT ON, wyłączamy tę funkcję. W przypadku procedur składowanych zawierających kilka wyrażeń lub pętli \\ akcja ta może znacznie zwiększyć wydajność, ponieważ ilość ruchu zostanie znacznie zmniejszona.
Transact-sql
Użyj nazwy schematu z nazwą obiektu:
Myślę, że to jasne. Ta operacja informuje serwer, gdzie ma szukać obiektów, i zamiast losowego przeszukiwania jego pojemników, od razu będzie wiedział, gdzie musi iść i co zabrać. Dzięki dużej liczbie baz danych, tabel i procedur przechowywanych może znacznie zaoszczędzić nasz czas i nerwy.
Transact-sql
WYBIERZ * Z dbo.MyTable - Tutaj warto to zrobić - Zamiast WYBRAĆ * Z MyTable - I źle to zrobić - Wywołaj procedurę EXEC dbo.MyProc - Znowu dobrze - Zamiast EXEC MyProc - Źle!
Nie używaj przedrostka „sp_” w nazwie procedur składowanych:
Jeśli nazwa naszej procedury zaczyna się od „sp_”, SQL Server najpierw przeszuka swoją główną bazę danych. Faktem jest, że ten prefiks jest używany do osobistych procedur przechowywanych na serwerze wewnętrznym. Dlatego jego użycie może prowadzić do dodatkowych kosztów, a nawet niepoprawnych wyników, jeśli procedura o tej samej nazwie jak Twoja zostanie znaleziona w bazie danych.
Użyj JEŚLI ISTNIEJE (WYBIERZ 1) zamiast JEŻELI ISTNIEJE (WYBIERZ *):
Aby sprawdzić rekord w innej tabeli, używamy wyrażenia IF EXISTS. To wyrażenie zwraca wartość true, jeśli co najmniej jedna wartość zostanie zwrócona z wyrażenia wewnętrznego, nie ma znaczenia „1”, wszystkie kolumny lub tabela. Zwrócone dane w zasadzie nie są wykorzystywane w żaden sposób. Dlatego bardziej logiczne jest użycie „1” do kompresji ruchu podczas przesyłania danych, jak pokazano poniżej.
Do programowania rozszerzonych procedur przechowywanych Microsoft udostępnia interfejs API ODS (Open Data Service) zestaw makr i funkcji używanych do tworzenia aplikacji serwerowych rozszerzających funkcjonalność MS SQL Server 2000.
Rozszerzone procedury składowane to zwykłe funkcje napisane w C / C ++ przy użyciu ODS API i WIN32 API, zaprojektowane jako biblioteka dll (dll) i zaprojektowane, jak powiedziałem, w celu rozszerzenia funkcjonalności serwera SQL. ODS API zapewnia programistom bogaty zestaw funkcji pozwalających przesyłać dane do klienta otrzymane z dowolnych zewnętrznych źródeł danych (źródła danych) w postaci zwykłych zestawów rekordów. Ponadto rozszerzona procedura składowana może zwracać wartości poprzez przekazany do niej parametr (parametr OUTPUT).
Jak działają rozszerzone procedury składowane.
- Gdy aplikacja kliencka wywołuje rozszerzoną procedurę przechowywaną, żądanie jest przesyłane w formacie TDS przez bibliotekę sieciową Net-Libraries i usługę Open Data Service do jądra MS SQL SERVER.
- SQL Sever znajduje bibliotekę dll powiązaną z nazwą rozszerzonej procedury składowanej i ładuje ją do swojego kontekstu, jeśli nie została tam wcześniej załadowana, i wywołuje rozszerzoną procedurę przechowywaną, zaimplementowaną jako funkcję wewnątrz biblioteki dll.
- Rozszerzona procedura składowana wykonuje niezbędne działania na serwerze i przekazuje zestaw wyników do aplikacji klienckiej przy użyciu usługi udostępnianej przez interfejs API ODS.
Funkcje rozszerzonych procedur przechowywanych.
- Rozszerzone procedury składowane to funkcje wykonywane w przestrzeni adresowej MS SQL Server oraz w kontekście bezpieczeństwa konta, na którym działa usługa MS SQL Server;
- Po załadowaniu biblioteki dll z rozszerzonymi procedurami przechowywanymi do pamięci, pozostaje tam do momentu zatrzymania programu SQL Server lub do momentu silnego zwolnienia go przez administratora za pomocą polecenia:
DBCC nazwa_ DLL (ZA DARMO). - Rozszerzona procedura przechowywana jest uruchamiana w taki sam sposób, jak zwykła procedura przechowywana:
EXECUTE xp_extendedProcName @ param1, @ param2 OUTPUT
@ parametr wejściowy param1
@ parametr wejścia / wyjścia param2
Ponieważ rozszerzone procedury przechowywane są wykonywane w przestrzeni adresowej procesu usługi MS SQL Server, wszelkie krytyczne błędy, które pojawią się podczas ich działania, mogą uszkodzić rdzeń serwera, dlatego zaleca się dokładne przetestowanie biblioteki DLL przed zainstalowaniem jej na serwerze produkcyjnym.
Twórz zaawansowane procedury składowane.
Rozszerzona procedura składowana to funkcja, która ma następujący prototyp:
SRVRETCODE xp_extendedProcName (SRVPROC * pSrvProc);
Parametr pSrvProc wskaźnik do struktury SRVPROC, która jest uchwytem każdego konkretnego połączenia klienta. Pola tej struktury są nieudokumentowane i zawierają informacje używane przez bibliotekę ODS do zarządzania komunikacją i danymi między aplikacją serwera Open Data Services a klientem. W każdym razie nie musisz uzyskiwać dostępu do tej struktury, a tym bardziej nie możesz jej modyfikować. Ten parametr musi zostać określony podczas wywoływania dowolnej funkcji API ODS, więc w przyszłości nie będę się zastanawiał nad jej opisem.
Używanie przedrostka xp_ jest opcjonalne, ale istnieje zgoda na rozpoczęcie nazwy rozszerzonej procedury składowanej w taki sposób, aby podkreślić różnicę w stosunku do zwykłej procedury przechowywanej, której nazwy, jak wiadomo, zwykle zaczynają się od przedrostka sp_.
Należy również pamiętać, że w nazwach rozszerzonych procedur przechowywanych rozróżniana jest wielkość liter. Nie zapomnij o tym, gdy wywołasz rozszerzoną procedurę przechowywaną, w przeciwnym razie zamiast oczekiwanego wyniku pojawi się komunikat o błędzie.
Jeśli chcesz napisać kod inicjalizacji / deinicjalizacji dll, użyj do tego standardowej funkcji DllMain (). Jeśli nie masz takiej potrzeby i nie chcesz pisać DLLMain (), to kompilator skompiluje swoją wersję funkcji DLLMain (), która nic nie robi, a jedynie zwraca PRAWDA. Wszystkie funkcje wywoływane z biblioteki dll (tj. Rozszerzone procedury składowane) muszą zostać zadeklarowane jako wyeksportowane. Jeśli piszesz w MS Visual C ++, skorzystaj z dyrektywy __declspec (dllexport). Jeśli twój kompilator nie obsługuje tej dyrektywy, opisz eksportowaną funkcję w sekcji EKSPORT w pliku DEF.
Aby stworzyć projekt, potrzebujemy następujących plików:
- Plik nagłówkowy Srv.h zawiera opis funkcji i makr interfejsu API ODS;
- Opends60.lib to plik importu biblioteki Opends60.dll, który implementuje całą usługę udostępnianą przez ODS API.
Declspec (dllexport) ULONG __GetXpVersion ()
{
zwraca ODS_VERSION;
}
Gdy MS SQL Server ładuje bibliotekę DLL z rozszerzoną procedurą składowaną, najpierw wywołuje tę funkcję, aby uzyskać informacje o używanej wersji biblioteki.
Aby napisać pierwszą rozszerzoną procedurę składowaną, musisz zainstalować na swoim komputerze:
MS SQL Server 2000 dowolnej edycji (mam Personal Edition). Podczas instalacji pamiętaj, aby wybrać opcję próbki źródłowej
- MS Visual C ++ (użyłem wersji 7.0), ale wiem na pewno, że 6.0 też
Instalowanie programu SQL Server -a jest potrzebne do testowania i debugowania biblioteki DLL. Debugowanie przez sieć jest również możliwe, ale nigdy tego nie zrobiłem, więc zainstalowałem wszystko na dysku lokalnym. Edycja Interprise Edition Microsoft Visual C ++ 7.0 jest dostarczana z Kreatorem DLL Extended Stored Procedura. Zasadniczo nie robi nic poza naturalnym, ale generuje jedynie szablon dla rozszerzonej procedury składowanej. Jeśli lubisz czarodzieje, możesz z niego korzystać. Wolę robić wszystko za pomocą długopisów, dlatego nie rozważę tego przypadku.
Teraz do rzeczy:
- Uruchom Visual C ++ i stwórz nowy projekt - Win32 Dynamic Link Library.
- Dołącz plik nagłówka do projektu - #include
- Przejdź do Narzędzia \u003d\u003e Opcje i dodaj ścieżki wyszukiwania dla plików dołączanych i bibliotek. Jeśli podczas instalacji MS SQL Server nic nie zmieniłeś, określ:
C: Pliki programów Microsoft SQL Server80ToolsDevToolsInclude dla plików nagłówkowych;
- C: Program Files Microsoft SQL Server80ToolsDevToolsLib dla plików bibliotecznych.
- Podaj nazwę pliku biblioteki opends60.lib w opcjach linkera.
Na tym etapie faza przygotowawcza jest zakończona, możesz rozpocząć pisanie pierwszej rozszerzonej procedury składowanej.
Określenie problemu.
Przed przystąpieniem do programowania musisz mieć jasne pojęcie, od czego zacząć, jaki powinien być efekt końcowy i jak go osiągnąć. Oto dla nas zakres uprawnień:
Opracuj rozszerzoną procedurę przechowywaną dla MS SQL Server 2000, który otrzymuje pełną listę użytkowników zarejestrowanych w domenie i zwraca ją klientowi w postaci standardowego zestawu rekordów. Jako pierwszy parametr wejściowy funkcja otrzymuje nazwę serwera zawierającego katalog bazy danych (Active Directory), czyli nazwę kontrolera domeny. Jeśli ten parametr ma wartość NULL, musisz przekazać listę grup lokalnych do klienta. Drugi parametr zostanie wykorzystany przez rozszerzoną procedurę składowaną do zwrócenia wartości wyniku udanej / nieudanej operacji (parametr WYJŚCIE). Jeśli rozszerzona procedura przechowywana zakończyła się powodzeniem, konieczne jest przeniesienie liczby rekordów zwróconych do zestawu rekordów klienta, jeśli podczas pracy nie było możliwe uzyskanie wymaganych informacji, wartość drugiego parametru należy ustawić na -1, co jest oznaką niepowodzenia.
Warunkowy prototyp rozszerzonej procedury składowanej jest następujący:
xp_GetUserList (@NameServer varchar, @CountRec int OUTPUT);
A oto szablon rozszerzonej procedury składowanej, który musimy wypełnić treścią:
#include
#include
# zdefiniować XP_NOERROR 0
# zdefiniować XP_ERROR -1
__declspec (dllexport) SERVRETCODE xp_GetGroupList (SRVPROC * pSrvProc)
{
// Sprawdź liczbę przekazanych parametrów
// Sprawdź typ przekazanych parametrów
// Sprawdź, czy parametr 2 WYJŚCIE jest parametrem
// Sprawdź, czy parametr 2 jest wystarczająco długi, aby zapisać wartość
// Uzyskaj parametry wejściowe
// Uzyskaj listę użytkowników
// Wyślij otrzymane dane do klienta w postaci standardowego zestawu rekordów (zestaw rekordów)
// Ustaw wartość parametru OUTPUT parametru
return (XP_NOERROR);
}
Praca z parametrami wejściowymi
W tym rozdziale nie chcę rozpraszać twojej uwagi na inne rzeczy, ale chcę skupić się na pracy z parametrami przekazanymi do rozszerzonej procedury składowanej. Dlatego nieco uprościmy nasze zakresy wymagań i opracujemy tylko tę część, która działa z parametrami wejściowymi. Ale na początku niewiele teorii
Pierwszą czynnością, którą powinna wykonać nasza rozszerzona procedura składowana, jest pobranie parametrów, które zostały do \u200b\u200bniej przekazane po wywołaniu. Zgodnie z powyższym algorytmem musimy wykonać następujące czynności:
Określić liczbę przekazanych parametrów;
- Upewnij się, że przekazane parametry mają poprawny typ danych;
- Upewnij się, że określony parametr OUTPUT ma wystarczającą długość, aby zapisać w nim wartość zwróconą przez naszą rozszerzoną procedurę składowaną.
- Uzyskaj przesłane parametry;
- Ustaw wartości parametru wyjściowego w wyniku pomyślnego / nieudanego zakończenia rozszerzonej procedury składowanej.
Teraz rozważ szczegółowo każdy element:
Określanie liczby parametrów przekazanych do rozszerzonej procedury składowanej
Aby uzyskać liczbę przekazanych parametrów, musisz użyć funkcji:
int srv_rpcparams (SRV_PROC * srvproc);
Po pomyślnym zakończeniu funkcja zwraca liczbę parametrów przekazanych do rozszerzonej procedury składowanej. Jeśli rozszerzona procedura składowana została wywołana bez parametrów, srv_rpcparams zwróci -1. Parametry mogą być przekazywane według nazwy lub pozycji (bez nazwy). W każdym razie nie można mieszać tych dwóch metod. Próba jednoczesnego przekazania parametrów wejściowych do funkcji według nazwy i pozycji spowoduje błąd, a srv_rpcparams zwróci 0.
Definicja typu danych i długości przekazywanych parametrów
Aby uzyskać informacje o typie i długości przekazywanych parametrów, Microsoft zaleca użycie funkcji srv_paramifo. Ta ogólna funkcja zastępuje wywołania srv_paramtype, srv_paramlen, srv_parammaxlen, które są obecnie nieaktualne. Oto jej prototyp:
int srv_paraminfo (
SRV_PROC * srvproc,
int n
BYTE * pbType,
ULONG * pcbMaxLen,
ULONG * pcbActualLen,
BYTE * pbData,
BOOL * pfNull);
pbType ustawia numer seryjny parametru. Numer pierwszego parametru zaczyna się od 1.
pcbMaxLen wskaźnik do zmiennej, do której funkcja wprowadza maksymalną wartość długości parametru. Ta wartość jest określona przez konkretny typ danych przekazywanego parametru i użyjemy go, aby upewnić się, że parametr WYJŚCIE jest wystarczająco długi, aby zapisać przesłane dane.
pcbActualLen Wskaźnik do rzeczywistej długości parametru przekazywanego do rozszerzonej procedury składowanej po wywołaniu. Jeśli przekazany parametr ma zerową długość, a flaga pfNull jest ustawiona na FAŁSZ, wówczas (* pcbActualLen) \u003d\u003d 0.
pbData - wskaźnik do bufora, dla którego należy przydzielić pamięć przed wywołaniem srv_paraminfo. W tym buforze funkcja umieszcza parametry wejściowe otrzymane z rozszerzonej procedury składowanej. Rozmiar bufora w bajtach jest równy pcbMaxLen. Jeśli ten parametr jest ustawiony na NULL, żadne dane nie są zapisywane w buforze, ale funkcja poprawnie zwraca wartości * pbType, * pcbMaxLen, * pcbActualLen, * pfNull. Dlatego musisz wywołać srv_paraminfo dwa razy: najpierw z pbData \u003d NULL, a następnie, po przydzieleniu wymaganego rozmiaru pamięci dla bufora równego pcbActualLen, wywołaj srv_paraminfo po raz drugi, przekazując wskaźnik do przydzielonego bloku pamięci w pbData.
pfNull wskaźnik do flagi NULL. srv_paraminfo ustawia go na PRAWDA, jeśli wartość parametru wejściowego wynosi NULL.
Sprawdź, czy drugi parametr WYJŚCIE jest parametrem.
Funkcja srv_paramstatus () służy do określania statusu przekazywanego parametru:
int srv_paramstatus (
SRV_PROC * srvproc,
int n
);
n numer parametru przekazywany do rozszerzonej procedury składowanej po wywołaniu. Przypomnę: parametry są zawsze ponumerowane od 1.
Aby zwrócić wartość, srv_paramstatus używa bitu zerowego. Jeśli jest ustawiony na 1, przekazany parametr jest parametrem WYJŚCIOWYM, a jeśli wynosi 0, jest to zwykły parametr przekazywany przez wartość. Jeśli rozszerzona procedura składowana została wywołana bez parametrów, funkcja zwróci -1.
Ustawienie wartości parametru wyjściowego.
Parametr wyjściowy przekazany do pamięci rozszerzonej można przekazać za pomocą funkcji srv_paramsetoutput. Ta nowa funkcja zastępuje wywołanie funkcji srv_paramset, które jest obecnie uważane za przestarzałe, ponieważ nie obsługuje nowych typów danych wprowadzonych w interfejsie API ODS i danych o zerowej długości.
int srv_paramsetoutput (
SRV_PROC * srvproc,
int n
BYTE * pbData,
ULONG cbLen,
BOOL fNull
);
pbData wskaźnik do bufora z danymi, które zostaną wysłane do klienta w celu ustawienia wartości parametru wyjściowego.
cbLen długość bufora wysyłanych danych. Jeśli typ danych przekazywanego parametru OUTPUT definiuje dane o stałej długości i nie pozwala na przechowywanie wartości NULL (na przykład SRVBIT lub SRVINT1), funkcja ignoruje parametr cbLen. Wartość cbLen \u003d 0 wskazuje dane o zerowej długości, a parametr fNull należy ustawić na FAŁSZ.
fNull ustaw tę wartość na PRAWDA, jeśli zwracany parametr musi być ustawiony na NULL, podczas gdy wartość cbLen musi wynosić 0, w przeciwnym razie funkcja się nie powiedzie. We wszystkich innych przypadkach fNull \u003d FALSE.
Jeśli się powiedzie, funkcja zwraca SUCCEED. Jeśli zwracana wartość to FAIL, połączenie nie powiodło się. Wszystko jest proste i jasne.
Teraz wiemy wystarczająco dużo, aby napisać naszą pierwszą rozszerzoną procedurę składowaną, która zwróci wartość poprzez przekazany do niej parametr. Niech, zgodnie z tradycją, będzie to ciąg Hello world! Debugowaną wersję przykładu można pobrać tutaj.
#include
# zdefiniować XP_NOERROR 0
# zdefiniować XP_ERROR 1
# zdefiniuj MAX_SERVER_ERROR 20000
# zdefiniuj XP_HELLO_ERROR MAX_SERVER_ERROR + 1
void printError (SRV_PROC *, CHAR *);
#ifdef __cplusplus
extern „C” (
#endif
SRVRETCODE __declspec (dllexport) xp_helloworld (SRV_PROC * pSrvProc);
#ifdef __cplusplus
}
#endif
SRVRETCODE xp_helloworld (SRV_PROC * pSrvProc)
{
char szText \u003d "Hello World!";
BYTE bType;
ULONG cbMaxLen;
ULONG cbActualLen;
BOOL fNull;
/ * Określanie liczby przesłanych danych do pamięci rozszerzonej
procedura parametrów * /
if (srv_rpcparams (pSrvProc)! \u003d 1)
{
printError (pSrvProc, „Nieprawidłowa liczba parametrów!”);
return (XP_ERROR);
}
/ * Uzyskiwanie informacji o typie danych i długości przekazywanych parametrów * /
if (srv_paraminfo (pSrvProc, 1 i bType, i cbMaxLen,
& cbActualLen, NULL i fNull) \u003d\u003d FAIL)
{
printError (pSrvProc,
„Nie można uzyskać informacji o parametrach wejściowych ...”);
return (XP_ERROR);
}
/ * Sprawdź, czy przekazany parametr OUTPUT jest parametrem * /
if ((srv_paramstatus (pSrvProc, 1) i SRV_PARAMRETURN) \u003d\u003d FAIL)
{
printError (pSrvProc,
„Przekazany parametr nie jest parametrem WYJŚCIOWYM!”);
return (XP_ERROR);
}
/ * Sprawdź typ danych przekazywanego parametru * /
if (bType! \u003d SRVBIGVARCHAR && bType! \u003d SRVBIGCHAR)
{
printError (pSrvProc, „Przekazano nieprawidłowy typ parametru!”);
return (XP_ERROR);
}
/ * Upewnij się, że przekazany parametr jest wystarczająco długi, aby zapisać zwrócony ciąg * /
if (cbMaxLen< strlen(szText))
{
printError (pSrvProc,
„Przekazano parametr o niewystarczającej długości, aby zapisać n zwrócony ciąg!”);
return (XP_ERROR);
}
/ * Ustaw wartość WYJŚCIA parametru * /
if (FAIL \u003d\u003d srv_paramsetoutput (pSrvProc, 1, (BYTE *) szText, 13, FALSE))
{
printError (pSrvProc,
„Nie mogę ustawić wartości WYJŚCIA parametru ...”);
return (XP_ERROR);
}
srv_senddone (pSrvProc, (SRV_DONE_COUNT | SRV_DONE_MORE), 0, 1);
return (XP_NOERROR);
}
void printError (SRV_PROC * pSrvProc, CHAR * szErrorMsg)
{
srv_sendmsg (pSrvProc, SRV_MSG_ERROR, XP_HELLO_ERROR, SRV_INFO, 1,
NULL, 0, 0, szErrorMsg, SRV_NULLTERM);
Srv_senddone (pSrvProc, (SRV_DONE_ERROR | SRV_DONE_MORE), 0, 0);
}
Funkcje srv_sendmsg i srv_senddone pozostały niezbadane. Funkcja srv_sendmsg służy do wysyłania wiadomości do klienta. Oto jej prototyp:
int srv_sendmsg (
SRV_PROC * srvproc,
int msgtype,
DBINT msgnum,
Klasa DBTINYINT,
Stan DBTINYINT,
DBCHAR * nazwa rpc,
int rpcnamelen,
DBUSMALLINT linenum,
Komunikat DBCHAR *,
int msglen
);
numer wiadomości msgnum;
klasa - dotkliwość błędu. Komunikaty informacyjne mają wartość istotności mniejszą lub równą 10;
stan numer statusu błędu dla bieżącej wiadomości. Ten parametr zawiera informacje o kontekście błędu, który wystąpił. Dozwolone wartości mieszczą się w zakresie od 0 do 127;
rpcname nie jest obecnie używany;
rpcnamelen - obecnie nieużywany;
pościel tutaj możesz podać numer wiersza kodu źródłowego. Zgodnie z tą wartością łatwo będzie ustalić, gdzie wystąpił błąd. Jeśli nie chcesz korzystać z tej funkcji, ustaw pościel na 0;
wskaźnik wiadomości do łańcucha wysłanego do klienta;
msglen określa długość w bajtach ciągu komunikatu. Jeśli ten ciąg kończy się znakiem pustym, wówczas wartość tego parametru można ustawić na wartość SRV_NULLTERM.
Zwracane wartości:
- jeśli się powiedzie SUKCEED
- jeśli FAIL zawiedzie.
Podczas działania rozszerzona procedura przechowywana powinna regularnie informować aplikację kliencką o jej statusie, tj. wysyłać wiadomości o zakończonych działaniach. Funkcja srv_senddone jest przeznaczona do tego:
int srv_senddone (
SRV_PROC * srvproc,
Status DBUSMALLINT,
Informacje DBUSMALLINT,
Liczba DBINT
);
status status flag. Wartość tego parametru można ustawić za pomocą operatorów logicznych AND i OR, aby połączyć stałe podane w tabeli:
Flaga stanu Opis
SRV_DONE_FINAL Bieżący zestaw wyników jest ostateczny;
SRV_DONE_MORE Bieżący zestaw wyników nie jest ostateczny; spodziewaj się uczciwej części danych;
SRV_DONE_COUNT Parametr count zawiera poprawną wartość.
SRV_DONE_ERROR Służy do powiadamiania o błędach i natychmiastowego zakończenia.
w zastrzeżone, musi być ustawiony na 0.
count Liczba zestawów wyników wysłanych do klienta. Jeśli flaga stanu jest ustawiona na SRV_DONE_COUNT, liczba musi zawierać poprawną liczbę zestawów rekordów wysłanych do klienta.
Zwracane wartości:
- jeśli się powiedzie SUKCEED
- jeśli FAIL zawiedzie.
Zainstaluj zaawansowane procedury składowane na MS SQL Server 2000
1. Skopiuj bibliotekę DLL z rozszerzoną procedurą składowaną do katalogu binn na komputerze z zainstalowanym MS SQL Server. Mam następującą ścieżkę: C: Program FilesMicrosoft SQL ServerMSSQLBinn;
2. Zarejestruj rozszerzoną procedurę przechowywaną na serwerze, uruchamiając następujący skrypt:
UŻYJ Mistrza
EXECUTE SP_ADDEXTENDEDPROC xp_helloworld, xp_helloworld.dll
Przetestuj xp_helloworld, uruchamiając następujący skrypt:
DECLARE @Param varchar (33)
WYKONAJ xp_helloworld @Param WYJŚCIE
WYBIERZ @Param JAKO WYJŚCIE_Param
Wniosek
To jest pierwsza część mojego artykułu. Teraz jestem pewien, że jesteś gotowy, aby w 100% poradzić sobie z naszym zakresem uprawnień. W następującym artykule dowiesz się:
- Typy danych zdefiniowane w ODS API;
- Funkcje debugowania zaawansowanych procesów przechowywanych;
- Jak tworzyć zestawy rekordów i przenosić je do aplikacji klienckiej;
- Zbadamy funkcje interfejsu API zarządzania siecią Active Directory niezbędne do uzyskania listy użytkowników domeny;
- Stworzymy gotowy projekt (wdrożymy nasz zakres uprawnień)
Mam nadzieję - do zobaczenia wkrótce!
PS: przykładowe pliki do pobrania artykułu do studia 7.0
- Aby przestudiować operatorów opisu procedur przechowywanych i zasad przekazywania ich parametrów wejściowych i wyjściowych.
- Dowiedz się, jak tworzyć i debugować procedury składowane w MS SQL Server 2000.
- Opracuj pięć podstawowych procedur przechowywanych dla szkoleniowej bazy danych bibliotek.
- Przygotuj raport postępu drogą elektroniczną.
1. Ogólne informacje o procedurach przechowywanych
Procedura składowana Jest zestawem poleceń przechowywanych na serwerze i wykonywanych jako całość. Procedury składowane to mechanizm, dzięki któremu można tworzyć procedury działające na serwerze i kontrolowane przez jego procesy. Podobne procedury mogą być aktywowane przez aplikację wywołującą. Ponadto mogą być wyzwalane przez reguły utrzymujące integralność danych lub przez wyzwalacze.
Procedury przechowywane mogą zwracać wartości. W tej procedurze możesz porównać wartości wprowadzone przez użytkownika z informacjami wstępnie zainstalowanymi w systemie. Procedury składowane wykorzystują zaawansowane rozwiązania sprzętowe SQL Server. Są zorientowane na bazę danych i ściśle współpracują z SQL Server Optimizer. Pozwala to uzyskać wysoką wydajność podczas przetwarzania danych.
Możesz przenosić wartości do procedur przechowywanych i uzyskiwać z nich wyniki pracy, niekoniecznie związane z arkuszem. Procedura składowana może obliczyć wyniki podczas pracy.
Istnieją dwa rodzaje procedur przechowywanych: zwykły i przedłużony. Regularne procedury składowane to zestaw poleceń języka Transact-SQL, natomiast rozszerzone procedury składowane są reprezentowane jako biblioteki dynamiczne (DLL). Takie procedury, w przeciwieństwie do zwykłych, mają przedrostek xp_. Serwer ma standardowy zestaw zaawansowanych procedur, ale użytkownicy mogą pisać własne procedury w dowolnym języku programowania. Najważniejsze jest użycie interfejsu programowania SQL Server Open Data Services API. Rozszerzone procedury składowane mogą znajdować się tylko w głównej bazie danych.
Konwencjonalne procedury składowane można również podzielić na dwa typy: układowy i niestandardowe. Procedury systemowe są standardowymi procedurami służącymi do działania serwera; użytkownik - wszelkie procedury utworzone przez użytkownika.
1.1 Korzyści z procedur przechowywanych
W najbardziej ogólnym przypadku procedury składowane mają następujące zalety:
- Wysoka wydajność. Jest to wynik lokalizacji procedur przechowywanych na serwerze. Serwer z reguły jest mocniejszą maszyną, więc czas wykonania procedury na serwerze jest znacznie krótszy niż na stacji roboczej. Ponadto informacje z bazy danych i procedury przechowywanej znajdują się w tym samym systemie, dlatego przesyłanie rekordów przez sieć praktycznie nie zajmuje czasu. Procedury przechowywane mają bezpośredni dostęp do baz danych, co sprawia, że \u200b\u200bpraca z informacjami jest bardzo szybka.
- Zaletą opracowania systemu w architekturze klient-serwer. Polega na możliwości osobnego tworzenia oprogramowania klienta i serwera. Ta zaleta jest kluczem do rozwoju, dzięki czemu można znacznie skrócić czas potrzebny na ukończenie projektu. Kod działający na serwerze można opracować niezależnie od kodu po stronie klienta. Ponadto komponenty po stronie serwera mogą być współużytkowane przez komponenty po stronie klienta.
- Poziom bezpieczeństwa. Procedury przechowywane mogą działać jako narzędzie zwiększające bezpieczeństwo. Można tworzyć procedury składowane, które wykonują operacje dodawania, modyfikowania, usuwania i wyświetlania list, a tym samym uzyskują kontrolę nad każdym aspektem dostępu do informacji.
- Wzmocnienie reguł serwera do pracy z danymi. Jest to jeden z najważniejszych powodów korzystania z inteligentnego silnika bazy danych. Procedury przechowywane pozwalają na stosowanie reguł i innej logiki w celu kontroli informacji wprowadzanych do systemu.
Chociaż SQL jest zdefiniowany jako nieprocesowy, SQL Server używa słów kluczowych związanych z kontrolowaniem postępu procedur. Te słowa kluczowe służą do tworzenia procedur, które można zapisać do późniejszego wykonania. Procedur przechowywanych można używać zamiast programów utworzonych przy użyciu standardowych języków programowania (na przykład C lub Visual Basic) i wykonywania operacji w bazie danych SQL Server.
Procedury składowane są kompilowane przy pierwszym uruchomieniu i przechowywane w tabeli systemowej bieżącej bazy danych. Podczas kompilacji są one zoptymalizowane. W takim przypadku wybierany jest najlepszy sposób dostępu do informacji o tabeli. Taka optymalizacja uwzględnia faktyczne położenie danych w tabeli, dostępne indeksy, ładowanie tabeli itp.
Skompilowane procedury składowane mogą znacznie poprawić wydajność systemu. Warto jednak zauważyć, że statystyki danych od momentu utworzenia procedury do momentu jej wykonania mogą stać się nieaktualne, a indeksy mogą stać się nieefektywne. I chociaż można aktualizować statystyki i dodawać nowe, bardziej wydajne indeksy, plan wykonania procedury został już opracowany, to znaczy procedura została skompilowana, w wyniku czego sposób dostępu do danych może już nie być skuteczny. Dlatego możliwe jest ponowne skompilowanie procedur przy każdym wywołaniu.
Z drugiej strony kompilacja będzie wymagać czasu za każdym razem. Dlatego kwestia skuteczności ponownej kompilacji procedury lub jednorazowego planu jej wdrożenia jest dość delikatna i należy ją rozpatrywać osobno dla każdego konkretnego przypadku.
Procedury przechowywane mogą być wykonywane na komputerze lokalnym lub na zdalnym systemie SQL Server. Umożliwia to aktywację procesów na innych komputerach i pracę nie tylko z lokalnymi bazami danych, ale także z informacjami na kilku serwerach.
Aplikacje napisane w jednym z języków wysokiego poziomu, takich jak C lub Visual Basic .NET, mogą również wywoływać procedury składowane, co zapewnia optymalne rozwiązanie do równoważenia obciążenia między oprogramowaniem po stronie klienta a serwerem SQL.
1.2 Tworzenie przechowywanych procedur
Aby utworzyć procedurę przechowywaną, używana jest instrukcja Utwórz procedurę. Nazwa procedury składowanej może mieć do 128 znaków, w tym znaki # i ##. Składnia definicji procedury:
UTWÓRZ PROC nazwa_procedury [; liczba]
[(parametr @ data_type) [\u003d wartość domyślna]] [, ... n]
Jak
<Инструкции_SQL>
Rozważ opcje tego polecenia:
- Nazwa_procedury - nazwa procedury; musi być zgodny z zasadami dotyczącymi identyfikatorów: jego długość nie może przekraczać 128 znaków; w lokalnych procedurach tymczasowych przed nazwą używany jest znak #, a w globalnych procedurach tymczasowych - znaki ##;
- Number - opcjonalna liczba całkowita używana do grupowania kilku procedur pod jedną nazwą;
- @ typ danych parametru - lista nazw parametrów procedury ze wskazaniem odpowiedniego typu danych dla każdego; Takie parametry mogą mieć do 2100. Dozwolona jest wartość NULL. Można używać wszystkich typów danych oprócz tekstu, ntext i image. Można użyć typu danych Kursor jako parametru wyjściowego (słowo kluczowe OUTPUT lub VARYING). Parametry o typie danych Kursor mogą być tylko parametrami wyjściowymi;
- RÓŻNICOWANIE - słowo kluczowe, które określa, że \u200b\u200bzestaw wyników jest używany jako parametr wyjściowy (używany tylko dla typu Kursora);
- WYJŚCIE - wskazuje, że określony parametr może być użyty jako wyjście;
- wartość domyślna - używany, gdy parametr jest pomijany podczas wywoływania procedury; musi być stały i może zawierać znaki maski (%, _, [,], ^) i wartość NULL;
- Z RECOMPILE - słowa kluczowe wskazujące, że SQL Server nie zapisze planu procedury w pamięci podręcznej, ale utworzy go za każdym razem, gdy zostanie wykonany;
- Z SZYFROWANIEM - Słowa kluczowe wskazujące, że SQL Server szyfruje procedurę przed zapisaniem do tabeli systemowej Syscomments. Aby tekst zaszyfrowanych procedur był niemożliwy do odzyskania, po zaszyfrowaniu konieczne jest usunięcie odpowiednich krotek z tabeli systemów;
- DO REPLIKACJI - słowa kluczowe wskazujące, że ta procedura jest tworzona tylko w celu replikacji. Ta opcja nie jest kompatybilna ze słowami kluczowymi RECOMPILE;
- AS - początek definicji tekstu procedury;
- <Инструкции_SQL> - zestaw prawidłowych instrukcji SQL, ograniczony jedynie maksymalnym rozmiarem procedury składowanej - 128 Kb. Następujące instrukcje są niepoprawne: ZMIEŃ BAZY DANYCH, ZMIEŃ PROCEDURĘ, ZMIEŃ TABELĘ, UTWÓRZ DOMYŚLNE, UTWÓRZ PROCEDURĘ, ZMIEŃ TRIGGER, ZMIEŃ WIDOK, UTWÓRZ BAZA DANYCH, UTWÓRZ REGUŁĘ, UTWÓRZ SCHEMAT, UTWÓRZ WYZWOLENIE, UTWÓRZ WIDOK, DISPEKT DISK USUŃ DOMYŚLNIE, PROCEDURA UPADKU, ZASADA UPADKU, WYZWALACZ DROP, WIDOK UPADKU, BAZA DANYCH RESOTRE, REJESTRACJA DZIENNIKA, REKONFIGURACJA, AKTUALIZACJA STATYSTYK.
Rozważ przykład procedury składowanej. Opracujemy procedurę składowaną, która liczy i wyświetla liczbę książek, które są obecnie w bibliotece:
Procedura CREATE Count_Ex1
- procedura zliczania liczby egzemplarzy książek,
- obecnie w bibliotece,
- i nie w rękach czytelników
Jak
- ustaw tymczasową zmienną lokalną
Zadeklaruj @N int
Wybierz @N \u003d count (*) z Exemplar Where Yes_No \u003d „1”
Wybierz @N
GO
Ponieważ procedura składowana jest pełnoprawnym składnikiem bazy danych, jak już zrozumiałeś, możesz utworzyć nową procedurę tylko dla bieżącej bazy danych. Podczas uruchamiania w programie SQL Server Query Analyzer bieżąca baza danych jest instalowana za pomocą instrukcji Use, a następnie nazwy bazy danych, w której ma zostać utworzona procedura składowana. Możesz także wybrać bieżącą bazę danych, korzystając z listy rozwijanej.
Po utworzeniu procedury składowanej w systemie SQL Server kompiluje ją i sprawdza uruchomione procedury. Jeśli pojawią się jakiekolwiek problemy, procedura zostaje odrzucona. Błędy należy naprawić przed ponownym nadaniem.
SQL Server 2000 używa opóźnionego rozpoznawania nazw, więc jeśli procedura przechowywana zawiera wywołanie innej, jeszcze nie zaimplementowanej procedury, zostanie wyświetlone ostrzeżenie, ale wywołanie nieistniejącej procedury zostanie zapisane.
Jeśli opuścisz system z nieokreśloną procedurą składowaną, użytkownik otrzyma komunikat o błędzie podczas próby jej wykonania.
Możesz także utworzyć procedurę składowaną za pomocą SQL Server Enterprise Manager:
Aby sprawdzić funkcjonalność utworzonej procedury składowanej, należy przejść do Query Analyzer i rozpocząć procedurę wykonania przez operatora EXEC<имя процедуры> . Wyniki uruchomienia stworzonej przez nas procedury przedstawiono na ryc. 4

Ryc. 4. Uruchom procedurę przechowywaną w Query Analyzer

Ryc. 5. Wynik procedury bez operatora ekranu
1.3 Parametry procedury składowanej
Procedury przechowywane są bardzo potężnym narzędziem, ale maksymalną wydajność można osiągnąć tylko poprzez ich dynamikę. Deweloper powinien mieć możliwość przekazywania wartości do procedury składowanej, z którą będzie działał, to znaczy parametrów. Poniżej przedstawiono podstawowe wytyczne dotyczące używania parametrów w procedurach przechowywanych.
- Możesz zdefiniować jeden lub więcej parametrów dla procedury.
- Parametry są używane jako nazwane miejsca przechowywania danych, podobnie jak zmienne w językach programowania, takich jak C, Visual Basic .NET.
- Nazwa parametru jest koniecznie poprzedzona symbolem @.
- Nazwy parametrów są lokalne w procedurze, w której zostały zdefiniowane.
- Parametry służą do przesyłania informacji do procedury podczas jej wykonywania. Utkną w wierszu polecenia po nazwie procedury.
- Jeśli procedura ma kilka parametrów, są one rozdzielane przecinkami.
- Aby określić typ informacji przesyłanych jako parametr, wykorzystywane są typy danych systemu lub użytkownika.
Poniżej znajduje się definicja procedury, która ma jeden parametr wejściowy. Zmienimy poprzednie zadanie i rozważymy nie wszystkie kopie książek, ale tylko kopie określonej książki. Nasze książki są jednoznacznie oznaczone unikalnym numerem ISBN, więc przekażemy ten parametr do procedury. W takim przypadku tekst procedury przechowywanej zmieni się i będzie wyglądał następująco:
Procedura tworzenia Count_Ex (@ISBN varchar (14))
Jak
Zadeklaruj @N int
Wybierz @N
GO
Rozpoczynając tę \u200b\u200bprocedurę do wykonania, musimy przekazać jej wartość parametru wejściowego (ryc. 6).

Ryc. 6. Rozpoczęcie procedury od przekazania parametru
Aby utworzyć kilka wersji tej samej procedury o tej samej nazwie, umieść średnik i liczbę całkowitą po nazwie głównej. Jak to zrobić, pokazano w poniższym przykładzie, w którym opisano utworzenie dwóch procedur o tej samej nazwie, ale o różnych numerach wersji (1 i 2). Numer służy do sterowania działającą wersją tej procedury. Jeśli nie podano numeru wersji, wykonywana jest pierwsza wersja procedury. Ta opcja nie jest pokazana w poprzednim przykładzie, ale mimo to jest dostępna dla Twojej aplikacji.
Aby wydrukować komunikat identyfikujący wersję, obie procedury używają instrukcji print. Pierwsza wersja uwzględnia liczbę darmowych kopii, a druga - liczbę dostępnych kopii tej książki.
Tekst obu wersji procedur podano poniżej:
Procedura CREATE Count_Ex_all; 1
(@ISBN varchar (14))
- procedura liczenia bezpłatnych egzemplarzy danej książki
Jak
Zadeklaruj @N int
Wybierz @N \u003d liczba (*) z Przykładu, gdzie ISBN \u003d @ISBN i Tak_No \u003d „1”
Wybierz @N
--
GO
--
Procedura CREATE Count_Ex_all; 2)
(@ISBN varchar (14))
- procedura liczenia bezpłatnych egzemplarzy danej książki
Jak
Deklaracja @ N1 int
Wybierz @ N1 \u003d liczba (*) z przykładowego miejsca gdzie ISBN \u003d @ISBN i Tak_No \u003d „0”
Wybierz @ N1
GO
Wyniki procedury z różnymi wersjami pokazano na ryc. 7

Ryc. 7. Wyniki uruchomienia różnych wersji tej samej procedury składowanej
Pisząc kilka wersji, należy pamiętać o następujących ograniczeniach: ponieważ wszystkie wersje procedury są kompilowane razem, wszystkie zmienne lokalne są uważane za wspólne. Dlatego jeśli jest to wymagane przez algorytm przetwarzania, konieczne jest użycie różnych nazw zmiennych wewnętrznych, co zrobiliśmy, nazywając zmienną @N nazwą @ N1 w drugiej procedurze.
Procedury, które napisaliśmy, nie zwracają ani jednego parametru, po prostu wyświetlają wynikową liczbę. Jednak najczęściej musimy uzyskać parametr do dalszego przetwarzania. Istnieje kilka sposobów zwracania parametrów z procedury składowanej. Najprostszym jest użycie operatora powrotu RETURN. Ten operator zwróci jedną wartość liczbową. Musimy jednak podać nazwę zmiennej lub wyrażenie przypisane do zwróconego parametru. Poniżej przedstawiono wartości zwrócone przez instrukcję RETURN zarezerwowaną przez system:
| Kod | Wartość |
| 0 | Wszystko w porządku |
| -1 | Nie znaleziono obiektu |
| –2 | Błąd typu danych |
| –3 | Proces ten stał się ofiarą „impasu” |
| –4 | Błąd dostępu |
| –5 | Błąd składniowy |
| –6 | Jakiś błąd |
| –7 | Błąd zasobów (brak miejsca) |
| –8 | Wystąpił możliwy do naprawienia błąd wewnętrzny |
| –9 | Limit systemu został osiągnięty. |
| –10 | Śmiertelne naruszenie wewnętrznej integralności |
| –11 | To samo |
| –12 | Zniszczenie tabeli lub indeksu |
| –13 | Zniszczenie bazy danych |
| –14 | Błąd sprzętowy |
Dlatego, aby nie zaprzeczyć systemowi, za pomocą tego parametru możemy zwracać tylko dodatnie liczby całkowite.
Na przykład możemy zmienić tekst wcześniej zapisanej procedury składowanej Count_ex w następujący sposób:
Procedura tworzenia Count_Ex2 (@ISBN varchar (14))
Jak
Zadeklaruj @N int
Wybierz @N \u003d count (*) z Exemplar
Gdzie ISBN \u003d @ISBN i YES_NO \u003d „1”
- zwraca wartość zmiennej @N,
- jeśli wartość zmiennej nie jest zdefiniowana, zwróć 0
Zwrot Coalesce (@N, 0)
GO
Teraz możemy uzyskać wartość zmiennej @N i wykorzystać ją do dalszego przetwarzania. W takim przypadku wartość zwracana jest przypisywana do samej procedury przechowywanej, a do jej analizy można użyć następującego formatu operatora wywołania procedury przechowywanej:
Exec<переменная> = <имя_процедуры> <значение_входных_параметров>
Przykład wywołania naszej procedury pokazano na ryc. 8

Ryc. 8. Przekazywanie wartości zwracanej procedury składowanej do zmiennej lokalnej
Parametry wejściowe do procedur przechowywanych mogą korzystać z wartości domyślnej. Ta wartość zostanie użyta, jeśli wartość parametru nie została określona podczas wywoływania procedury.
Wartość domyślna jest określana za pomocą znaku równości po opisie parametru wejściowego i jego typu. Rozważ procedurę składowaną, która liczy liczbę kopii książek w danym roku wydania. Domyślny rok wydania to 2006.
UTWÓRZ PROCEDURĘ ex_books_now (@year int \u003d 2006)
- zliczanie liczby egzemplarzy książek z danego roku wydania
Jak
Zadeklaruj @N_books int
wybierz @ N_books \u003d count (*) z książek, przykład
gdzie Books.ISBN \u003d exemplar.ISBN i YEARIZD \u003d @ rok
zwrot coalesce (@N_books, 0)
GO
Na ryc. Rysunek 9 pokazuje przykład wywołania tej procedury z parametrem wejściowym i bez niego.

Ryc. 9. Wywołanie procedury składowanej z parametrem i bez parametru
Wszystkie powyższe przykłady użycia parametrów w procedurach przechowywanych zawierały tylko parametry wejściowe. Jednak parametry mogą być wyprowadzane. Oznacza to, że wartość parametru po zakończeniu procedury zostanie przekazana osobie, która wywołała tę procedurę (do innej procedury, wyzwalacza, pakietu poleceń itp.). Oczywiście, aby uzyskać parametr wyjściowy, podczas wywoływania należy podać nie stałą, ale zmienną jako parametr rzeczywisty.
Zauważ, że zdefiniowanie parametru jako wyniku w procedurze nie zobowiązuje cię do użycia go jako takiego. Oznacza to, że jeśli podasz stałą jako parametr rzeczywisty, wówczas nie wystąpi błąd i zostanie on użyty jako zwykły parametr wejściowy.
Instrukcja OUTPUT służy do wskazania, że \u200b\u200bparametr jest generowany. To słowo kluczowe jest zapisane po opisie parametru. Opisując parametry procedur przechowywanych, pożądane jest ustawienie wartości parametrów wyjściowych po danych wejściowych.
Rozważ przykład wykorzystujący parametry wyjściowe. Napiszemy procedurę składowaną, która dla danej książki oblicza całkowitą liczbę kopii w bibliotece i liczbę bezpłatnych kopii. Nie możemy tutaj użyć operatora powrotu RETURN, ponieważ zwraca on tylko jedną wartość, dlatego musimy tutaj zdefiniować parametry wyjściowe. Tekst procedury składowanej może wyglądać następująco:
UTWÓRZ Procedura Count_books_all
(@ISBN varchar (14), @ all int output, @free int output)
- procedura obliczania całkowitej liczby egzemplarzy danej książki
- oraz liczba bezpłatnych kopii
Jak
- obliczenie całkowitej liczby kopii
Wybierz @ all \u003d count (*) z Exemplar Where ISBN \u003d @ISBN
Wybierz @free \u003d count (*) z Exemplar Where ISBN \u003d @ISBN i Yes_No \u003d „1”
GO
Przykład tej procedury pokazano na ryc. 10

Ryc. 10. Testowanie procedury składowanej z parametrami wyjściowymi
Jak wspomniano wcześniej, aby uzyskać wartości parametrów wyjściowych do analizy, musimy ustawić je jako zmienne, a te zmienne muszą zostać opisane przez operatora Deklaracja. Ostatnia instrukcja wyjściowa pozwoliła nam po prostu wyświetlić uzyskane wartości.
Parametry procedury mogą być nawet zmiennymi typu Kursor. W tym celu zmienną należy opisać jako specjalny typ danych VARYING, bez odniesienia do standardowych typów danych systemowych. Ponadto należy zaznaczyć, że jest to zmienna typu Cursor.
Napiszemy najprostszą procedurę, która wyświetla listę książek w naszej bibliotece. Co więcej, jeśli nie ma więcej niż trzy książki, wówczas wyświetlamy ich nazwy w ramach samej procedury, a jeśli lista książek przekracza określoną liczbę, wówczas przesyłamy je w postaci kursora do programu lub modułu wywołującego.
Tekst procedury jest następujący:
UTWÓRZ PROCEDURĘ GET3TITLES
(@MYCURSOR CURSOR RÓŻNE WYJŚCIE)
- procedura drukowania tytułów książek kursorem
Jak
- zdefiniuj zmienną lokalną typu Kursor w procedurze
SET @MYCURSOR \u003d CURSOR
WYBIERZ TYTUŁ WYRÓŻNIAJĄCY
Z KSIĄŻEK
- otwórz kursor
OTWARTY @MYCURSOR
- opisujemy wewnętrzne zmienne lokalne
ZADEKLARUJ @ TYTUŁ VARCHAR (80), @CNT INT
--- ustaw początkowy stan licznika książek
SET @CNT \u003d 0
- przejdź do pierwszego wiersza kursora
- gdy są linie kursora,
- to znaczy, podczas gdy przejście do nowej linii jest prawidłowe
PODCZAS (@@ FETCH_STATUS \u003d 0) ORAZ (@CNT<= 2) BEGIN
PRINT @TITLE
POBIERZ NASTĘPNIE @MYCURSOR DO @TITLE
- zmień stan licznika książek
SET @CNT \u003d @CNT + 1
Koniec
JEŚLI @CNT \u003d 0 WYDRUKUJ „BRAK ODPOWIEDNICH KSIĄŻEK”
GO
Przykład wywołania tej procedury składowanej pokazano na ryc. 11

W procedurze wywoływania kursor musi być opisany jako zmienna lokalna. Następnie wywołaliśmy naszą procedurę i przekazaliśmy jej nazwę lokalnej zmiennej typu Cursor. Procedura zaczęła działać i wyświetliła pierwsze trzy nazwiska na ekranie, a następnie przeniosła kontrolę do procedury wywoływania i kontynuowała przetwarzanie kursora. Aby to zrobić, zorganizowała cykl typu Na zmiennej globalnej @@ FETCH_STATUS, która śledzi stan kursora, a następnie w cyklu wyświetlała wszystkie pozostałe linie kursora.
W oknie wyników widzimy zwiększony odstęp między pierwszymi trzema liniami i kolejnymi nazwami. Ten przedział pokazuje, że sterowanie jest przekazywane do programu zewnętrznego.
Zauważ, że zmienna @TITLE, lokalna dla procedury, zostanie zniszczona po jej zakończeniu, dlatego jest zadeklarowana ponownie w bloku wywołującym procedurę. Tworzenie i otwieranie kursora w tym przykładzie odbywa się w procedurze, a zamykanie, niszczenie i dodatkowe przetwarzanie odbywa się w bloku poleceń, w którym wywoływana jest procedura.
Najprościej jest zobaczyć tekst procedury, zmienić lub usunąć go za pomocą interfejsu graficznego Enterprise Manager. Ale można to zrobić za pomocą specjalnych procedur przechowywanych w systemie Transact-SQL. W Transact-SQL definicja procedury jest wyświetlana przy użyciu procedury systemowej sp_helptext, a procedura systemowa sp_help umożliwia wyświetlanie informacji sterujących o procedurze. Procedury systemowe sp_helptext i sp_help są również używane do przeglądania obiektów bazy danych, takich jak tabele, reguły i ustawienia domyślne.
Informacje o wszystkich wersjach jednej procedury, niezależnie od numeru, są wyświetlane natychmiast. Usuwanie różnych wersji tej samej procedury składowanej również występuje w tym samym czasie. Poniższy przykład pokazuje, jak wyświetlane są definicje wersji 1 i 2 procedury Count_Ex_all, gdy jej nazwa jest określona jako parametr procedury systemowej sp_helptext (ryc. 12).

Ryc. 12. Przeglądanie tekstu procedury składowanej za pomocą systemowej procedury składowanej
Procedura systemowa SP_HELP wyświetla charakterystykę i parametry utworzonej procedury w następującej formie:
|
Data utworzenia | |||||
|
2006-12-06 23:15:01.217 | |||||
|
Skala | Zestawienie param_order | ||||
|
Zero | 1 | Cyrillic_General_CI_AS | |||
|
0 | 2 | Zero | |||
|
0 | 3 | Zero | |||
Spróbuj samodzielnie odszyfrować te parametry. O czym oni mówią?
1.4 Kompilowanie procedury składowanej
Zaletą używania procedur przechowywanych do wykonywania zestawu instrukcji Transact-SQL jest to, że kompilują się przy pierwszym uruchomieniu. Podczas kompilacji instrukcje Transact-SQL są konwertowane z oryginalnej reprezentacji znaków na postać wykonywalną. Wszelkie obiekty dostępne w procedurze są również konwertowane na alternatywną reprezentację. Na przykład nazwy tabel są konwertowane na identyfikatory obiektów, a nazwy kolumn na identyfikatory kolumn.
Plan wykonania jest tworzony w taki sam sposób, jak w przypadku wykonywania pojedynczej instrukcji Transact-SQL. Ten plan zawiera na przykład indeksy używane do odczytywania wierszy z tabel, do których ma dostęp procedura. Plan wykonania procedury jest przechowywany w pamięci podręcznej i jest używany przy każdym wywołaniu.
Uwaga: Rozmiar pamięci podręcznej procedur można określić tak, aby zawierał większość lub wszystkie procedury dostępne do wykonania. Oszczędza to czas potrzebny na zregenerowanie planu leczenia.
1.5 Automatyczna rekompilacja
Zazwyczaj plan wykonania znajduje się w pamięci podręcznej procedur. Umożliwia to zwiększenie wydajności podczas jej wykonywania. Jednak w niektórych okolicznościach procedura jest ponownie kompilowana automatycznie.
- Procedura jest zawsze rekompilowana po uruchomieniu programu SQL Server. Zwykle dzieje się to po ponownym uruchomieniu systemu operacyjnego i podczas pierwszego wykonania procedury po utworzeniu.
- Plan wykonania procedury jest zawsze automatycznie rekompilowany, jeśli indeks tabeli, do której odwołuje się procedura, zostanie usunięty. Ponieważ bieżący plan odwołuje się do indeksu tabeli, który jeszcze nie istnieje, należy utworzyć nowy plan wykonania. Żądania dotyczące procedury zostaną wykonane tylko wtedy, gdy zostaną zaktualizowane.
- Kompilacja planu wykonania ma również miejsce, jeśli inny użytkownik aktualnie pracuje z tym planem pamięci podręcznej. Dla drugiego użytkownika tworzona jest indywidualna kopia planu wykonania. Gdyby pierwsza kopia planu nie została pobrana, nie byłoby konieczne utworzenie drugiej kopii. Gdy użytkownik zakończy procedurę, plan wykonania jest dostępny w pamięci podręcznej dla innego użytkownika z odpowiednim uprawnieniem dostępu.
- Procedura zostanie ponownie skompilowana automatycznie, jeśli zostanie usunięta i ponownie utworzona. Ponieważ nowa procedura może różnić się od starej wersji, wszystkie kopie planu wykonania w pamięci podręcznej są usuwane, a plan jest kompilowany ponownie.
SQL Server ma na celu optymalizację przechowywanych procedur poprzez buforowanie najczęściej używanych procedur. Dlatego zamiast nowego planu można użyć starego planu wykonania załadowanego do pamięci podręcznej. Aby zapobiec temu problemowi, musisz usunąć i ponownie utworzyć procedurę przechowywaną lub zatrzymać i ponownie aktywować program SQL Server. Spowoduje to wyczyszczenie pamięci podręcznej procedur i wyeliminuje możliwość pracy ze starym planem wykonania.
Możesz także utworzyć procedurę za pomocą opcji Z RECOMPILE. W takim przypadku zostanie on ponownie skompilowany przy każdym wykonaniu. Opcji WITH RECOMPILE należy używać w przypadkach, gdy procedura uzyskuje dostęp do bardzo dynamicznych tabel, których wiersze są często dodawane, usuwane lub aktualizowane, ponieważ prowadzi to do znacznych zmian w indeksach zdefiniowanych dla tabel.
Jeśli procedura nie zostanie ponownie skompilowana automatycznie, można ją wymusić. Na przykład, jeśli statystyki użyte do ustalenia, czy indeks może być użyty w tym zapytaniu, zostaną zaktualizowane lub jeśli zostanie utworzony nowy indeks, należy wykonać wymuszoną rekompilację. Aby wymusić rekompilację, instrukcja EXECUTE używa klauzuli WITH RECOMPILE:
WYKONAJ nazwę procedury;
Jak
<инструкции Transact-SQL>
Z RECOMPILE
Jeśli procedura działa z parametrami kontrolującymi kolejność jej wykonywania, użyj opcji Z RECOMPILE. Jeśli parametry procedury przechowywanej mogą określić najlepszy sposób jej wykonania, zaleca się utworzenie planu wykonania w trakcie pracy, a nie tworzenie go przy pierwszym wywołaniu procedury w celu użycia we wszystkich kolejnych wywołaniach.
Uwaga: Czasami trudno jest ustalić, czy użyć opcji Z RECOMPILE podczas tworzenia procedury, czy nie. W razie wątpliwości lepiej nie korzystać z tej opcji, ponieważ ponowna kompilacja procedury przy każdym wykonaniu spowoduje utratę bardzo cennego czasu procesora. Jeśli w przyszłości będziesz musiał ponownie skompilować podczas wykonywania procedury składowanej, możesz to zrobić, dodając klauzulę WITH RECOMPILE do instrukcji EXECUTE.
Nie można użyć opcji Z RECOMPILE w instrukcji CREATE PROCEDURE zawierającej opcję FOR REPLICATION. Ta opcja służy do utworzenia procedury, która będzie uruchamiana podczas procesu replikacji.
1.6 Zagnieżdżanie procedur przechowywanych
W procedurach przechowywanych można wywoływać inne procedury przechowywane, jednak istnieje ograniczenie poziomu zagnieżdżenia. Maksymalny poziom zagnieżdżenia wynosi 32. Bieżący poziom zagnieżdżenia można określić za pomocą zmiennej globalnej @@ NESTLEVEL.
2. Funkcje zdefiniowane przez użytkownika (UDF)
W MS SQL SERVER 2000 istnieje wiele predefiniowanych funkcji, które pozwalają na wykonywanie różnych działań. Jednak zawsze może być konieczne użycie określonych funkcji. W tym celu, począwszy od wersji 8.0 (2000), stało się możliwe opisywanie funkcji zdefiniowanych przez użytkownika (User Defined Functions, UDF) i przechowywanie ich jako pełnoprawnego obiektu bazy danych wraz z procedurami przechowywanymi, widokami itp.
Przydatność funkcji zdefiniowanych przez użytkownika jest oczywista. W przeciwieństwie do procedur przechowywanych, funkcje można osadzić bezpośrednio w instrukcji SELECT i używać ich zarówno do uzyskania określonych wartości (w sekcji SELECT), jak i jako źródła danych (w sekcji FROM).
Podczas korzystania z UDF jako źródeł danych ich przewaga nad reprezentacjami polega na tym, że UDF, w przeciwieństwie do reprezentacji, może mieć parametry wejściowe, których można użyć, aby wpłynąć na wynik funkcji.
Funkcje zdefiniowane przez użytkownika mogą być trzech typów: funkcje skalarne, funkcje wbudowane i funkcje wielu operatorów, które zwracają wynik tabeli. Rozważmy wszystkie te typy funkcji bardziej szczegółowo.
2.1 Funkcje skalarne
Funkcje skalarne zwracają pojedynczy wynik skalarny. Ten wynik może być dowolnego typu opisanego powyżej, z wyjątkiem typów tekst, ntext, image i znacznik czasu. To najprostszy rodzaj funkcji. Jego składnia jest następująca:
ZWRACA skalarny typ danych
ROZPOCZNIJ
body_funkcyjne
RETURN wyrażenie skalarne
Koniec
- Parametr SZYFROWANIA został już opisany w rozdziale dotyczącym procedur przechowywanych;
- SCHEMABINDING - Wiąże funkcję ze schematem. Oznacza to, że usunięcie tabel lub widoków, na podstawie których zbudowana jest funkcja, nie będzie możliwe bez usunięcia lub zmiany samej funkcji. Nie można również zmienić struktury tych tabel, jeśli funkcja używa części zmiennej. Tak więc ta opcja pozwala wykluczyć sytuacje, w których funkcja korzysta z niektórych tabel lub widoków, a ktoś, kto o tym nie wie, usunął je lub zmienił;
- ZWRACA skalarny typ danych - opisuje rodzaj danych zwracanych przez funkcję;
- wyrażenie skalarne - wyrażenie, które bezpośrednio zwraca wynik funkcji. Musi być tego samego typu, jak opisany po ZWROTACH;
- function_body to zestaw instrukcji języka Transact-SQL.
Rozważmy przykłady użycia funkcji skalarnych.
Utwórz funkcję, która wybierze najmniejszą z dwóch liczb całkowitych podawanych do wejścia jako parametry.
Niech funkcja będzie wyglądać następująco:
UTWÓRZ FUNKCJĘ min_num (@a INT, @b INT)
ZWRACA INT
ROZPOCZNIJ
DECLARE @c INT
IF @a< @b SET @c = @a
ELSE SET @c \u003d @b
Zwróć @c
Koniec
Wykonajmy tę funkcję:
WYBIERZ dbo.min_num (4, 7)
W rezultacie otrzymujemy wartość 4.
Możesz użyć tej funkcji, aby znaleźć najmniejszą spośród wartości kolumny tabeli:
WYBIERZ min_lvl, max_lvl, min_num (min_lvl, max_lvl)
OD Jobs
Stwórzmy funkcję, która otrzyma jako parametr parametr typu datetime i zwróci datę i godzinę odpowiadającą początkowi określonego dnia. Na przykład, jeśli parametr wejściowy to 09/20/03 13:31, wynikiem będzie 09/20/03 00:00.
UTWÓRZ FUNKCJĘ dbo.daybegin (@dat DATETIME)
ZWRACA smalldatetime AS
ROZPOCZNIJ
KONWERSJA ZWROTU (datetime, FLOOR (konwersja (FLOAT, @dat)))
Koniec
Tutaj funkcja CONVERT dokonuje konwersji typu. Po pierwsze, typ daty i godziny jest rzutowany na typ FLOAT. Przy takim zmniejszeniu część całkowita jest liczbą dni liczoną od 1 stycznia 1900 roku, a część ułamkowa to czas. Następnie następuje zaokrąglenie do mniejszej liczby całkowitej za pomocą funkcji PODŁOGA i rzutowanie na typ daty i godziny.
Sprawdź działanie funkcji:
WYBIERZ dbo.daybegin (GETDATE ())
Tutaj GETDATE () to funkcja, która zwraca bieżącą datę i godzinę.
Poprzednie funkcje wykorzystywały tylko parametry wejściowe w obliczeniach. Możesz jednak użyć danych przechowywanych w bazie danych.
Utwórzmy funkcję, która przyjmie dwie daty jako parametry: początek i koniec przedziału czasowego - i obliczyć całkowite przychody ze sprzedaży dla tego przedziału. Data sprzedaży i ilość zostaną pobrane z tabeli Sprzedaż, a ceny sprzedanych publikacji zostaną pobrane z tabeli Tytuły.
UTWÓRZ FUNKCJĘ dbo.SumSales (@datebegin DATETIME, @dateend DATETIME)
ZWRACA Pieniądze
Jak
ROZPOCZNIJ
ZADEKLARUJ @ Sumy pieniędzy
WYBIERZ @Suma \u003d suma (t. cena * s.qty)
RETURN @Sum
Koniec
2.2 Funkcje wbudowane
Ten typ funkcji zwraca w wyniku nie wartość skalarną, ale tabelę, a raczej zestaw danych. Może to być bardzo wygodne w przypadkach, w których ten sam typ podzapytania jest często wykonywany w różnych procedurach, wyzwalaczach itp. Następnie zamiast pisać wszędzie to zapytanie, możesz utworzyć funkcję i użyć jej później.
Funkcje tego typu są jeszcze bardziej przydatne w przypadkach, w których wymagana jest zależność zwracanej tabeli od parametrów wejściowych. Jak wiadomo, widoki nie mogą mieć parametrów, więc tylko funkcje wbudowane mogą rozwiązać ten problem.
Cechą funkcji wbudowanych jest to, że mogą one zawierać tylko jedno żądanie w swoim ciele. Zatem funkcje tego typu są bardzo podobne do reprezentacji, ale mogą dodatkowo mieć parametry wejściowe. Składnia funkcji wbudowanej:
CREATE FUNCTION [właściciel.] Nazwa_funkcji
([(@ nazwa_parametru skalar_ typ_ danych [\u003d wartość domyślna]) [, ... n]])
TABELA ZWROTÓW
POWRÓT [(<запрос>)]
Definicja funkcji wskazuje, że zwróci tabelę;<запрос> - jest to zapytanie, którego wynikiem wykonania będzie wynik funkcji.
Napiszemy funkcję podobną do funkcji skalarnej z ostatniego przykładu, ale zwracamy nie tylko wynik sumowania, ale także wiersze sprzedaży, w tym datę sprzedaży, nazwę książki, cenę, liczbę sztuk i kwotę sprzedaży. Należy wybrać tylko sprzedaż mieszczącą się w danym okresie. Szyfrujemy tekst funkcji, aby inni użytkownicy mogli z niej korzystać, ale nie mogli jej odczytać i poprawić:
UTWÓRZ FUNKCJĘ Sales_Period (@datebegin DATETIME, @dateend DATETIME)
TABELA ZWROTÓW
Z SZYFROWANIEM
Jak
POWRÓT (
WYBIERZ t.title, t.price, s.qty, ord_date, t.price * s.qty as stoim
Z tytułów t DOŁĄCZ Sprzedaż s ON t.title_Id \u003d s.Title_ID
GDZIE ord_date MIĘDZY @datebegin i @dateend
)
Teraz wywołaj tę funkcję. Jak już wspomniano, można go wywołać tylko w sekcji FROM instrukcji SELECT:
WYBIERZ * Z Okres_sprzedaży („01.09.94”, „13.09.94”)
2.3 Funkcje wielu operatorów zwracające wynik tabeli
Pierwszy rozważany typ funkcji pozwolił nam na użycie jak największej liczby instrukcji w języku Transact-SQL, ale zwrócił tylko wynik skalarny. Drugi typ funkcji może zwracać tabele, ale jego treść reprezentuje tylko jedno zapytanie. Funkcje wielu operatorów, które zwracają wynik tabeli, pozwalają łączyć właściwości dwóch pierwszych funkcji, tzn. Mogą zawierać wiele instrukcji Transact-SQL w treści i zwracać tabelę jako wynik. Składnia funkcji multioperatora:
CREATE FUNCTION [właściciel.] Nazwa_funkcji
([(@ nazwa_parametru skalar_ typ_ danych [\u003d wartość domyślna]) [, ... n]])
ZWRACA @ TABELA nazwa_zmiennej_wyniku
<описание_таблицы>
ROZPOCZNIJ
<тело_функции>
Powrót
Koniec
- Tabela<описание_таблицы> - opisuje strukturę zwracanej tabeli;
- <описание_таблицы> - zawiera listę kolumn i ograniczeń.
Rozważmy teraz przykład, który można wykonać tylko przy użyciu funkcji tego typu.
Niech będzie drzewo katalogów i leżące w nich pliki. Niech cała ta struktura zostanie opisana w bazie danych w formie tabel (ryc. 13). W rzeczywistości mamy tutaj hierarchiczną strukturę katalogów, więc schemat pokazuje zależność tabeli Folders od siebie.

Ryc. 13. Struktura bazy danych opisująca hierarchię plików i katalogów
Teraz piszemy funkcję, która pobierze identyfikator katalogu na wejściu i wyświetli wszystkie pliki, które są w nim przechowywane i we wszystkich katalogach w dół hierarchii. Na przykład, jeśli katalogi instytutów utworzyły katalogi Wydział 1, Wydział 2 itd., Zawierają katalogi wydziałów, a każdy katalog zawiera pliki, a następnie określając identyfikator Instytutu jako parametr naszej funkcji, listę wszystkich plików dla wszystkich te katalogi. Dla każdego pliku należy wyświetlić nazwę, rozmiar i datę utworzenia.
Nie można rozwiązać problemu za pomocą funkcji wbudowanej, ponieważ SQL nie jest przeznaczony do wykonywania zapytań hierarchicznych, więc nie ma potrzeby wykonywania tylko jednego zapytania SQL. Nie można również zastosować funkcji skalarnej, ponieważ wynikiem musi być tabela. Tutaj funkcja multioperatora powróci na ratunek, zwracając tabelę:
UTWÓRZ FUNKCJĘ dbo.GetFiles (@Folder_ID int)
ZWROTY @files TABELA (Nazwa VARCHAR (100), Data_ Utwórz DATETIME, FileSize INT) AS
ROZPOCZNIJ
DECLARE @tmp TABLE (Folder_Id int)
DECLARE @Cnt INT
INSERT INTO @tmp wartości (@Folder_ID)
SET @Cnt \u003d 1
WHILE @Cnt<> 0 POCZĄTEK
INSERT INTO @tmp WYBIERZ Folder_Id
Z folderów f DOŁĄCZ @ tmp t ON f.parent \u003d t.Folder_ID
GDZIE NIE JEST (NIE WYBIERZ ID_folderu @tmp)
ZESTAW @Cnt \u003d @@ ROWCOUNT
Koniec
INSERT INTO @Files (Name, Date_Create, FileSize)
WYBIERZ F.Name, F.Date_Create, F.FileSize
Z plików f DOŁĄCZ foldery Fl na f.Folder_id \u003d Fl.id
DOŁĄCZ @tmp t na Fl.id \u003d t.Folder_Id
Powrót
Koniec
Tutaj, w pętli, wszystkie podkatalogi na wszystkich poziomach zagnieżdżania są dodawane do zmiennej @tmp, dopóki nie zostaną już żadne podkatalogi. Następnie wszystkie niezbędne atrybuty plików znajdujących się w katalogach wymienionych w zmiennej @tmp są zapisywane w zmiennej wynikowej @Files.
Zadania do samodzielnej pracy
Należy utworzyć i debugować pięć procedur składowanych z następującej wymaganej listy:
Procedura 1. Zwiększ termin dostarczenia kopii książki o tydzień, jeśli obecny termin wynosi od trzech dni do bieżącej daty do trzech dni po bieżącej dacie.
Procedura 2. Zliczanie liczby bezpłatnych kopii danej książki.
Procedura 3. Sprawdzenie istnienia czytelnika o danym nazwisku i dacie urodzenia.
Procedura 4. Wpisanie nowego czytnika z weryfikacją jego istnienia w bazie danych i ustalenie nowego numeru karty bibliotecznej.
Procedura 5. Obliczanie grzywny w kategoriach pieniężnych dla czytelników-dłużników.
Krótki opis procedur
Procedura 1. Przedłużenie terminu na książki
Dla każdego wpisu w przykładowej tabeli sprawdza się, czy data dostawy książki mieści się w określonym przedziale czasowym. Jeśli tak, to data zwrotu książki wydłuża się o tydzień. Podczas wykonywania procedury musisz użyć funkcji do pracy z datami:
DateAdd (dzień,<число добавляемых дней>, <начальная дата>)
Procedura 2. Zliczanie liczby bezpłatnych kopii danej książki
Parametrem wejściowym procedury jest ISBN, unikalny szyfr książki. Procedura zwraca 0 (zero), jeśli wszystkie egzemplarze tej książki znajdują się w rękach czytelników. Procedura zwraca wartość N równą liczbie kopii książek, które znajdują się obecnie w rękach czytelników.
Jeśli książki o określonym numerze ISBN nie ma w bibliotece, wówczas procedura zwraca wartość –100 (minus sto).
Procedura 3. Sprawdzenie istnienia czytelnika o danym nazwisku i dacie urodzenia
Procedura zwraca numer karty bibliotecznej, jeśli istnieje czytnik z takimi danymi, w przeciwnym razie 0 (zero).
Porównując datę urodzenia, należy użyć funkcji konwersji Convert (), aby przekonwertować datę urodzenia - zmienną znakową typu Varchar (8), używaną jako parametr wejściowy do procedury, na dane typu datatime, które są używane w tabeli Readers. W przeciwnym razie operacja porównania podczas wyszukiwania tego czytnika nie będzie działać.
Procedura 4. Wprowadzanie nowego czytnika
Procedura ma pięć parametrów wejściowych i trzy parametry wyjściowe.
Parametry wejściowe:
- Pełna nazwa z inicjałami;
- Adres
- Data urodzenia;
- Telefon domowy;
- Telefon działa
Parametry wyjściowe:
- Numer karty bibliotecznej;
- Znak, czy czytnik był wcześniej zapisany w bibliotece (0 - nie, 1 - był);
- Liczba książek wymienionych przez czytelnika.
Procedura 5. Obliczanie grzywny w kategoriach pieniężnych dla czytelników dłużników
Procedura działa z kursorem, który zawiera listę numerów kart bibliotecznych wszystkich dłużników. W trakcie pracy powinien zostać utworzony globalny tymczasowy stół ## DOLG, w którym dla każdego dłużnika zostanie wpisany jego całkowity dług w ujęciu pieniężnym dla wszystkich książek, które utrzymywał przez dłuższy okres zwrotu. Wynagrodzenie pieniężne oblicza się na 0,5% ceny książki za dzień opóźnienia.
Zlecenie pracy

- kopie ekranów (zrzuty ekranu) potwierdzające zmiany dokonane w bazie danych;
- zawartość tabel bazy danych, które są wymagane do potwierdzenia prawidłowego działania;
- tekst procedury składowanej z komentarzami;
- proces rozpoczynania procedury składowanej od wyniku pracy.
Dodatkowe zadania
Poniższe dodatkowe procedury składowane dotyczą poszczególnych zadań.
Procedura 6. Zliczanie liczby książek w danym obszarze tematycznym, które są obecnie w bibliotece, w co najmniej jednym egzemplarzu. Obszar tematyczny jest przekazywany jako parametr wejściowy.
Procedura 7. Wprowadzanie nowej książki ze wskazaniem liczby kopii. Wprowadzając kopie nowej książki, nie zapomnij podać poprawnych numerów inwentarza. Pomyśl, jak to zrobić. Przypominam, że masz funkcje Max i Min, które pozwalają znaleźć maksymalną lub minimalną wartość dowolnego atrybutu numerycznego za pomocą narzędzia Wybierz zapytanie.
Procedura 8. Tworzenie tabeli z listą czytelników dłużników, czyli tych, którzy mieli zwrócić książki do biblioteki, ale jeszcze nie wrócili. W tabeli wynikowej każdy czytelnik dłużnika powinien pojawić się tylko raz, niezależnie od tego, ile książek jest winien. Oprócz pełnej nazwy i numeru karty bibliotecznej w tabeli wynikowej należy podać adres i numer telefonu.
Procedura 9. Wyszukaj darmową kopię dla danego tytułu książki. Jeśli istnieje wolna instancja, wówczas procedura zwraca numer inwentarza instancji; jeśli nie, procedura zwraca listę czytelników, którzy mają tę książkę, ze wskazaniem daty zwrotu książki i numeru telefonu czytelnika.
Procedura 10. Lista czytelników, którzy obecnie nie trzymają w ręku żadnej książki. Na liście wskaż nazwę i numer telefonu.
Procedura 11. Wyświetlanie listy książek ze wskazaniem liczby egzemplarzy tej książki w bibliotece i liczby wolnych egzemplarzy w tej chwili.
Wersja do wydruku
W tym samouczku dowiesz się, jak to zrobić tworzyć i usuwać procedury w SQL Server (Transact-SQL) ze składnią i przykładami.
Opis
W SQL Server procedura jest przechowywanym programem, do którego można przekazać parametry. Nie zwraca wartości jako funkcji. Może jednak przywrócić status powodzenia / niepowodzenia do procedury, która go spowodowała.
Utwórz procedurę
Możesz tworzyć własne procedury składowane w SQL Server (Transact-SQL). Przyjrzyjmy się bliżej.
Składnia
Składnia procedur w SQL Server (Transact-SQL):
UTWÓRZ (PROCEDURA | PROC) nazwa_procedury
[@parametr typ danych
[VARYING] [\u003d domyślnie] [OUT | WYDAJNOŚĆ | CZYTELNIE]
, @parameter typ danych
[VARYING] [\u003d domyślnie] [OUT | WYDAJNOŚĆ | CZYTELNIE]]
[Z (SZYFROWANIE | ZALECENIE | WYKONANIE JAKO Klauzula)]
[DO REPLIKACJI]
Jak
ROZPOCZNIJ
sekcja_wykonywalna
KONIEC
Parametry lub argumenty
nazwa_schematu to nazwa schematu, do którego należy procedura składowana.
nazwa_procedury to nazwa, do której ma zostać przypisana ta procedura w programie SQL Server.
@parameter - jeden lub więcej parametrów jest przekazywanych do procedury.
nazwa_schemy_typu jest schematem, który jest właścicielem typu danych, jeśli dotyczy.
Typ danych to typ danych dla @parameter.
ZMIENNE - ustawianie parametrów kursora, gdy zestaw wyników jest parametrem wyjściowym.
default - domyślna wartość do przypisania do parametru @parameter.
OUT - oznacza to, że parametr @ jest parametrem wyjściowym.
WYJŚCIE - oznacza to, że parametr @ jest parametrem wyjściowym.
TYLKO ODCZYT - oznacza to, że @parameter nie może zostać zastąpiony przez procedurę przechowywaną.
SZYFROWANIE - oznacza to, że źródło procedury składowanej nie zostanie zapisane jako zwykły tekst w widokach systemu SQL Server.
RECOMPILE - oznacza to, że plan zapytania nie będzie buforowany dla tej procedury składowanej.
EXECUTE AS - Ustawia kontekst bezpieczeństwa dla wykonywania procedury składowanej.
DO REPLIKACJI - oznacza to, że procedura przechowywana jest wykonywana tylko podczas replikacji.
Przykład
Rozważ przykład tworzenia procedury przechowywanej w SQL Server (Transact-SQL).
Oto prosta przykładowa procedura:
Transact-sql
UTWÓRZ PROCEDURĘ FindSite @nazwa_partycji VARCHAR (50) WYJŚCIE NA POCZĄTEK DEKLARACJA @site_id INT; SET @site_id \u003d 8; JEŚLI @site_id< 10 SET @site_name = "yandex.com"; ELSE SET @site_name = "google.com"; END;
UTWÓRZ PROCEDURĘ FindSite @ nazwa_strony VARCHAR (50) OUT ROZPOCZNIJ DECLARE @ site_id INT; SET @ site_id \u003d 8; IF @ site_id< 10 SET @ site_name \u003d "yandex.com"; ELSE SET @ site_name \u003d "google.com"; KONIEC |
Ta procedura nazywa się FindSite. Ma jeden parametr o nazwie @nazwa_partycji, który jest parametrem wyjściowym aktualizowanym na podstawie zmiennej @site_id.
Następnie możesz odwołać się do nowej procedury składowanej o nazwie FindSite w następujący sposób.