اینترنت مانند یک کتابخانه عظیم جهانی است ، که فقط یک تفاوت دارد ، اما تفاوت قابل توجهی: برای جستجوی کتاب در کتابخانه ، یک کاتالوگ وجود دارد ، به عنوان آخرین چاره ، می توانید به یک کتابدار باتجربه مراجعه کنید. هیچ کاتالوگ کاملی از اینترنت وجود ندارد. اما ، جستجو در شبکه رایانه ای جهانی امکان پذیر است و شاید این یکی از مهمترین جنبه های آن باشد. برای جستجوی داده ها در شبکه ، از سرورهای ویژه ای استفاده می شود که اطلاعات مربوط به آنها تقریباً به صورت خودکار حفظ و به روز می شود.
امروزه که اینترنت به یکی از منابع اصلی اطلاعات تبدیل شده است ، جستجوی اینترنت هرچه بیشتر ارزش عملی پیدا می کند. اما با افزایش سریع مقدار داده های موجود ، روش جستجو خود پیچیده و پیچیده می شود.
اینترنت یک شبکه رایانه ای جهانی است که هم کاربران شبکه رایانه و هم کاربران رایانه را به هم متصل می کند. اینترنت به آرامی اما مطمئناً به اصلی ترین وسیله ارتباطی شرکت ها تبدیل می شود و جای خود را به تلفن می دهد.
منابع عظیمی از اطلاعات در وب وجود دارد. طبق برخی تخمین ها ، تعداد اسناد از 65 میلیون سند گذشته است و به سرعت در حال رشد است. چنین حجم اطلاعاتی نیاز به سازماندهی صحیح فرآیند جستجو و استفاده از ابزارهای فنی ویژه مانند موتورهای جستجو دارد. یک جستجوی ساده برای یک کلمه کلیدی نسبتاً معمول معمولاً از ده ها هزار تا چندین میلیون پیوند دارد. بدیهی است که کار با این تعداد زیاد اسناد عملاً غیرممکن است ، خصوصاً اینکه اکثریت قریب به اتفاق آنها حاوی اطلاعاتی هستند که بی ربط هستند.
منابع اطلاعات در اینترنت در نحوه ارائه اطلاعات و در نتیجه در روش دسترسی به آنها متفاوت است.
1 ابزار جستجو
1.1 ابزار جستجوی پرونده
یافتن فایل به صورت دستی در ساختار دایرکتوری پیچیده سرور ftp می تواند مدت ها طول بکشد. برای ساده سازی و سرعت بخشیدن به جستجو ، سرویس جستجوی اینترنتی Archie ایجاد شد که یک سرور ویژه Archie است که محتوای دایرکتوری های سرورهای ناشناس ftp را ذخیره می کند. هنگام آدرس دهی به یک جستجوی جستجو در سرور Archie ، نتیجه جستجو لیستی از آدرس های سرورهای ftp ناشناس است که فایل مورد نظر را دارند.
اما این وظیفه پیدا کردن یکی از موارد دلخواه در این سرور است که به دلیل نامشخص بودن و نامفهوم بودن پرونده ها و دایرکتوری ها بسیار دشوار است. برای حل این مشکل ، از سیستم Gopher استفاده شده است ، که به شما امکان می دهد از طریق سیستم منوهای زمینه ای که محتوای فایل ها را با استفاده از نمادهای قابل فهم نشان می دهد ، حرکت کنید. بسیاری از سرورهای Gopher وجود دارند که حاوی بایگانی از داده ها در قالب فهرست های ساختار سلسله مراتبی هستند که براساس محتوا مرتب شده اند. کار با آنها بسیار ساده است و مربوط به کار با نمایشگر سیستم فایل معمولی است.
پسوندی از این سیستم وجود دارد - Veronica ، که شامل دایرکتوری تمام سرورهای Gopher در پایگاه داده آن است. پس از ورود به یک جستجوی جستجو ، Veronica به طور خودکار تمام دایرکتوری های Gopher را برای اطلاعاتی که به دنبال آن هستید اسکن می کند ، در نتیجه نیازی به جستجوی دستی بسیاری از سرورهای Gopher نیست.
با این روش پیمایش ، Gopher تا حدی پیشگام WWW بود. در حال حاضر ، متناسب با افزایش استفاده از WWW ، استفاده از Gopher در حال کاهش است.
1.2 ابزار WWW - WorldWideWeb
در سال 1993 ، سیستم بازیابی اطلاعات WWW ایجاد شد که به دلیل سهولت در ناوبری و دسترسی ، منابع اطلاعاتی اینترنت را به روی کاربران غیرآماده باز کرد. WWW باعث رونق اینترنت شده است که تا به امروز ادامه دارد و هر سال میزان اطلاعات موجود در اینترنت دو برابر می شود.
WWW مبتنی بر اصل ابرمتن (که قبلاً برای خواننده آشنا بوده است) استوار است ، یعنی بر اساس سیستمی از اسناد مرتبط با هایپر لینک است. Hypertext روش ویژه ای برای برجسته سازی کلمات کلیدی از متن معمولی است. پیوندهای ابر متن کاربر را به اسناد دیگر در همان سرور یا سرورهای دیگری که می توانند در هر نقطه از اینترنت قرار بگیرند ، ارسال می کنند. اگر این سند متن نیز دارای ابر متن باشد ، پیوندهای آن به شما امکان می دهد که بیشتر به اسناد مربوطه بروید. هر تغییر مسیر برای کاربر به طور نامحسوس اتفاق می افتد ، به طوری که او می تواند بدون نگرانی در مورد آدرس دهی به رایانه های خاص ، ترکیب اطلاعات اینترنت را به طرز معنی داری مشاهده کند.
با توسعه برنامه های چندرسانه ای ، در ابتدا اسناد کاملاً متن فوق العاده به طور فزاینده ای به ابر رسانه تبدیل می شوند. بنابراین ، اسناد WWW می توانند در هر قالب داده ای وجود داشته باشند: متن ، گرافیک ، صدا / موسیقی یا کلیپ ویدیویی. جهت گیری و پیمایش در شبکه جهانی وب با استفاده از برنامه های خاصی به نام WWW-مرورگرها که رابط کاربری مانند NetscapeNavigator یا MicrosoftInternetExplorer را فراهم می کنند ، رخ می دهد.
نقطه شروع جستجو برای اطلاعات ، به طور معمول ، صفحه اصلی (پایگاه ، صفحه اصلی) (سایت) منبع اطلاعات است که با وارد کردن آدرس مربوطه در مرورگر می توانید به آن دسترسی پیدا کنید (به عنوان مثال http: // ncpi .gov.by یا www.iparegistr.com). سایت های WWW توسط شرکت ها یا سازمان های ویژه ای که اطلاعات را منتشر می کنند و محتوای سایت های WWW خود را نظارت می کنند ، ایجاد و به روز می کنند. بنابراین ، استفاده از WWW انفعالی نیست و هر کاربر اینترنت با کمک برنامه های ویژه ویرایشگر ابر متن می تواند به طور مستقل صفحات WWW تعاملی خود را ایجاد کند. این زمینه را برای تجارت فزاینده و گسترش اینترنت فراهم کرد.
در حال حاضر ، اطلاعات تازه ایجاد شده ، به عنوان یک قاعده ، با در نظر گرفتن نیاز به دسترسی به WWW تولید می شود و اسناد قبلی به تدریج برای آن تبدیل می شوند ، اما در سراسر جهان هنوز میلیون ها پرونده به اشکال غیر از WWW وجود دارد. برای استفاده از این اطلاعات و از طریق WWW ، خدمات اینترنتی فوق در مرورگرهایی که دسترسی به آن را فراهم می کنند (telnet ، ftp ، Archie ، Gopher) گنجانده شده است. از طریق WWW می توانید از سایر سرویس های اینترنتی که برای برقراری ارتباط استفاده می شوند نیز استفاده کنید (پست الکترونیکی ، NetNews). بنابراین ، مرورگر WWW اکنون به یک برنامه ارتباطی جهانی برای اینترنت تبدیل شده است.
با ظهور سرویس WWW ، رونق اینترنت آغاز شد. این محیط کاربری آسان و کاربرپسند برای همه سرویس ها توجه بسیاری از افراد و سازمان ها را در اینترنت جلب کرده است. ناگهان مشخص شد که شما برای استفاده از خدمات شبکه نیازی به متخصص اینترنت ندارید. این را می توان با موفقیت مایکروسافت در انتشار Microsoft Windows به عنوان یک رابط کاربری گرافیکی مقایسه کرد. قبل از ظهور ویندوز ، هر برنامه DOS کتابچه راهنمای کاربر خود را داشت و بنابراین نیاز به مطالعه جداگانه هر برنامه داشت.
2 روش اساسی برای یافتن اطلاعات در اینترنت
2.1 الزامات اساسی برای جستجو
برای کامل بودن پوشش منابع ، قابلیت اطمینان اطلاعات به دست آمده ، حداقل زمان مورد نیاز و حداکثر سرعت جستجو ، الزاماتی به نتایج جستجو اعمال می شود.
نیاز به کامل بودن پوشش منابع نیازی به توضیحات اضافی ندارد ، مگر اینکه نیاز به استفاده از منابع نه تنها از WWW برای جستجوها ، بلکه از سایر خدمات اینترنت نیز باشد.
قابلیت اطمینان اطلاعات ، با توجه به ماهیت اینترنت ، در حال تبدیل شدن به یک نیاز فوق العاده مهم است. ارزیابی قابلیت اطمینان می تواند هم با روش های سنتی (بررسی قانونی بودن انتشارات روی کاغذ ، کسب اطلاعات در مورد سازمان ها و نویسندگان ، یافتن اعتبار منابع الکترونیکی آنها و غیره) و هم با استفاده از امکانات اینترنت (آشنایی با منابع اطلاعاتی جایگزین ، سازگاری مطالب واقعی ، ایجاد تعداد دفعات استفاده از آن توسط سایر منابع ؛ پیدا کردن وضعیت سند و رتبه بندی منبع توسط موتورهای جستجو ، کسب اطلاعات در مورد صلاحیت و وضعیت نویسنده از مطالب با استفاده از خدمات جستجوی اینترنتی ویژه ؛ تجزیه و تحلیل عناصر فردی سازمان سایت به منظور ارزیابی صلاحیت متخصصان پشتیبانی کننده آن و موارد دیگر).
زمان جستجو ، بدون احتساب زمان صرف شده برای مشخصات اتصال ، بستگی زیادی به برنامه ریزی جستجو و مهارت متخصص جستجو با نوع انتخاب منبع دارد. برنامه ریزی جستجو عبارت است از تعیین خدمات جستجوی لازم برای حل یک درخواست جستجو و ترتیب اعمال آنها. علاوه بر این ، بسیاری از موارد به مهارت و تجربه متخصص جستجوی فردی بستگی دارد.
همانطور که قبلاً اشاره شد ، اطلاعات در اینترنت از انواع مختلف منابع در دسترس است. اول از همه ، این منابع WWW هستند (سیستم ابر متن ، کاتالوگ منابع ، موتورهای جستجو). علاوه بر این ، از قبل برای ایمیل خوانندگان ، ربات های پستی ، Usenet و سایر گروه های خبری ، و همچنین سیستم های ftp و بایگانی ها (با استفاده از Gopher و Veronica) شناخته شده است. WWW به شما این امکان را می دهد تا منابع مورد نیاز را بر اساس بیش از حد خواص خود جستجو کنید ، یعنی موتورهای جستجوی موجود با استفاده از هایپر لینک در حالت خودکار کار می کنند ، بدون اینکه امکان مرور دستی را حذف کنید. WWW دارای تعدادی سرویس جستجوی عمومی و تخصصی است.
دایرکتوری های منابع پایگاه داده هایی با آدرس منابع اینترنتی و موضوعات متنوع هستند. آنها معمولاً دارای ساختار سلسله مراتبی هستند که برای کاربر آشنا هستند و برخی از ابزارهای جستجو در آن است. در بیشتر موارد ، این کاتالوگ ها توسط متخصصان طبقه بندی ارائه می شوند ، یعنی یک رویکرد ذهنی خاص برای انتخاب اطلاعات از پیش تعیین شده است ، که از یک طرف ، تا حدودی قابلیت اطمینان اطلاعات را تضمین می کند ، اما از سوی دیگر ، پیش تعیین کننده امکان عدم وجود (حذف) برخی از اطلاعات ، و همچنین تمام جایگذاری دیر هنگام در فهرست.
موتورهای جستجو مکانیزمی برای ایجاد خودکار پیوندها (فهرست ها) به منابع مختلف هستند. موتورهای جستجو می توانند منابع جهانی ، تخصصی یا محلی را هدف قرار دهند. در واقع ، آنها IRS قدرتمندی هستند که با کمک برنامه های ویژه ربات (به اصطلاح "عنکبوت") دائماً به جستجوی خودکار اطلاعات مورد نیاز در اینترنت می پردازند. پایگاه داده های تخصصی ایجاد شده بر این اساس بازیابی اطلاعات را بر اساس درخواست های کاربر مبتنی بر IPL های خاص ارائه می دهند. درست است ، پوشش اطلاعات مشاهده شده به الگوریتم های استفاده شده بستگی دارد و حتی برای موتورهای جستجوی قدرتمند نیز جای مطلوب است.
نامه الکترونیکی در اینترنت و WWW استفاده می شود. در این حالت آدرس ها به موتورهای جستجو می روند و در دسترس موتورهای جستجو قرار دارند.
ربات های نامه ای برنامه های ویژه ای هستند که می توانند با اعمال خاصی به دستوراتی که به آنها می رسد پاسخ دهند ، اما از طریق ایمیل. هدف اصلی آنها ارسال داده های درخواستی در مواردی است که به هیچ وجه دیگر در دسترس نیستند و همچنین گزینه ای برای کار آنلاین با هر یک از منابع شناخته شده ، به عنوان مثال بایگانی های ftp. آدرس ربات پستی در قالب ایمیل است. هنگام جستجو ، ربات های پستی معمولاً فقط به عنوان واسطه در بدست آوردن اطلاعات استفاده می شوند. بعضی اوقات باید با این واقعیت کنار بیایید که آنها تنها وسیله برای کسب اطلاعات لازم هستند.
Usenet و سایر گروه های خبری منطقه ای و تخصصی "تابلوهای پیام" الکترونیکی هستند که کاربر اطلاعات خود را در یکی از گروه های خبری موضوعی ارسال می کند و به مشترکان موضوع مربوطه ارسال می شود. این منبع برای انباشت سریع اطلاعات از اهمیت بیشتری برخوردار است ، اما یک مسئله باریک است ، و هنگام جستجو - اغلب برای به دست آوردن اطلاعات خصوصی و غیر رسمی.
منابع موجود از طریق telnet ، در بعضی موارد ، اطلاعات کاملاً منحصر به فردی را نشان می دهد ، در درجه اول در کاتالوگ کتابخانه های دانشگاه های اروپا و آمریکا و همچنین سازمان های دولتی.
همانطور که قبلاً اشاره شد ، سیستم بایگانی فایل ftp دارای یک منبع اطلاعاتی بسیار گسترده است که هنوز به WWW ترجمه نشده است. بایگانی های ftp اصولاً منابعی برای بدست آوردن نرم افزار هستند. اگر ساختار بایگانی را بدانید ، جستجوی آنها می تواند مورد توجه باشد. ایجاد سیستم های پرونده ، نام پرونده ها و دایرکتوری ها حاوی منابع مورد نیاز.
2.2 روش جستجو برای اطلاعات در اینترنت
جستجوی اطلاعات مورد نیاز شما در اینترنت به روش های مختلفی انجام می شود:
با موتورهای جستجو با کلمات کلیدی جستجو کنید
جستجو با طبقه بندی موتور جستجو
راهنماها و مجموعه پیوندها (مفاهیم کلی تر)
کنفرانس ، چت
· صفحات پیوندها ("پیوندها") در سایتهای موضوعی (موارد تخصصی نادر)
روش های غیر شبکه ای (مشاوره دوستان ، آشنایان ؛ تبلیغات در رسانه های چاپی)
در ابتدای جستجوی اطلاعات ، تعیین نوع آن ضروری است. به طور معمول ، 4 نوع اطلاعات را می توان تشخیص داد.
1 نوع - عمومی (به عنوان مثال: تاریخ امپراتوری روسیه) ،
نوع 2 - کمتر عمومی (به عنوان مثال: امپراطور اسکندر دوم) ،
نوع 3 - خاص (به عنوان مثال: اصلاحات اسکندر دوم) ،
نوع 4 خاص تر است (به عنوان مثال: لغو رعیت).
مسیرهای جستجو نیز بسته به نوع اطلاعات تعیین می شوند.
اطلاعات نوع 1 با استفاده از طبقه بندی موتور جستجو جستجو می شود (از روسی - Yandex www.Yandex.ru توصیه می شود). اگر سایتهایی با اطلاعات مورد نیاز بلافاصله پیدا نشدند ، باید کاتالوگها و صفحات پیوندها ("پیوندها") را که توسط طبقه بندی کننده در سایتهای با موضوع مشابه واقع شده اند ، جستجو کنید. این سایتها در طبقه بندی شده بر اساس موضوع لیست شده و فهرست آنها پیدا شده است.
اطلاعات نوع 2 مشابه جستجوی نوع 1 جستجو می شود ، اما با مزیت جستجوی فهرست ها و صفحات پیوند.
اطلاعات از 3 نوع - توسط کلمات کلیدی که در نوار جستجو موتورهای جستجو ، کاتالوگ ها ، صفحات پیوند وارد می شوند
اطلاعات از 4 نوع - با توجه به داده های مفصلی که در نوار جستجو وارد می شود. داده ها با توجه به روشهای جستجوی مشخص شده برای انواع 2 و 3 یافت می شوند.
جستجو بر اساس نوع 1. اطلاعات مورد نیاز: "تاریخ امپراتوری روسیه".
ما به Yandex - علوم و معارف / علوم اجتماعی / تاریخ می رویم. با توجه به توضیحات موضوع ، سایت http://rus-hist.on.ufanet.ru را می یابیم .. اگر اطلاعات لازم را ندارد ، به صفحه پیوندهای این سایت بروید. این شامل پیوندهایی به کاتالوگ منابع است: www.history.ru ، http://www.lants.tellur.ru/history/index.htm. در آنها ، به احتمال زیاد ، سایتهایی با موضوع مشخص پیدا می شوند.
جستجو بر اساس نوع 2. اطلاعات مورد نیاز: "Emperor Alexander II".
جستجو مشابه مورد قبلی انجام می شود ، اما بیشتر به کار با کاتالوگ ها توجه می شود www.history.ru ، http://www.lants.tellur.ru/history/index.htm.
جستجو بر اساس نوع 3. اطلاعات مورد نیاز: "اصلاحات اسکندر دوم"
در اینجا روش جدیدی برای جستجو وجود دارد - توسط کلمات کلیدی. ما در خط جستجوی Yandex "Reforms of Alexander II" می نویسیم. نتیجه برای مشاهده - 1790 صفحه ، که در 170 سایت واقع شده است ، که شامل دایرکتوری است. برای محدود کردن اطلاعات ، می توانید کلمات کلیدی جدید اضافه کنید - حقایق اضافی در سایت هایی که قبلا پیدا شده است ، به عنوان مثال: "1860-1870". و غیره. در سایر موتورهای جستجو ، کل "اصلاحات الكساندر دوم در 1860-1870" تایپ می شود. برای جستجوی اطلاعات مشخص شده ، می توانید از "پیوندها" که در سایت های یافت شده ارائه می شود نیز استفاده کنید
2.3 توسعه یک منبع اطلاعاتی
مانند سایر فناوری های اطلاعاتی ، اینترنت توسط توسعه دهندگان ایجاد می شود ، اما در این حالت عمدتاً عامل ایجاد منابع (با شروع از متخصصانی که سخت افزار و نرم افزار را پشتیبانی می کنند ، طراحان ، هنرمندان ، ویراستاران و از همه مهمتر نویسندگان منابع اطلاعاتی) . به طور طبیعی ، ایجاد منابع به خودی خود هدف نیست ، منابع توسط کاربران شبکه تقاضا می شوند ، یعنی توسط همان متخصصان و مصرف کنندگان منابع ، که در میان آنها ، همانطور که قبلا ذکر شد ، یک لایه جدید ظاهر می شود - متخصصان در زمینه داده ، در اطلاعات جستجو کردن. منابع اطلاعاتی اینترنت و همچنین منابع دیگر ، از جمله منابع اطلاعاتی غیر الکترونیکی (به ویژه رسانه های جمعی) ، با شرایط خاصی از فعالیت های خود مشخص می شوند (شکل 9.3).
این منبع مطابق با نیازهای جامعه و توانایی های آن (به ویژه منابع مربوط به سطح وضعیت فنی و اجتماعی جامعه) سرچشمه می گیرد.
تا آنجا که ممکن است ، یک "بلوغ" وجود دارد ، تشکیل منبع (یا از بین رفتن آن در صورت عدم تقاضا ، یعنی ناپدید شدن ، شاید نه به معنای فیزیکی - سایت می تواند وجود داشته باشد ، یعنی به معنای وجود مورد تقاضا).
در سطح مشخصی از تقاضا و (از جمله تلاش نویسندگان سایت) فهرست بندی می شود ، یعنی اطلاعات مربوط به منبع در فهرست های مختلف متناسب با نوع منبع ظاهر می شود.
نمایه سازی ، یعنی ظهور یک منبع در نمایه های موتورهای جستجو ، هنگامی اتفاق می افتد که به مقدار مشخصی از محتوا رسیده و مورد تقاضا باشد.
اگر رشد مداوم تقاضا وجود داشته باشد ، منبع به طور مداوم در حال توسعه است ، در غیر این صورت منبع از بین می رود و به تدریج از فهرست ها و فهرست ها محو می شود.
2.4 مورد نیاز برای ابزار جستجو
همانطور که قبلاً اشاره شد ، ویژگیهای ذاتی یک جستجوی حرفه ای کامل بودن ، قابلیت اطمینان و سرعت بالا آن است. جدی ترین و غیر پیش پا افتاده ترین عامل تعیین کننده سرعت دستیابی به هدف جستجو ، برنامه ریزی روش جستجو است. این امر از یک سو نیاز به انتخاب نوع منابعی دارد که به طور بالقوه توانایی حمل اطلاعات مربوط به کار جستجو را دارند و از طرف دیگر ، انتخاب ابزار جستجو در زمینه اطلاعات مربوطه بسته به عملکرد مورد انتظار آنها . اگر ما در مورد ظرفیت پذیرترین برای امروز صحبت کنیم ، از نظر محتوای اطلاعاتی ، فضای WWW ، وفور نسبی امکانات جستجوی آن حل مشکلات عملی را چند متغیره می کند. ساخت دنباله بهینه برای استفاده از ابزارهای خاص در هر مرحله از جستجو و اثربخشی آن را تعیین می کند. ایده روشنی از انواع ، هدف و ویژگی های کار سیستم های بازیابی اطلاعات (ISS) در اینترنت می تواند به حل مشکل انتخاب کمک کند.
حاملان واقعی اطلاعات در مورد منابعی که اینترنت در اختیار دارد موتورهای جستجو و کاتالوگ ها هستند. سیستم های بازیابی اطلاعات در اینترنت متفاوت است ، اما اصل انتخاب اطلاعات ، که به یک درجه یا درجه دیگر در برنامه اسکن موتور جستجو وجود دارد و در فعالیت های متخصصان فهرست نویسی وجود دارد. به عنوان یک قاعده ، دو شاخص اصلی از هم متمایز می شوند: مقیاس مکانی سیستم و تخصص آن.
هنگام تشکیل آرایه اطلاعات ، موتور جستجو می تواند به روزرسانی مجموعه ای از پیش تعیین شده از اسناد ، کاتالوگ ها یا تعداد محدودی از گره ها را که طبق برخی اصول انتخاب شده اند ، پیگیری کند. چنین سیستم هایی را که در اینترنت پیاده سازی می شوند ، می توان تا حدودی مشروطاً محلی و. موتورهای جستجوی جهانی ، برخلاف موتورهای محلی ، کار پرزحمت تری را حل می کنند - کاملترین پوشش ممکن از منابع کل حوزه اطلاعاتی اینترنت (WWW یا سایر موارد) را که در خدمت آنها هستند. پیامد این امر افزایش نقش مکانیزم مورد استفاده چنین سیستمی برای افزایش مداوم تعداد سایتهای مشاهده شده است.
ایجاد خدمات جستجوی منطقه ای و تخصصی ، تصفیه فعال اطلاعات را پیش فرض می گیرد. تخصص یک موتور جستجو بر اساس هر نمایه یا موضوعی ، خواه یک موضوع حقوقی باشد ، جستجوی شخصیت ها یا پرونده های چندرسانه ای در قالب MP3 ، هم در مقیاس جهانی و هم در سطح محلی رخ می دهد. البته ساخت و نگهداری سیستم در فضای محدودی از سایتهای بروز شده آسان تر است که معمولاً در عمل پیاده سازی می شود.
خدمات جستجوی منطقه ای اطلاعات را عمدتا توسط نام دامنه سطح بالای سرور فیلتر می کنند ، به عنوان مثال توسط Belarus ، ru - برای روسیه. یک اشکال جدی در این سیستم ها عدم حسابداری برای تعداد زیادی از منابع ارسال شده توسط نویسندگان منابع منطقه ای به طور مستقیم در دامنه com است.
در نظر گرفتن ویژگی های منطقه ای اغلب در خدمات جستجوی جهانی وجود دارد. به عنوان مثال سیستم Lycos ، پاسخ ها را براساس منطقه درخواست رتبه بندی می کند.
از نظر ماهیت ، اینترنت با هرج و مرج اطلاعاتی همراه است. و فقط ابزارهای مدرن برای نمایه سازی خودکار اسناد با در نظر گرفتن الگوریتم های استفاده شده و قابلیت های ابزارهای فنی قادر به یافتن دانه ای منطقی در این هرج و مرج هستند. استفاده از منابع هنگام جستجوی منابع بدون جستجوی کلمات کلیدی یادآور گشت و گذار است و کار جدی با اطلاعات نیست.
2.6 موتورهای جستجوی جهانی WWW
کاربر پس از آشنایی با چندین موتور جستجوی جهانی ، به طور معمول ، در یک یا دو مورد متوقف می شود ، که ترجیح می دهد در آینده با آن کار کند. در همان زمان ، انتخاب یک سرویس جستجو اغلب به روشی کاملاً دلخواه ، نه بر اساس تجزیه و تحلیل توانایی های واقعی سیستم ها ، بلکه بر اساس محبوبیت آنها صورت می گیرد. یکی از بزرگترین و محبوب ترین ها AltaVista است. سیستم AltaVista دارای یک زبان جستجوی انعطاف پذیر است ، که به هر حال نیاز به مطالعه تخصصی دارد. AltaVista دارای پشتیبانی چند زبانه از فهرست جستجو و توانایی ترجمه آنلاین (یعنی مستقیماً در طول جلسه) متن یک صفحه وب از زبانهای رایج اروپایی به انگلیسی است.
یکی دیگر از سیستم های شناخته شده NorthernLight است که دارای مجموعه ای نسبتاً استاندارد از توابع است. این سیستم علاوه بر این امکان کار با مجموعه ای منحصر به فرد از پیوندها (بیش از 6 هزار) ، عمدتا به مقالات از نشریات دوره ای را فراهم می کند. پشتیبانی از الفبای سیریلیک (از جمله زبان روسی) باعث می شود که همراه با AltaVista ، یک موتور جستجوگر منطقه ای روسی Rambler ، Yndex و Aport برای جستجوی روسی زبان باشد.
یافتن و جمع آوری اطلاعات در اینترنت نیاز به برنامه ریزی دارد. منطق اشتباه ساخت پرس و جو ، توالی بدون بهینه استفاده از ابزار جستجو ، تلاش برای سرعت بخشیدن به جستجو - همه اینها نه تنها نتیجه را به تأخیر می اندازد ، بلکه می تواند معنای کار جستجو را به خطر بیندازد.
بگذارید در چندین نکته مهم مربوط به برنامه ریزی و اولین مراحل این کار صحبت کنیم.
لازم است با تجزیه و تحلیل واژگانی جامع اطلاعات مورد نیاز شروع شود. برای بدست آوردن اطلاعات اولیه باید از هرگونه توضیح کافی و قابل اعتماد و دقیق در مورد موضوع مورد مطالعه استفاده شود. چنین منبعی ممکن است هم یک کتاب مرجع کاملاً تخصصی باشد و هم یک دایره المعارف الکترونیکی با مشخصات عمومی. بر اساس مطالب مورد مطالعه ، تشکیل گسترده ترین مجموعه ممکن از کلمات کلیدی در قالب اصطلاحات ، عبارات ، واژگان حرفه ای ، عامیانه ، کلمات کلیشه ای و تمبرهای کلامی پایدار ، در صورت لزوم به چندین زبان ، ضروری است. اصلاحات احتمالی پرسش جستجو باید از قبل تعیین شود - کلمات نادر ، مترادف و متضاد. نام و نام خانوادگی نزدیک به سوال مورد نظر است. همچنین پیش بینی پاسخهای بی ربط احتمالی به سeriesالات ، یعنی ویژگیهای احتمالی نویز جستجو ، از قبل توصیه می شود. پس از جمع آوری این داده های اولیه ، می توانید اطلاعات اولیه را از اینترنت دریافت کنید.
وظیفه اصلی این مرحله در نظر گرفتن ویژگی های اینترنت است که نه تنها حامل فناوری ها است ، بلکه سنت ها و اخلاق خاص خود را نیز دارد. واژگان شبکه ، عامیانه و هجی کلمات رایج در اینجا ممکن است با کلمات پذیرفته شده متفاوت باشد.
بهتر است به جستجوی اطلاعات مربوط به در دسترس بودن داده های لازم در اینترنت در یک فهرست شناخته شده قبلی بپردازید که از جستجوی کلمات کلیدی پشتیبانی می کند. هنگام حل کردن ، به عنوان مثال ، کارهای ساده مانند "متن قانون اساسی جمهوری بلاروس را دریافت کنید" یا "در کدام یک از اقدامات قانونی نام شهر زادگاه خود استفاده می شود" ، یک سایت یا کاتالوگ معروف می تواند یک راه سریع به دست آوردن اطلاعات از یک شاخص خودکار و قابلیت اطمینان بیشتری را فراهم می کند.
پس از تجزیه و تحلیل واژگانی اطلاعات ، مرحله فن آوری آغاز می شود. انتخاب زمینه اطلاعات اینترنت و ابزارهای جستجو بر اساس رویکردهای فوق است.
از عبارتهای آزمایشی یک یا دو کلمه کلیدی یا عبارت استفاده می شود ، سپس پاسخ کمی تجزیه و تحلیل می شود. تجزیه و تحلیل محتوای داده ها به شما امکان می دهد س quالات را تنظیم کنید ، اما ارتباط آنها با پاسخ مرتبط است. در نتیجه آزمایش ، نماینده ترین منابع اطلاعاتی شناسایی می شوند ، پس از آن توالی استفاده از ابزار جستجو باید روشن شود. این مرحله برنامه ریزی را به پایان می رساند.
در پایان ، یادآور می شویم که در حل مشکل جمع آوری اطلاعات از اینترنت ، خدمات جستجوی منطقه ای و تخصصی نقش بسزایی دارند. استفاده از نمایه های جهانی ، نه برای جستجوی مستقیم اطلاعات لازم ، بلکه برای بومی سازی این ابزارهای جستجو ، کوتاه کردن زمان لازم برای حل یک مسئله جستجوی مشخص را ممکن می کند.
نتیجه
با در نظر گرفتن همه موارد فوق ، می توان ماهیت اینترنت را در یک کلمه تعریف کرد: این ارتباط ، ارتباط بین افراد و کل ملتها بدون دخالت مقامات دولتی است. این فناوری جدید در حال تغییر چهره تمدن با سرعتی شگرف است و ایده انسان را در مورد جهان و خود کاملاً تغییر می دهد. اینترنت در حال حاضر دهها میلیون نفر ، بیش از یکصد کشور جهان را جذب خود کرده است ، روند انتشار و درک اطلاعات را کاملاً تغییر داده است. در عصر فناوری های اطلاعاتی ، اینترنت واقعیت مجازی ، کمک به پاک کردن مرزهای کشور ، کاهش فاصله جغرافیایی ، از بین بردن موانع بین فرهنگ ها , کمتر از جهان مادی اطراف ما آشکار می شود
با توسعه اینترنت ، جستجوی سریع و راحت اطلاعات مستندات لازم امکان پذیر شد. اکنون نیازی به انتخاب و مطالعه مقادیر زیادی از ادبیات در کتابفروشی ها و کتابخانه ها نیست. اطلاعات را می توان بدون خروج از خانه یا محل کار خود به دست آورد. برای این کار ، شما فقط نیاز به خود رایانه دارید که با یک برنامه ویژه نصب شده به اینترنت متصل شده است - یک مرورگر که برای مشاهده محتوای صفحات وب طراحی شده است.
با تشکر از انواع موتورهای جستجو که به طور خاص برای یک کاربر معمولی طراحی شده اند ، همه می توانند به راحتی جریان اطلاعات واضح و غیرضروری را قطع کنند ، فقط با فرمول بندی صحیح هدف جستجو.
لیست ادبیات استفاده شده
1. گرینبرگ A.S. ، Kashinsky Yu.I. ، Slavin B.S مقدمه ای در انفورماتیک حقوقی. Minsk: NO OOO BIP-S ، 2002 S. 303.
2. Gusev V.S. گوگل: به طور موثر جستجو کنید. راهنمای شروع سریع. م. ، 2006.
3. انفورماتیک برای وکلا و اقتصاددانان. / ویرایش شده توسط S. V. Simonovich. SPb.: Peter، 2001.
4. انفورماتیک. دوره مقدماتی کتاب درسی برای دانشگاه ها ، سن پترزبورگ ، 2001
5. فن آوری های رایانه ای در فعالیت های حقوقی. / ویرایش شده توسط پروفسور N. Polevoy. م.: انتشارات BEK ، 1994
6. ترشی MM قانون اطلاعات - M.M: حقوقدان ، 1999.-321s.
7. دائرlopالمعارف اینترنت ، سن پترزبورگ ، 2001
8. مرورگرها چگونه مقایسه می کنند // http: //www.microsoft.com
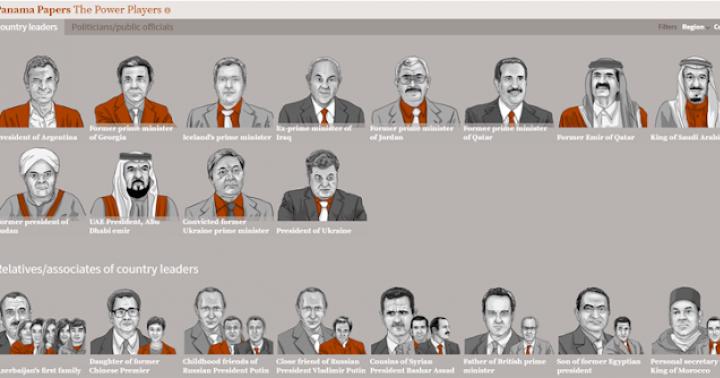
زمان زیادی از آن زمان نمی گذرد و کنسرسیوم بین المللی روزنامه نگاری تحقیقی - ICIJ ، بر اساس این اسناد ، "هدیه ای" بزرگ و بزرگ جدید را برای سیاستمداران فاسد آماده کرده است. درز اسناد محرمانه نشان داد كه روسای جمهور قدرت های بزرگ و كوچك ، نزدیكان و نزدیكان آنها در كتمان درآمد در مناطق فراساحلی نقش دارند.
بزرگترین نشت شرکت پانامایی فساد رهبران جهان را نشان می دهد
این اسناد حاوی اسامی 72 رهبر فعلی و پیشین دولت ها از جمله رهبرانی است که به غارت کشورهای خود متهم شده اند. این لیست شامل اسامی رئیس جمهور اوکراین پترو پوروشنکو ، پادشاه عربستان سعودی ، رئیس جمهور فدراسیون روسیه پوتین و دوستان نزدیک وی ، بشار اسد و رهبر ملت آذربایجان ، الهام علی اف است. 
جرارد رایل ، مدیر ICIJ گفت که "این نشتی ترین صدمه در خارج از کشور است که تاکنون انجام شده است." ظاهراً کسی واقعاً قدرتمند و آگاه ، که ضربه ای به تجارت خارج از کشور وارد کرده بود ، علیه فساد ، مخفی کردن درآمد و پولشویی در مقیاس جهانی جنگ اعلام کرد.
چرا در مورد مقالات پاناما چنین سر و صدا وجود دارد
بگذارید به خواننده گرامی یادآوری کنم که این وبلاگ مربوط به سیاست نیست ، بلکه اطلاعات و جستجوی آن در اینترنت است. در این حالت ، البته این موارد بهم آمیخته شده اند. اما ، این مقاله فقط برای برجسته کردن یک اتفاق خارق العاده از جنبه اطلاعاتی است. در حالی که در اطراف PanamaLeaks سر و صدا و کف وجود دارد ، ما سعی خواهیم کرد این رویداد و عواقب آن را تجزیه و تحلیل کنیم.
باید گفت که برداشت وجوه به خارج از کشور ، به عنوان راهی برای جلوگیری از مالیات در کشور شما ، کاملاً جرم محسوب نمی شود. بله - زشت ، بله - نه میهن پرستانه ، بلکه جرم نیست. در آن کشورهایی که مجاز است. درست است ، اما وقتی صحبت از تاجران یا بازیگران می شود ، همانطور که در مورد بازیکن فوتبال لیونل مسی یا بازیگر بدلکاری جکی چان اتفاق می افتد.
(به روز شده)
اگر اطلاعات مربوط به یک نهاد تجاری مورد علاقه یافت شود ، می توانید نظارت خودکار بر تغییرات ثبت را که مربوط به این شرکت یا کارآفرین است ، فعال کنید. اطلاعات به روز شده به ایمیل شما ارسال می شود. توسعه دهندگان خدمات برنامه های خود را برای توسعه پروژه پنهان نمی کنند. برنامه ریزی شده است که اطلاعات تحلیلی را اضافه کنید: مقالات در رسانه ها ، شهرت اشخاص تجاری بر اساس بازخورد از شرکای تجاری ، تجزیه و تحلیل مالی ، احتمال ورشکستگی و غیره
البته هنوز زمان کمی برای نتیجه گیری در مورد کار موتور جستجو گذشته است. ممکن است مشکلات بیشتری وجود داشته باشد. من به عنوان مثال تناقضات مرتبط با مفهوم اسرار تجاری را پیش بینی می کنم. به طور کلی ، ما خواهیم دید که چگونه پروژه توسعه می یابد و برای تلاش شما آرزوی موفقیت می کنیم!
لینک های مربوطه:
youcontrol.com.ua در VKontakte vk.com/public91977868
در فیسبوک www.facebook.com/youcontrol.com.ua
پست الکترونیک [ایمیل محافظت شده]
تلفن 066 189 02 06 +38
خوب ، و ، به طور معمول ، یک ویدیو ، نظرات در مورد آن کاملا غیر ضروری است.
همانطور که منبع یادآوری می کند ، اطلاعات منتشر شده توسط وی تنها نوعی بخش آزمایشی است. مقدار واقعی داده هایی که روزنامه نگاران در اختیار دارند بسیار بیشتر است. بنابراین سخنان نمایندگان کنسرسیوم روزنامه نگاری مبنی بر اینکه دنیای آرام شرکت های فراساحل در انتظار یک "زلزله" واقعی است کاملاً منطقی به نظر می رسد. 

به تازگی ، توسعه دهندگان فرانسوی موتور جستجوی جدید Qwant (qwant.com) را به مخاطبان اینترنت ارائه داده اند. خود فرانسوی ها موتور جستجوی خود را انقلابی می نامند. به گفته یکی از بنیانگذاران ، Qwant یک سیستم جامع و بی طرفانه است. این اطلاعات را بدون ایجاد هرگونه ترجیح جستجو ارائه می دهد.
توسعه Qwant دو سال است که ادامه دارد. همانطور که توسعه دهندگان اعتراف می کنند ، هدف اصلی موتور جستجوی جدید سبقت گرفتن و سبقت گرفتن از بزرگترین موتور جستجوگر Google است. بنابراین ، qwant.com در 13 فوریه 2013 راه اندازی شد. این سیستم در حال آزمایش است و در 35 کشور به 15 زبان در دسترس است.
از جمله ویژگی های جستجوی جدید ، توزیع نتایج یافت شده براساس گروه است. بنابراین ، می توانید اطلاعات را در شبکه های اجتماعی پیدا کنید - این ستون Social است ، یا به عنوان مثال ، از طریق داده های خبرخوان (Live) پیمایش کنید. ستون وب محبوب ترین مقالات را برای درخواست شما نمایش می دهد ، در حالی که ستون خرید اطلاعات تجاری مربوط به کالای درخواستی شما را نشان می دهد.
در وسط صفحه ستون نمودار دانش وجود دارد - در آنجا می توانید شرح کوتاهی از جستجوی خود دریافت کنید - این چیست ، کجا اعمال می شود و غیره - مانند توضیحات در فرهنگ لغت توضیحی. علاوه بر این ، Qwant به درخواست شما خروجی تصویر و فیلم ارائه می دهد. همچنین تفاوت زیادی با موتورهای جستجوی گوگل ، یاندکس و سایر موتورهای جستجو وجود دارد ، جایی که برای مشاهده تصاویر برای جستجوی جستجو باید به یک تب مخصوص بروید.
Qwant را می توان یکی از کاربرپسندترین موتورهای جستجو نامید. تعداد زیادی تنظیمات را برای نمایش راحت تر داده ها برای شما ارائه می دهد. ستون های دسته های شماره را می توان با توجه به موقعیت مکانی آنها در میان خود تغییر داد. به عنوان مثال ، اگر در درجه اول به خط خبر علاقه مند هستید ، می توانید آن را به سمت چپ حرکت دهید تا اولین کسی باشد که مورد توجه قرار گیرد و لیست دارای اطلاعات تجاری تا آنجا که ممکن است به سمت راست منتقل شود.
بیایید کمی از موتور جستجو آزمایش کنیم. بگذارید بگوییم ما به کار مونیکا بلوچی علاقه مند هستیم. ما صفحه شروع qwant.com را باز می کنیم ، که اتفاقاً از نظر طراحی بسیار شبیه Google است. ما در خط وارد "مونیکا بلوچی" می شویم و موارد زیر را می بینیم: در بالای صفحه یک فیلم و عکس از این بازیگر معروف به ما پیشنهاد می شود ، در حالی که می توانید بدون استفاده از فلش ، در بالای صفحه نتایج رسانه را پیمایش کنید برگه با عکس. 
در ستون وب ، پیوندهایی به چندین مرتبط ترین سایت که اطلاعاتی در مورد بلوچی دارند - ویکی پدیا ، KinoPoisk و غیره مشاهده می کنیم. در ستون Live - اخبار مربوط به بازیگر زن (مصاحبه های اخیر ، جلسات عکس و غیره) ، در بخش Social ستون می توانید نظرات مردم در مورد مونیکا بلوچی را از شبکه های اجتماعی مشاهده کنید ، اما در خرید لیستی از سایت هایی را می بینیم که می توانید با مونیکا فیلم خریداری کنید.
همانطور که ملاحظه می کنید ، هدف این سیستم ارائه پاسخ به هرگونه درخواست کاربر است ، بدون اینکه نتیجه ای به کاربر تحمیل شود ، اما آنها را در چندین دسته برای انتخاب ارائه می دهد. خود سازندگان Qwant تأیید می کنند که تأکید اصلی بر بهبود جستجوی اطلاعات در شبکه های اجتماعی محبوب بوده است.

البته ، فناوری های ابری پرداخت می شوند ، زیرا شما از سرورهای شخص ثالث استفاده می کنید. اما چنین خدماتی دارای تعداد زیادی مزیت است ، به ویژه:
مشتری باید فقط برای مبلغ ذخیره سازی در فضای ذخیره سازی که در واقع استفاده می کند ، پرداخت کند و نه برای اجاره سرور.
- مشتری نیازی به خرید ، نگهداری و نگهداری تجهیزات ذخیره سازی خود ندارد ، که هزینه های تولید را بسیار کاهش می دهد.
- کلیه موارد فنی در مورد حفظ یکپارچگی اطلاعات ارسال شده و پشتیبان گیری از داده ها توسط ارائه دهنده انجام می شود ، که نیازی به مشارکت مشتری ندارد.
چرا ذخیره سازی ابر بسیار جذاب است
مطمئناً شما از اشتراک فایل استفاده کرده اید که هنوز تعداد زیادی از آنها وجود دارد. در آنجا می توانید فایل خود را بارگذاری کنید ، که برای هر کاربری که می تواند پرونده شما را با برچسب یا نام پیدا کند در دسترس قرار می گیرد. در مقابل ، فناوری ابر حریم خصوصی کاملی را فراهم می کند. یعنی فقط صاحب اطلاعات می تواند از داده های ارسال شده استفاده کند و او با نام کاربری و رمز ورود خود وارد سیستم می شود.
کاربران عادی عاشق چنین فناوری هایی شدند زیرا اکنون دیگر نیازی به مسدود کردن رایانه با تعداد زیادی اطلاعات قدیمی نیست - در هر رایانه ای همیشه می توانید چندین گیگابایت موسیقی قدیمی پیدا کنید ، که ممکن است روزی هم مفید باشد ، مجموعه ای از فیلم ها قبلاً چندین بار تجدید نظر شده است ، اسنادی که قبلاً چاپ شده و مورد استفاده قرار گرفته اند.
اما ، با این وجود ، همه این اطلاعات باید در جایی ذخیره شود. سرویس های Cloud با ارسال تمام داده های غیرضروری به "cloud" ، فضای مستقیم رایانه را پاک می کنند. تمام کاری که شما باید انجام دهید این است که مایل باشید مقداری هزینه پرداخت کنید و از اینترنت پرسرعت برخوردار باشید.
ویژگی دیگر ذخیره سازی ابری این است که می توانید داده های ذخیره شده را در هر زمان و از هر دستگاهی دریافت کنید. یعنی اگر از طریق یک فیلم "به ابر" فیلم ارسال کردید ، می توانید آن را از طریق لپ تاپ ، تبلت ، تلفن هوشمند به رایانه خود برگردانید ... نکته اصلی این است که رمز عبور داشته باشید و با خود وارد شوید.
کدام فضای ذخیره سازی ابری را باید انتخاب کنید؟
تعداد زیادی سرویس ابری وجود دارد و آنها دائماً در حال پیشرفت هستند و نه تنها فضای ذخیره سازی ، بلکه خدمات مرتبط را نیز ارائه می دهند. در زیر محبوب ترین موارد ذکر شده است.
1. Windows Live SkyDrive - بیشترین فضای سرور را ارائه می دهد. کاربران ثبت نام شده می توانند حداکثر 25 گیگابایت اطلاعات شخصی خود را در فضای ابری بصورت رایگان ذخیره کنند. اسناد اداری بارگذاری شده در فضای ذخیره سازی ابری را می توان در مرورگر ویرایش و باز کرد. همگام سازی را می توان همزمان از چندین دستگاه رایانه ای انجام داد.
2. DropBox یک سرویس کاملاً شناخته شده در بین کاربران عادی است ، اما فقط 2 گیگابایت فضا برای هر مشتری خود ارائه می دهد. اگر از یک حساب پولی استفاده می کنید ، می توانید قابلیت های خود را تا 20 گیگابایت افزایش دهید.

جستجوی نمودار (از این پس GS) نام به روزرسانی فیس بوک (FB) است که اخیراً توسط زاکربرگ اعلام شده و اولین شبکه اجتماعی روی کره زمین را "اجتماعی" می کند. نسخه بتا سرویس جدید تاکنون فقط در بخش انگلیسی زبان فیس بوک راه اندازی شده است. جستجوی "دانش فنی" بعداً در دسترس کاربران روسی زبان شبکه اجتماعی قرار خواهد گرفت ، اما اکنون می توانید حساب خود را به "لیست انتظار" اضافه کنید.
از نظر فنی ، GS سیستمی از فیلترها است که از الگوریتم جستجوی Bing در شبکه اجتماعی استفاده می کند و به شما امکان می دهد افراد ، مکانهای دیدنی ، موسیقی (در به روزرسانی آینده) ، عکسهای مرتبط با علایق Facebook خود را جستجو کنید. برای یک کاربر اجتماعی ، نمودار جستجو مانند یک نوار جستجو در بالای هر صفحه FB به نظر می رسد.
وقتی سوالی وارد خط جستجوی GS می شود ، نتیجه جستجو در یک صفحه جداگانه با نام پرس و جو جمع می شود (به عنوان مثال: "دوستان من در ریو"). برنامه ریزی شده است که براساس "پسندیدن" ، نظرات ، محتوای رسانه ای ، علامت های عکس جستجو شود. تاریخ به روزرسانی بعدی سرویس هوشمند هنوز مشخص نیست.
جستجوی نمودار فیس بوک - چگونه کار می کند؟
توسعه با این بیانیه آغاز شد: برای یک کاربر ، توصیه دوست مهمتر از تخمین هزاران فرد ناشناخته است. بنابراین ، با استفاده از جستجوی نمودار ، می توانید به عنوان مثال پیدا کنید:
عکس های هم دانش آموزان قبل از سال 1995؛
- دوستداران کدو از شهر شما ؛
- عکس های دوستان گرفته شده در اندونزی ؛
- میله های سوشی شهری مورد علاقه دوستان خود ؛
- دیدنی های پراگ یا پاریس ، که توسط دوستان شما بازدید می شود.
دلیل نگرانی یا هشدار نادرست؟
اولین خبر در مورد نمودار جستجو برخی نگرانی ها را در میان کاربران FB ایجاد کرد. بله ، یک سرویس هوشمند از نظر قابلیت جستجو بسیار جذاب است ، اما بسیاری از استفاده از جستجوی اجتماعی توسط شرکت های بازاریابی ، خدمات ویژه ، گروه های جنایی ، سازمان های دولتی و دارندگان بی پروای خدمات اینترنتی برای جمع آوری اطلاعات می ترسند. آیا ترس موجه است؟
از یک طرف ، جستجوی نمودار تنظیمات حریم خصوصی را تغییر نمی دهد ، بنابراین ، فقط کاربران FB که برای آنها باز هستند می توانند داده های خصوصی "بدهند". از طرف دیگر ، شرکت های بین قاره ای ، اینترانت های دولتی و حتی بانک ها از "نشت اطلاعات" رنج می برند. آیا فیس بوک از نظر امنیتی امن است؟ زمان نشان خواهد داد.
تحقیقات بازاریابی به جمع آوری منظم ، نمایش و تجزیه و تحلیل داده ها در مورد جنبه های مختلف فعالیت های بازاریابی اشاره دارد.
تحقیقات بازاریابی عملکردی است که از طریق اطلاعات ، بازاریاب ها را با بازارها ، مصرف کنندگان ، رقبا ، با تمام عناصر محیط بازاریابی خارجی مرتبط می کند.
اطلاعات اولیه اطلاعاتی است که محقق به طور مستقل برای حل مشکل تحقیقات بازاریابی به طور مستقل دریافت می کند.
برای جمع آوری اطلاعات در مورد ترجیحات و ترجیحات مصرف کنندگان متخصصان واجد شرایط در زمینه روش های جمع آوری ، منابع اطلاعات در اینترنت ، از روش پیمایشی استفاده شد.
این نظرسنجی شامل جمع آوری اطلاعات اولیه با پرسیدن مستقیم سوالات از پاسخ دهندگان در مورد سطح دانش ، نگرش به محصول ، تنظیمات ترجیحی و رفتار خرید است.
بسته به نوع پاسخ دهندگان ، یک نظرسنجی با مشارکت گروهی از جمعیت که فعالیت حرفه ای آنها به موضوع تجزیه و تحلیل ارتباط ندارد ، انتخاب شد.
تحقیقات بازاریابی برای شناسایی ویژگی های جستجو و استفاده از اطلاعات در اینترنت انجام شد. مخاطبان این مطالعه جمعیت جمهوری بلاروس زیر 18 سال و بالاتر است. جمع آوری اطلاعات در شهر گومل انجام می شود.
برای تعیین اندازه نمونه مورد نیاز ، از فرمول زیر استفاده شده است:
که n اندازه نمونه است.
z - انحراف نرمال ، تعیین شده بر اساس سطح اطمینان انتخاب شده ؛
p تنوع یافت شده برای نمونه است.
e یک خطای معتبر است.
از این رو ، مقدار تنوع برابر با یک شخص است.
هر تحقیقات بازاریابی با تعریف مشکل شروع می شود. بنابراین ، در تحقیقات ما ، مسئله نیاز به تحقیق به شرح زیر فرموله می شود: «احساسات مصرف کنندگان درباره استفاده و جستجوی اطلاعات در اینترنت چیست؟
س questionsالات جستجو تک تک م componentsلفه های مسئله را روشن می کند ، هر یک از این س canالات به نوبه خود می توانند به م componentsلفه هایی تقسیم شوند - س searchالات جستجو. س questionsالات جستجو دامنه اطلاعات خاصی را تعیین می کند که برای حل مسئله تحقیق مورد نیاز خواهد بود. بنابراین ، س searchالات جستجو در تحقیقات ما می تواند به شرح زیر باشد: 1- چه کسی کاربر موتورهای جستجو است ": جنسیت ، سن ، سطح درآمد ، وضعیت اجتماعی چیست. 2. کاربران کدام موتور جستجو را انتخاب می کنند؟ 3. کاربران بیشتر از چه سایتهایی بازدید می کنند؟ 4- کاربران برای چه هدفی از اینترنت استفاده می کنند؟ 5- چه اطلاعاتی در اینترنت بیشترین جذابیت را دارد؟ بر اساس س questionsالات جستجو ، می توان فرضیه ها را فرموله کرد: 1. کاربران موتور جستجوی گوگل را انتخاب می کنند 2. بیشتر اوقات ، کاربران موتورهای جستجو جمعیت 19-25 ساله هستند 3. کاربران بیشتر از سایت های سرگرمی بازدید می کنند 4. بیشتر کاربران استفاده می کنند اینترنت برای ارتباطات 5. اطلاعات جالب در مورد سرگرمی و تفریح برای کاربران 6. بیشتر کاربران اطلاعات مورد نیاز خود را پیدا می کنند 7. کاربران بیشتر از خانه در اینترنت از اینترنت استفاده می کنند
در سپتامبر - نوامبر 2011 ، یک تحقیق بازاریابی انجام شد ، که طی آن 150 شهروند ساکن شهر Gomel مصاحبه شدند. از پاسخ دهندگان خواسته شد پرسشنامه ای متشکل از 17 سوال را پر کنند. دوره مطالعه 12 هفته است ، با در نظر گرفتن تهیه پرسشنامه و پردازش داده های به دست آمده.
برای شناسایی ترجیحات مصرف کننده ، پرسشنامه ای تهیه شد (ضمیمه A).
در فرآیند تحقیقات بازاریابی ، هنگام مصاحبه با پاسخ دهندگان ، گروه های سنی زیر مصرف کنندگان شناسایی شدند. (شکل 3.1)

شکل 3.1- نمودار توزیع پاسخ دهندگان بر اساس سن
همانطور که از شکل 3.1 مشاهده می شود ، با توجه به معیار سنی ، استفاده از موتورهای جستجو سهم زیادی از پاسخ دهندگانی است که سن آنها در محدوده 19-25 سال است که 35٪ است. شهرونداني كه سن آنها 56 سال به بالا است ، درصد 3 درصد را تشكيل مي دهند. مخاطبان هدف از نظر منطقه فعالیتشان در شکل 3.2 نشان داده شده است.

شکل 3.2 - نمودار توزیع پاسخ دهندگان بر اساس وضعیت اجتماعی
با تجزیه و تحلیل پاسخ های پاسخ دهندگان ، می توان نتیجه گرفت که بخش قابل توجهی از کاربران موتور جستجو کارمندان (36٪) و کارگران (30٪) هستند. پس از آن دانشجویان (17٪) و کارآفرینان (15٪) ، با اندکی اختلاف ، دنبال می شوند.
داده های بدست آمده از سطح درآمد جمعیت در شکل 3.3 ارائه شده است.

شکل. 3.3
شکل 3.3 نشان می دهد که تعداد بیشتری از پاسخ دهندگان نظرسنجی سطح درآمد متوسطی دارند که در بازه زمانی از 1،000،000 تا 2،000،000 روبل است که به 65.3٪ رسیده است. پاسخ دهندگان با سطح پایین درآمد 26.3٪ و با درآمد بالا - 8٪ را تشکیل می دهند.

شکل. 3.4
شکل 3.4 نشان می دهد که تعداد انواع و نام های موتور جستجو بسیار زیاد است. محبوب ترین سیستم ها گوگل هستند. -45٪ و پس از آن Mail.ru ، سپس Yandex-20٪ و Rambler-10٪ در مکان آخر قرار دارند. به طور کلی ، تفاوت زیادی در ترجیحات مصرف کننده Google ، Mail.ru ، Yandex و Rambler مشاهده شده است.

شکل. 3.5
شکل 3.5 نشان می دهد که سایتهایی که بیشتر از دیگران بازدید می شوند ، سرگرمی هستند - 35٪ ، سپس اطلاعاتی - 33٪ ، سپس شرکت ها - 25٪ و دیگری - 7٪

شکل. 3.6
شکل نشان می دهد که اکثر پاسخ دهندگان مورد بررسی از موتورهای جستجو استفاده می کنند - 90.2٪

شکل. 3.7
با توجه به نتایج مطالعه ، مشخص شد که برای 61٪ از پاسخ دهندگان ، موتور جستجو یک وسیله ارتباطی مناسب است ، برای 34٪ یک روش ساده موثر برای یافتن اطلاعات و برای 5٪ چیز دیگری است. ساختار پاسخ ها به وضوح در شکل 3.7 نشان داده شده است.

شکل. 3.8
این مطالعه اطلاعات مربوط به دفعات استفاده از اینترنت را ارائه داده است ، جایی كه مصرف كنندگانی كه روزانه به اینترنت مراجعه می كنند 74٪ ، 3-4 بار در هفته - 16٪ و 3-4 بار در ماه است -10 ساختار پاسخ ها به وضوح نشان داده شده است در شکل 3.8 نشان داده شده است

شکل. 3.9
همانطور که از شکل 3.9 دیده می شود ، اکثر پاسخ دهندگان از اینترنت در خانه (75٪) ، 16٪ در محل کار ، 5٪ در هنگام بازدید و 4٪ در کافی نت استفاده می کنند.
شکل. 3.10
شکل 3.10 نشان می دهد که پاسخ دهندگان اغلب از اینترنت برای برقراری ارتباط (48٪) و همچنین جستجوی اطلاعات (26٪) ، مشاهده اخبار (19٪) و نامه (7٪) استفاده می کنند.

شکل. 3.11
با توجه به نتایج مطالعه ، مشخص شد 44٪ از پاسخ دهندگان بیشترین علاقه را به اطلاعات در مورد تفریح و سرگرمی دارند - 44٪ ، اینترنت -42٪ ، تجارت 31٪ ، رایانه 29٪ ، جامعه 27٪ ، علوم و آموزش 25 ٪ ، فرهنگ و هنر 20٪ ، دارو و بهداشت 19٪ ، خانه و خانواده 18٪. ساختار پاسخ ها به وضوح در شکل 3.11 نشان داده شده است.

شکل. 3.12 - نمودار توزیع پاسخ دهندگان با پاسخ به س questionال: "آیا شما موفق به یافتن اطلاعات موردنیاز خود در اینترنت می شوید؟" ،٪
شکل 3.12 نشان می دهد که تعداد بیشتری از پاسخ دهندگان نظرسنجی همیشه اطلاعات مورد نظر خود را پیدا می کنند -52٪ ، سپس اغلب -33٪ ، به ندرت -12٪ ، هرگز 3٪ پیدا می کنند.
بنابراین ، در طول بررسی ، ترجیحات مصرف کننده زیر نشان داده شد: اکثر پاسخ دهندگان موتور جستجو مانند Google را ترجیح می دهند ، در حالی که استفاده از Mail.ru فاصله زیادی بین آنها ندارد (5 ،٪).
35٪ از نمونه ها اغلب از سایت های سرگرمی بازدید می کنند. 58٪ از مصرف کنندگان هر روز از اینترنت بازدید می کنند ، اما همانطور که تجزیه و تحلیل نشان داده است ، بازدیدها روزانه افزایش می یابد. و پیش بینی رشد آینده پیش بینی شده است. بنابراین ، توسعه دهندگان موتور جستجو باید:
بهبود الگوریتم های جستجو (یا توسعه استراتژی های جدید جستجو) ، و "زنگ ها و سوت های" مرتبط مانند طراحی و خدمات اضافی.
تجزیه و تحلیل سeriesالات (سوالات) مطرح شده به زبان طبیعی را ارائه دهید.
موتورهای جستجو فایلهای CSS خارجی را فهرست می کنند.
اندازه سند یا اندازه بخشی که نمایه خواهد شد را افزایش دهید
تجزیه کنندهآیا برنامه ای برای اتوماسیون فرآیند تجزیه است ، یعنی پردازش اطلاعات با توجه به الگوریتم خاصی. در این مقاله چند نمونه از برنامه های تجزیه کننده آورده و به طور خلاصه هدف و عملکرد اصلی آنها را شرح می دهم.
تجزیه کننده محتوای X-Parser
توابع اصلی برنامه نیز از چندین بلوک برنامه تشکیل شده است.
- تجزیه و تحلیل موتورهای جستجو برای سeriesالات کلیدی
- تجزیه و تحلیل مطالب از هر سایتی
- تجزیه کننده محتوا برای س quالات کلیدی از نتایج هر موتور جستجو
- تجزیه کننده محتوا برای لیستی از URL ها
- تجزیه کننده پیوند داخلی
- تجزیه کننده پیوندهای خارجی
برنامه WebParser
تجزیه کننده WebParser یک برنامه همه کاره است. عملکرد اصلی آن تجزیه موتورهای جستجو است. با PS Google ، Yandex ، Rambler ، Yahoo و برخی دیگر کار می کند. موتورهای سایت (CMS) را تجزیه و تحلیل می کند. سازگار با تمام نسخه های ویندوز از W2000. اطلاعات کامل Bolle.
پلاگین WP Uniparser
فراموش نکنیم و پلاگین برای WordPress WP Uniparser... با دنبال کردن این لینک می توانید اطلاعات بیشتری در مورد آن کسب کنید.
پارسر "مگادان"
تجزیه کننده کلمه کلیدی با نام عاشقانه "Magadan" به طور خاص برای پردازش هدفمند کلمات کلیدی Yandex.Direct ایجاد شده است. برای تدوین هسته معنایی ، تهیه کمپین های تبلیغاتی و جمع آوری و تجزیه و تحلیل اطلاعات مفید است.
در پایان ، قابل ذکر است زبان برنامه نویسی برای ایجاد سایت های Parser، ایجاد شده در استودیوی Artemy Lebedev و در خدمت توسعه سایت ها. این زبان تا حدودی پیچیده تر از HTML معمولی است ، اما به همان اندازه که به عنوان مثال PHP احتیاج ندارد.
معرفیاینترنت مانند یک کتابخانه عظیم جهانی است ، که فقط یک تفاوت دارد ، اما تفاوت قابل توجهی: برای جستجوی کتاب در کتابخانه ، یک کاتالوگ وجود دارد ، به عنوان آخرین چاره ، می توانید به یک کتابدار باتجربه مراجعه کنید. هیچ کاتالوگ کاملی از اینترنت وجود ندارد. اما ، جستجو در شبکه رایانه ای جهانی امکان پذیر است و شاید این یکی از مهمترین جنبه های آن باشد. برای جستجوی داده ها در شبکه ، از سرورهای ویژه ای استفاده می شود که اطلاعات مربوط به آنها تقریباً به صورت خودکار حفظ و به روز می شود.
امروزه که اینترنت به یکی از منابع اصلی اطلاعات تبدیل شده است ، جستجوی اینترنت هرچه بیشتر ارزش عملی پیدا می کند. اما با افزایش سریع مقدار داده های موجود ، روش جستجو خود پیچیده و پیچیده می شود.
اینترنت یک شبکه رایانه ای جهانی است که هم کاربران شبکه رایانه و هم کاربران رایانه را به هم متصل می کند. اینترنت به آرامی اما مطمئناً به اصلی ترین وسیله ارتباطی شرکت ها تبدیل می شود و جای خود را به تلفن می دهد.
منابع عظیمی از اطلاعات در وب وجود دارد. طبق برخی تخمین ها ، تعداد اسناد از 65 میلیون سند گذشته است و به سرعت در حال رشد است. چنین حجم اطلاعاتی نیاز به سازماندهی صحیح فرآیند جستجو و استفاده از ابزارهای فنی ویژه مانند موتورهای جستجو دارد. یک جستجوی ساده برای یک کلمه کلیدی نسبتاً معمول معمولاً از ده ها هزار تا چندین میلیون پیوند دارد. بدیهی است که کار با این تعداد زیاد اسناد عملاً غیرممکن است ، خصوصاً اینکه اکثریت قریب به اتفاق آنها حاوی اطلاعاتی هستند که بی ربط هستند.
منابع اطلاعات در اینترنت در نحوه ارائه اطلاعات و در نتیجه در روش دسترسی به آنها متفاوت است.
1 ابزار جستجو
1.1 ابزار جستجوی پرونده
یافتن فایل به صورت دستی در ساختار دایرکتوری پیچیده سرور ftp می تواند مدت ها طول بکشد. برای ساده سازی و سرعت بخشیدن به جستجو ، سرویس جستجوی اینترنتی Archie ایجاد شد که یک سرور ویژه Archie است که محتوای دایرکتوری های سرورهای ناشناس ftp را ذخیره می کند. هنگام آدرس دهی به یک جستجوی جستجو در سرور Archie ، نتیجه جستجو لیستی از آدرس های سرورهای ftp ناشناس است که فایل مورد نظر را دارند.
اما این وظیفه پیدا کردن یکی از موارد دلخواه در این سرور است که به دلیل نامشخص بودن و نامفهوم بودن پرونده ها و دایرکتوری ها بسیار دشوار است. برای حل این مشکل ، از سیستم Gopher استفاده شده است ، که به شما امکان می دهد از طریق سیستم منوهای زمینه ای که محتوای فایل ها را با استفاده از نمادهای قابل فهم نشان می دهد ، حرکت کنید. بسیاری از سرورهای Gopher وجود دارند که حاوی بایگانی از داده ها در قالب فهرست های ساختار سلسله مراتبی هستند که براساس محتوا مرتب شده اند. کار با آنها بسیار ساده است و مربوط به کار با نمایشگر سیستم فایل معمولی است.
پسوندی از این سیستم وجود دارد - Veronica ، که شامل دایرکتوری تمام سرورهای Gopher در پایگاه داده آن است. پس از ورود به یک جستجوی جستجو ، Veronica به طور خودکار تمام دایرکتوری های Gopher را برای اطلاعاتی که به دنبال آن هستید اسکن می کند ، در نتیجه نیازی به جستجوی دستی بسیاری از سرورهای Gopher نیست.
با این روش پیمایش ، Gopher تا حدی پیشگام WWW بود. در حال حاضر ، متناسب با افزایش استفاده از WWW ، استفاده از Gopher در حال کاهش است.
1.2 ابزار WWW - WorldWideWeb
در سال 1993 ، سیستم بازیابی اطلاعات WWW ایجاد شد که به دلیل سهولت در ناوبری و دسترسی ، منابع اطلاعاتی اینترنت را به روی کاربران غیرآماده باز کرد. WWW باعث رونق اینترنت شده است که تا به امروز ادامه دارد و هر سال میزان اطلاعات موجود در اینترنت دو برابر می شود.
WWW مبتنی بر اصل ابرمتن (که قبلاً برای خواننده آشنا بوده است) استوار است ، یعنی بر اساس سیستمی از اسناد مرتبط با هایپر لینک است. Hypertext روش ویژه ای برای برجسته سازی کلمات کلیدی از متن معمولی است. پیوندهای ابر متن کاربر را به اسناد دیگر در همان سرور یا سرورهای دیگری که می توانند در هر نقطه از اینترنت قرار بگیرند ، ارسال می کنند. اگر این سند متن نیز دارای ابر متن باشد ، پیوندهای آن به شما امکان می دهد که بیشتر به اسناد مربوطه بروید. هر تغییر مسیر برای کاربر به طور نامحسوس اتفاق می افتد ، به طوری که او می تواند بدون نگرانی در مورد آدرس دهی به رایانه های خاص ، ترکیب اطلاعات اینترنت را به طرز معنی داری مشاهده کند.
با توسعه برنامه های چندرسانه ای ، در ابتدا اسناد کاملاً متن فوق العاده به طور فزاینده ای به ابر رسانه تبدیل می شوند. بنابراین ، اسناد WWW می توانند در هر قالب داده ای وجود داشته باشند: متن ، گرافیک ، صدا / موسیقی یا کلیپ ویدیویی. جهت گیری و پیمایش در شبکه جهانی وب با استفاده از برنامه های خاصی به نام WWW-مرورگرها که رابط کاربری مانند NetscapeNavigator یا MicrosoftInternetExplorer را فراهم می کنند ، رخ می دهد.
نقطه شروع جستجو برای اطلاعات ، به طور معمول ، صفحه اصلی (پایگاه ، صفحه اصلی) (سایت) منبع اطلاعات است که با وارد کردن آدرس مربوطه در مرورگر می توانید به آن دسترسی پیدا کنید (به عنوان مثال http: // ncpi .gov.by یا www.iparegistr.com). سایت های WWW توسط شرکت ها یا سازمان های ویژه ای که اطلاعات را منتشر می کنند و محتوای سایت های WWW خود را نظارت می کنند ، ایجاد و به روز می کنند. بنابراین ، استفاده از WWW انفعالی نیست و هر کاربر اینترنت با کمک برنامه های ویژه ویرایشگر ابر متن می تواند به طور مستقل صفحات WWW تعاملی خود را ایجاد کند. این زمینه را برای تجارت فزاینده و گسترش اینترنت فراهم کرد.
در حال حاضر ، اطلاعات تازه ایجاد شده ، به عنوان یک قاعده ، با در نظر گرفتن نیاز به دسترسی به WWW تولید می شود و اسناد قبلی به تدریج برای آن تبدیل می شوند ، اما در سراسر جهان هنوز میلیون ها پرونده به اشکال غیر از WWW وجود دارد. برای استفاده از این اطلاعات و از طریق WWW ، خدمات اینترنتی فوق در مرورگرهایی که دسترسی به آن را فراهم می کنند (telnet ، ftp ، Archie ، Gopher) گنجانده شده است. از طریق WWW می توانید از سایر سرویس های اینترنتی که برای برقراری ارتباط استفاده می شوند نیز استفاده کنید (پست الکترونیکی ، NetNews). بنابراین ، مرورگر WWW اکنون به یک برنامه ارتباطی جهانی برای اینترنت تبدیل شده است.
با ظهور سرویس WWW ، رونق اینترنت آغاز شد. این محیط کاربری آسان و کاربرپسند برای همه سرویس ها توجه بسیاری از افراد و سازمان ها را در اینترنت جلب کرده است. ناگهان مشخص شد که شما برای استفاده از خدمات شبکه نیازی به متخصص اینترنت ندارید. این را می توان با موفقیت مایکروسافت در انتشار Microsoft Windows به عنوان یک رابط کاربری گرافیکی مقایسه کرد. قبل از ظهور ویندوز ، هر برنامه DOS کتابچه راهنمای کاربر خود را داشت و بنابراین نیاز به مطالعه جداگانه هر برنامه داشت.
2 روش اساسی برای یافتن اطلاعات در اینترنت
2.1 الزامات اساسی برای جستجو
برای کامل بودن پوشش منابع ، قابلیت اطمینان اطلاعات به دست آمده ، حداقل زمان مورد نیاز و حداکثر سرعت جستجو ، الزاماتی به نتایج جستجو اعمال می شود.
نیاز به کامل بودن پوشش منابع نیازی به توضیحات اضافی ندارد ، مگر اینکه نیاز به استفاده از منابع نه تنها از WWW برای جستجوها ، بلکه از سایر خدمات اینترنت نیز باشد.
قابلیت اطمینان اطلاعات ، با توجه به ماهیت اینترنت ، در حال تبدیل شدن به یک نیاز فوق العاده مهم است. ارزیابی قابلیت اطمینان می تواند هم با روش های سنتی (بررسی قانونی بودن انتشارات روی کاغذ ، کسب اطلاعات در مورد سازمان ها و نویسندگان ، یافتن اعتبار منابع الکترونیکی آنها و غیره) و هم با استفاده از امکانات اینترنت (آشنایی با منابع اطلاعاتی جایگزین ، سازگاری مطالب واقعی ، ایجاد تعداد دفعات استفاده از آن توسط سایر منابع ؛ پیدا کردن وضعیت سند و رتبه بندی منبع توسط موتورهای جستجو ، کسب اطلاعات در مورد صلاحیت و وضعیت نویسنده از مطالب با استفاده از خدمات جستجوی اینترنتی ویژه ؛ تجزیه و تحلیل عناصر فردی سازمان سایت به منظور ارزیابی صلاحیت متخصصان پشتیبانی کننده آن و موارد دیگر).
زمان جستجو ، بدون احتساب زمان صرف شده برای مشخصات اتصال ، بستگی زیادی به برنامه ریزی جستجو و مهارت متخصص جستجو با نوع انتخاب منبع دارد. برنامه ریزی جستجو عبارت است از تعیین خدمات جستجوی لازم برای حل یک درخواست جستجو و ترتیب اعمال آنها. علاوه بر این ، بسیاری از موارد به مهارت و تجربه متخصص جستجوی فردی بستگی دارد.
همانطور که قبلاً اشاره شد ، اطلاعات در اینترنت از انواع مختلف منابع در دسترس است. اول از همه ، این منابع WWW هستند (سیستم ابر متن ، کاتالوگ منابع ، موتورهای جستجو). علاوه بر این ، از قبل برای ایمیل خوانندگان ، ربات های پستی ، Usenet و سایر گروه های خبری ، و همچنین سیستم های ftp و بایگانی ها (با استفاده از Gopher و Veronica) شناخته شده است. WWW به شما این امکان را می دهد تا منابع مورد نیاز را بر اساس بیش از حد خواص خود جستجو کنید ، یعنی موتورهای جستجوی موجود با استفاده از هایپر لینک در حالت خودکار کار می کنند ، بدون اینکه امکان مرور دستی را حذف کنید. WWW دارای تعدادی سرویس جستجوی عمومی و تخصصی است.