Quel est le noyau sémantique du site? Noyau de site sémantique (ci-après dénommé SIA) - Ceci est une combinaison de mots-clés et de phrases par quelle ressource promotion dans les moteurs de recherche et qui indiquent l'affiliation du site à un certain sujet.
Pour une promotion réussie dans les moteurs de recherche, les mots-clés doivent être correctement regroupés et distribués via les pages du site et dans un certain formulaire à contenir dans les méta-descriptions (,,, Mots-clés), ainsi que dans les titres H1-H6. Dans le même temps, il est impossible de permettre le remplacement afin de ne pas "s'envoler" à Baden-Baden.
Dans cet article, nous essaierons de regarder la question non seulement d'un point de vue technique, mais également de regarder le problème des yeux des propriétaires d'entreprise et des spécialistes du marketing.
Qu'advient-il de collecter?
- Main - Peut-être pour de petits sites (jusqu'à 1000 mots-clés).
- Automatique - Les programmes ne définissent pas toujours correctement le contexte de la demande. Il peut donc y avoir des problèmes de distribution de mots-clés sur les pages.
- Semi-automatique - Les phrases et la fréquence sont collectées automatiquement, la distribution de phrases et de raffinement se produit manuellement.
Dans notre article, nous examinerons une approche semi-automatique de la création d'un noyau sémantique, car il est plus efficace.
En outre, il y a deux cas typiques lors de la rédaction:
- pour le site avec la structure finie;
- pour le nouveau site.
Plus préférable est la deuxième option, car il est possible de créer la structure idéale du site sous le moteur de recherche.
Quel est le processus d'élaboration?
Le travail sur la formation du noyau sémantique est divisé en étapes suivantes:
- Allocation de zones pour lesquelles le site se déplacera.
- Recueillir des mots-clés, une analyse de demandes similaires et de conseils de recherche.
- Analyse de fréquence, demandes "vides".
- Clustering (regroupement) Demandes.
- Distribution des demandes sur les pages du site (rédaction de la structure de site parfaite).
- Recommandations à utiliser.
Mieux vous composez le noyau du site et la qualité dans ce cas signifie l'ampleur et la profondeur de l'étude de la sémantique, le flux de recherche plus puissant et fiable de la circulation de recherche peut être capable d'envoyer au site et d'attirer les clients plus importants. .
Comment faire un noyau de site sémantique
Considérons donc chaque article avec divers exemples plus en détail.
Dans la première étape, il est important de déterminer quelles biens et services présents sur le site se déplaceront dans la recherche de Yandex et de Google.
Exemple numéro 1. Supposons que sur le site, il existe deux directions de services: réparation d'ordinateurs à la maison et à la formation avec Word / Exel à la maison. Dans ce cas, il a été décidé que la formation n'est plus en demande. Cela n'a donc aucun sens de promouvoir, ce qui signifie de collecter une sémantique à ce sujet. Un autre point important, vous devez collecter non seulement des demandes contenant "Réparation d'ordinateurs à la maison", mais aussi "Réparation d'ordinateurs portables, réparation PC" et d'autres.
Exemple numéro 2. La société est engagée dans une construction à faible hauteur. Mais en même temps ne construit que des maisons en bois. En conséquence, demandes et sémantiques dans les directions "Construction de maisons d'un béton aéré"ou alors "Construction de maisons de briques"vous ne pouvez pas collectionner.
Collection de sémantique
Nous examinerons deux sources principales de mots-clés: Yandex et Google. Nous vous dirons comment collecter la sémantique gratuitement et brièvement des services payants qui vous permettent d'accélérer et d'automatiser ce processus.
À Yandex, la collecte des phrases clés est effectuée à partir du Yandex. Avordstat Service et Google à travers les statistiques des demandes de Google AdWords. Si vous avez des sources de sémantique supplémentaires, vous pouvez utiliser Yandex Webmaster Data et Yandex Metrics, Google Webmaster et Google Analytics.
Collectionner des mots-clés de yandex.sordstat
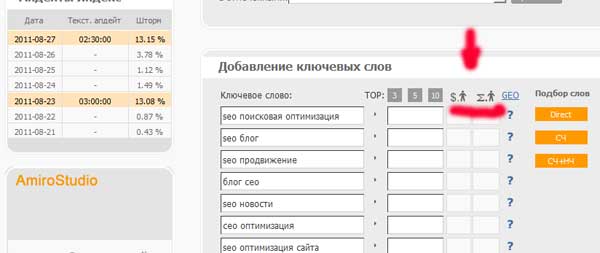
La collecte de demandes de Vordstat peut être considérée comme gratuite. Pour voir ce service, vous avez seulement besoin d'un compte dans Yandex. Alors allez à wordstat.yandex.ru.et entrez un mot-clé. Considérons un exemple de sémantique collectant pour une société de location de voitures.

Que voyons-nous dans cette capture d'écran?
- Colonne de gauche. La demande principale et ses différentes variations avec "Queue."En face de chaque requête coûte un nombre montrant combien cette demande dans général Il a été utilisé par divers utilisateurs.
- Colonne de droite. Les demandes sont similaires aux principaux et aux indicateurs de leur fréquence globale. Nous voyons ici qu'une personne qui veut louer une voiture, à l'exception de la demande "location de voiture",peut utiliser "Louer une voiture", "Location de voitures", "Location de voitures"et d'autres. Ce sont des données très importantes pour faire attention à ne manquer aucune demande.
- Régionalité et histoire. En sélectionnant l'une des options possibles, vous pouvez vérifier la distribution des demandes par région, le nombre de demandes dans une région ou une ville distincte, ainsi qu'une tendance vers des changements dans le temps ou avec un changement de l'année.
- Dispositifsà partir de laquelle la demande a été faite. Onglets de commutation, vous pouvez déterminer quels périphériques recherchent le plus souvent.
Vérifiez différentes options pour les phrases clés et les données reçues sont fixées à la table Exel ou dans les tables de Google. Pour plus de commodité, installez le plugin Yandex WordStat Helper. Après son installation, les plus apparaîtront à côté des phrases de recherche, lorsque vous cliquez sur lequel les mots seront copiés, il ne sera pas nécessaire d'allouer et d'insérer manuellement l'indicateur de fréquence.
Recueillir des mots-clés à partir de Google AdWords
Malheureusement, Google a une source ouverte de requêtes de recherche avec leurs indicateurs de fréquence, il est donc nécessaire d'agir ici par la solution de contournement. Et pour cela, nous avons besoin d'un compte de travail dans Google AdWords.
Nous enregistrons un compte sur Google AdWords et reconstituons le solde du montant le plus bas possible - 300 roubles (sur un compte rendu inactif du budget de compte, des données approximatives sont affichées). Après cela, nous allons dans les "outils" - le "planificateur de mots-clés".

Une nouvelle page s'ouvrira dans la "recherche de nouveaux mots-clés sur l'onglet Phrase, Site ou catégorie", entrez un mot-clé.

Faites défiler vers le bas, appuyez sur «Obtenir des options» et voyez une telle image.

- La demande principale et les requêtes moyennes par mois. Si le compte n'est pas payé, vous verrez des données approximatives, c'est-à-dire le nombre moyen de demandes. Lorsqu'il existe des fonds sur le compte, des données précises seront affichées, ainsi que la dynamique de la variation de la fréquence de la clé entrée.
- Mots clés sur la pertinence. C'est la même chose que des demandes similaires à Yandex WordStat.
- Téléchargement de données. Cet outil est pratique car les données obtenues peuvent être téléchargées.
Nous avons examiné le travail avec deux sources principales de statistiques sur les requêtes de recherche. Maintenant, passons à l'automatisation de ce processus, car la collection sémantique prend manuellement trop de temps.
Programmes et services pour la collecte de mots-clés
Collecteur de clés.
Le programme est installé sur l'ordinateur. Le programme comprend des comptes de fonctionnement d'où les statistiques seront collectées. Ce qui suit est un nouveau projet et un dossier mot-clé.
Sélectionnez la "collection par lots de mots de la colonne de gauche yandex.wordstat", entrez les demandes pour lesquelles les données sont en collectant.

Dans la capture d'écran, un exemple a été introduit, en fait, pour un souriant plus complet, il est également nécessaire de collecter toutes les options de requête avec des timbres et des classes de voiture. Par exemple, "BMW pour la location", "Achetez Toyota avec le droit de rédemption", "Location de SUV" et ainsi de suite.
Slobel
Analogique gratuit programme précédent. Cela peut être considéré comme un plus - pas besoin de payer et moins - le programme a une fonctionnalité nettement coupée.
Pour collecter des mots-clés, les actions sont les mêmes.
Rush-analytics.ru.
Un service en ligne. Son principal avantage - vous n'avez rien à télécharger et à installer. J'ai inscrit et utilisez. Le service est payé, mais lors de votre inscription sur votre compte, 200 pièces sont suffisantes pour collecter une petite sémantique (jusqu'à 5000 demandes) et résoudre la fréquence.
Moins - Collection Sémantique uniquement de WordStat.
Vérifiez la fréquence des mots-clés et des demandes

Et encore une fois, remarquez une diminution du nombre de demandes. Nous allons plus loin et essayons une autre forme de mot de la même demande.

Nous notons que dans le singulier, cette demande recherche un nombre beaucoup plus petit d'utilisateurs, ce qui signifie que la demande initiale pour nous est plus prioritaire.
De telles manipulations doivent être faites avec chaque mot et par phrase. Ces requêtes dans lesquelles la fréquence finale est zéro (avec l'utilisation de citations et une marque d'exclamation), sont tamisées, car "0" - suggère que personne ne introduit de telles demandes et ces demandes ne font que partie des autres. Le sens de la préparation du noyau sémantique consiste à sélectionner des demandes qui utilisent des personnes à rechercher. Toutes les demandes sont ensuite placées dans la table Exel, sont regroupées par la signification et sont distribuées via les pages du site.

Dans le manuel, il n'est tout simplement pas réel, donc sur Internet, de nombreux services sont payés et gratuits, ce qui vous permet de le faire automatiquement. Nous donnons quelques-uns:
- megaindex.com;
- rush-analytics.ru;
- outils.pixelplus.ru.;
- key-collector.ru.
Supprimer les demandes non ciblées
Après avoir cherché des mots-clés, vous devez supprimer les inutiles. Quelles requêtes de recherche peuvent être supprimées de la liste?
- demandes avec les noms des entreprises des concurrents (vous pouvez quitter B);
- demandes de biens ou de services que vous ne vendez pas;
- demandes où la zone est spécifiée ou la zone dans laquelle vous ne travaillez pas.
Demandes de clustering (regroupement) Demandes de site de site
L'essence de cette étape consiste à combiner des demandes similaires aux grappes de la signification similaires, puis déterminez les pages qu'ils déplaceront. Comment comprendre les demandes de promotion d'une page et de quoi d'autre?
1. Par type de demande.
Nous savons déjà que tout le monde est divisé en plusieurs espèces, en fonction du but de la recherche:
- commercial (achat, vente, commande) - Déplacer vers des pages d'atterrissage, page des catégories de produits, cartes de marchandises, pages avec services, pages de prix;
- informations (où, comment, pourquoi, pourquoi) - articles, thèmes des forums, en rubrique la réponse à la question;
- navigation (téléphone, adresse, nom de marque) - page avec contacts.
Si vous doutez de quel type de demande, entrez sa chaîne de recherche et analysez l'émission. Pour une demande commerciale, il y aura plus de pages avec une suggestion de services, sur l'information - Articles.
Il y a aussi. La plupart des demandes commerciales sont de la région géographique, car les gens font principalement confiance aux entreprises de leur ville.
2. Logique de requête.
- "Acheter iPhone X" et "prix iPhone x" - vous devez promouvoir une page, comme dans les premier et second cas, le même produit est recherché et des informations plus détaillées à ce sujet;
- "Acheter iPhone" et "Achetez l'iPhone x" - Vous devez promouvoir différentes pages, car dans la première demande, nous traitons avec une demande commune (adaptée à la catégorie de produits, où les iPhones sont localisés) et dans la seconde, l'utilisateur est Vous recherchez un produit spécifique et cette demande suit la promotion de la carte de biens;
- "Comment choisir un bon smartphone" - Cette demande est plus logique pour promouvoir l'article du blog avec le nom approprié.
Voir les résultats de la recherche sur eux. Si, vérifiez quelles pages de différents sites sont des demandes de renseignements "Construction de maisons d'un bar" et "Construction de maisons de briques", puis dans 99% des cas, ce sont des pages différentes.
4. Regroupement automatique avec logiciel et raffinement manuel.
Les 1er et 2e méthodes conviennent parfaitement à la préparation du noyau sémantique des petits sites, où un maximum de 2-3 mille mots-clés a été collecté. Pour de gros sourire (de 10 000 à l'infinité des demandes), vous devez aider les machines. Voici quelques programmes et services qui vous permettent d'effectuer une clusterisation:
- KeyAssistant - Assistant.contentmonster.ru;
- semparser.ru;
- juste-magic.org;
- rush-analytics.ru;
- outils.pixelplus.ru.;
- key-collector.ru.
Après l'achèvement du clustering automatique, il est nécessaire de vérifier le résultat du travail du programme dans le manuel et si des erreurs sont faites - pour corriger.
Exemple: Le programme peut envoyer les demandes suivantes à un cluster: «Rest in Sochi 2018 Hotel» et «Sinki 2018 Hotel Breeze» - dans le premier cas, l'utilisateur recherche diverses options d'hébergement et dans la seconde, un hôtel spécifique. .
Pour exclure la survenue de telles inexactitudes, il est nécessaire de tout vérifier manuellement et lorsque des erreurs sont détectées, éditer.
Que faire ensuite, après avoir élaboré le noyau sémantique?
Basé sur le noyau sémantique collecté, alors nous:
- nous faisons une structure idéale (hiérarchie) du site, du point de vue des moteurs de recherche;
ou alors En coordination avec le client, nous modifions la structure de l'ancien site; - nous écrivons des tâches techniques pour les rédacteurs pour écrire du texte en tenant compte de la cluster de demandes qui seront promues dans ces pages;
ou alors Nous affinons de vieux textes d'articles sur le site.
Cela ressemble à ceci.

Dans chaque cluster de demande, nous créons une page sur le site et la définit une place dans la structure du site. Les demandes les plus populaires sont promues aux pages les plus hautes de la hiérarchie des ressources, les plus populaires sont situées sous eux.
Et pour chacune de ces pages, nous avons déjà collecté des demandes de renseignements que nous allons les promouvoir. Ensuite, écrivez tk rédacteurs pour effectuer un texte pour ces pages.
Tâches techniques pour le rédacteur
Comme dans le cas de la structure du site, nous décrivons cette étape en termes généraux. Donc, tâche technique pour le texte:
- le nombre de caractères sans espace;
- titre de la page;
- sous-titres (s'il y a);
- liste des mots (basé sur notre noyau), qui devrait être dans le texte;
- exigence d'unicité (nécessite toujours 100% unicité);
- style de texte souhaité;
- autres exigences et souhaits dans le texte.
N'oubliez pas que je n'ai pas besoin d'essayer de promouvoir une page +100500 demandes, limiter la queue de 5-10 +, sinon vous obtiendrez une interdiction de surmonter et de ramper du jeu en haut.
Production
La compilation du noyau sémantique du site est la minutie et le travail acharné, ce qui doit être payé à une attention particulière, car c'est qu'il est basé sur la promotion ultérieure du site. Suivez la simple instruction donnée dans cet article et agir.
- Sélectionnez le sens de la promotion.
- Collectez toutes les demandes possibles de Yandex et de Google (utilisez des programmes et des services spéciaux).
- Vérifiez la fréquence des demandes et éliminez les sucettes (qui ont une fréquence - 0).
- Supprimer les demandes non ciblées - Services et biens que vous ne vendez pas, la demande avec la mention des concurrents.
- Former les clusters de demande et les distribuer via les pages.
- Créez une structure de site idéale et faites un TK sur le remplissage du site.
Le noyau sémantique est un joli thème de paris, non? Aujourd'hui, nous la réparerons ensemble en collectant une sémantique dans cette leçon!
Ne crois pas? - Regardez vous-même - il suffit de conduire à Yandex ou à la phrase Google le noyau sémantique du site. Je pense qu'aujourd'hui, je vais réparer cette erreur agaçante.
Mais en fait, qu'est-ce qu'elle est pour vous - sémantique parfaite? Vous pourriez penser que pour une question stupide, mais en fait, il est complètement Néhall, la plupart des maîtres Web-maîtres et des propriétaires de sites Web estiment qu'ils peuvent faire des noyaux sémantiques et que tout écolier va faire face à tout cela, oui, ils essaient eux-mêmes d'enseigner aux autres ... Mais en fait, tout est beaucoup plus difficile. Une fois que je me suis demandé - que dois-je faire au début? - site et contenu ou noyau SEZ, et a demandé à une personne qui ne se considère pas un nouveau venu dans le PDG. C'est la question et m'a donné pour comprendre la complexité et l'ambiguïté de ce problème.
Le noyau sémantique est la base de la base - la toute première chambre qui se tient avant et lancant une campagne publicitaire sur Internet. Parallèlement, la sémantique du site est le processus le plus vigoureux qui nécessitera beaucoup de temps, mais avec plus de merci en tout cas.
Bien ... Créons le sien ensemble!
Petite préface
Pour créer un champ sémantique du site, nous aurons besoin d'un seul programme - Collecteur de clés.. Sur l'exemple du collecteur, je vais trouver un exemple de collecte d'un petit groupe. En plus du programme rémunéré, il existe également des analogues gratuits tels que Slobel et d'autres.
La sémantique recueillie dans plusieurs étapes de base, parmi lesquelles devrait être allouée:
- brainstorming - Analyse des phrases de base et de la formation de l'analyse
- analyse - expansion de la sémantique de base basée sur VORDSTAT et d'autres sources
- ouverture - chute après l'analyse
- analyse - Analyse de la fréquence, de la saisonnalité, de la concurrence et d'autres indicateurs importants
- raffinement - Grapping, séparation des expressions commerciales et d'information NUCLEUS
Les étapes les plus importantes de la collecte et seront discutées ci-dessous!
Vidéo - Compilation du noyau sémantique des concurrents
Brainstorming lors de la création d'un cerveau de souche de noyau sémantique
À ce stade, il est nécessaire en tête pour faire une sélectionle noyau sémantique du site et propose autant de phrases que possible sous notre sujet. Alors, lancez le collecteur Kay et choisissez analyse de wortstat, comme indiqué dans la capture d'écran:

Nous avons une petite fenêtre, où vous devez introduire un maximum de phrases sur notre sujet. Comme je l'ai déjà dit, Dans cet article, nous créerons un exemple de jeu de phrases pour ce blogDonc, des phrases peuvent être les suivantes:
- blog de référencement
- blog de référencement
- blog sur SEO
- blog sur SEO.
- promotion
- promotion projet
- promotion
- promotion
- promotion des blogs
- blog Promotion
- blog's Promotion
- blog Promotion
- articles de promotion
- promotion activée
- miralinks.
- travailler dans la sape.
- liens d'achat
- achat de liens
- optimisation
- optimisation de la page
- optimisation interne
- promotion indépendante
- comment promouvoir une ressource
- comment promouvoir votre site
- comment promouvoir le site vous-même
- comment promouvoir le site vous-même
- promotion indépendante
- promotion gratuite
- promotion gratuite
- optimisation du moteur de recherche
- comment promouvoir le site de Yandex
- comment promouvoir le site de Yandex
- promotion sous Yandex.
- promotion sous Google
- promotion dans Google
- indexage
- indexation de l'accélération
- sélectionner le site de donneur
- checkout Donor
- promotion postov
- utiliser des poteaux
- blog's Promotion
- algorithme yandex
- mise à jour Titz
- mise à jour de la base de données de recherche
- updiet Yandex
- liens pour toujours
- références éternelles
- liens de loyer
- référence de location
- liens avec paiement mensuel
- compilation de noyau sémantique
- secrets Promotion
- secrets Promotion
- secrets SEO.
- optimisation des secrets
Je pense que c'est suffisant, et donc une liste du sol de la page;) En général, l'idée est qu'à la première étape, vous devez analyser notre industrie afin de maximiser et de choisir autant de phrases reflétant le sujet du site. Bien que si vous avez manqué quoi que ce soit à ce stade - ne désespérez pas - les phrases aryplied émergent nécessairement aux étapes suivantesIl suffit de faire beaucoup de travail supplémentaire, mais rien de terrible. Nous prenons notre liste et copiez-le sur le collecteur de clés. Ensuite, cliquez sur le bouton - Poule avec Yandex.Wordstat.:
L'analyse peut prendre assez longtemps, vous devriez donc être patient. Le noyau sémantique va généralement entre 3 et 5 jours et le premier jour où vous passerez à la préparation du noyau sémantique de la base et de l'analyse.
Comment travailler avec une ressource, comment choisir des mots-clés J'ai rédigé une instruction détaillée. Et vous pouvez en apprendre davantage sur la promotion du site sur les demandes NF.
De plus, je dirai que, au lieu de brainstorming, nous pouvons utiliser la sémantique des concurrents avec l'un des services spécialisés, par exemple des spywords. Dans l'interface de ce service, nous entrons simplement le mot-clé dont vous avez besoin et que vous voyez les principaux concurrents présents sur cette phrase en haut. De plus, la sémantique du site de tout concurrent peut être complètement déchargée avec ce service.

Ensuite, nous pouvons choisir l'un d'entre eux et retirer ses demandes qui seront laissées de la poubelle et d'utiliser comme une sémantique de base pour une analyse ultérieure. Ou nous pouvons le faire encore plus facile et utiliser.
Sémantique de nettoyage
Dès que le WordStat analysant pleinement ces arrêts - il est temps de couper le noyau sémantique. Cette étape est très importante, nous devrions donc la prendre avec l'attention.
Donc, mon analyse a terminé, mais les phrases se sont avérées Beaucoup deEt par conséquent, les mots des mots peuvent trop nous enlever de nous. Par conséquent, avant de procéder à la définition de la fréquence, il est nécessaire de produire un nettoyage primaire des mots. Nous le ferons dans plusieurs étapes:
1. Filtrer les requêtes avec une fréquence très basse
Pour ce faire, il est basé sur le symbole de tri de la fréquence et commencer à extraire toutes les demandes qui ont des fréquences inférieures à 30:
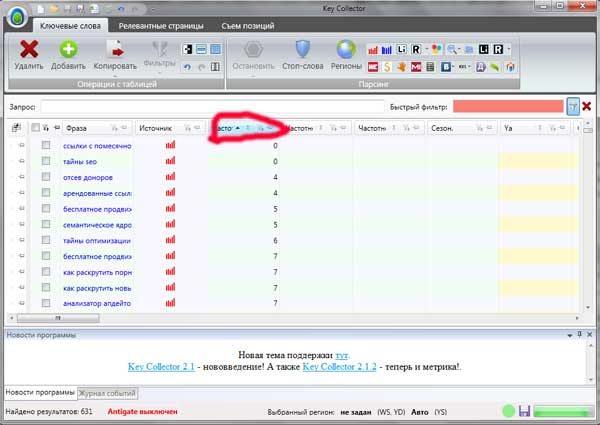
Je pense que avec cet article, vous pouvez facilement faire face.
2. Supprimer ne convient pas dans les demandes de sens
Il existe de telles requêtes qui ont une fréquence suffisante et une faible concurrence, mais elles du tout ne convient pas à notre sujet. De telles clés doivent être supprimées avant de vérifier les objectifs exacts de la clé, car Chèque peut prendre beaucoup de temps. Nous supprimerons de telles clés que nous allons manuellement. Donc, pour mon blog, ils étaient inutiles:
cours d'optimisation des moteurs de recherche site de vente de vente
Analyse du noyau sémantique
À ce stade, nous devons déterminer la fréquence exacte de nos clés, pour laquelle vous devez cliquer sur le symbole de la loupe, comme indiqué dans l'image:

Le processus est assez long, vous pouvez donc vous faire du thé)
Lorsque le chèque a réussi, il est nécessaire de continuer à nettoyer notre noyau.
Je vous suggère de supprimer toutes les clés avec une fréquence inférieure à 10 demandes. De plus, pour votre blog, je supprime toutes les demandes qui ont des valeurs supérieures à 1 000, car je ne prévois toujours pas de telles demandes.
Exportation et regroupement du noyau sémantique
Ne pensez pas que cette étape sera la dernière. Pas du tout! Nous devons maintenant transférer le groupe résultant à Exel pour une visibilité maximale. Ensuite, nous trierons par les pages, puis nous verrons de nombreuses lacunes, la correction de laquelle nous allons traiter.
La sémantique exportée du site à Exel est tout à fait facile. Pour ce faire, il vous suffit de cliquer sur le caractère correspondant, comme indiqué dans l'image:
Après avoir inséré à Exel, nous verrons la photo suivante:
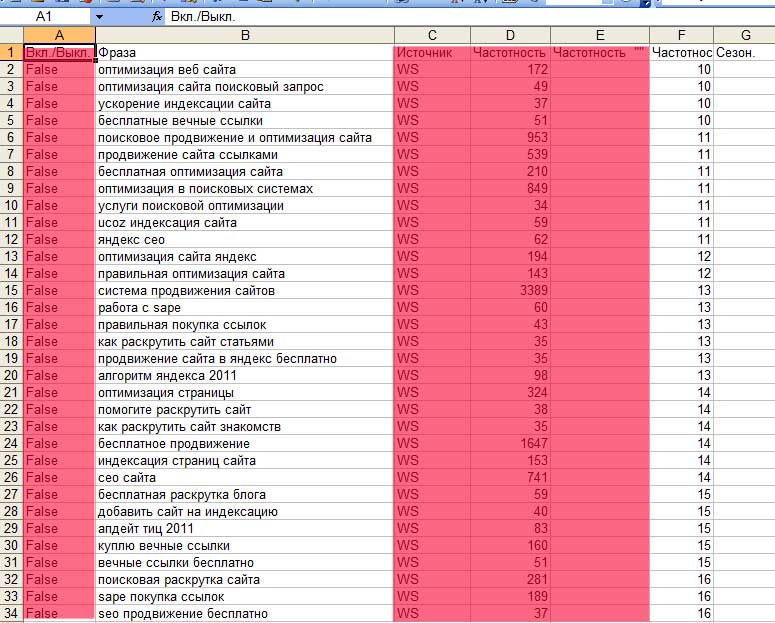
Les colonnes marquées de rouge doivent être supprimées. Créez ensuite une autre table à Exel, où le dernier noyau sémantique sera contenu.
La nouvelle table sera de 3 colonnes: URLpages, phrase-clé et cela la fréquence. En tant qu'URL, sélectionnez ou déjà une page ou une page existante qui sera conçue dans la perspective. Pour commencer, choisissons les clés de la page principale de mon blog:

Après toutes les manipulations, nous voyons la photo suivante. Et suggère immédiatement plusieurs conclusions:
- ces requêtes de fréquence, selon lesquelles il est nécessaire d'avoir une queue beaucoup plus grande de moins de phrases de fréquence que nous ne voyons
- Nouvelles de référencement
- la nouvelle clé revêtue, que nous n'avons pas prises plus tôt - articles de PDG. Besoin d'analyser cette clé
Comme je l'ai dit, aucune clé de nous ne cache. La prochaine étape pour nous sera le brainstorming de ces trois phrases. Après le brainstorming, nous répétons toutes les étapes à partir du tout premier élément de ces clés. Vous pouvez tous sembler trop long et fastidieux pour vous, mais c'est - la compilation du noyau sémantique est un travail très responsable et minutieux. Mais, la secte composée de manière compétente vous aidera grandement à promouvoir le site et à sauver votre budget.
Après tout le produit, nous avons pu obtenir de nouvelles clés pour la page principale de ce blog:
- meilleur blog de référencement
- nouvelles de référencement
- articles SEO.
Et d'autres. Je pense que la technique est compréhensible pour vous.
Après toutes ces manipulations, nous verrons quelles pages de notre projet doivent être modifiées () et quelles nouvelles pages doivent ajouter. La plupart des clés trouvées par nous (avec fréquence jusqu'à 100, et parfois beaucoup plus élevées) peuvent être facilement favorisées seules.
Casting final
En principe, le noyau sémantique est presque prêt, mais il existe un autre point assez important qui nous aidera à améliorer considérablement notre groupe d'établissement. Pour cela, nous avons besoin de seopult.
* En fait, vous pouvez utiliser n'importe lequel des services similaires qui vous permettent d'apprendre la concurrence par des mots-clés, par exemple Mutagen!
Donc, nous créons une autre table dans Exel et copier uniquement les noms de clés là-bas (colonne moyenne). Pour ne pas passer beaucoup de temps, je ne copierai que les clés de la page principale de votre blog:

Ensuite, vérifiez le coût d'obtention d'une transition vers nos mots-clés:
Le coût de la transition vers certaines phrases dépassait 5 roubles. De telles phrases doivent être exclues de notre noyau.

Vos préférences seront peut-être un peu différentes, alors vous pouvez exclure des phrases moins chères ou inversement. Dans son cas, j'ai supprimé 7 phrases.
Information utile!
selon la préparation du noyau sémantique, l'accent est mis sur le dépistage des mots-clés les plus compétitifs.
Si vous avez votre boutique en ligne - lis , où est décrit comment le noyau sémantique peut être utilisé.
Clustering de noyau sémantique
Je suis sûr que vous avez déjà entendu parler de ce mot comme appliqué à la promotion de la recherche. Trouvons le type de bête et pourquoi il est nécessaire de promouvoir le site.
Le modèle de promotion de la recherche classique ressemble à ceci:
- Sélection et analyse des requêtes de recherche
- Regroupement des requêtes sur les pages du site (pages d'atterrissage)
- Préparation de textes de référencement pour les pages d'atterrissage basées sur un groupe de requêtes pour ces pages
Faciliter et améliorer la deuxième étape de la liste ci-dessus et sert de regroupement. En substance, le clustering est une méthode logicielle qui permet de simplifier cette étape lorsque vous travaillez avec une grande sémantique, mais tout n'est pas si simple qu'il peut sembler à première vue.
Pour une meilleure compréhension de la théorie du regroupement, vous devriez faire une petite excursion à l'histoire du référencement:
Littéralement il y a quelques années, lorsque le terme regroupement n'a pas cherché à chaque coiffe - Sienes, dans la majorité écrasante des cas, regroupés par la sémantique avec leurs mains. Mais lors du regroupement d'une énorme sémantique dans 1000, 10 000 et même de 100 000 demandes, cette procédure s'est transformée en un véritable catguard pour une personne ordinaire. Et puis la méthodologie du groupe de sémantique a commencé à utiliser partout (et beaucoup d'entre eux utilisent aujourd'hui cette approche). La technique de regroupement sémantique implique la combinaison d'un groupe de requêtes ayant des relations sémantiques. À titre d'exemple, les demandes "Achetez une machine à laver" et "Achetez une machine à laver à 10 000" combinée dans un groupe. Et tout irait bien, mais cette méthode contient un certain nombre de problèmes critiques et pour leur compréhension, il est nécessaire d'introduire un nouveau terme dans notre narration, à savoir - " demande d'intention”.
Le moyen le plus simple de décrire ce terme peut être le besoin d'un utilisateur, son désir. L'introvent n'est rien de plus que le désir de l'utilisateur entrant dans la requête de recherche.
La base du regroupement de la sémantique consiste à collecter dans un groupe de demandes ayant la même intention, ou aussi près que possible d'intensité possible, et ici 2 caractéristiques intéressantes émerge immédiatement, à savoir:
- La même intention peut avoir plusieurs demandes qui n'ont aucune proximité sémantique, par exemple - "Service de voiture" et "S'inscrire pour"
- Les demandes qui ont une proximité sémanée absolue peuvent contenir une intensis radicalement différente, par exemple, la situation du manuel est le "téléphone portable" et "téléphones portables". Dans un cas, l'utilisateur souhaite acheter un téléphone et dans un autre pour regarder un film
Ainsi, le regroupement de la sémantique en correspondance sémantique ne tient pas compte des intensités des demandes. Et les groupes établis de cette manière ne vous permettront pas d'écrire le texte qui tombera dans le haut. À temps du groupement manuel pour éliminer ce malentendu, les gars avec la profession du «spécialiste de la primune de référencement» ont été analysés à la main.
L'essence de la clustering est une comparaison de la délivrance formée du moteur de recherche à la recherche de régularités. À partir de cette définition, vous devez immédiatement prendre une note pour moi-même que le regroupement lui-même n'est pas la vérité dans la dernière instance, car l'émission formée peut ne pas divulguer pleinement l'intention (dans la base Yandex peut simplement être un site qui combine correctement les demandes à le groupe).
La mécanique de la clustering est simple et ressemble à ceci:
- Le système introduit alternativement toutes les demandes soumises et se souvient des résultats du sommet
- Après une alternance d'une entrée de demandes et de la maintenance des résultats, le système recherche une intersection dans l'extradition. Si le même site est le même document (page de site) est en haut en haut dans plusieurs demandes, ces demandes peuvent être combinées théoriquement dans un seul groupe.
- Il devient pertinent un tel paramètre en tant que groupe de regroupement, qui parle du système, combien de temps il doit y avoir des intersections que les demandes peuvent être ajoutées à un groupe. Par exemple, la force du regroupement 2 signifie qu'au moins deux intersections devraient être présentes dans l'extradition de 2 minutes. Aussi plus facile - au moins deux pages de deux sites différents doivent être présentes simultanément dans le haut d'une autre et une autre demande. Exemple ci-dessous.
- Lors du regroupement de grandes sémantiques, la logique des liens entre les demandes est pertinente, sur la base de laquelle il existe 3 types de base de clustering: doux, moyen et dur. Nous parlerons toujours de types de regroupement dans les enregistrements suivants de ce journal.
Bonjour à tous! Lorsque vous conservez un site de blog ou de contenu, il est toujours nécessaire de faire un noyau sémantique pour le site, le cluster ou l'article. Pour plus de commodité et de système, il est préférable de travailler avec un noyau sémantique selon le système bien établi.
Dans cet article nous examinerons:
- comment la collecte du noyau sémantique est-elle pour écrire un article?
- quels services peuvent et doivent être utilisés;
- comment adapter les clés de l'article;
- mon expérience de sélection personnelle.
Comment collecter des noyaux sémantiques en ligne
- Tout d'abord, nous devons utiliser le service de Yandex -. Ici, nous ferons un échantillon initial de clés possibles.
Dans cet article, je collectionnerai Xia sur le sujet "Comment pondre un stratifié". De même, vous pouvez utiliser cette instruction sur la préparation du noyau sémantique pour tout sujet.
- Si notre article est sur le sujet "Comment poser un stratifié", nous introduirons cette demande d'obtenir des informations sur la fréquence dans wordstat.yandex.ru..
Comme nous pouvons le constater, en plus de la demande cible, nous avons chuté beaucoup de demandes similaires contenant de la phrase "Stratifié"Ici, vous pouvez semer toutes les clés inutiles, toutes les clés qui ne seront pas considérées dans notre article. Par exemple, nous n'écrirons pas sur des sujets similaires, tels que "Combien ça vaut la peine de mettre des stratifiés", "Stratifié snéoriquement posé" etc.
Pour se débarrasser de nombreuses requêtes sciemment non appropriées, je recommande d'utiliser opérateur "-" (moins).
- Nous substituons moins moins, et après tous les mots ne sont pas le sujet.

- Nous allocions maintenant tout ce qui reste et copie des demandes au bloc-notes ou en mot.

- En insérant tout dans le fichier Word, en cours d'exécution dans les yeux et supprimez tout ce qui ne sera pas décrit dans notre article si de fausses demandes sont trouvées, vous pourrez alors vérifier la combinaison des clés de la présence dans le document. Ctrl + F.La fenêtre s'ouvre (panneau latéral à gauche), où nous entrons les mots souhaités.
La première partie du travail est terminée, vous pouvez désormais vérifier notre pièce du noyau sémantique de Yandex pour nettoyer la fréquence, l'opérateur de citation nous aidera.
Si les mots ne suffisent pas, il est facile de faire directement dans le WordStat, en substituant la phrase dans des citations et de la recherche de fréquence propre (Les citations montrent combien de demandes étaient avec le contenu de cette phrase particulière, sans mots supplémentaires). Et si, comme dans notre exemple du noyau sémantique de l'article ou du site, il a révélé beaucoup de mots, il est préférable d'automatiser ce travail à l'aide du service Mutagen.
Se débarrasser des nombres Utilisez les étapes suivantes avec le document Word.
- Ctrl + A. - mettre en surbrillance tout le contenu du document.
- Ctrl + H. - Appelle une fenêtre pour remplacer les caractères.
- Substitut à la première ligne ^ # et appuyez sur "Remplacer tout" Cette combinaison supprimera tous les chiffres de notre document.
Soyez prudent avec les clés contenant les chiffres, les actions ci-dessus peuvent changer la clé.
Sélection de noyau sémantique / Articles en ligne
Donc, j'ai écrit en détail sur le service. Ici, nous continuerons à apprendre la préparation du noyau sémantique.
- Nous allons sur le site et utilisons ce programme pour compiler le noyau sémantique, car je n'ai pas rencontré une meilleure alternative.
- Premièrement, Fréquence Nettoyante OTRACE POUR CE PASSE "PARSER WORDSTAT" → "analyse de masse"

- Insérez tous nos mots sélectionnés du document dans la fenêtre d'analyseur (CTRL + C et CTRL + V) et choisissez la "fréquence du WordStat" dans les citations.

Cette automatisation de processus vaut la peine total 2 kopecks pour la phrase! Si vous choisissez le noyau sémantique pour la boutique en ligne, cette approche vous fera gagner du temps pour le chant-centime!
- Nous cliquons pour vérifier pour vérifier et, en règle générale, 10 à 40 secondes (selon le nombre de mots), vous pouvez télécharger des mots déjà en fréquence dans des guillemets.
- Le fichier de sortie a une extension. CSV Il s'ouvre pour exceller. Nous commençons à filtrer les données pour créer le noyau sémantique en ligne.

- Nous terminons la troisième colonne, il est nécessaire de définir la concurrence (étape suivante).
- Nous mettons le filtre pour les trois colonnes.
- Filtrez la colonne "Fréquence" "décroissante".
- Tout a fréquence inférieure à 10 - Suppression.
Nous avons eu une liste de clésqui peut être utilisé dans le texte de l'article, mais d'abord besoin de les vérifier pour la concurrence. Après tout, si ce sujet est vide sur Internet le long et à travers, il est logique d'écrire sur cette touche sur cette clé? La probabilité que notre article sur elle ira au sommet, extrêmement petit!
- Pour vérifier le noyau sémantique en ligne de la concurrence, aller à "compétition".

- Nous commençons à vérifier chaque demande et la valeur de la concurrence est substituée dans la colonne appropriée de notre fichier Excel.
Coût Vérifie une phrase clé est 30 kopecks.
Après la première réapprovisionnement de la balance, 10 contrôles gratuits seront disponibles tous les jours.
Déterminer les phrases qui valent la peine d'écrire un article prenez le meilleur rapport qualité-prix.
Écrire un article est:
- fréquence d'au moins 300;
- la concurrence n'est pas supérieure à 12 (mieux moins).
En élaborant le noyau sémantique en ligne appliquer des phrases à faible concurrence Donne votre trafic. Si vous avez un nouveau site, il n'apparaîtra pas immédiatement à attendre de 4 à 8 mois.
Presque n'importe quel sujet, vous pouvez trouver SC et RF avec une faible concurrence de 1 à 5, dans de telles clés par jour recevez de 50 visiteurs.
Pour en faire des demandes de noyau sémantique en grappes, ils vous aideront à faire la bonne structure du site.
Où insérer le noyau sémantique dans le texte
Après avoir collecté le noyau sémantique pour le site, il est temps d'entrer des phrases clés dans le texte et voici quelques recommandations pour les débutants et ceux qui "ne croient pas" dans l'existence d'un trafic de recherche.
Signature de règles dans le texte du mot clé
- La clé suffit à utiliser 1 fois;
- les mots peuvent être inclinés par des cas, changer de place;
- vous pouvez diluer des phrases en d'autres termes, bien, lorsque toutes les phrases clés sont diluées et lisibles;
- vous pouvez supprimer / remplacer les prépositions et les mots de question (tels que, etc.);
- vous pouvez insérer dans les signes de phrase "-" et ":"
par exemple:
Il y a une clé: "Comment mettre un stratifié de vos propres mains" Dans le texte, il peut ressembler à ceci: "... Afin de jeter les planches de stratifié avec vos mains, nous avons besoin de ..." ou tellement "Tous ceux qui ont essayé de mettre des stratifiés avec leurs propres mains ...".
Certaines phrases contiennent déjà d'autresPar exemple, phrase:
"Comment pondre un stratifié de vos propres mains dans la cuisine" contient déjà une phrase clé "Comment mettre un stratifié de vos propres mains". Dans ce cas, il est permis d'omettre la seconde, comme il est déjà présent dans le texte. Mais s'il y a peu de clésIl est préférable de l'utiliser dans le texte ou dans le titre, ou dans la description.
- s'il est impossible de pousser la phrase dans le texte, laissez-le, ne faites pas cela (au moins deux phrases peuvent être utilisées dans le titre et la description et ne les écrivez pas dans le corps de l'article);
- Avant que, une phrase est le titre de l'article (la fréquence et la compétition les plus grosses)La langue Webmasters est H1, cette phrase suffit à utiliser une fois dans le corps du texte.
Contre-indications aux Écritures des clés
- il est impossible de séparer la phrase clé de la virgule (uniquement dans des cas extrêmes) ou de points;
- il est impossible d'entrer la clé du texte sous forme directe afin de ne pas sembler naturellement (non lisible);
Titre et page Description
Titre et description. - Il s'agit d'un titre et d'une description de page, ils ne sont pas visibles dans l'article, Yandex et Google leur montrent lors de l'exploration de l'utilisateur.
Règles de parole:
- le titre et la description doivent être «journalistiques», c'est-à-dire attrayant pour la transition;
- pour contenir le texte thématique (requête pertinent), pour cet ajustement dans le titre et dans la description des phrases clés (diluées).
Général exigences de symbole au plugin Tout dans un pack de référencementCe qui suit:
- Titre - 60 caractères (espaces compris).
- Description - 160 caractères (espaces compris).
Vérifiez le plagiat votre création ou obtenu de votre part.
Sur cette question avec le sujet, que faire avec le noyau sémantique après la compilation que nous avons compris. En conclusion, je partagerai ma propre expérience.
Après avoir compilé le noyau sémantique selon les instructions - mon expérience
Vous pourriez penser que je suis triste pour vous, quelque chose n'est pas plausible. Afin de ne pas être non fondé ici est une capture d'écran de statistiques pour la dernière année (mais pas la seule) année de ce site, comment j'ai réussi à reconstruire le blog et à commencer à recevoir du trafic.
Cette formation est la préparation du noyau sémantique, bien que longtemps mais efficace, car dans le site construisant la principale approche et la bonne patience!
Si vous avez des questions ou avez des critiques, écrivez-vous dans le commentaire, je serai intéressé, partagez également votre expérience!
En contact avec
Le noyau sémantique (SIA) est un ensemble de mots-clés, de requêtes, des expressions de recherche pour lesquelles vous devez promouvoir votre site pour y venir les visiteurs ciblés des moteurs de recherche. La compilation du noyau sémantique est la deuxième étape, après la mise en place de votre site sur l'hébergement. Il provient de la composition compétent de XI, quelle meilleure trafic sera sur votre site.
La nécessité de préparer le noyau sémantique est quelques points.
Premièrement, il permet de développer une stratégie plus efficace de la promotion de la recherche, car le maître Web qui fera un noyau sémantique pour son projet, sera une idée claire des méthodes de promotion de la recherche qu'il devra s'appliquer à Son site, décider du coût de la recherche de promotion, qui dépend fortement du niveau de concurrence des phrases clés dans la délivrance des services de recherche.
Deuxièmement, le noyau sémantique permet de remplir la ressource avec un meilleur contenu, c'est-à-dire que le contenu qui sera bien optimisé pour les demandes clés. Par exemple, si vous souhaitez effectuer un site sur des plafonds extensibles, le noyau sémantique des demandes doit être sélectionné "repsillement" à partir de ce mot clé.
De plus, la compilation du noyau sémantique implique la définition de la fréquence d'utilisation des mots-clés par les utilisateurs de moteurs de recherche, ce qui permet de déterminer le système de recherche dans lequel vous devez accorder plus d'attention à la promotion d'une demande.
Il est également nécessaire de noter certaines règles de compilation du noyau sémantique, qui doit être observée afin de pouvoir constituer une SIA de haute qualité et efficace.
Ainsi, dans la composition du noyau sémantique, vous devez activer toutes les demandes de clé possibles pour lesquelles le site peut être promu, à l'exception de ces demandes qui ne peuvent pas apporter à la ressource au moins une petite quantité de trafic. Par conséquent, le noyau sémantique devrait inclure des mots-clés à haute fréquence (HF), des requêtes de moyenne (s) et des basses fréquences (LF).
Conditionnellement, ces demandes peuvent être cassées comme ceci: PL - Jusqu'à 1 000 demandes par mois, SCH - de 1 000 à 10 000 demandes par mois, HF - plus de 10 000 demandes par mois. Il est nécessaire de prendre en compte le fait que, dans différents sujets, ces chiffres peuvent différer de manière significative (dans certains thèmes particulièrement étroits, la fréquence maximale des demandes ne dépasse pas 100 demandes par mois).
Les demandes basse fréquence sont simplement nécessaires pour être apportées à la structure du noyau sémantique, car toute jeune ressource a la capacité d'avancer dans les moteurs de recherche, tout d'abord, sur eux (et sans aucune promotion externe du site - écrivit un article sous La demande NF, le moteur de recherche a été indexé et votre site de moteur de recherche après quelques semaines peut être en haut).
Il est également nécessaire d'observer la règle de structuration du noyau sémantique, qui est que tous les mots-clés du site doivent être combinés en groupes non seulement par leur fréquence, mais également le degré de similarité. Cela permettra de mieux optimiser le contenu, par exemple, d'optimiser certains textes pour plusieurs demandes.
Également dans la structure du noyau sémantique de nombreux sites, il est conseillé d'inclure de tels types de demandes telles que des demandes synonymes, une requête d'argot, une réduction des mots, etc.
Voici un exemple clair de la manière dont vous pouvez accroître la fréquentation du site par une en écrivant des articles optimisés, qui incluent le compte et un grand nombre de demandes de LF:
1. Le site des sujets masculins. Bien qu'il soit très rarement mis à jour (pour tout le temps, il a été publié un peu plus de 25 articles), mais grâce à des demandes bien sélectionnées, il gagne de plus en plus de fréquentation. Le site n'a pas acheté de liens!

Pour le moment, la croissance de la participation a suspendu, car seuls 3 articles ont été publiés.
2. Le site du thème féminin. Au début, les articles non optimisés n'étaient pas publiés. En été, un noyau sémantique a été compilé, qui consistait en des requêtes avec une très faible concurrence (comment collecter des demandes similaires, je dirai ci-dessous). Selon ces demandes, des articles pertinents ont été écrits et plusieurs références ont été acquises sur des ressources thématiques. Les résultats de cette promotion que vous pouvez voir ci-dessous: 
3. Le site des sujets médicaux. Une niche médicale a été choisie avec une concurrence plus ou moins adéquate et a publié plus de 200 articles pour de délicieuses demandes avec de bonnes offres (sur Internet, le terme "offre" désignant le coût d'un utilisateur de transit utilisateur sur la liaison de publicité). Les liens ont commencé à acheter en février, lorsque le site était de 1,5 mois. Jusqu'à présent, la plupart du temps le trafic provient de Google, Yandex n'a pas encore pris en compte les liens achetés.

Comme vous pouvez le constater, la sélection du noyau sémantique joue un rôle crucial dans la promotion du site. Même avec un petit budget, ou en général, il n'est pas possible de créer un site de circulation qui apportera vos bénéfices.
Sélection de requêtes de recherche
Choisissez des demandes pour le noyau sémantique de la manière suivante:
Utilisation de services gratuits de Statistiques de la requête de recherche Google, Yandex ou Rambler
Avec un logiciel spécial ou un service en ligne (gratuit ou payé).
Après avoir analysé les sites Web des concurrents.
Sélection des requêtes de recherche Utilisation de Google Recherche Queries Statistiques, Yandex ou Rambler
Immédiatement, je souhaite vous avertir que ces services montrent des informations très précises sur le nombre de requêtes de recherche par mois.
Par exemple, vous êtes sur demande "Windows en plastique" Vue 4 page des résultats de la recherche, puis le service Statistics vous montrera que cette demande n'a été recherchée pas 1, et 4 fois, car elle est considérée comme non seulement la première question de l'émission, Mais tout le prochain, qui sont considérés comme des utilisateurs consultés. Par conséquent, dans la pratique, les chiffres réels seront quelque peu inférieurs à ceux qui montrent divers services.
Pour déterminer le nombre exact de transitions, le meilleur de tous, bien sûr, sera mis en évidence par les statistiques de la présence de concurrents qui sont au top 10 (LiveInternet ou masculin, s'il est ouvert). Ainsi, il sera possible de comprendre combien de trafic apportera la demande qui vous intéresse.
Vous pouvez également compter sur le nombre de visiteurs vous apportera cette demande, en fonction du poste que le site occupera dans les résultats de la recherche. C'est ainsi que CTR changera (coeff. Clickability) de votre site sur diverses positions en haut:

Considérons la demande "! Réparation! Appartements, région" Moscou et région ":

Dans ce cas, si votre site occupera la 5ème position dans l'extradition, cette demande vous apportera environ 75 visiteurs par mois (6%), 4ème place (8%) - 100 pos. / par mois, 3ème place (11% ) - 135 pos. / par mois, 2e place (18%) - 223 pos. / par mois. et la 1ère position (28%) - 350 visiteurs par mois.
Le CTR peut également être affecté à l'aide d'un extrait lumineux, augmentant ainsi la fréquentation sur cette demande. Comment améliorer l'extrait et ce qu'il peut être lu.
Statistiques de requête Google Recherche
Auparavant, les statistiques de la requête de recherche de Google, j'ai utilisées plus souvent, depuis tout d'abord été déplacées dans ce moteur de recherche. Ensuite, il suffisait d'optimiser l'article, l'achetant autant que possible une variété de liens simples de relations publiques (il est très important que ces liens soient naturels et les liens des transitions des visiteurs) et de la vila - vous êtes en haut!
Maintenant, dans Google, la situation est telle qu'il n'est pas beaucoup plus facile de le déplacer que dans Yandex. Par conséquent, vous devez accorder beaucoup plus d'attention à l'écriture et à la conception (!) Des articles et d'acheter des liens pour le site.
Je veux aussi attirer votre attention sur le fait suivant:
En Russie, Yandex bénéficie de la plus grande popularité (Yandex - 57,7%, Google - 30,6%, Mail.RU - 8,9%, Rambler -1,5%, Nigma / Ask.com - 0,4%), donc si vous vous déplacez dans ce pays, Vous êtes d'abord la file d'attente mérite de naviguer Yandex.
En Ukraine, la situation est différente: Google - 70-80%, Yandex - 20-25%. Par conséquent, les webmasters ukrainiens doivent se concentrer sur la promotion dans Google.
Pour tirer parti des demandes de Google, allez à
Considérons un exemple de sélection de mots-clés pour certains sites culinaires.
Tout d'abord, vous devez entrer la demande principale, sur la base desquelles les options de mots-clés seront sélectionnées pour le futur noyau sémantique du site. J'ai entré la demande "Comment cuisiner".
La prochaine étape - choisissez le type de conformité. Il y a 3 types de conformité: large, phrase et précis. Je vous conseille de choisir exactement, car cette option présentera les informations les plus précises sur demande. Et maintenant je vais expliquer pourquoi.
Une vaste conformité signifie que les statistiques des spectacles seront affichées dans tous les mots figurant dans cette demande. Par exemple, pour la demande "Windows en plastique" sera affichée pour tous les mots dans lesquels le mot "plastique" et le mot "Windows" (plastique, fenêtre, windows, achètent des stores pour Windows, PVC Windows). En bref, il y aura beaucoup de "ordures".
La conformité à la phrasale signifie que les statistiques seront indiquées pour des mots précisément dans l'ordre dans lequel ils sont spécifiés. Avec la phrase spécifiée des mots, d'autres mots peuvent être présents dans la requête. Pour la demande de "Windows en plastique", les mots "Windows en plastique peu coûteux" seront pris en compte "Windows en plastique Moscou", "Combien de fenêtres en plastique sont" etc. ", etc.

Nous sommes le plus intéressés par le chiffre "Nombre de demandes par mois (régions cible)" et "Prix approximatif par clic" (si nous allons poster des publicités AdSense sur les pages du site).
Dire des statistiques Yandex
J'utilise les statistiques des requêtes de recherche presque tous les jours, car elles sont présentées sous une forme plus pratique que son analogue dans Google.
Le seul minuscule du WordStat est que vous ne trouverez pas dans les types de conformité informatiques, n'émettez pas de vos requêtes sélectionnées sur votre ordinateur, vous ne pourrez pas connaître le prix de clic, etc.
Pour des résultats plus précis, vous devez utiliser des opérateurs spéciaux avec lesquels vous pouvez clarifier des demandes qui nous intéressent. Liste des opérateurs que vous trouverez à ce sujet.
Si vous entrez simplement la requête «Comment cuisiner» dans le VORDSTAT, nous obtenons les statistiques suivantes:

Ceci est égal si nous avons choisi une "conformité plus large" dans AdWords.
Si vous entrez la même demande, mais déjà dans des devis, nous obtiendrons des statistiques plus précises (conformité analogique de phrase dans AdWords):

Eh bien, pour obtenir des statistiques uniquement pour une requête spécifiée, vous devez utiliser l'opérateur "!": "! Comment! Préparer"

Pour obtenir des résultats encore plus précis, vous devez spécifier la région sous laquelle le site bouge:

De plus, dans le panneau supérieur, le WordStat dispose d'outils avec lesquels vous pouvez voir les statistiques d'une demande spécifiée par les régions, par mois et par semaine. Avec l'aide de ce dernier, d'ailleurs, il est très pratique d'analyser les statistiques des demandes saisonnières.
Par exemple, en analysant la demande "Comment cuisiner", vous pouvez savoir ce qu'il aime le plus populaire au mois de décembre (ce n'est pas surprenant - tout se prépare pour la nouvelle année):

Statistique de requête de recherche Rambler
Immédiatement, je tiens à vous avertir que les statistiques de la demande de rackell perdent de plus en plus leur pertinence chaque année (tout d'abord, il est associé à la faible popularité de ce moteur de recherche). Par conséquent, vous n'avez probablement pas à travailler avec cela.


À Adstat, vous n'avez pas besoin d'entrer aucun opérateur - cela donne immédiatement la fréquence de la demande dans l'affaire dans laquelle il a été introduit. De plus, il existe également des statistiques séparées des demandes de fréquence pour la première page des résultats de recherche et de toutes les pages émettrices, y compris la première.
Sélection de requêtes de recherche avec logiciel spécial ou services en ligne
Rookee peut non seulement promouvoir vos demandes, mais peut également aider à créer le noyau sémantique du site.
Avec l'aide de Rokee, vous sélectionnerez facilement le noyau sémantique de votre site, vous pouvez également prédire le nombre de visites sur certaines demandes et le coût de leur promotion au sommet.
Sélection des demandes à l'aide d'un programme Word gratuit
Si vous allez faire un SIA (noyau sémantique) à un niveau plus professionnel, ou si vous aurez besoin de Google Statistiques sur Google.Adwords, Rambler.adstat, le réseau social Vkontakte, divers agrégateurs de référence, etc., je vous conseille immédiatement de Achetez le collecteur Kay.
Si vous voulez faire un grand noyau sémantique, mais vous ne voulez pas dépenser de l'argent sur l'achat de programmes payants, la meilleure option dans ce cas sera un programme de mots (lire des informations sur le programme ici). Elle est un collectionneur de Kay "plus jeune" et vous permet de collecter Xia, en fonction des statistiques des demandes de Yandex.Wordstat.
Installer un programme de mots.
Téléchargez l'archive avec le logiciel.
Assurez-vous que l'archive est déverrouillée. Pour ce faire, dans les propriétés du fichier (dans le menu contextuel, sélectionnez "Propriétés") Appuyez sur le bouton "Déverrouillage" / "Débloquer" si elle est présente.
Décompressez le contenu de l'archive.
Exécuter le fichier exécutable slovoeb.exe
Créer un nouveau projet:

Choisissez la région souhaitée (Bouton Régions Yandex.Wordstat):

Nous enregistrons des modifications.
Cliquez sur le bouton "Yandex.WordStat Gauche Colonne"
Si nécessaire, définissez les "mots d'arrêt" (mots qui ne doivent pas être inclus dans notre noyau sémantique). Les mots d'arrêt peuvent être tels que des mots: "gratuitement" (si vous vendez quelque chose sur votre site), "Forum", "Wikipedia" (Si vous avez votre propre site d'information sur lequel il n'y a pas de forum), "Porn", "sexe "(Eh bien, tout est clair ici), etc.
Vous devez maintenant définir la liste initiale des mots, sur la base de laquelle la XIA sera compilée. Faisons un noyau pour une entreprise qui est engagée dans l'installation de plafonds extensibles (à Moscou).
Lorsque vous sélectionnez un noyau sémantique, tout d'abord, vous devez faire une classification du sujet du sujet.
Dans notre cas, des plafonds extentés peuvent être classés selon les critères suivants (cartes de renseignement appropriées similaires dans le programme Mindjet MindManager):

Conseils utiles: Pour une raison quelconque, de nombreux webmasters oublient d'inclure les noms de petites colonies de peuplement dans le noyau sémantique.
Dans notre cas, dans XIA, il serait possible d'inclure les noms des domaines d'intérêt pour Moscou et les villes de la région de Moscou. Même si dans ces mots-clés ("Plafonds de tension Golitsyno", "Plafonds extensibles Aprelevka", etc.) Très peu de demandes par mois, elles doivent encore écrire au moins un petit article, dans le titre de la clé souhaitée. Ces articles ne doivent pas nécessairement promouvoir, car le plus souvent, selon ces demandes, il y aura une très faible concurrence.
10-20 articles de ce type et votre site disposera de plusieurs commandes supplémentaires de ces villes.
Appuyez sur la touche "Colonne de gauche Yandex.Wordstat" et entrez les demandes souhaitées:

Cliquez sur le bouton "Pass". En conséquence, nous obtenons cette liste de demandes:

Nous tirons toutes les requêtes inutiles qui ne conviennent pas sur le sujet du site (par exemple, "plafonds extensibles avec leurs propres mains" - cette requête apportera un certain trafic, mais cela ne nous apportera pas aux clients qui commanderont l'installation de les plafonds). Nous allouons ces demandes et supprimons cela à l'avenir de ne pas passer du temps à leur analyse.
Maintenant, vous devez clarifier la fréquence pour chacune des clés. Cliquez sur le bouton "Récupérer la fréquence"! "":

Nous avons maintenant les informations suivantes: demande, sa fréquence globale et précise.
Maintenant, sur la base de la fréquence obtenue, vous devez reconsidérer toutes les demandes et supprimer inutile.
Les demandes inutiles sont des demandes de renseignements que:
Fréquence précise ("!") Très faible (dans le sujet choisi par moi, en principe, vous devez passer par tous les visiteurs. Je vais donc couper des demandes qui ont une fréquence mensuelle inférieure à 10). S'il n'y avait pas de thème de construction, mais, par exemple, certains généralement thématiques, vous pouvez alors couper en toute sécurité les demandes de la fréquence inférieure à 50-100 par mois.
Le rapport de fréquence commune et précis dépasse très grand. Par exemple, la demande "Acheter des plafonds de tension" (1335/5) peut être immédiatement supprimée, car il s'agit d'une "demande de requête".
Les demandes avec une très grande concurrence doivent également être supprimées, il sera difficile d'avancer (surtout si vous avez un jeune site et un petit budget pour la promotion). Une telle demande, dans notre cas, est "Plafonds extensibles". De plus, les requêtes qui se composent de 3,4 et d'autres mots sont plus efficaces - ils apportent plus de visiteurs cibles.
En plus du mot, il existe un autre excellent programme pour la collecte, l'analyse et le traitement automatique de statistiques de mots-clés de mots-clés yandex.direct.
Actualités Recherche requêtes
Dans ce cas, il n'est pas créé comme pour le projet de contenu habituel. Pour le site d'information, tout d'abord, vous devez mettre en évidence les rubriques, dans lesquelles des nouvelles seront publiées:

Après cela, vous devez choisir des demandes pour chacune des sections. Les demandes de nouvelles sont attendues et non attendues.
Au premier type de demandes, la raison d'information est prédite. Le plus souvent, vous pouvez même déterminer avec précision la date à laquelle il y a une éclaboussure de popularité d'une demande. Cela peut être des vacances (nouvel an, le 9 mai, le 8 mai, le 23 mai, la Journée de l'indépendance, la Journée de la Constitution, les vacances à l'église), l'événement (événements musicaux, concerts, cinéastes, compétitions sportives, élection présidentielle).
Préparer de telles demandes à l'avance et déterminer le volume approximatif de trafic dans ce cas peut utiliser
En outre, n'oubliez pas de voir les statistiques de la fréquentation de votre site (si vous avez déjà négligé tout événement) et des sites de concurrents (si leurs statistiques sont ouvertes).
Le deuxième type de requêtes est moins prévisible. Celles-ci incluent des nouvelles d'urgence: cataclysmes, catastrophes, tout événement dans les familles de personnes célèbres (naissance / mariage / mort), sortie d'un produit logiciel non annoncé, etc. Dans ce cas, vous devez juste être l'un des premiers à publier ces nouvelles.
Pour ce faire, il ne suffit pas de simplement surveiller les nouvelles de Google et de Yandex - dans ce cas, votre site ne sera qu'un de ceux qui ont simplement reproduit cet événement. Une méthode plus efficace qui vous permet de déchirer le grand Kush - suivi de sites étrangers. Publié par cette nouvelle l'une des premières dans Runet, vous, en plus des tonnes de trafic, qui mettront le serveur sur votre hébergement, obtenez beaucoup de backlinks sur votre site.
Les demandes des sujets "cinéma" peuvent également être attribuées au premier type (demandes attendues). En effet, dans ce cas, la date du film est connue à l'avance, le script de film est approximativement connu, ses acteurs. Par conséquent, vous devez préparer une page à l'avance sur laquelle le film apparaîtra, ajoutez une remorque pendant un moment. Vous pouvez également publier sur les nouvelles du site sur le film, ses acteurs. Cette tactique vous aidera à prendre les meilleures positions des moteurs de recherche à l'avance et dirigera les visiteurs sur le site avant sa première.
Vous voulez savoir ce qui demande maintenant à la tendance ou à prédire la pertinence de votre sujet à l'avenir? Utilisez ensuite les services fournissant des informations sur les tendances. Il permet de nombreuses opérations d'analyse: comparer les tendances de la recherche pour plusieurs demandes, analyse des régions géographiques de la demande, visualisation des tendances les plus chaudes pour le moment, visualisant les requêtes réelles pertinentes, les résultats d'exportation au format CSV, la possibilité de s'abonner au flux RSS pour Hot Tendances, etc..
Comment accélérer la collection de noyau sémantique?
Je pense que tous ceux qui ont traversé la collection du noyau sémantique, une pensée est apparue: «Combien de temps et fit une analyse, fatiguée de traverser et de grouper des milliers de ces demandes!». C'est normal. Je l'ai aussi parfois. Surtout lorsque vous devez parcourir et régler, ce qui consiste en plusieurs dizaines de milliers de demandes.
Avant de commencer un colis, je vous conseille vivement de scinder toutes les demandes de groupes. Par exemple, si vous avez le sujet du site "Maison de construction", rompez-la sur la fondation, les murs, les fenêtres, les portes, le toit, le câblage, le chauffage, etc. Vous serez tout simplement beaucoup plus facile à suivre et à regrouper des demandes de groupe lorsqu'ils sont situés dans un petit groupe et sont interconnectés par un certain thème étroit. Si vous êtes simplement versé tout dans une pile, vous aurez une énorme liste irréaliste, dont le traitement ne se produira pas un jour. Et ainsi, en traitant toute la liste de sourire en petits étapes, vous ferez non seulement mieux travailler toutes les demandes, mais également pour commander un article avec des copyceux pour les clés déjà collectées en parallèle.
Le processus de collecte du noyau sémantique commence presque toujours par des requêtes automatiques analysantes (pour cela, j'utilise Kay Collector). Manuellement, vous pouvez également collecter, mais si nous travaillons avec un grand nombre de demandes, je ne vois pas le point de dépenser mon temps précieux sur ce travail de routine.
Si vous travaillez avec d'autres programmes, vous serez probablement disponible pour travailler avec des serveurs proxy. Cela vous permet d'accélérer le processus d'analyse d'analyse et de sécuriser votre adresse IP de la Banna des moteurs de recherche. Honnêtement, ce n'est pas très agréable lorsque vous devez remplir complètement la commande et votre adresse IP en raison de l'appel fréquent au service de statistiques Google / Yandex pour une journée. Ici dans ce cas et viennent à la rescousse des serveurs proxy payés.
Personnellement, je ne les utilise peut-être pas pour une seule raison - ils sont constamment Bantas, trouver des proxies de haute qualité ne sont pas si faciles, et même une fois encore, payez-leur de l'argent que je n'ai aucun désir. Par conséquent, j'ai trouvé une autre méthode de collecte de SIA, qui a accéléré plusieurs fois ce processus.
Sinon, vous devrez rechercher d'autres sites d'analyse.
Dans la plupart des cas, les sites ferment cette statistique afin que vous puissiez utiliser les statistiques des points d'entrée.
En conséquence, nous aurons les statistiques des pages de site les plus visitées. Allez-y, nous écrivons les demandes principales que celles-ci ont été optimisées et déjà sur eux, nous collectons SIA.
Au fait, si le site dispose des statistiques sur les phrases de recherche, vous pouvez faciliter le travail et collecter des demandes à l'aide d'un collecteur kei (il vous suffit de saisir l'adresse du site et de cliquer sur le bouton "Obtenir les données"):

La deuxième façon d'analyser le site d'un concurrent consiste à analyser son site.
Il y a un widget des "articles les plus populaires" (ou quelque chose comme ça) sur certaines ressources. Parfois, les articles les plus populaires sont choisis en fonction du nombre de commentaires, parfois fondés sur le nombre de vues.

En tout état de cause, avoir une liste des articles les plus populaires devant ses propres yeux, vous pouvez déterminer quel type de demande un ou plusieurs articles ont été écrits.
Troisième façon - Utilisez des outils. Il a généralement été créé pour analyser les sites de fiducie, mais honnêtement, il considère très bien la confiance. Mais ce qu'il peut bien faire - il est donc d'analyser les demandes des sites Web des concurrents.
Entrez l'adresse de n'importe quel site (même avec des statistiques fermées!) Et appuyez sur le bouton de chèque de la confiance. Au bas de la page sera affiché des statistiques de la visibilité du site par mots clés:
Visibilité du site dans les moteurs de recherche (Mots-clés)

Le seul minus - ces demandes ne peuvent être exportées, vous devez tout copier manuellement.
Quatrième moyen - l'utilisation de services et.

Avec cela, vous pouvez définir toutes les demandes par lesquelles le site occupe des positions dans les 100 premiers dans les deux moteurs de recherche. Il est possible d'exporter des positions et des demandes au format XLS, mais je ne pouvais pas ouvrir ce fichier sur aucun des ordinateurs.

Eh bien, la dernière façon de découvrir les mots clés des concurrents - avec
Analysons l'exemple de la demande "Maison de Bruus". Dans l'onglet "Analyse de concurrents", entrez cette demande (si vous souhaitez analyser un site spécifique, il vous suffit de saisir son URL dans ce champ).
En conséquence, nous obtenons des informations sur la fréquence de la demande, le nombre d'annonceurs dans chacun des moteurs de recherche (et s'il existe des annonceurs, il y a de l'argent dans ce créneau) et le coût moyen de cliquer sur Google et Yandex:

Vous pouvez également voir toutes les annonces dans Yandex.Direct et Google AdWords:


Mais cela ressemble au sommet de chacun des PS. Vous pouvez cliquer sur l'un des domaines et voir toutes les demandes par lesquelles il se trouve en haut et à toutes ses annonces contextuelles:

Il existe une autre façon d'analyser les demandes des concurrents, dont peu de personnes connaissent - avec l'aide du service ukrainien
Je l'appellerais la "version ukrainienne de Spywords", car ils sont très similaires à la fonctionnalité. La seule différence est dans la base de données des phrases clés qui recherchent des utilisateurs ukrainiens. Donc, si vous travaillez à UA-NETE, ce service vous sera très, à la manière!
Analyse de la concurrence des demandes
Donc, les demandes sont assemblées. Maintenant, vous devez analyser la concurrence pour que chacun d'entre eux puisse comprendre à quel point un ou plusieurs mots-clés seront favorisés.
Personnellement, je, lorsque je fais un nouveau site, essayez d'abord d'écrire des articles pour des requêtes par quelle faible concurrence. Cela permettra un peu de temps et des investissements minimaux pour amener le site à une très bonne participation. Au moins, sous des sujets tels qu'une construction, la médecine peut être libérée dans 500-1000 visiteurs en 2,5 mois. Sur les thèmes féminins en général silencieux.
Voyons comment analyser la concurrence de manière manuelle et automatique.
Façon manuelle d'analyser la concurrence
Nous entrons dans le mot-clé souhaité dans la recherche et consultons les sites T0P-10 (et si nécessaire, T0P-20) dans les résultats de la recherche.
Les paramètres les plus élémentaires auxquels vous devez regarder est:
Le nombre de pages principales dans le sommet (si vous faites la promotion de la page intérieure du site et, en haut des concurrents, les pages principales sont principalement situées, alors probablement, vous ne pourrez pas les dépasser);
Le nombre de dirigeants de mots clés directs dans les pages de titre.
Selon des demandes telles que «Promotion du site Web», «Comment perdre du poids», «Comment construire une maison» est une compétition élevée non réalisée (nombre des pages principales en haut de la saisie directe du mot-clé du titre), donc vous ne devrait pas passer sur eux. Mais si vous déménagez sur demande «Comment construire une maison de blocs de mousse avec vos propres mains avec un sous-sol», vous aurez plus de chances d'entrer dans le haut. Par conséquent, une fois de plus en se concentrant sur ce que vous devez vous déplacer sur des demandes composées de 3 mots et d'autres mots.
En outre, si vous analysez l'émission de Yandex, vous pouvez faire attention aux sites TITZ (plus le plus difficile à les dépasser, car le haut Titz indique le plus souvent un poids de référence important du site), qu'ils soient dans le répertoire Yandex. (Les sites du catalogue Yandex ont une grande confiance), son âge (les sites liés à l'âge de moteurs de recherche comme plus).
Si vous analysez les meilleurs sites de Google, faites attention aux mêmes paramètres que j'ai écrit ci-dessus, uniquement dans ce cas, au lieu du répertoire Yandex, il y aura un répertoire DMOZ, et au lieu de l'indicateur TIC, il y aura un indicateur PR. (Si le site des pages du site a PR de 3 à 10, pour les dépasser ne sera pas facile).
Je vous conseille d'analyser des sites à l'aide d'un plugin. Il affiche toutes les informations sur le site du concurrent:

Manière automatique d'analyser la concurrence de la requête
S'il existe de nombreuses demandes, vous pouvez utiliser des programmes qui feront tout le travail pour vous des centaines de fois. Dans ce cas, vous pouvez utiliser le mot ou le collecteur Kei.
Auparavant, analysez les concurrents, j'ai utilisé l'indicateur «Kei» (taux de compétition). Cette fonctionnalité est dans le collecteur Kay et un mot.
Dans le mot, l'indicateur KEI montre simplement le nombre total de sites dans la délivrance de cette demande ou une autre demande.
À cet égard, Kay Collector a un avantage, car il a la possibilité de spécifier la formule pour calculer le paramètre KEI. Pour ce faire, accédez aux paramètres du programme - Kei:

Dans la "formule du calcul de la formule de calcul Kei 1" insertion:
(Kei_yandexmainpagescount * kei_yandexmainpagescount * kei_yandexmainpagescount) + (kei_yandextextexount * kei_yandextext * kei_yandextextCount)
Dans le champ "Calcul Formula Kei 2" Insérer:
(Kei_googlemainpagescount * kei_googlemainpagescount * kei_googlemainpagescount) + (kei_googlettlesCount * kei_googolettesSount * kei_googlettlesCount)
Cette formule prend en compte le nombre de pages principales de l'émission d'un mot clé donné et le nombre de pages dans le top-10, dans lequel cette phrase clé est incluse dans les pages de titre. Ainsi, vous pouvez obtenir des données de concurrence plus ou moins objectives pour chaque demande.
Dans ce cas, moins la demande de Kei est meilleure. Les meilleurs mots-clés seront avec Kei \u003d 0 (si dans eux, bien sûr, il y aura au moins du trafic).
Cliquez sur les boutons de collecte de données pour Yandex et Google:

Cliquez ensuite sur ce bouton:

Dans la colonne Kei 1 et Kei 2 apparaîtra sur les demandes de Kei pour Yandex et Google
respectivement. Trier les demandes en augmentant la colonne Kei 1:

Comme vous pouvez le constater, parmi les demandes sélectionnées, la promotion ne devrait pas être des problèmes particuliers. Dans des sujets moins compétitifs, apporter dans le top-10 de ce type, il suffit de rédiger un bon article optimisé. Et en même temps n'aura pas besoin d'acheter des liens externes pour sa promotion!
Comme je l'ai dit ci-dessus, j'ai utilisé l'indicateur de Kei plus tôt. Maintenant, pour évaluer la concurrence, il me suffit d'obtenir le nombre de pages principales dans le haut et le nombre d'entrées de mots clés dans la page de titre. Dans le collecteur Kay, il y a une fonction similaire:


Après cela, je trie les requêtes sur le "nombre de pages principales de PS Yandex" et examinez de manière à ce que ce paramètre n'a pas plus de 2 pages principales en haut et en tant que peu d'entrées dans les titres. Après toutes ces demandes, je serai établi, je réduit les paramètres du filtre. Ainsi, le premier à publier des articles dans les demandes NK sera publié et celui-ci - sous les demandes SC et VC.
Une fois que toutes les requêtes les plus intéressantes sont collectées et regroupées ensemble (je dirais le groupe ci-dessous), cliquez sur le bouton "Exporter des données" et enregistrez-les dans un fichier. Dans le fichier d'exportation, j'allumes habituellement les paramètres suivants: la fréquence de Yandex avec "!" Dans une région donnée, le nombre de pages majeures des sites et le nombre de buts du mot clé dans les titres.
Conseil: Collecteur Kay Parfois, il n'indique pas très à juste titre le nombre de demandes dans les titres. Par conséquent, il est souhaitable d'entrer en outre à ces demandes dans Yandex et de regarder la délivrance manuelle.
Évaluez la compétitivité des requêtes de recherche peut également être utilisée avec gratuitement
Demandes de regroupement
Une fois que toutes les demandes sont sélectionnées, l'heure est assez ennuyeuse et travail monotone sur le regroupement des demandes. Veuillez prendre des questions similaires pouvant être combinées dans un petit groupe et promouvoir dans une page.
Par exemple, si vous avez de telles demandes dans votre liste: "Comment apprendre à être enfermée", "Comment apprendre à être pressé à la maison", "Apprenez à appuyer sur la fille". De telles demandes peuvent être combinées dans un groupe et écrire un gros article optimisé en dessous.
Pour accélérer le processus de regroupement, suivez l'analyse des mots-clés dans les pièces (par exemple, si vous avez un site de fitness, alors pendant l'analyse, nous décomposerons les groupes dans lesquels vous inclurez les demandes liées au cou, aux mains et au dos , poitrine, presse, jambes et etc.). Cela facilitera grandement votre travail!
Si les groupes reçus contiendront un petit nombre de requêtes, vous pouvez rester sur ceci. Et lorsque vous vous retrouvez, il s'avère toujours une liste de plusieurs douzaines, voire des centaines de demandes, vous pouvez essayer les méthodes suivantes.
Travailler avec des mots stoppal
Dans Kay, la sélection est la possibilité de spécifier des mots d'arrêt pouvant être utilisés pour marquer des mots-clés indésirables dans la table de requête reçue. De telles demandes sont généralement supprimées du noyau sémantique.
En plus de supprimer les demandes indésirables, cette fonction peut également être utilisée pour rechercher tous les mots nécessaires pour une clé donnée.
Indiquez la clé souhaitée:

La table allouera tous les mots-clés spécifiés:

Nous les transmettons dans un nouvel onglet et il y a déjà manuellement travailler avec toutes les demandes.
Filtration pour le champ "Phrase"
Vous pouvez trouver tous les mots-clés spécifiés dans le paramètre de filtrage pour le champ "Phrase".
Essayons de trouver toutes les demandes que le mot "barres" comprend:

En conséquence, nous obtenons:

Outil "Analyse du groupe"
C'est l'outil le plus pratique pour le regroupement des phrases et leur filtrage manuel supplémentaire.
Allez dans l'onglet "Data" - "Analyse du groupe":

Et c'est ce qui est affiché si vous ouvrez l'un de ces groupes:

Notting de tout groupe de phrases dans cette fenêtre, vous marquez simultanément ou tirez sur la marque avec la phrase dans la table principale avec toutes les demandes.
En tout cas, sans faire à la main, vous ne pouvez pas faire. Mais, grâce au collecteur de Kay, une partie du travail (et pas petit!) Cela a déjà été fait et c'est au moins un peu, mais facilite le processus d'élaboration du site SIA.
Après avoir manipulé manuellement toutes les demandes, vous devriez en parler:

Comment trouver une niche rentable à faible concurrence?
Tout d'abord, vous devez décider vous-même comment vous allez gagner sur votre site Web. Beaucoup de webmasters novices font une seule et même erreur stupide - ils font d'abord des sites sur le sujet qu'ils aiment (par exemple, après avoir acheté un iPhone ou iPada, tout le monde s'exécute immédiatement pour faire le prochain site de "Topics Apple"), puis de commencer Pour comprendre que la concurrence dans cette créneau est très élevée et de briser les premiers endroits de leur govariytique sera pratiquement irréaliste. Ou faites le site culinaire, parce qu'ils aiment cuisiner, puis ils comprennent avec horreur qu'ils ne savent pas comment monétiser ce trafic.
Avant de créer un site, décidez immédiatement comment vous allez monétiser le projet. Si vous avez des sujets de divertissement, la publicité teaser vous conviendra plus probablement. Pour les niches commerciales (dans lesquelles quelque chose à vendre), la publicité contextuelle et la bannière conviendra parfaitement.
Immédiatement, je veux vous dissuader de créer des sites de sujets communs. Sites sur lesquels tout sur tout est écrit maintenant n'est pas si facile à promouvoir, car les sommets ont longtemps été engagés dans des portails de confiance célèbres. Il sera rentable de faire un site novateur étroit, qui, en peu de temps, supervisera tous les concurrents et se consolidera dans le sommet pendant une longue période. Je vous parle d'expérience personnelle.
Mon site étroit-gradratique de sujets médicaux après 4 mois après sa création occupe les premiers endroits de Google et de Yandex, tout en dépassant les plus grands portails généraux médicaux généraux.
Les sites uzkotématiques favorisent plus facilement et plus rapides!
Passons à la sélection d'une niche commerciale pour le site où nous allons gagner sur la publicité contextuelle. À ce stade, vous devez adhérer à 3 critères:

Évaluation de la concurrence dans une certaine niche, j'utilise la recherche dans la région de Moscou, il est généralement plus élevé. Pour ce faire, spécifiez dans les paramètres des régions de votre compte dans Yandex "Moscou":
L'exception est des cas lorsque le site est effectué dans la région spécifique - alors vous devez regarder des concurrents dans cette région.
Les principaux signes de faible concurrence dans l'extradition sont les suivants:
Pas de réponses à part entière à la demande assignée (émission non pertinente).
Il n'y a pas plus de 2-3 pages principales dans le sommet (ils sont également appelés "museaux"). Plus "Mord" signifie que tout le site se déplace délibérément sous cette demande. La page intérieure de votre site dans ce cas favorisera beaucoup plus difficile.
Des phrases inexactes dans l'extrait de l'extrémité disent que la recherche d'informations sur les sites de concurrents est tout simplement manquante ou que leurs pages ne sont pas optimisées du tout sous cette demande.
Un petit nombre de portails thématiques majeurs. Si sur de nombreuses demandes de votre avenir dans le haut Il existe de nombreux grands portails et sites satellites étroits, vous devez comprendre que la niche est déjà formée et la concurrence est très élevée.
Plus de 10 000 demandes par mois pour la fréquence de base. Ce critère signifie que vous ne devriez pas trop pour "réduire" le sujet du site. La niche devrait avoir une quantité suffisante de trafic sur laquelle vous pouvez gagner dans son contexte. Par conséquent, à la demande principale du sujet sélectionné, il devrait y avoir au moins 10 000 demandes par mois sur Vordstatu (sans citations et régions de la région!). Sinon, vous devrez développer un peu de sujet.
En outre, environ l'estimation approximative du nombre de trafic dans la niche peut être utilisé par les statistiques de la présence de sites qui occupent les premières positions en haut. Si ces statistiques sont fermées avec elles, utilisez ensuite
La plupart des MFA-Shnikov expérimentés recherchent des créneaux pour leurs sites de cette manière, mais en utilisant le service ou le programme Micro Niche Finder.
Ce dernier, à la manière, montre le paramètre SOC (0-100 - la requête ne sera libérée que sur l'optimisation interne, 100-2000 - concurrence moyenne). Vous pouvez choisir en toute sécurité des demandes de SOC moins de 300.
Sur l'écran ci-dessous, vous pouvez voir non seulement la fréquence des demandes, mais également le prix moyen du clic, les positions du site sur demande:

Il existe également une puce utile en tant que "acheteurs potentiels de publicité":

Vous pouvez également entrer simplement sur la demande qui vous intéresse et l'analyse et les demandes similaires à celle-ci:

Comme vous pouvez le constater, vous avez toute la photo dans votre visage, il reste seulement de vérifier la concurrence pour chacune des demandes et de choisir le plus intéressant d'entre eux.

Nous évaluons le coût des offres pour les sites de seigle
Voyons maintenant comment vous devez analyser le coût des offres pour les sites RFING.
Nous allons entrer dans les demandes qui vous intéressent:

En conséquence, nous obtenons:

Attention! Nous examinons l'indicateur des spectacles garantis! Le prix approximatif réel du clic sera 4 fois inférieur à celui indiqué par le service.
Il s'avère si vous apportez à la page supérieure du traitement de la sinusite et des visiteurs cliquera sur la publicité, le coût de 1 clic sur la publicité sera égal à 12 roubles (1,55 / 4 \u003d 0,39 $).
Si vous choisissez la région "Moscou et la région", les offres seront encore plus élevées.
C'est pourquoi il est si important de prendre les premiers endroits en haut de cette région.
Veuillez noter que lors de l'analyse des demandes, vous n'avez pas besoin de prendre en compte les demandes commerciales (par exemple, "Acheter une table"). Pour des projets de contenu, vous devez analyser et promouvoir des demandes d'informations («Comment faire de la table avec vos propres mains», «Comment choisir une table pour bureau», «Où acheter une table», etc.).
Où chercher des requêtes pour sélectionner une niche?
1. Allumez le brainstorming, écrivez tous vos intérêts.
2. Ecrivez ce qui vous inspire dans la vie (il peut s'agir d'une sorte de rêve, de relation, de style de vie, etc.).
3. Regardez autour de vous et écrivez toutes les choses qui vous entourent (tout mettre dans un ordinateur portable au sens littéral: stylo, ampoule, papier peint, canapé, chaise, peintures).
4. Quel genre d'activité avez-vous? Peut-être que vous travaillez à l'usine derrière la machine ou dans l'hôpital? Entrez dans le cahier tout ce que vous utilisez au travail.
5. Qu'est-ce que tu vas bien? Écrivez et ceci.
6. Découvrez les annonces dans les journaux, les magazines, les annonces sur les sites, le spam par courrier. Peut-être qu'ils offrent quelque chose d'intéressant ce que vous pourriez faire un site.
Trouvez-vous là des sites avec une fréquentation de 1000-3000 personnes par jour. Regardez le sujet de ces sites et notez les requêtes les plus fréquences qu'ils apportent du trafic. Peut-être qu'il y a quelque chose d'intéressant.
Je vais donner la sélection d'une niche de grille étroite.
Donc, je m'intéressais à une telle maladie que "Heel Spur". Il s'agit d'un microscope très étroit, qui peut être fait un petit site pendant 30 pages. Idéalement, je vous conseille de rechercher des niches plus larges, ce qui pourrait être faite par 100 pages ou plus.
Nous ouvrons et vérifions la fréquence de cette demande (dans les paramètres de la région n'indiquera rien!):

Excellent! La fréquence de la demande principale est supérieure à 10 000. Il y a du trafic dans cette niche.
Maintenant, je veux vérifier la concurrence sur les demandes par lesquelles le site sera promu ("Traitement de Talon Spir", "Traitement du talon shori" "," Talon Spist Comment traiter ")
Je me tourne vers Yandex, je précise dans la région des paramètres "Moscou" et c'est ce que je reçois:

En haut, il existe de nombreuses pages internes de sites médicaux thématiques généraux, de dépasser que nous ne serons pas difficiles pour nous (cela se produira, pas plus tôt de 3-4 mois) et il y a une face de 1 site, qui est affûté à le thème du traitement des éperons de talon.
Le site Web WNOPA est un govariytique de 10 pages (qui, bien que PR \u003d 3) avec présence dans 500 visiteurs. Ce site peut également être dépassé si vous faites un meilleur site et de promouvoir la page principale de cette demande.
Après avoir analysé le sommet pour chacune des demandes, on peut en conclure que ce micronish n'est pas encore occupé.
Maintenant, la dernière étape reste - vérifier les offres.
Allez et entrez nos demandes. Vous n'avez pas besoin de choisir la région, car notre site visitera des personnes russophones du monde entier)
Maintenant, je trouve la moyenne arithmétique de tous les indicateurs de spectacles garantis. Il s'avère 0,812 $. Cet indicateur est divisé par 4, il arrive en moyenne 0,2 $ (6 roubles) pour 1 clic. Pour les sujets médicaux, il s'agit essentiellement d'un indicateur normal, mais si vous le souhaitez, vous pouvez trouver des sujets et des meilleures offres.
Devrais-je choisir une niche similaire pour le site? C'est pour vous résoudre. Je rechercherais des niches plus larges dans lesquelles il y aurait plus de trafic et la meilleure valeur de clic
Si vous voulez vraiment trouver de bons sujets, je vous conseille vivement d'effectuer la prochaine étape!
Faites un panneau avec les colonnes suivantes (je spécifiées les données approximativement):

Le jour où vous devriez donc écrire au moins 25 demandes! Dépensez sur la recherche d'une niche de 2 à 5 jours et vous, à la fin, vous ferez de quoi choisir!
Choisir une niche est l'une des étapes les plus importantes de la création d'un site et si vous réagissez de négocier à lui, vous pouvez supposer que dans le futur, vous venez de jeter votre temps et votre argent.
Comment écrire le bon article optimisé
Lorsque j'écris un article optimisé pour toute demande, j'ai d'abord pensé que ce sont des visiteurs utiles et intéressants. De plus, j'essaie de délivrer le texte pour qu'il soit agréable de lire. À ma compréhension, le texte idéalement décoré doit contenir:
1. Rubrique spectaculaire brillante. C'est le titre d'abord attire l'utilisateur lorsqu'il parcourt la page de résultats de recherche. Notez que le titre doit être complètement pertinent pour ce qui est écrit dans le texte!
2. Le manque de "eau" dans le texte. Je pense que peu d'amours, lorsque ce qui pourrait être écrit en 2 mots, décrit plusieurs feuilles de texte.
3. Simplifiez les paragraphes et les suggestions. Pour que le texte soit plus facile à faciliter, assurez-vous de casser de grandes offres pour courtes, qui sont placées sur une ligne. Simplifier la vitesse complexe. Pas en vain dans tous les journaux et magazines, le texte est publié par de petites propositions dans les colonnes. Ainsi, le lecteur va mieux percevoir le texte et ses yeux ne sont pas fatigués si vite.
Les paragraphes du texte ne doivent pas également être importants. Le texte est préférable d'être perçu, dans lequel il existe alternance de petits et moyens paragraphes. L'idéal sera le paragraphe, qui se compose de 4 à 5 lignes.
4. Utilisez les sous-titres dans le texte (H2, H3, H4). Une personne a besoin de 2 secondes pour "scanner" une page ouverte et décidez de le lire ou non. Pendant ce temps, il passe à travers la page et met en évidence les éléments les plus importants qui l'aident à comprendre ce qui est dépensé dans le texte. Les sous-titres sont exactement l'outil avec lequel vous pouvez accrocher l'attention du visiteur.
Pour que le texte soit structuré, plus facile dans la perception, utilisez un sous-titre pour tous les 2-3 paragraphes.
Veuillez noter que ces balises doivent être utilisées dans l'ordre (de H2 à H4). Par exemple:
C'est ce que vous n'avez pas besoin de faire:
<И3>Sous-titre<И3>
<И3>Sous-titre<И3>
<И2>Sous-titre<И2>
Et vous pouvez donc:
<И2>Sous-titre<И2>
<И3>Sous-titre<И3>
<И4>Sous-titre<И4>
Vous pouvez également être effectué comme suit:
<И2>Comment pomper la presse<И2>
<И3>Comment pomper la presse à la maison<И3> <И3>Comment pomper une presse sur la barre horizontale<И3> <И2>Comment pomper les biceps<И2> <И3>Comment pomper les biceps sans simulateurs<И3>
Dans les textes, vous devez minimiser les mots-clés (pas plus de 2 à 3 fois, en fonction de la taille de l'article). Le texte doit être aussi naturel que possible!
Oubliez la répartition des mots-clés en gras et en italique. C'est un signe clair de dépassement et de Yandex, il n'aime vraiment pas. Sélectionnez uniquement des suggestions importantes, des pensées, des idées (en même temps, essayez d'avoir une clé clé).
5. Utilisez des listes marquées et numérotées dans tous leurs textes, des citations (ne confondez pas avec des citations et des aphorismes de personnes bien connues! Ils ne portent que des pensées importantes, des idées, des conseils), des images (avec des attributs remplis ALT, le titre et la signature). Insérez des vidéos à thème intéressantes dans un article, il est très affecté par la durée des visiteurs de rester sur le site.
6. Si l'article est très important, cela a du sens avec l'aide du contenu et des ancrages de liaison pour faire la navigation dans le texte.
Après avoir effectué tous les changements nécessaires dans le texte, allez-y à travers vos yeux. Est-ce difficile de le lire? Peut-être que certaines suggestions doivent faire encore moins? Ou avez-vous besoin de changer la police en plus lisible?
Ce n'est qu'après que vous êtes satisfait de toutes les modifications du texte, vous pouvez remplir le titre, la description et les mots-clés et l'envoyer à la publication.
Conditions requises pour le titre
Titre (Tist) est un en-tête d'un extrait, qui est affiché dans les résultats de la recherche. Titre du titre et titre dans l'article (un qui est attribué par balise
) Doit différer les uns des autres et en même temps, ils doivent respecter le mot-clé principal (ou plusieurs clés).Conditions requises pour la description.
La description doit être brillante, intéressante. Il doit apporter brièvement le sens de l'article et n'oublier pas de mentionner les mots-clés nécessaires.
Exigences pour les mots-clés.
Entrez ici des mots-clés promotables à travers un espace. Pas plus de 10 pièces.
Donc, comme j'écris des articles optimisés.
Tout d'abord, je choisis des demandes qui seront utilisées dans l'article. Par exemple, je prendrai la demande de base "Comment apprendre à écrire". Conduire dans wordstat.yandex.ru

Wordstat a apporté 14 demandes. Je vais essayer d'utiliser la plupart d'entre eux dans l'article de l'article (suffisamment pour mentionner chaque mot clé). Les mots-clés peuvent et doivent être inclinés, réarrangés par des endroits, remplacer les synonymes pour faire autant que possible. Les moteurs de recherche, la compréhension de russe (surtout Yandex), reconnaissent parfaitement les synonymes et les prendre en compte lors du classement.
La taille de l'article que j'essaie de déterminer sur la taille moyenne des articles du haut.
Par exemple, s'il y a 7 sites dans le top 10, la taille de texte est essentiellement de 4 000 à 7 000 caractères et 3 sites que cet indicateur est très faible (ou élevé), les 3 derniers que je ne prends tout simplement pas attention.
Voici une structure HTML approximative d'un article optimisé par demande "Comment apprendre à appuyer sur":
……………………………
Comment apprendre à pousser 100 ou plus de 2 mois
……………………………
Que devrait être puissant?
……………………………
Régime quotidien
……………………………
……………………………
Programme de formation
Certains optimiseurs conseillent de manière obligatoire d'entrer la clé principale du premier paragraphe. En principe, il s'agit d'une méthode efficace, mais si vous avez 100 articles sur le site, dans chacun desquels dans le premier paragraphe, il y aura une demande promotable, elle peut avoir des conséquences désagréables.
En tout état de cause, nous vous conseillons de ne pas vous habiter sur un système spécifique, expérimenter, expérimenter et expérimenter à nouveau. Et rappelez-vous que si vous voulez faire un site qui adorera des robots de recherche, faites-la aimer par de vraies personnes!
Comment augmenter la fréquentation du site à l'aide d'une simple manipulation avec trop de débordement?
Je pense que chacun de vous a connu une variété de systèmes transfeulants sur les sites, et je suis plus que convaincu que vous n'avez pas attaché beaucoup d'importance à ces régimes. Et en vain. Regardons le premier système de transfinking qui est la plupart des sites. Cependant, il manque encore des liens des pages internes à la maison, mais ce n'est pas si important. Il est important que, dans ce cas, la page de poids principale aura des rubriques de page (qui sont le plus souvent déplacées et fermées de l'indexation dans robots.txt!) Et la page principale du site. Les pages avec enregistrements dans ce cas ont le plus petit poids:

Et maintenant réfléchissons à logiquement: les optimiseurs qui sont engagés dans la promotion de projets de contenu, sont principalement promus aux pages? C'est bon - pages avec des enregistrements (dans notre cas, il s'agit des pages de 3ème niveau). Alors, pourquoi, promouvoir le site par des facteurs externes (liens), avons-nous souvent oublié que des facteurs internes moins importants - les facteurs internes (transfeulage correct)?
Et examinons maintenant le schéma dans lequel les pages internes auront un plus grand poids:

Cela peut être réalisé en ajustant simplement le flux de poids des pages de niveau supérieur, sur la page du 3ème niveau inférieur. Nous n'oublions pas non plus que les pages internes seront également pompées par des liens externes dans d'autres sites.
Comment mettre en place un streaming similaire de poids? Très simple - avec des tags NOFOOLEX NOINDEX.
Regardons le site dans lequel vous devez pomper des pages internes:
Sur la page principale (1 Niveau): Tous les liens internes sont ouverts à l'indexation, les liens externes sont fermés via NOFOWE NOnDex, le lien vers la carte du site est ouvert.
Sur les pages avec des rubriques (2e niveau): Pour l'indexation, des liens vers des pages avec des enregistrements (3ème niveau) et sur la carte du site, tous les autres liens (maison, rubriques, étiquettes, externes sont fermés via Nofollow NOnDex.
Sur les pages avec enregistrements (niveau 3D): Liens ouverts vers la page du même niveau, 3ème niveau et sur la carte du site, tous les autres liens (home, rubriques, étiquettes, externes) Fermer via Nofollow noindex.
Après une telle transfinement a été faite, la carte du site a reçu le poids le plus important, ce qui le distribuait uniformément à toutes les pages internes. Les pages internes, à leur tour, ont été considérablement du poids. Page principale et page Les titres ont le moins de poids, ce que je voulais réellement atteindre.
Poids de la page Je vérifierai en utilisant le programme. Il est utile de voir visuellement la distribution du poids statique sur le site, de la concentrer sur les pages progressables et soulevez ainsi son site dans l'émission de moteurs de recherche, enregistrant considérablement le budget sur des références externes.
Et maintenant, allons au plus intéressant - les résultats d'une expérience similaire.
Thème Femme Site. Des changements de distribution de poids sur le site ont été effectués en janvier de cette année. Une telle expérience apportée +1000 à la fréquentation:

Le site sous le filtre Google, la base de données n'a donc augmenté que dans Yandex:

À l'aube du trafic en mai mois, ne faites pas attention, c'est la saisonnalité (mai
Vacances).
2. Le deuxième site de la matière féminine, les modifications ont également été apportées en janvier:


Ce site est toutefois constamment mis à jour et des liens sont achetés.
TK pour les rédacteurs pour écrire des articles
Le titre de l'article:comment les verts peuvent-ils être utiles?
Unicité: pas inférieur à 95% par ETXT
Taille de l'article: 4 000 à 6 000 caractères sans espaces
Mots clés:
ce qui est utile pour les verts - la clé principale
verts utiles
propriétés utiles de la verdure
bénéficier des verts
Conditions requises pour l'article:
Le mot-clé principal (est indiqué en premier dans la liste) ne doit pas être dans le premier paragraphe, il devrait simplement se rencontrer dans la première moitié du texte !!!
Il est interdit: les mots-clés du groupe dans certaines parties du texte, vous devez distribuer des mots-clés dans tout le texte.
Les mots-clés doivent être mis en évidence en gras (il est nécessaire que vous soyez plus pratique de vérifier la commande)
Les mots-clés doivent s'adapter harmonieusement (il est donc nécessaire d'utiliser non seulement la saisie directe des clés, mais peut également être inclinée, pour changer les mots dans des endroits, utiliser des synonymes, etc.)
Utilisez des sous-titres dans le texte. Dans les sous-titres, essayez de ne pas utiliser l'entrée directe des mots-clés. Faites des sous-titres pour chaque article autant que possible!
Dans le texte, n'utilisez pas plus de 2-3 entrées directes de la demande principale!
Si l'article doit utiliser les mots-clés "Qu'est-ce que les Verts sont utiles" et "plus grandes greens pour une personne", puis écrivez le deuxième mot clé, vous utilisez automatiquement le premier. Autrement dit, il n'y a pas de besoin spécial d'écrire 2 fois la clé, si l'une a déjà la saisie d'une autre clé.
Bonjour, chère blog lecteurs site web. Je veux faire une autre occasion sur le sujet "Sumyader's Collection". Tout d'abord, comme cela devrait être, puis beaucoup de pratique peut être quelque peu maladroite dans ma performance. Alors, paroles. Pour marcher avec les yeux aux yeux bandés à la recherche de bonne chance, j'étais fatigué de l'année après le début de ce blog. Oui, il y avait une "frappe réussie" (devinement intuitif des moteurs de recherche de requêtes fréquemment posés) et il y avait un certain trafic de moteurs de recherche, mais je voulais battre la cible à chaque fois (au moins pour le voir).
Ensuite, elle voulait plus d'automatisation du processus de collecte des demandes et des découvertes "Pacificateurs". Pour cette raison, l'expérience a été de l'expérience avec Kason (et son frère cadet sans rapport) et un autre article sur le sujet. Tout était génial et même simplement merveilleux jusqu'à ce que je me rendais compte qu'il existe un point très important qui reste essentiellement dans les coulisses - Demandes de diffusion des articles.
Pour écrire un article distinct dans une demande distincte est justifiée soit dans des sujets très compétitifs, soit très rentable. Pour les infosites, il s'agit d'un non-sens complet, et vous devez donc fusionner des requêtes sur une page. Comment? Intuitivement, c'est-à-dire Encore aveuglément. Mais toutes les demandes ne s'entendent pas sur une page et ont au moins une chance hypothétique d'aller dans le sommet.
En fait, aujourd'hui, il sera discuté sur le clustering automatique du noyau sémantique via Keyassort (ventilation des demandes de pages et pour les nouveaux sites, il existe également une construction sur la base de la structure, c'est-à-dire des catégories). Eh bien, et le processus de collecte de demandes, nous aurons lieu pour chaque pompier (y compris les nouveaux outils).
Lequel du noyau sémantique est l'assemblée la plus importante?
La collecte des demandes (les fondements du noyau sémantique) pour l'avenir ou le site déjà existant est le processus est assez intéressant (à une personne comme, bien sûr) et mis en œuvre peut être plusieurs façons, dont les résultats peuvent ensuite être combinés en un Grande liste (en double torsadée, suppression de sucettes sur les mots de pied).
Par exemple, vous pouvez commencer manuellement à terrifier le WordStat, et en plus de connecter le Kecikelector (ou sa version gratuite intolérable). Cependant, tout est formidable lorsque vous êtes plus ou moins familier avec le thème et connaissez les clés auxquelles vous pouvez compter sur (collecter leurs dérivés et des demandes similaires de la colonne de droite du WordStat).
Sinon (oui, et dans tous les cas, cela n'empêche pas) Il sera possible de commencer par les outils de "broyage grossier". Par example, Serpstat. (Dans le principal prodvigator), ce qui vous permet de "voler" vos concurrents pour les mots-clés que vous utilisez (voir). Il existe d'autres services similaires de "concurrents volants" (Spywords, Keys.so), mais je suis "cuit" précisément à l'ancien progresseur.
En fin de compte, il y a un bouchon libre qui vous permet de commencer très rapidement à assembler des demandes. Vous pouvez également commander un déchargement privé de la base de données Ahrefs Monster et obtenez à nouveau les clés de vos concurrents. En général, il convient de considérer tout ce qui peut apporter au moins un tolérique utile pour la promotion de la promotion future, qui n'est pas si difficile à nettoyer et à combiner en une grosse (souvent même une énorme liste).
Tout cela nous (en termes généraux, bien sûr), considérons un peu plus bas, mais à la fin monte toujours la question principale - que faire ensuite. En fait, il est terriblement évolué de simplement approcher ce que nous avons reçu en conséquence (en cognant une douzaine de concurrents et des hurleurs sur le Kason Slaving). La tête peut éclater d'essayer de casser toutes ces demandes (mots-clés) sur certaines pages du site futur ou déjà existant.
Quelles demandes réussiront sur une page et qu'est-ce que vous n'essayez même pas d'unir? Une question très difficile, que j'ai précédemment décidée purement intuitivement, d'analyser l'émission de Yandex (ou de Google) pour le sujet "et comme dans les concurrents" massacre manuellement et que les options d'automatisation ne sont pas entrées. Eh bien, pour le moment. Tout de même, un tel outil "surfacé" et aujourd'hui sera discuté dans la dernière partie de l'article.
Ce n'est pas un service en ligne, mais une solution logicielle distribue laquelle vous pouvez télécharger Sur la page principale du site officiel (version de démonstration).

Par conséquent, il n'y a pas de restrictions sur le nombre de demandes recouvrables - combien vous avez besoin, autant et le processus (il y a cependant les nuances de la collecte de données). La version payante coûte moins de deux mille, qui est pour des tâches résolues, vous pouvez dire, pour rien (IMHO).
Mais sur le côté technique de Keyassort, nous allons parler juste ci-dessous et je voudrais ici dire de moi-même le principe qui vous permet de scinder une liste de mots-clés (presque toutes les longueurs) sur des grappes, c'est-à-dire Un ensemble de mots-clés pouvant être utilisés avec succès sur une page du site (optimiser le texte, les titres et la masse de référence sous eux - Appliquez SEO Magic).
Où puis-je dessiner des informations? Qui vous dira que "Burns", mais qu'est-ce qui ne fonctionnera pas de manière fiable? De toute évidence, le meilleur conseil sera le moteur de recherche lui-même (dans notre cas, Yandex, en tant que magasin de demandes commerciales). Il suffit de regarder une grande quantité d'émission de données (par exemple, d'analyser le top 10) de toutes ces demandes (de la liste collectée du futur Semililar) et il est entendu que vous avez réussi à combiner avec succès sur une page. Si cette tendance est répétée plusieurs fois, nous pouvons parler de modèles et, sur la base de celui-ci, vous pouvez déjà battre les classes aux clusters.
KeyAssort vous permet de définir "Rigor" dans les paramètres, avec lesquels des clusters seront formés (sélectionnez les touches que vous pouvez utiliser sur une page). Par exemple, pour le commerce, il est logique de resserrer les exigences de sélection, car il est important d'obtenir un résultat garanti, mais avec une dépense légèrement importante sur la rédaction de textes à un plus grand nombre de grappes. Pour les sites d'information, vous pouvez inversement à faire de la détente pour que vous ayez moins d'efforts pour obtenir un trafic potentiellement plus important (avec un risque légèrement important de «non-combustion»). Comment recommencer à parler.
Et que faire si vous avez déjà un site avec un tas d'articles, mais que vous voulez développer des semences existantes Et optimiser les articles déjà disponibles sous un plus grand nombre de clés, afin de minimiser les efforts (un peu de transfert des touches d'accent) pour obtenir du trafic sur le trafic? Ce programme et cette question donnent la réponse - vous pouvez demander aux pages existantes dans lesquelles les pages existantes sont déjà optimisées, de faire un cluster avec des demandes supplémentaires, qui sont tout à fait promus avec succès (sur une seule page) à votre édition de la publication. Fait intéressant, il se trouve ...
Comment assembler un pool de demandes de sujet dont vous avez besoin?
Tout noyau sémantique commence, en fait, de collecter un grand nombre de demandes, dont la plupart seront jetés. Mais la principale chose est que, à la phase initiale, ils l'ont frappé les «perles», qui seront créées et les pages individuelles de votre avenir ou déjà un site existant sera créée et avancée. À ce stade, le plus important est probablement de marquer autant de requêtes plus ou moins appropriées et de ne rien manquer, et les pacificateurs sont alors faciles à couper.
Une juste question se pose et quels outils pour cette utilisation? Il y a une réponse sans ambiguïté et très correcte - différente. Le plus gros le meilleur. Cependant, ces méthodes la plupart des méthodes de collecte du noyau sémantique, probablement, il convient de la liste et de donner des évaluations générales et des recommandations pour leur utilisation.
- Yandex WordStat Et ses analogues dans d'autres moteurs de recherche - initialement, ces outils étaient destinés à ceux qui placent la publicité contextuelle de manière à comprendre à quel point les phrases populaires des utilisateurs de moteur de recherche sont aussi populaires. Eh bien, il est clair que les sosters sont également utilisés par ces instruments et très avec succès. Je peux recommander de courir à travers l'article par l'article, ainsi que l'article mentionné au tout début de cette publication (il sera utile pour les débutants).

Des inconvénients de l'eau, on peut noter:
- La monstrueusement beaucoup à la main (l'automatisation est définitivement requise et elle sera considérée comme légèrement inférieure), à \u200b\u200bla fois en brisant les phrases basées sur la clé et en brisant les requêtes associatives de la colonne de droite.
- Limitant la délivrance du WordStat (2000 requêtes et non une ligne de plus) peut devenir un problème, car, pour certaines phrases (par exemple, «travail»), il est extrêmement petit et nous manquons le type de basse fréquence, et parfois même moyen -Les requêtes qui peuvent apporter un bon trafic et des revenus (après tout, beaucoup sont manquants). Il est nécessaire de "contraindre beaucoup" ou d'utiliser des méthodes alternatives (par exemple, des bases de données de mots-clés, dont nous allons examiner ci-dessous - tandis que c'est gratuit!).
- Caicollecteur (et son frère cadet gratuit Slovoeb.) - Il y a quelques années, l'apparition de ce programme était simplement "salut" pour de nombreux ouvriers du réseau (et il est maintenant assez difficile d'imaginer sans QC). Paroles de chanson. J'ai acheté le CC pour deux de plus ou trois ans, mais je les ai utilisés de la force pendant plusieurs mois, car le programme est lié à la glande (rembourrage du compartiment) et cela me change plusieurs fois par an. En général, avoir une licence pour le QC que j'utilise SE - c'est pourquoi j'apporte trop de paresseux.

Vous pouvez lire les détails de l'article "". Les deux programmes vous aideront à collecter des demandes et à partir de la droite et de la colonne de gauche du WordStat, ainsi que des conseils de recherche sur les phrases clés dont vous avez besoin. Les conseils sont ce qui tombe de la chaîne de recherche lorsque vous commencez à taper la demande. Les utilisateurs souvent sans terminer l'ensemble choisissent simplement l'option la plus appropriée dans cette liste. CECES Cette entreprise demandait et utilise de telles demandes d'optimisation et même.
CK et SE vous permettent de composer immédiatement un très grand pool de demandes (cependant, il peut être nécessaire de prendre beaucoup de temps, ou d'acheter des limites XML, mais à ce sujet est légèrement inférieure) et il est facile de saisir les sucettes, car Exemple, vérifiant la fréquence des phrases prises dans des guillemets (enseigner le match, si vous ne comprenez pas quel discours - liens au début de la publication) ou demandez à la liste des mots d'arrêt (particulièrement pertinents pour le commerce). Après cela, l'ensemble du bassin de demandes peut être facilement exporté vers Excel pour plus de travaux ou de télécharger sur KeyAssort (Clusterizer), qui sera discuté ci-dessous.
- Serpstat. (Et d'autres services similaires) - vous permet d'introduire une UL de votre site pour obtenir une liste de vos concurrents pour émettre Yandex et Google. Et pour chacun de ces concurrents, il sera possible d'obtenir une liste complète de mots-clés, pour lesquelles ils ont réussi à percer et à atteindre certaines sommets (obtenir le trafic des moteurs de recherche). Le tableau récapitulatif contiendra la fréquence de la phrase, le site du site sur celui-ci en haut et un groupe d'autres informations utiles et non très différentes.

Il n'y a pas si longtemps, j'ai utilisé presque le plan tarifaire Serpstata le plus cher (mais seulement un mois) et a réussi à sortir pour cette période dans Excel presque gigaoctets de différents clutters. J'ai cueilli non seulement les clés des concurrents, mais aussi juste un pool de demandes de personnes qui m'intéressent des phrases clés et a également rassemblé le semiomère des pages les plus prospères de ses concurrents, qui me semble-t-il aussi très important. Une mauvaise chose - maintenant, je ne trouverai aucun temps de fermer au traitement de toutes ces informations inestimables. Mais il est possible que KeyAssort élimine toujours la déconnexion avant la transformation de Monstrous Mahuina.
- Bukvilk - Base de mots-clés gratuite dans votre propre shell logiciel. La sélection des adoriens clés prend une fraction de seconde (déchargement à la minute d'excellence). Combien de millions de mots ne se souviennent pas, mais des critiques sur elle (y compris la mienne) sont simplement géniales, et surtout tout cela est la richesse gratuitement! Vrai, la distribution du programme pèse 28 concerts et sous forme fractionnée, la base occupe plus de 100 Go sur le disque dur, mais il s'agit de toutes les petites choses comparées à la simplicité et à la rapidité de demander un pool de demandes.

Mais non seulement le taux de collecte de la sécurité est le principal avantage par rapport au WordStat et au Kason. L'essentiel est qu'il n'y a pas de restrictions sur 2000 lignes pour chaque demande, ce qui signifie qu'il n'y a pas de LF et sur le LF de notre part ne sera pas échaudé. Bien entendu, la fréquence peut être clarifiée pour être clarifiée à travers le même QC et sur les mots d'arrêt pour effectuer un examinateur, mais la tâche principale du Bundler effectue grand. Vrai, le tri des colonnes ne fonctionne pas pour lui, mais la conservation du pool de demandes d'excellence peut être triée comme élégante.
Probablement, au moins quelques outils "sérieux" de la cathédrale de la piscine des demandes vous donneront des commentaires et je les emprunterai avec succès ...
Comment nettoyer les requêtes de recherche collectées de "Dusties" et "Garbage"?
La liste obtenue à la suite de la manipulation ci-dessus est susceptible d'être très grande (sinon énorme). Par conséquent, avant de le télécharger sur le cluster (nous aurons un keyassort) il est logique de le nettoyer légèrement. Pour ce faire, le pool de demandes, par exemple, peut être déchargé sur Kecikelecter et supprimer:
- Demandes avec une fréquence trop basse (personnellement, je brise la fréquence entre guillemets, mais sans marques d'exclamation). Quel seuil de choisir de vous résoudre et que, à bien des égards, cela dépend du sujet, de la compétitivité et du type de ressource, qui va à la graine.
- Pour les demandes commerciales, il est logique d'utiliser une liste de mots d'arrêt (type, "Gratuit", "Télécharger", "Essai", ainsi que, par exemple, les noms des villes, l'année, etc.) pour supprimer le fait qu'il ne conduira pas au site des acheteurs ciblés (couper les congélateurs, la recherche d'informations, pas des biens, des puits et des résidents d'autres régions, par exemple).
- Parfois, il est logique d'être guidé par l'indicateur de la concurrence sur cette demande d'extradition. Par exemple, sur demande "Windows en plastique" ou "climatiseurs", vous ne pouvez même pas crier - l'échec est fourni à l'avance et avec une garantie de 100%.
Dis-moi que c'est trop facile des mots, mais c'est difficile à réellement. Et voici pas. Pourquoi? Et parce qu'un cher homme (Mikhail Shakin) n'a pas regretté le temps et enregistré une vidéo avec détaillé description des méthodes de nettoyage des requêtes de recherche dans le collecteur de clés:
Merci pour cela, car cette question est beaucoup plus facile et plus claire de montrer quoi décrire dans l'article. En général, manipulez, car je crois en toi ...
Configuration du cluster de semences KeyAsTort pour votre site
En fait, le plus intéressant commence. Maintenant, toute cette énorme liste de clés devra en quelque sorte diviser (dispersion) sur les pages individuelles de votre futur ou un site Web déjà existant (que vous souhaitez améliorer de manière significative en termes de trafic progressable). Je ne répéterai pas et ne parlerai pas des principes et de la complexité de ce processus, car alors j'ai écrit la première partie de cela.
Donc, notre méthode est assez simple. Nous allons sur le site officiel de Keyassort et téléchargez la version de démonstrationPour essayer un programme à la dent (la différence entre la démo de la version complète est l'incapacité de décharger, alors vous voulez exporter le grenage collecté), et le contournement déjà peut être payé et payable (1900 roubles - peu, peu de temps moderne réalités). Si vous souhaitez commencer immédiatement à travailler sur le noyau ce qu'on appelle «sur le Castovik», il est préférable de choisir la version complète avec la possibilité d'exporter.
Le programme KeiSsort lui-même n'est pas capable de collecter des clés (c'est-à-dire en fait et non sa prérogative), et ils seront donc nécessaires pour les télécharger. Vous pouvez le faire de quatre manières - manuellement (probablement, il y a un sens de recourir à cette méthode pour ajouter une partie de la collecte de clé majeure déjà trouvée), ainsi que trois façons de paquet d'importer des clés:
- au format TCT - lorsque vous devez importer une liste des touches (chacune sur une ligne distincte de fichier TCT et).
- outre deux options pour le format Exeline: avec les paramètres dont vous avez besoin à l'avenir, ou avec les sites collectés de la top10 pour chaque touche. Ce dernier peut accélérer le processus de clustering, car le programme KeyAsort n'a pas à égaler ces données. Cependant, les ulles du top10 doivent être fraîches et précises (une telle version de la liste peut être obtenue, par exemple dans un KecikelectSer).
Oui, qu'est-ce que je vous dis - il vaut mieux voir une fois:
En tout cas, au début, n'oubliez pas de créer un nouveau projet dans le même menu "Fichier", et il ne s'agira que d'une fonction d'importation abordable que:

Exécutons sur les paramètres du programme (l'avantage d'eux est un peu un peu), car pour différents types de sites, il peut s'agir de différents paramètres différents. Ouvrez l'onglet "Service" - "Paramètres du programme" et vous pouvez immédiatement aller à l'onglet "Clusterization":

Ici la chose la plus importante est, peut-être, choisir le type de clustering dont vous avez besoin. Le programme peut utiliser deux principes pour lesquels les demandes sont combinées en groupes (clusters) sont difficiles et mous.
- Difficile - Toutes les demandes tombées dans un groupe (adaptées à la promotion sur une page) doivent être combinées sur une page du nombre de concurrents requis du sommet (ce numéro est défini dans la ligne "Puissance de la GROUPE").
- Soft - Toutes les demandes qui sont tombées dans un groupe se réuniront partiellement sur une seule page du nombre de concurrents et de sommets souhaités (ce numéro est également défini dans le groupe "Puissance du groupement").
Il y a une bonne image. Il illustre vivement tout cela:

Si ce n'est pas clair, alors cela ne vous dérange pas, car c'est juste une explication du principe, et nous ne sommes pas importants pour nous, mais la pratique qui dit que:
- La clusterisation dure est préférable de demander des sites commerciaux. Cette méthode donne une précision élevée, grâce auxquelles la probabilité d'entrer dans le haut sur une page sur une page du site du site sera plus élevée (avec une approche appropriée pour optimiser le texte et sa promotion), bien que les demandes elles-mêmes soient moins dans le cluster et Par conséquent, les grappes eux-mêmes sont plus (plus devra créer et promouvoir).
- La clusterisation douce est logique d'utiliser des sites d'informationPour que les articles soient obtenus avec une forte plénitude de complétude (pourra répondre à un nombre similaire au sens des demandes des utilisateurs), qui est également prise en compte dans le classement. Et les pages elles-mêmes seront plus petites.
Un autre important, à mon avis, la tique est une tique dans le domaine "Utilisez des phrases de marqueur". Pourquoi cela peut-il en avoir besoin? Voyons voir.
Supposons que vous ayez déjà un site Web, mais les pages de celui-ci ont été optimisées non sous la piscine des demandes, mais pour une personne, ou ce pool que vous considérez pas assez en vrac. Dans le même temps, vous voulez tout cœur à développer SEYEDRO non seulement en ajoutant de nouvelles pages, mais également en améliorant les personnes déjà existantes (il est toujours plus facile en termes de mise en œuvre). Donc, vous avez besoin de chacune de ces pages pour empêcher les semences «à la fin».
C'est pour cela que vous avez besoin de ce paramètre. Après son activation en face de chaque phrase dans votre liste de demandes, vous pouvez mettre une tique. Vous ne trouverez que ces demandes majeures que vous avez déjà optimisées les pages existantes de votre site (une par page) et le programme KeyAssorT construira des clusters autour d'eux. En fait, tout. En savoir plus «fumée» dans cette vidéo:
Une autre importante (pour le bon fonctionnement du programme), la définition vit sur l'onglet "Collecte de données avec Yandex XML". Vous pouvez lire dans l'article. Si vous avez brièvement, les Soshers analysent constamment la délivrance de Yandex et la délivrance du WordStat, créant une charge excessive sur son pouvoir. Pour une protection, un CAPTCHA a été introduit, ainsi que l'accès spécial XML au XML, où le CAPTCHA n'atteindra et déformera des données sur des touches vérifiées. Vrai, le nombre de tels chèques par jour sera strictement limité.
À quoi dépendent le nombre de limites dédiées? De comment Yandex aura noté votre. Vous pouvez aller sur ce lien (tandis que dans le même navigateur, où vous êtes connecté dans YA.VESBMASTER). Par exemple, cela ressemble à ceci:

Il existe toujours un calendrier inférieur de la répartition des limites par heure de la journée, ce qui est également important. Si les demandes doivent être coulées beaucoup et que les limites ne suffisent pas, alors pas un problème. Ils peuvent être achetés. Pas yandex, bien sûr, directement et ceux qui ont ces limites, mais ils n'en ont pas besoin.
Le mécanisme YANDEX XML vous permet de transmettre des limites et les échanges liés à être des intermédiaires aident tout cela automatiser. Par exemple, sur Xmlproxy Vous pouvez acheter des limites pour seulement 5 roubles pour 1000 demandes, ce qui, vous voyez, pas assez cher.
Mais ce n'est pas important, car vous avez acheté des limites qui vous déplacent encore sur "Compte", mais de les utiliser à Keyassort, vous devrez aller à l'onglet " Réglage"Et copiez un lien long vers le champ" URL pour les demandes "(N'oubliez pas de cliquer sur" Votre adresse IP actuelle "et de cliquer sur le bouton" Enregistrer "pour lier la clé de votre ordinateur):

Après cela, insérez uniquement cet UL dans la fenêtre avec les paramètres KeyAssort dans le champ "URL pour enquête":

En fait, tout, avec les paramètres Keyassort, est terminé - vous pouvez commencer à regrouper le noyau sémantique.
Clustering Key Phrases à Keyassort
Donc, j'espère que vous êtes tous configurés (choisissez le type de clustering souhaité, connecté vos limites ou achetées de YANDEX XML), traitées avec les moyens d'importer une liste avec des demandes, bien et avec succès tout ce cas a été transféré à KeiasSort. Et après? Et puis exactement le plus intéressant consiste à commencer à collecter des données (sites des sites TOP10 sur chaque demande) et le clustering ultérieur de la liste entière basée sur ces données et les paramètres que vous apportez.
Donc, pour commencer, cliquez sur le bouton "Collecter des données" Et nous nous attendons à quelques minutes à plusieurs heures, tandis que le programme dure sur toutes les demandes de la liste (qu'elles n'en sont plus, l'attente plus longue):

J'ai trois cents demandes (il s'agit d'un petit noyau pour une série d'articles sur le travail sur Internet) a parcouru une minute. Après quoi vous pouvez déjà passer directement à la clusterisationLe même bouton est disponible sur la barre d'outils KeyAsTort. Ce processus est très rapide et littéralement après quelques secondes, j'ai reçu un ensemble complet de rouleaux (groupes) décorés sous la forme de listes investies:

Pour plus de détails sur l'utilisation de l'interface de programme, ainsi que sur environ création de clusters pour les pages de site existantes Voir mieux dans la vidéo, car il est tellement plus clair:
Tout ce que nous voulions, nous avons eu et remarquez - sur l'automate complet. Lépoty.
Bien que si vous créez un nouveau site, à l'exception du clustering est très important. notez la structure future du site (Déterminez les sections / catégories et distribuez des clusters pour les pages à venir). Curieusement, mais il est tout à fait pratique de faire à Keyassort, mais la vérité n'est plus automatiquement, mais en mode manuel. Comment?
Il sera plus facile de voir une fois de plus - tout se propage littéralement devant les yeux de la simple traînée de grappes de la fenêtre gauche du programme dans la droite:
Si vous avez acheté le programme, vous pouvez exporter le noyau sémantique obtenu (et la structure du site futur) dans Excel. De plus, sur la première onglet avec les demandes, il sera possible de fonctionner comme une seule liste, et la structure sera déjà enregistrée sur la seconde que vous avez configurée dans KeyAsort. Très très pratique.
Eh bien, peu importe comment. Prêt à discuter et à entendre votre opinion sur la collection de semeurs pour le site.
Bonne chance à toi! À des réunions ambiguës sur le site Web des pages de blog
Vous pouvez être intéressé
VPODSKAZKE - Nouveau service pour promisquer des invites dans les moteurs de recherche SE Classement - Le meilleur service de surveillance des services pour débutants et professionnels en SEO Collecte du noyau sémantique complet dans le toppoolosor, la variété des moyens de sélectionner des mots-clés et de leurs pages de regroupement La pratique de la collecte du noyau sémantique sous le référencement d'un professionnel - comment cela se produit dans la réalité actuelle 2018 Optimisation des facteurs comportementaux sans tricherie SEO PowerSite - Auditeur de site Web, Rank Tracker et External (SEO Spyglass, LinkAssistant) Optimisation du site Sélection de mots-clés dans Yandex WordStat - Analyse des statistiques manuellement et en utilisant Slovoeb ou Collecteur de clés  Serpstat - Aperçu de la "surveillance des postes" Outils, "Clustering" et "Text Analytics"
Serpstat - Aperçu de la "surveillance des postes" Outils, "Clustering" et "Text Analytics"


