Internet jest jak ogromna światowa biblioteka, która ma tylko jedną, ale istotną różnicę: aby szukać książki w bibliotece jest katalog, w skrajnych przypadkach można zwrócić się do doświadczonego bibliotekarza. Nie ma pełnego katalogu Internetu. Niemniej jednak wyszukiwanie w globalnej sieci komputerowej jest możliwe i jest to być może jeden z najważniejszych jego aspektów. Do wyszukiwania danych w sieci wykorzystywane są specjalne serwery, o których informacje są utrzymywane i aktualizowane niemal automatycznie.
Dziś, gdy internet stał się jednym z głównych źródeł informacji, wyszukiwanie w internecie nabiera coraz większej wartości praktycznej. Jednak wraz z szybkim wzrostem ilości dostępnych danych sama procedura wyszukiwania staje się coraz bardziej skomplikowana.
Internet to globalna sieć komputerowa, która łączy zarówno użytkowników sieci komputerowych, jak i użytkowników komputerów PC. Internet powoli, ale nieuchronnie staje się głównym środkiem komunikacji korporacyjnej, ustępując dotychczas miejsca telefonowi.
W sieci jest ogromna ilość zasobów informacyjnych. Według niektórych szacunków liczba dokumentów przekroczyła 65 milionów i nadal szybko rośnie. Taka ilość informacji wymaga prawidłowej organizacji procesu wyszukiwania i użycia specjalnych środków technicznych, takich jak wyszukiwarki. Proste wyszukiwanie dość powszechnego słowa kluczowego daje zwykle od kilkudziesięciu tysięcy do kilku milionów linków. Oczywistym jest, że praca z tak dużą liczbą dokumentów jest praktycznie niemożliwa, zwłaszcza że w przeważającej większości zawierają one informacje nieistotne.
Źródła informacji w Internecie różnią się sposobem prezentacji informacji, a co za tym idzie sposobem dostępu do nich.
1 NARZĘDZIA WYSZUKIWANIA
1.1 Narzędzia wyszukiwania plików
Ręczne odnalezienie pliku w złożonej strukturze katalogów serwera FTP może zająć dużo czasu. Aby uprościć i przyspieszyć wyszukiwanie, opracowano usługę wyszukiwania internetowego Archie, która jest specjalnym serwerem Archie, który przechowuje zawartość katalogów anonimowych serwerów ftp. Podczas adresowania zapytania wyszukiwania na serwerze Archie wynikiem wyszukiwania jest lista adresów anonimowych serwerów FTP, które mają żądany plik.
Pojawia się jednak zadanie znalezienia pożądanego wśród zestawu plików na tym serwerze, co jest dość trudne ze względu na niejasne i niezrozumiałe nazwy plików i katalogów. Do rozwiązania tego problemu wykorzystywany jest system Gopher, który pozwala na poruszanie się po systemie menu kontekstowych, pokazujących zawartość plików za pomocą zrozumiałych notacji. Istnieje wiele serwerów Gopher, które zawierają archiwa danych w postaci katalogów o strukturze hierarchicznej, uporządkowanych według zawartości. Praca z nimi jest bardzo prosta i odpowiada pracy z normalnym wyświetlaczem systemu plików.
Istnieje rozszerzenie tego systemu - Veronica, które zawiera w swojej bazie katalogi wszystkich serwerów Gopher. Po wprowadzeniu zapytania wyszukiwania Veronica automatycznie skanuje wszystkie katalogi Gopher w poszukiwaniu informacji, których szukasz, eliminując w ten sposób potrzebę ręcznego przeszukiwania wielu serwerów Gopher.
Dzięki temu sposobowi nawigacji Gopher był w pewnym stopniu poprzednikiem WWW. Obecnie wykorzystanie Gopher maleje proporcjonalnie do wzrostu wykorzystania WWW.
1.2 Narzędzia WWW - WorldWideWeb
W 1993 roku opracowano system wyszukiwania informacji WWW, który ze względu na łatwość nawigacji i dostępność otwierał źródła informacji w Internecie dla nieprzygotowanych użytkowników. WWW spowodowało boom internetowy, który trwa do dziś, a ilość informacji dostępnych w Internecie podwaja się z roku na rok.
WWW opiera się na zasadzie hipertekstu (znanego już czytelnikowi), czyli na systemie dokumentów połączonych hiperłączami. Hipertekst to specjalny sposób wyróżniania słów kluczowych ze zwykłego tekstu. Łącza hipertekstowe odsyłają użytkownika do innych dokumentów na tym samym serwerze lub do innych serwerów, które mogą znajdować się w dowolnym miejscu w Internecie. Jeśli ten dokument tekstowy jest również hipertekstem, jego linki pozwalają przejść dalej do odpowiednich dokumentów. Każde przekierowanie następuje niepostrzeżenie dla użytkownika, dzięki czemu może on w sensowny sposób przeglądać strukturę informacji w Internecie, nie martwiąc się o adresowanie konkretnych komputerów.
Wraz z rozwojem aplikacji multimedialnych, początkowo dokumenty czysto hipertekstowe w coraz większym stopniu stają się hipermediami. Dokumenty WWW mogą więc istnieć w dowolnym formacie danych: tekstowym, graficznym, dźwiękowym/muzycznym lub wideoklipem. Orientacja i nawigacja w sieci WWW odbywa się za pomocą specjalnych programów zwanych przeglądarkami WWW, które zapewniają interfejs użytkownika, takich jak NetscapeNavigator lub MicrosoftInternetExplorer.
Punktem wyjścia do wyszukiwania informacji jest z reguły główna (bazowa, główna) strona (witryna) zasobu informacyjnego, do którego można się dostać, wpisując odpowiedni adres w przeglądarce (na przykład http: //ncpi .gov.by lub www.iparegistr.com). Strony WWW są tworzone i aktualizowane przez firmy lub specjalne organizacje, które publikują informacje i monitorują zawartość swoich stron WWW. Korzystanie z WWW nie jest zatem pasywne, a każdy internauta za pomocą specjalnych programów do edycji hipertekstu może samodzielnie tworzyć własne interaktywne strony WWW. To utorowało drogę do rosnącej komercjalizacji i ekspansji Internetu.
Obecnie nowo tworzone informacje z reguły są tworzone z uwzględnieniem konieczności zapewnienia dostępu przez WWW, a wcześniejsze dokumenty są dla nich stopniowo konwertowane, ale na całym świecie wciąż istnieją miliony plików w formach innych niż wymagania WWW. W celu korzystania z tych informacji oraz za pośrednictwem WWW, powyższe usługi internetowe zawarte są w przeglądarkach zapewniających do nich dostęp (telnet, ftp, Archie, Gopher). Za pośrednictwem WWW można również korzystać z innych serwisów internetowych przeznaczonych do komunikacji (eMail, NetNews). Dlatego przeglądarka WWW stała się obecnie uniwersalnym programem komunikacyjnym dla Internetu.
Wraz z pojawieniem się serwisu WWW rozpoczął się boom internetowy. To łatwe w użyciu, przyjazne dla użytkownika środowisko dla wszystkich usług przyciągnęło zainteresowanie wielu osób i organizacji w Internecie. Nagle okazało się, że nie trzeba być ekspertem od Internetu, aby korzystać z usług sieci. Można to porównać do sukcesu firmy Microsoft w udostępnianiu systemu Microsoft Windows jako graficznego interfejsu użytkownika. Przed Windows każda aplikacja DOS miała swój własny podręcznik użytkownika i dlatego wymagała osobnego przestudiowania każdej aplikacji.
2 PODSTAWOWE METODY WYSZUKIWANIA INFORMACJI W INTERNECIE
2.1 Podstawowe wymagania dotyczące wyszukiwania
Na wyniki wyszukiwania nakładane są wymagania dotyczące kompletności pokrycia zasobów, wiarygodności otrzymanych informacji, minimalnego nakładu czasu i maksymalnej szybkości wyszukiwania.
Wymóg kompletności pokrycia zasobów nie wymaga dodatkowych wyjaśnień, z wyjątkiem konieczności wykorzystania zasobów nie tylko dla WWW, ale także dla innych usług internetowych podczas wyszukiwania.
Wiarygodność informacji, biorąc pod uwagę specyfikę Internetu, staje się niezwykle ważnym wymogiem. Ocenę rzetelności można przeprowadzić zarówno metodami tradycyjnymi (sprawdzenie legalności publikacji na papierze, uzyskanie informacji o organizacjach i autorach, sprawdzenie aktualności ich zasobów elektronicznych itp.), jak i z wykorzystaniem możliwości Internetu (zapoznanie z alternatywnymi źródłami informacji, uzgodnienie materiału faktycznego, ustalenie częstotliwości jego wykorzystania przez inne źródła, poznanie statusu dokumentu i oceny źródła za pomocą wyszukiwarek, uzyskanie informacji o kompetencjach i statusie autora materiału za pomocą specjalnych usług wyszukiwania w Internecie, analiza poszczególnych elementów organizacji strony w celu oceny kwalifikacji wspierających ją specjalistów i nie tylko).
Czas wyszukiwania, nie licząc czasu spędzonego na specyfikacji połączenia, jest w dużej mierze zależny od planowania wyszukiwania i umiejętności specjalisty wyszukiwania w zakresie wybranego typu zasobów. Planowanie wyszukiwania polega na określeniu usług wyszukiwania wymaganych do rozwiązania żądania wyszukiwania oraz kolejności ich stosowania. Ponadto wiele zależy od umiejętności i doświadczenia konkretnego specjalisty ds. wyszukiwania.
Jak już wspomniano, informacje w Internecie są dostępne z różnego rodzaju źródeł. Przede wszystkim są to zasoby WWW (system hipertekstowy, katalogi zasobów, wyszukiwarki). Ponadto jest już znany czytelnikowi poczty e-mail, robotów pocztowych, Usenetu i innych grup dyskusyjnych, a także systemów ftp i archiwów (przy użyciu Gopher i Veronica). WWW umożliwia wyszukiwanie wymaganych zasobów w oparciu o swoje hiperwłaściwości, czyli istniejące wyszukiwarki działają z wykorzystaniem hiperłączy w trybie automatycznym, nie wykluczając możliwości ręcznego przeglądania. WWW oferuje szereg ogólnych i specjalistycznych usług wyszukiwania.
Katalogi zasobów to bazy danych z adresami zasobów internetowych i różnymi tematami. Zwykle mają strukturę hierarchiczną znaną użytkownikowi i pewne sposoby jej przeszukiwania. W większości katalogi te są obsługiwane przez specjalistów od klasyfikacji, to znaczy z góry określone jest pewne subiektywne podejście do selekcji informacji, co z jednej strony gwarantuje niejako wiarygodność informacji, ale z drugiej strony predeterminuje możliwość braku (pominięcia) niektórych informacji, a także wszelkie spóźnione umieszczenie w katalogu.
Wyszukiwarki to mechanizm automatycznego budowania linków (indeksów) do różnych zasobów. Wyszukiwarki mogą kierować reklamy na zasoby globalne, specjalistyczne lub lokalne. W rzeczywistości są to potężne IRS, które za pomocą specjalnych programów robotów (tak zwanych „pająków”) stale przeprowadzają automatyczne wyszukiwanie wymaganych informacji w Internecie. Tworzone na tej podstawie specjalistyczne bazy danych zapewniają wyszukiwanie informacji na podstawie żądań użytkowników na podstawie specjalnych IPL. To prawda, że zasięg przeglądanych informacji zależy od zastosowanych algorytmów i nawet w przypadku potężnych wyszukiwarek pozostawia wiele do życzenia.
Poczta elektroniczna jest wykorzystywana w Internecie i WWW. W takim przypadku adresy trafiają do wyszukiwarek i są dostępne dla wyszukiwarek.
Roboty pocztowe to specjalne programy zdolne do reagowania pewnymi akcjami na otrzymane przez nie polecenia, ale za pośrednictwem poczty e-mail. Ich głównym celem jest przesyłanie danych na żądanie w przypadku, gdy nie są one dostępne w inny sposób, a także jako alternatywa dla pracy online z dowolnymi znanymi zasobami, np. archiwami ftp. Adres robota pocztowego jest w formacie e-mail. Podczas wyszukiwania roboty pocztowe są zwykle wykorzystywane jedynie jako pośrednicy w pozyskiwaniu informacji. Czasami trzeba się zmierzyć z faktem, że są one jedynym sposobem na uzyskanie niezbędnych informacji.
Usenet i inne regionalne i wyspecjalizowane grupy dyskusyjne to elektroniczne „tablice ogłoszeń”, na których użytkownik umieszcza swoje informacje w jednej z tematycznych grup dyskusyjnych przesyłanych do subskrybentów danego tematu. Ten zasób jest najważniejszy dla szybkiego gromadzenia informacji, ale wąska kwestia, a przy wyszukiwaniu - częściej dla uzyskania prywatnych, nieoficjalnych informacji.
Zasoby dostępne przez telnet w niektórych przypadkach stanowią całkowicie unikatowe informacje, przede wszystkim w katalogach bibliotecznych uniwersytetów europejskich i amerykańskich, a także agencji rządowych.
Jak już wspomniano, system archiwum plików ftp posiada dość obszerny zasób cennych informacji, które nie zostały jeszcze przetłumaczone na WWW. Archiwa ftp to przede wszystkim źródła pozyskiwania oprogramowania. Przeszukiwanie ich może być interesujące, jeśli znasz strukturę archiwów; budowanie systemów plików, nazw plików i katalogów zawierających wymagane zasoby.
2.2 Metody wyszukiwania informacji w Internecie
Wyszukiwanie niezbędnych informacji w Internecie można wykonać na różne sposoby:
Szukaj w wyszukiwarkach według słowa kluczowego
Szukaj za pomocą klasyfikatorów wyszukiwarek
Katalogi i kolekcje linków (pojęcia bardziej ogólne)
Konferencje, czaty
· Strony linków („Linki”) w serwisach tematycznych (rzadkie, specjalistyczne elementy)
Metody niesieciowe (porady przyjaciół, znajomych; reklama w mediach drukowanych)
Na początku wyszukiwania informacji konieczne jest określenie jej rodzaju. Konwencjonalnie można wyróżnić 4 rodzaje informacji.
1 typ - generał (np. historia Imperium Rosyjskiego),
Typ 2 - mniej ogólny (np. cesarz Aleksander II),
Typ 3 - specyficzny (na przykład: reformy Aleksandra II),
Typ 4 jest bardziej szczegółowy (na przykład: zniesienie pańszczyzny).
Ścieżki wyszukiwania są również określane w zależności od rodzaju informacji.
Informacje typu 1 są wyszukiwane za pomocą klasyfikatorów wyszukiwarek (z rosyjskiego - zaleca się Yandex www.Yandex.ru). Jeśli strony z wymaganymi informacjami nie zostaną od razu znalezione, należy przejrzeć katalogi i strony linków („Linki”) znalezionych przez klasyfikator, które znajdują się na stronach o podobnej tematyce. Te witryny są wymienione w klasyfikatorze według tematu i znalezionych katalogów.
Informacje typu 2 są przeszukiwane podobnie do wyszukiwania typu 1, ale z korzyścią przeszukiwania katalogów i stron linków.
Informacje 3 typów - według słów kluczowych, które są wpisywane w pasku wyszukiwania wyszukiwarek, katalogów, stron linków
Informacje 4 typów - zgodnie ze szczegółowymi danymi wprowadzonymi do paska wyszukiwania. Dane są wyszukiwane zgodnie z metodami wyszukiwania przedstawionymi dla typów 2 i 3.
Szukaj według typu 1. Wymagane informacje: „Historia Imperium Rosyjskiego”.
Idziemy do Yandex - Nauka i edukacja / Nauki społeczne / Historia. Zgodnie z opisem tematu znajdujemy witrynę http://rus-hist.on.ufanet.ru .. Jeśli nie zawiera niezbędnych informacji, przejdź do strony linków tej witryny. Zawiera linki do katalogów zasobów: www.history.ru, http://www.lants.tellur.ru/history/index.htm. W nich najprawdopodobniej znajdą się strony na dany temat.
Szukaj według typu 2. Wymagane informacje: „Cesarz Aleksander II”.
Wyszukiwanie przebiega podobnie jak poprzednie, ale więcej uwagi poświęca się pracy z katalogami www.history.ru, http://www.lants.tellur.ru/history/index.htm.
Szukaj według typu 3. Wymagane informacje: „Reformy Aleksandra II”
Oto nowy sposób wyszukiwania - według słów kluczowych. Piszemy w linii wyszukiwania Yandex „Reformy Aleksandra II”. Wynik do obejrzenia - 1790 stron, które znajdują się na 170 serwisach, które zawierają katalogi. Aby zawęzić informacje, możesz dodać nowe słowa kluczowe - dodatkowe fakty w już znalezionym wyborze witryn, na przykład: „1860-1870”. itd. W innych wyszukiwarkach wpisuje się całe „Reformy Aleksandra II w latach 1860-1870”. Aby wyszukać określone informacje, możesz również skorzystać z „Linków”, które znajdują się na znalezionych stronach
2.3 Rozwój zasobu informacyjnego
Podobnie jak inne technologie informacyjne, Internet tworzą programiści, ale w tym przypadku to głównie twórcy zasobów (począwszy od specjalistów obsługujących sprzęt i oprogramowanie, projektantów, artystów, redaktorów, a przede wszystkim autorów zasobów informacyjnych) . Oczywiście tworzenie zasobów nie jest celem samym w sobie, zasoby są poszukiwane przez użytkowników sieci, czyli przez tych samych specjalistów i konsumentów zasobów, wśród których, jak już wspomniano, pojawia się nowa warstwa - specjaliści od dataminingu, od informacji Szukaj. Zasoby informacyjne Internetu, a także inne, w tym nieelektroniczne zasoby informacyjne (w szczególności środki masowego przekazu), charakteryzują się pewnymi stanami ich aktywności (rys. 9.3).
Zasób powstaje zgodnie z potrzebami społeczeństwa i jego możliwościami (w szczególności związanymi z poziomem stanu technicznego i społecznego społeczeństwa).
W miarę możliwości dochodzi do „dojrzewania”, powstawania zasobu (lub jego zaniku przy braku zapotrzebowania, czyli zaniku, być może nie w sensie fizycznym – miejsce może istnieć, czyli w sensie bycia cieszący się popytem).
Przy pewnym poziomie zapotrzebowania i (włączając w to starania autorów strony) jest on katalogowany, to znaczy informacje o zasobie pojawiają się w różnych katalogach odpowiadających rodzajowi zasobu.
Indeksowanie, czyli pojawienie się zasobu w indeksach wyszukiwarek, ma miejsce, gdy osiągnięta zostanie określona ilość treści i jest ona potrzebna.
Jeśli popyt stale rośnie, zasób stale się rozwija, w przeciwnym razie zasób wymiera i stopniowo znika z indeksów i katalogów.
2.4 Wymagania dotyczące narzędzi wyszukiwania
Jak wspomniano wcześniej, nieodłącznymi cechami profesjonalnego wyszukiwania są jego kompletność, niezawodność i duża szybkość. Najpoważniejszym i nietrywialnym czynnikiem decydującym o szybkości osiągnięcia celu poszukiwań jest zaplanowanie postępowania poszukiwawczego. Wymaga to z jednej strony wyboru rodzaju zasobów, które są potencjalnie zdolne do przenoszenia informacji istotnych dla zadania wyszukiwania, a z drugiej strony doboru narzędzi wyszukiwania obsługujących odpowiednie pole informacyjne, w zależności od ich oczekiwanej wydajności. . Jeśli mówimy o najbardziej pojemnej na dzień dzisiejszy, z punktu widzenia zawartości informacji, przestrzeni WWW, to względna obfitość jej możliwości wyszukiwania sprawia, że rozwiązywanie większości praktycznych problemów jest wielowymiarowe. Skonstruowanie optymalnej sekwencji do wykorzystania określonych narzędzi na każdym etapie wyszukiwania i z góry określa jego skuteczność. Jasne zrozumienie rodzajów, celu i cech pracy systemów wyszukiwania informacji (ISS) w Internecie może pomóc w rozwiązaniu problemu wyboru.
Prawdziwymi nośnikami informacji o zasobach, jakimi dysponuje Internet, są wyszukiwarki i katalogi. Systemy wyszukiwania informacji w Internecie różnią się, ale zasadą selekcji informacji, które w takim czy innym stopniu są obecne w programie skanującym wyszukiwarki, oraz w działaniach specjalistów wykonujących katalogowanie. Z reguły wyróżnia się dwa główne wskaźniki: skalę przestrzenną systemu oraz jego specjalizację.
Podczas tworzenia tablicy informacyjnej wyszukiwarka może śledzić aktualizację określonego zestawu dokumentów, katalogów lub skończonej liczby węzłów wybranych według jakiejś zasady. Takie systemy, wdrażane w Internecie, można nieco warunkowo nazwać lokalnymi i. Wyszukiwarki globalne, w przeciwieństwie do lokalnych, rozwiązują bardziej pracochłonne zadanie - jak najpełniejsze pokrycie zasobów całego pola informacyjnego Internetu (WWW lub innego), któremu służą. Konsekwencją tego jest rosnąca rola mechanizmu wykorzystywanego przez taki system do ciągłego zwiększania liczby przeglądanych stron.
Budowa regionalnych i specjalistycznych usług wyszukiwania zakłada aktywne filtrowanie informacji. Specjalizacja wyszukiwarki na podstawie dowolnego profilu LUB tematu, czy to prawnego, poszukiwania osobowości czy plików multimedialnych w formacie MP3, może mieć miejsce zarówno w skali globalnej, jak i lokalnej. Oczywiście system jest łatwiejszy do zbudowania i utrzymania w ograniczonej przestrzeni aktualizowanych witryn, co zwykle jest wdrażane w praktyce.
Regionalne usługi wyszukiwania filtrują informacje głównie według nazwy domeny najwyższego poziomu serwera, na przykład według dla Białorusi, ru - dla Rosji. Poważną wadą takich systemów jest brak rozliczania dużej liczby zasobów publikowanych przez regionalnych autorów zasobów bezpośrednio w domenie com.
W globalnych usługach wyszukiwania często występuje uwzględnienie specyfiki regionalnej. Na przykład system Lycos szereguje odpowiedzi według regionu żądania.
Internetowi ze swej natury towarzyszy chaos informacyjny. I tylko nowoczesne środki automatycznego indeksowania dokumentów są w stanie, biorąc pod uwagę zastosowane algorytmy i możliwości środków technicznych, znaleźć w tym chaosie racjonalne ziarno. Korzystanie z zasobów podczas wyszukiwania zasobów bez wyszukiwania według słów kluczowych przypomina surfowanie, a nie poważną pracę z informacjami.
2.6 Globalne wyszukiwarki WWW
Po zapoznaniu się z kilkoma globalnymi wyszukiwarkami użytkownik z reguły zatrzymuje się na jednej lub dwóch, z którymi woli pracować w przyszłości. Jednocześnie wybór usługi wyszukiwania często odbywa się w sposób całkowicie arbitralny, nie na podstawie analizy rzeczywistych możliwości systemów, ale ich popularności. Jednym z największych i najpopularniejszych jest AltaVista. System AltaVista posiada elastyczny język zapytań, który jednak wymaga specjalnego przestudiowania. AltaVista posiada wielojęzyczną obsługę indeksu wyszukiwania oraz możliwość tłumaczenia on-line (czyli bezpośrednio podczas sesji) tekstu strony internetowej z popularnych języków europejskich na angielski.
Innym znanym systemem jest NorthernLight, który ma dość standardowy zestaw funkcji. System dodatkowo umożliwia pracę z unikalnym zbiorem linków (ponad 6 tys.), głównie do artykułów z czasopism. Obsługa indeksowania cyrylicy (w tym języka rosyjskiego) sprawia, że wraz z AltaVista, jest dobrym dodatkiem do regionalnych rosyjskich wyszukiwarek Rambler, Yndex i Aport do wyszukiwania w języku rosyjskim.
Wyszukiwanie i zbieranie informacji w Internecie wymaga planowania. Błędna logika budowania zapytania, niezoptymalizowana kolejność korzystania z wyszukiwarek, próby przyspieszenia wyszukiwania – wszystko to nie tylko opóźnia uzyskanie wyniku, ale może narazić na szwank sens wyszukiwania.
Zastanówmy się nad kilkoma ważnymi punktami związanymi z planowaniem i pierwszymi krokami takiej pracy.
Należy zacząć od kompleksowej analizy leksykalnej wymaganych informacji. Do uzyskania podstawowych informacji należy wykorzystać każdy, wystarczająco rzetelny i szczegółowy opis badanego zagadnienia. Takim źródłem może być zarówno wysoce specjalistyczna książka informacyjna, jak i elektroniczna encyklopedia o ogólnym profilu. Na podstawie badanego materiału konieczne jest uformowanie jak najszerszego zestawu słów kluczowych w postaci odrębnych terminów, fraz, słownictwa fachowego, slangu, słów klisz i stabilnych stempli słownych, w razie potrzeby w kilku językach. Ewentualne doprecyzowanie zapytania należy ustalić z góry - rzadkie słowa, synonimy i antonimy. imiona i nazwiska ściśle związane z żądanym pytaniem. Pożądane jest również wcześniejsze przewidywanie możliwych nieistotnych odpowiedzi na zapytania, to jest możliwych charakterystyk szumu wyszukiwania. Po zgromadzeniu tych wstępnych danych możesz przystąpić do pozyskiwania podstawowych informacji z Internetu.
Głównym zadaniem tego etapu jest uwzględnienie specyfiki Internetu, który jest nie tylko nośnikiem technologii, ale także tradycji i własnej etyki. Słownictwo sieciowe, slang i pisownia popularnych słów mogą się tutaj różnić od przyjętych.
Informacji o dostępności niezbędnych danych najlepiej poszukać w Internecie w znanym wcześniej katalogu obsługującym wyszukiwanie słów kluczowych. Przy rozwiązywaniu np. prostych zadań, takich jak „Pobierz tekst Konstytucji Republiki Białoruś” lub „W których aktach prawnych użyto nazwy miasta rodzinnego”, szybciej można skorzystać ze znanej strony lub katalogu uzyskiwania informacji niż automatyczny indeks i zapewni większą wiarygodność.
Po leksykalnej analizie informacji rozpoczyna się etap technologiczny. Wybór pola informacyjnego Internetu i narzędzi wyszukiwania opiera się na powyższych podejściach.
Wykorzystywane są zapytania testowe z jednego lub dwóch słów kluczowych lub fraz, następnie analizowana jest odpowiedź ilościowa. Analiza treści danych pozwala dostosować zapytania, ale trafność odpowiedzi. W wyniku testów identyfikowane są najbardziej reprezentatywne źródła informacji, po czym należy doprecyzować kolejność korzystania z narzędzi wyszukiwania. Na tym kończy się faza planowania.
Podsumowując, zauważamy, że w rozwiązaniu problemu zbierania informacji z Internetu znaczącą rolę odgrywają regionalne i specjalistyczne usługi wyszukiwania. Wykorzystanie indeksów globalnych nie do bezpośredniego wyszukiwania potrzebnych informacji, ale do lokalizacji tych narzędzi wyszukiwania, często pozwala skrócić czas potrzebny na rozwiązanie danego problemu wyszukiwania.
WNIOSEK
Biorąc to wszystko pod uwagę, można jednym słowem określić istotę Internetu: jest to komunikacja, komunikacja między jednostkami i całymi narodami bez ingerencji władz państwowych. Ta nowa technologia zmienia oblicze cywilizacji z ogromną prędkością, radykalnie zmieniając rozumienie świata i samej ludzkości. Internet pochłonął już dziesiątki milionów ludzi, ponad sto krajów, całkowicie zmienił procesy rozpowszechniania i odbioru informacji. W dobie technologii informatycznych wirtualna rzeczywistość Internet przyczyniająca się do wymazywania granic państwowych, zmniejszania odległości geograficznych, niwelowania barier międzykulturowych , staje się nie mniej oczywisty niż otaczający nas świat materialny.
Wraz z rozwojem INTERNETU stało się możliwe szybkie i wygodne wyszukiwanie potrzebnych informacji dokumentacyjnych. Teraz nie musisz zajmować się selekcją i studiowaniem ogromnej ilości literatury w księgarniach i bibliotekach. Informacje można uzyskać bez wychodzenia z domu lub biura. W tym celu wystarczy komputer podłączony bezpośrednio do INTERNETU z zainstalowanym specjalnym programem - przeglądarką przeznaczoną do przeglądania zawartości stron WWW.
Dzięki różnorodności wyszukiwarek specjalnie zaprojektowanych dla przeciętnego użytkownika, każdy może łatwo odciąć oczywiście niepotrzebny przepływ informacji, tylko poprzez prawidłowe sformułowanie celu wyszukiwania.
WYKAZ UŻYWANEJ LITERATURY
1. Grinberg A.S., Kashinsky Yu.I., Slavin B.S. Wprowadzenie do informatyki prawnej. Mińsk: NO OOO BIP-S, 2002.S. 303.
2. Gusiew W.S. Google: Szukaj skutecznie. Skrócona instrukcja obsługi. M., 2006.
3. Informatyka dla prawników i ekonomistów / Redakcja S. V. Simonovich. SPb.: Piotr, 2001.
4. Informatyka. Kurs podstawowy. Podręcznik dla uniwersytetów, Petersburg, 2001
5. Technologie komputerowe w działalności prawnej / pod redakcją profesora N. Polevoya. M .: Wydawnictwo BEK, 1994.
6. Ogórki MM Prawo informacyjne. - M.M .: Prawnik, 1999.-321s.
7. Encyklopedia Internetu, Petersburg, 2001
8. Porównanie przeglądarek // http://www.microsoft.com
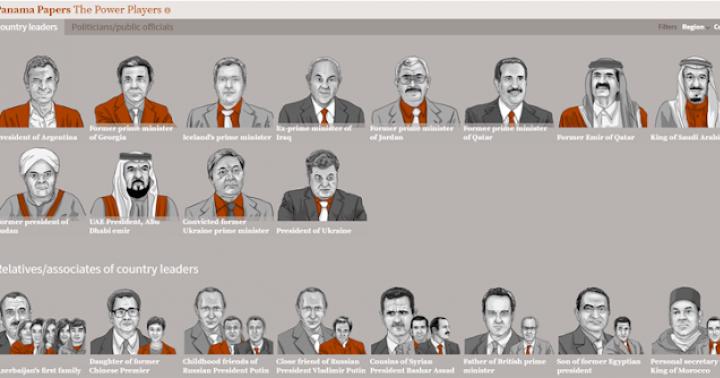
Od tamtej pory nie minęło wiele czasu, a Międzynarodowe Konsorcjum Dziennikarstwa Śledczego – ICIJ, na podstawie tych dokumentów, przygotowało nowy, okazały „prezent” dla skorumpowanych polityków. Wyciek tajnych dokumentów pokazał, jak prezydenci dużych i małych mocarstw, ich krewni i współpracownicy są zaangażowani w ukrywanie dochodów w strefach offshore.
Wyciek największej firmy z Panamy ujawnia korupcję światowych liderów
Dokumenty zawierają nazwiska 72 obecnych i byłych przywódców państw, w tym przywódców oskarżonych o grabież ich krajów. Lista ta zawiera nazwiska prezydenta Ukrainy Petra Poroszenki, króla Arabii Saudyjskiej, prezydenta Federacji Rosyjskiej Putina i jego bliskich przyjaciół Baszara al-Assada oraz przywódcy narodu Azerbejdżanu Ilhama Alijewa. 
Dyrektor ICIJ Gerard Ryle powiedział, że „wyciek byłby najcięższym uderzeniem w morzu, jakie kiedykolwiek podjęto”. Najwyraźniej ktoś naprawdę potężny i kompetentny, zadawszy cios w biznes offshore, wypowiedział wojnę z korupcją, ukrywaniem dochodów i praniem brudnych pieniędzy na skalę globalną.
Dlaczego wokół Panama Papers jest takie zamieszanie?
Przypomnę drogi czytelniku, że ten blog nie jest o polityce, ale o informacji i jej wyszukiwaniu w Internecie. W tym przypadku te rzeczy są oczywiście ze sobą powiązane. Ale ten artykuł ma na celu jedynie podkreślenie niezwykłego wydarzenia od strony informacyjnej. Podczas gdy wokół PanamaLeaks panuje hałas i piana, postaramy się przeanalizować to wydarzenie i jego konsekwencje.
Należy powiedzieć, że wycofanie środków na offshore, jako sposób na uniknięcie opodatkowania w twoim kraju, nie jest przestępstwem. Tak - brzydkie, tak - nie patriotyczne, ale nie zbrodnia. W tych krajach, w których jest to dozwolone. Zgadza się, ale jeśli chodzi o biznesmenów lub aktorów, tak jak w przypadku piłkarza Lionela Messiego lub aktora kaskaderskiego Jackie Chana.
(zaktualizowany)
W przypadku znalezienia informacji o interesującym podmiocie gospodarczym, możesz włączyć automatyczne monitorowanie zmian w rejestrach, które dotyczą tej firmy lub przedsiębiorcy. Zaktualizowane informacje zostaną wysłane na Twój e-mail. Deweloperzy usług nie ukrywają swoich planów dotyczących rozwoju projektu. Planowane jest dodanie informacji analitycznych: artykułów w mediach, reputacji podmiotów gospodarczych na podstawie informacji zwrotnych od partnerów biznesowych, analizy finansowej, prawdopodobieństwa upadłości itp.
Oczywiście minęło jeszcze zbyt mało czasu, aby wyciągnąć jakiekolwiek wnioski na temat pracy wyszukiwarki. Być może będzie więcej problemów. Przewiduję na przykład sprzeczności związane z pojęciem tajemnic handlowych. Ogólnie zobaczymy, jak projekt będzie się rozwijał i życzymy powodzenia w przedsięwzięciu!
Powiązane linki:
youcontrol.com.ua na VKontakte vk.com/public91977868
na Facebooku www.facebook.com/youcontrol.com.ua
E-mail [e-mail chroniony]
Tel. +38 066 189 02 06
No i jak zwykle filmik, do którego komentarze są absolutnie niepotrzebne.
Jak zauważa źródło, udostępniane przez niego informacje to tylko swego rodzaju próbna część. Rzeczywista ilość danych, którymi dysponują dziennikarze, jest znacznie większa. Tym samym słowa przedstawicieli konsorcjum dziennikarskiego, że cichy świat spółek offshore czeka na prawdziwe „trzęsienie ziemi” wydają się całkiem prawdopodobne. 

Całkiem niedawno francuscy programiści zaprezentowali internautom nową wyszukiwarkę Qwant (qwant.com). Sami Francuzi nazywają swoją wyszukiwarkę rewolucyjną. Według współzałożyciela, Qwant jest systemem zarówno holistycznym, jak i bezstronnym. Oferuje informacje bez określania preferencji wyszukiwania.
Rozwój Qwant trwa już od dwóch lat. Jak przyznają twórcy, głównym celem nowej wyszukiwarki jest wyprzedzenie i wyprzedzenie największej wyszukiwarki Google. Tak więc witryna qwant.com została uruchomiona 13 lutego 2013 r. Ten system jest obecnie testowany i jest dostępny w 35 krajach w 15 językach.
Wśród funkcji nowego wyszukiwania znajduje się rozkład znalezionych wyników według kategorii. Możesz więc znaleźć informacje w sieciach społecznościowych - jest to kolumna Społeczności lub na przykład przewijać dane z kanału informacyjnego (Live). Kolumna Internet wyświetla najpopularniejsze artykuły dla Twojego zapytania, a kolumna Zakupy wyświetla informacje handlowe o żądanym produkcie.
Na samym środku strony znajduje się kolumna Graf wiedzy - możesz tam uzyskać krótki opis zapytania - co to jest, gdzie jest stosowane itp. - podobnie jak opis w słowniku objaśniającym. Ponadto Qwant oferuje na żądanie wyjście obrazu i wideo. Istnieje również duża różnica w porównaniu z Google, Yandex i innymi wyszukiwarkami, w których musisz przejść do specjalnej karty, aby wyświetlić obrazy dla zapytania wyszukiwania.
Qwant można nazwać jedną z najbardziej przyjaznych dla użytkownika wyszukiwarek. Oferuje dużą liczbę ustawień dla wygodniejszego wyświetlania danych. Kolumny kategorii spraw można zmieniać poprzez ich położenie między sobą. Na przykład, jeśli interesuje Cię przede wszystkim wiersz newsów, możesz przesunąć go w lewo, aby jako pierwszy przykuwał uwagę, a listę z informacjami handlowymi przesunąć maksymalnie w prawo.
Zróbmy małe testy wyszukiwarki. Powiedzmy, że interesuje nas twórczość Moniki Bellucci. Otwieramy stronę startową qwant.com, która swoją drogą jest bardzo podobna do Google. Wpisujemy w wierszu „Monica Bellucci” i widzimy, co następuje: na samym górze oferujemy nam film i zdjęcie tej słynnej aktorki, podczas gdy wyniki medialne można przewijać u góry za pomocą strzałki, bez przechodzenia do zakładka ze zdjęciami. 
W kolumnie Web widzimy linki do kilku najbardziej odpowiednich witryn, które zawierają informacje o Bellucci - Wikipedia, KinoPoisk itp. W kolumnie Na żywo - wiadomości o aktorce (ostatnie wywiady, sesje zdjęciowe itp.), w Social Możesz zobaczyć recenzje Moniki Bellucci z sieci społecznościowych, ale w Zakupach widzimy listę stron, w których możesz kupić filmy z Moniką.
Jak widać, system ma na celu udzielanie odpowiedzi na każde żądanie użytkownika, nie narzucając użytkownikowi wyników, ale oferując je w kilku kategoriach do wyboru. Sami twórcy Qwant potwierdzają, że główny nacisk położono na usprawnienie wyszukiwania informacji w popularnych sieciach społecznościowych.

Oczywiście technologie chmurowe są płatne, ponieważ korzystasz z serwerów firm trzecich. Ale taka usługa ma wiele zalet, w szczególności:
Klient powinien płacić tylko za ilość miejsca w pamięci, z której faktycznie korzysta, a nie za wynajem serwera;
- klient nie musi kupować, utrzymywać i utrzymywać własnego sprzętu do przechowywania danych, co znacznie obniża koszty produkcji;
- wszelkie kwestie techniczne dotyczące zachowania integralności zamieszczanych informacji oraz backupu danych są realizowane przez dostawcę, co nie wymaga udziału klienta w tym.
Dlaczego przechowywanie w chmurze jest tak atrakcyjne
Na pewno korzystałeś z udostępniania plików, których wciąż jest ogromna liczba. Tam możesz przesłać własny plik, który stanie się dostępny dla każdego użytkownika, który może znaleźć Twój plik według tagu lub nazwy. Natomiast technologia chmury zapewnia pełną prywatność. Oznacza to, że tylko właściciel informacji może korzystać z zamieszczonych danych i wchodzi do systemu ze swoją nazwą użytkownika i hasłem.
Zwykli użytkownicy zakochali się w takich technologiach, bo teraz nie ma już potrzeby zapychania komputera tonami starych informacji - na każdym komputerze zawsze można znaleźć kilka gigabajtów starej muzyki, która kiedyś może się jeszcze przydać, zbiór filmów, które były kilkakrotnie poprawiane, dokumenty, które zostały już wydrukowane i wykorzystane.
Niemniej jednak wszystkie te informacje muszą być gdzieś przechowywane. Usługi w chmurze oferują bezpośrednie oczyszczenie miejsca na komputerze, wysyłając wszystkie niepotrzebne dane do „chmury”. Wszystko, co musisz zrobić, to zapłacić pewną opłatę i mieć szybkie łącze internetowe.
Inną cechą przechowywania w chmurze jest to, że możesz uzyskać przechowywane dane w dowolnym momencie i z dowolnego urządzenia. Oznacza to, że jeśli wysłałeś film „do chmury” z komputera, możesz go zabrać z powrotem na komputer z laptopa, tabletu, smartfona ... Najważniejsze jest to, że masz hasło i logujesz się przy sobie.
Jaką pamięć masową w chmurze wybrać?
Istnieje ogromna liczba usług w chmurze, które stale się rozwijają, oferując nie tylko przestrzeń dyskową, ale także powiązane usługi. Poniżej znajdują się najpopularniejsze z nich.
1. Windows Live SkyDrive — oferuje najwięcej miejsca na serwerze. Zarejestrowani użytkownicy mogą bezpłatnie przechowywać do 25 GB własnych informacji w chmurze. Dokumenty biurowe przesłane do chmury można edytować i otwierać bezpośrednio w przeglądarce. Synchronizację można przeprowadzić z kilku urządzeń komputerowych jednocześnie.
2. DropBox jest bardzo dobrze znaną usługą wśród zwykłych użytkowników, ale oferuje tylko 2 GB miejsca dla każdego ze swoich klientów. Jeśli korzystasz z płatnego konta, możesz rozszerzyć swoje możliwości nawet do 20 GB.

Graph Search (dalej GS) to nazwa aktualizacji Facebooka (FB) ogłoszonej niedawno przez Zuckerberga, która dodatkowo „uspołecznia” pierwszą sieć społecznościową na świecie. Wersja beta nowej usługi została uruchomiona na razie tylko w anglojęzycznym segmencie Facebooka. Wyszukiwanie „know-how” stanie się później dostępne dla rosyjskojęzycznych użytkowników sieci społecznościowej, ale możesz teraz dodać swoje konto do „listy oczekujących”.
Technicznie rzecz biorąc, GS to system filtrów, który wykorzystuje algorytm wyszukiwania Bing w sieci społecznościowej i umożliwia wyszukiwanie osób, interesujących miejsc, muzyki (w przyszłej aktualizacji), zdjęć, które są odpowiednie dla Twoich zainteresowań na Facebooku. Dla użytkownika społecznościowego Graph Search będzie wyglądać jak pasek wyszukiwania u góry dowolnej strony FB.
Po wpisaniu zapytania w wierszu wyszukiwania GS, wynik wyszukiwania jest gromadzony na osobnej stronie opatrzonej nazwą zapytania (na przykład: „Moi znajomi w Rio”). Planowane jest wyszukiwanie według „polubień”, komentarzy, treści medialnych, oznaczeń zdjęć. Data kolejnej aktualizacji inteligentnej usługi wciąż nie jest znana.
Wyszukiwanie wykresów na Facebooku — jak to działa?
Rozwój rozpoczął się od stwierdzenia: dla użytkownika rekomendacja znajomego jest ważniejsza niż szacunki tysięcy nieznanych osób. Tak więc, korzystając z funkcji Graph Search, możesz znaleźć na przykład:
Zdjęcia kolegów studentów sprzed 1995 roku;
- miłośnicy squasha z Twojego miasta;
- zdjęcia znajomych z Indonezji;
- ulubione wielkomiejskie bary sushi znajomych;
-zabytki Pragi lub Paryża odwiedzane przez znajomych.
Powód do niepokoju lub fałszywy alarm?
Pierwsze informacje o Graph Search wzbudziły pewne obawy użytkowników FB. Tak, inteligentna usługa jest bardzo atrakcyjna pod względem możliwości wyszukiwania, ale wiele osób obawia się korzystania z wyszukiwania społecznościowego przez firmy marketingowe, służby specjalne, grupy przestępcze, agencje rządowe i pozbawionych skrupułów właścicieli serwisów internetowych do zbierania informacji. Czy obawy są uzasadnione?
Z jednej strony Graph Search nie zmienia ustawień prywatności, dlatego tylko użytkownicy FB, dla których są otwarci, mogą „rozdawać” prywatne dane. Z drugiej strony korporacje transkontynentalne, rządowe intranety, a nawet banki cierpią z powodu „wycieków informacji”. Czy Facebook jest bezpieczny pod względem bezpieczeństwa? Czas pokaże.
Badania marketingowe odnoszą się do systematycznego gromadzenia, wyświetlania i analizy danych dotyczących różnych aspektów działań marketingowych.
Badania marketingowe to funkcja, która poprzez informację łączy marketerów z rynkami, konsumentami, konkurentami, ze wszystkimi elementami zewnętrznego otoczenia marketingowego.
Informacja pierwotna to informacja, którą badacz samodzielnie otrzymuje specjalnie w celu rozwiązania problemu badań marketingowych.
Do zebrania informacji o preferencjach konsumentów i preferencjach wykwalifikowanych specjalistów w zakresie metod zbierania, źródeł informacji w Internecie wykorzystano metodę ankietową.
Badanie polega na zbieraniu podstawowych informacji poprzez bezpośrednie zadawanie respondentom pytań o ich poziom wiedzy, stosunek do produktu, preferencje i zachowania zakupowe.
W zależności od rodzaju respondentów dobierano ankietę z udziałem kategorii populacji, której aktywność zawodowa nie jest związana z przedmiotem analizy.
Przeprowadzono badania marketingowe w celu zidentyfikowania cech wyszukiwania i wykorzystania informacji w Internecie. Grupą docelową tego badania jest populacja Republiki Białorusi w wieku poniżej 18 lat i starsza. Zbieranie danych odbywa się w mieście Homel.
Do określenia wymaganej liczebności próby wykorzystano następujący wzór:
gdzie n jest wielkością próbki;
z - odchylenie znormalizowane, wyznaczone na podstawie wybranego poziomu ufności;
p jest znalezioną zmiennością próbki;
e jest poprawnym błędem.
W związku z tym ilość zmienności jest równa osobie.
Wszelkie badania marketingowe zaczynają się od zdefiniowania problemu. Tak więc w naszych badaniach problem wymagający badań zostanie sformułowany w następujący sposób: „Jak konsumenci myślą o korzystaniu i wyszukiwaniu informacji w Internecie?
Pytania wyszukiwania wyjaśniają poszczególne składniki problemu, z których każdy z kolei może zostać rozbity na składniki - pytania wyszukiwania. Pytania wyszukiwania określają zakres konkretnych informacji, które będą wymagane do rozwiązania problemu badawczego. Tak więc pytania wyszukiwania w naszym badaniu mogą być następujące: 1. Kto jest użytkownikiem wyszukiwarek ”: jaka jest płeć, wiek, poziom dochodów, status społeczny. 2. Jaką wyszukiwarkę wybierają użytkownicy? 3. Jakie strony użytkownicy odwiedzają najczęściej? 4. W jakim celu użytkownicy korzystają z Internetu? 5. Jakie informacje są najciekawsze w Internecie? Na podstawie pytań wyszukiwania można sformułować hipotezy: 1. Użytkownicy wybierają wyszukiwarkę Google 2. Najczęściej użytkownikami wyszukiwarek jest populacja w wieku 19-25 lat 3. Użytkownicy najczęściej odwiedzają serwisy rozrywkowe 4. Większość użytkowników korzysta z Internet do komunikacji 5. Dla użytkowników najciekawsze są informacje o rozrywce i rekreacji 6. Większość użytkowników znajduje potrzebne informacje 7. Użytkownicy częściej korzystają z Internetu w domu
W okresie wrzesień – listopad 2011 przeprowadzono badanie marketingowe, podczas którego przeprowadzono wywiady ze 150 mieszkańcami miasta Homel. Respondenci zostali poproszeni o wypełnienie ankiety składającej się z 17 pytań. Okres badania wynosi 12 tygodni, biorąc pod uwagę przygotowanie ankiety i przetwarzanie uzyskanych danych.
W celu określenia preferencji konsumentów opracowano ankietę (ZAŁĄCZNIK A).
W procesie badań marketingowych, przeprowadzając wywiady z respondentami, wyodrębniono następujące grupy wiekowe konsumentów (wykres 3.1).

Rysunek 3.1 – Schemat rozkładu respondentów według wieku
Jak widać na wykresie 3.1, według kryterium wieku, duży udział w korzystaniu z wyszukiwarek mają respondenci w wieku 19-25 lat, który wynosi 35%. Obywatele w wieku 56 lat i starsi stanowili 3% w ujęciu procentowym. Grupę docelową pod względem obszaru działania przedstawia rysunek 3.2.

Rysunek 3.2 – Schemat rozkładu respondentów według statusu społecznego
Analizując odpowiedzi respondentów możemy stwierdzić, że znaczna część użytkowników wyszukiwarek to pracownicy (36%) i pracownicy (30%). Na kolejnych miejscach plasują się studenci (17%) i przedsiębiorcy (15%), z niewielką różnicą.
Uzyskane dane o poziomie dochodów ludności przedstawiono na wykresie 3.3.

Figa. 3,3
Wykres 3.3 pokazuje, że większa liczba ankietowanych ma średni poziom dochodów, który mieści się w przedziale od 1 000 000 do 2 000 000 rubli, co wynosiło 65,3%. Respondenci o niskich dochodach stanowili 26,3%, ao wysokich 8%.

Figa. 3.4
Rysunek 3.4 pokazuje, że liczba typów i nazw wyszukiwarki jest bardzo duża. Najpopularniejszymi systemami są Google -45%, następnie Mail.ru, następnie Yandex-20% i Rambler-10% na ostatnim miejscu. ogólnie rzecz biorąc, zaobserwowano dużą różnicę w preferencjach konsumentów Google, Mail.ru, Yandex i Rambler.

Figa. 3,5
Rysunek 3.5 pokazuje, że strony odwiedzane częściej niż inne to strony rozrywkowe – 35%, następnie informacyjne – 33%, następnie korporacyjne – 25% i kolejne – 7%

Figa. 3,6
Z wykresu wynika, że większość ankietowanych korzysta z wyszukiwarek - 90,2%

Figa. 3,7
Zgodnie z wynikami badania okazało się, że dla 61% respondentów wyszukiwarka jest wygodnym środkiem komunikacji, dla 34% jest to prosty i skuteczny sposób wyszukiwania informacji, a dla 5% coś innego. Strukturę odpowiedzi wyraźnie pokazuje rysunek 3.7.

Figa. 3,8
Badanie to dostarczyło informacji o częstotliwości korzystania z Internetu, gdzie konsumenci odwiedzający internet codziennie stanowili 74%, 3-4 razy w tygodniu – 16% i 3-4 razy w miesiącu-10 Struktura odpowiedzi jest wyraźnie pokazano na rysunku 3.8

Figa. 3,9
Jak widać na wykresie 3.9, większość respondentów korzysta z internetu w domu (75%), 16% w pracy, 5% podczas wizyty i 4% w kafejce internetowej.
Figa. 3.10
Wykres 3.10 pokazuje, że respondenci najczęściej wykorzystują Internet do komunikacji (48%), a także do wyszukiwania informacji (26%), przeglądania wiadomości (19%) i poczty (7%).

Figa. 3.11
Zgodnie z wynikami badania, okazało się, że 44% respondentów jest najbardziej zainteresowanych informacjami o rekreacji i rozrywce 44%, Internecie 42%, biznesie 31%, komputerach 29%, społeczeństwie 27%, nauce i edukacji 25 %, kultura i sztuka 20%, medycyna i zdrowie 19%, dom i rodzina 18%. Strukturę odpowiedzi wyraźnie pokazuje rysunek 3.11.

Figa. 3.12 - Schemat rozkładu respondentów odpowiadając na pytanie: „Czy uda Ci się znaleźć potrzebne informacje w Internecie?”,%
Wykres 3.12 pokazuje, że większa liczba ankietowanych zawsze znajduje informacje, których szuka – 52%, następnie często -33%, rzadko -12%, nigdy 3%.
Tym samym w trakcie badania ujawniły się następujące preferencje konsumentów: większość respondentów preferuje wyszukiwarkę taką jak Google, podczas gdy korzystanie z Mail.ru nie ma między nimi dużej luki (5,%).
35% próby najczęściej odwiedza strony z rozrywką, 58% konsumentów odwiedza internet codziennie, ale jak wykazała analiza, odwiedziny rosną z dnia na dzień. Przewiduje się prognozę przyszłego wzrostu. Dlatego twórcy wyszukiwarek muszą:
Ulepszanie algorytmów wyszukiwania (lub opracowywanie nowych strategii wyszukiwania) i powiązanych „dzwonków i gwizdków”, takich jak projektowanie i usługi dodatkowe;
Zapewnienie analizy zapytań (pytań) stawianych w języku naturalnym;
Wyszukiwarki indeksują zewnętrzne pliki CSS;
Zwiększ rozmiar dokumentu lub rozmiar części, która będzie indeksowana
Parser To program do automatyzacji procesu parsowania, czyli przetwarzania informacji zgodnie z określonym algorytmem. W tym artykule podam kilka przykładów programów parserów oraz opiszę w skrócie ich przeznaczenie i główne funkcje.
Parser treści X-Parsera
Główne funkcje programu również składają się z kilku bloków programu.
- Parseruj dowolne wyszukiwarki pod kątem kluczowych zapytań
- Zawartość parsera z dowolnej witryny
- Parser treści dla kluczowych zapytań z wyników dowolnej wyszukiwarki
- Parser zawartości listy adresów URL
- Parser linków wewnętrznych
- Parser linków zewnętrznych
Program WebParser
Parser WebParser to wszechstronny program. którego główną funkcją jest parsowanie wyszukiwarek. Współpracuje z PS Google, Yandex, Rambler, Yahoo i kilkoma innymi. analizuje silniki witryn (CMS). Kompatybilny ze wszystkimi wersjami Windows począwszy od W2000. Bolle pełne informacje.
WP Uniparser Wtyczka
Nie zapominajmy i wtyczka do WordPressa WP Uniparserpar... Możesz dowiedzieć się więcej na ten temat, klikając ten link.
Parser „Magadan”
Parser słów kluczowych o romantycznej nazwie „Magadan” został stworzony specjalnie do ukierunkowanego przetwarzania słów kluczowych Yandex.Direct. Przydaje się do kompilowania rdzenia semantycznego, przygotowywania kampanii reklamowych oraz zbierania i analizowania informacji.
Na koniec warto wspomnieć język programowania do tworzenia stron Parser, stworzony w studiu Artemy Lebedev i służący do rozwoju witryn. Język ten będzie nieco bardziej złożony niż zwykły HTML, ale nie wymaga tak dużego przygotowania jak np. PHP.
WPROWADZENIEInternet jest jak ogromna światowa biblioteka, która ma tylko jedną, ale istotną różnicę: aby szukać książki w bibliotece jest katalog, w skrajnych przypadkach można zwrócić się do doświadczonego bibliotekarza. Nie ma pełnego katalogu Internetu. Niemniej jednak wyszukiwanie w globalnej sieci komputerowej jest możliwe i jest to być może jeden z najważniejszych jego aspektów. Do wyszukiwania danych w sieci wykorzystywane są specjalne serwery, o których informacje są utrzymywane i aktualizowane niemal automatycznie.
Dziś, gdy internet stał się jednym z głównych źródeł informacji, wyszukiwanie w internecie nabiera coraz większej wartości praktycznej. Jednak wraz z szybkim wzrostem ilości dostępnych danych sama procedura wyszukiwania staje się coraz bardziej skomplikowana.
Internet to globalna sieć komputerowa, która łączy zarówno użytkowników sieci komputerowych, jak i użytkowników komputerów PC. Internet powoli, ale nieuchronnie staje się głównym środkiem komunikacji korporacyjnej, ustępując dotychczas miejsca telefonowi.
W sieci jest ogromna ilość zasobów informacyjnych. Według niektórych szacunków liczba dokumentów przekroczyła 65 milionów i nadal szybko rośnie. Taka ilość informacji wymaga prawidłowej organizacji procesu wyszukiwania i użycia specjalnych środków technicznych, takich jak wyszukiwarki. Proste wyszukiwanie dość powszechnego słowa kluczowego daje zwykle od kilkudziesięciu tysięcy do kilku milionów linków. Oczywistym jest, że praca z tak dużą liczbą dokumentów jest praktycznie niemożliwa, zwłaszcza że w przeważającej większości zawierają one informacje nieistotne.
Źródła informacji w Internecie różnią się sposobem prezentacji informacji, a co za tym idzie sposobem dostępu do nich.
1 NARZĘDZIA WYSZUKIWANIA
1.1 Narzędzia wyszukiwania plików
Ręczne odnalezienie pliku w złożonej strukturze katalogów serwera FTP może zająć dużo czasu. Aby uprościć i przyspieszyć wyszukiwanie, opracowano usługę wyszukiwania internetowego Archie, która jest specjalnym serwerem Archie, który przechowuje zawartość katalogów anonimowych serwerów ftp. Podczas adresowania zapytania wyszukiwania na serwerze Archie wynikiem wyszukiwania jest lista adresów anonimowych serwerów FTP, które mają żądany plik.
Pojawia się jednak zadanie znalezienia pożądanego wśród zestawu plików na tym serwerze, co jest dość trudne ze względu na niejasne i niezrozumiałe nazwy plików i katalogów. Do rozwiązania tego problemu wykorzystywany jest system Gopher, który pozwala na poruszanie się po systemie menu kontekstowych, pokazujących zawartość plików za pomocą zrozumiałych notacji. Istnieje wiele serwerów Gopher, które zawierają archiwa danych w postaci katalogów o strukturze hierarchicznej, uporządkowanych według zawartości. Praca z nimi jest bardzo prosta i odpowiada pracy z normalnym wyświetlaczem systemu plików.
Istnieje rozszerzenie tego systemu - Veronica, które zawiera w swojej bazie katalogi wszystkich serwerów Gopher. Po wprowadzeniu zapytania wyszukiwania Veronica automatycznie skanuje wszystkie katalogi Gopher w poszukiwaniu informacji, których szukasz, eliminując w ten sposób potrzebę ręcznego przeszukiwania wielu serwerów Gopher.
Dzięki temu sposobowi nawigacji Gopher był w pewnym stopniu poprzednikiem WWW. Obecnie wykorzystanie Gopher maleje proporcjonalnie do wzrostu wykorzystania WWW.
1.2 Narzędzia WWW - WorldWideWeb
W 1993 roku opracowano system wyszukiwania informacji WWW, który ze względu na łatwość nawigacji i dostępność otwierał źródła informacji w Internecie dla nieprzygotowanych użytkowników. WWW spowodowało boom internetowy, który trwa do dziś, a ilość informacji dostępnych w Internecie podwaja się z roku na rok.
WWW opiera się na zasadzie hipertekstu (znanego już czytelnikowi), czyli na systemie dokumentów połączonych hiperłączami. Hipertekst to specjalny sposób wyróżniania słów kluczowych ze zwykłego tekstu. Łącza hipertekstowe odsyłają użytkownika do innych dokumentów na tym samym serwerze lub do innych serwerów, które mogą znajdować się w dowolnym miejscu w Internecie. Jeśli ten dokument tekstowy jest również hipertekstem, jego linki pozwalają przejść dalej do odpowiednich dokumentów. Każde przekierowanie następuje niepostrzeżenie dla użytkownika, dzięki czemu może on w sensowny sposób przeglądać strukturę informacji w Internecie, nie martwiąc się o adresowanie konkretnych komputerów.
Wraz z rozwojem aplikacji multimedialnych, początkowo dokumenty czysto hipertekstowe w coraz większym stopniu stają się hipermediami. Dokumenty WWW mogą więc istnieć w dowolnym formacie danych: tekstowym, graficznym, dźwiękowym/muzycznym lub wideoklipem. Orientacja i nawigacja w sieci WWW odbywa się za pomocą specjalnych programów zwanych przeglądarkami WWW, które zapewniają interfejs użytkownika, takich jak NetscapeNavigator lub MicrosoftInternetExplorer.
Punktem wyjścia do wyszukiwania informacji jest z reguły główna (bazowa, główna) strona (witryna) zasobu informacyjnego, do którego można się dostać, wpisując odpowiedni adres w przeglądarce (na przykład http: //ncpi .gov.by lub www.iparegistr.com). Strony WWW są tworzone i aktualizowane przez firmy lub specjalne organizacje, które publikują informacje i monitorują zawartość swoich stron WWW. Korzystanie z WWW nie jest zatem pasywne, a każdy internauta za pomocą specjalnych programów do edycji hipertekstu może samodzielnie tworzyć własne interaktywne strony WWW. To utorowało drogę do rosnącej komercjalizacji i ekspansji Internetu.
Obecnie nowo tworzone informacje z reguły są tworzone z uwzględnieniem konieczności zapewnienia dostępu przez WWW, a wcześniejsze dokumenty są dla nich stopniowo konwertowane, ale na całym świecie wciąż istnieją miliony plików w formach innych niż wymagania WWW. W celu korzystania z tych informacji oraz za pośrednictwem WWW, powyższe usługi internetowe zawarte są w przeglądarkach zapewniających do nich dostęp (telnet, ftp, Archie, Gopher). Za pośrednictwem WWW można również korzystać z innych serwisów internetowych przeznaczonych do komunikacji (eMail, NetNews). Dlatego przeglądarka WWW stała się obecnie uniwersalnym programem komunikacyjnym dla Internetu.
Wraz z pojawieniem się serwisu WWW rozpoczął się boom internetowy. To łatwe w użyciu, przyjazne dla użytkownika środowisko dla wszystkich usług przyciągnęło zainteresowanie wielu osób i organizacji w Internecie. Nagle okazało się, że nie trzeba być ekspertem od Internetu, aby korzystać z usług sieci. Można to porównać do sukcesu firmy Microsoft w udostępnianiu systemu Microsoft Windows jako graficznego interfejsu użytkownika. Przed Windows każda aplikacja DOS miała swój własny podręcznik użytkownika i dlatego wymagała osobnego przestudiowania każdej aplikacji.
2 PODSTAWOWE METODY WYSZUKIWANIA INFORMACJI W INTERNECIE
2.1 Podstawowe wymagania dotyczące wyszukiwania
Na wyniki wyszukiwania nakładane są wymagania dotyczące kompletności pokrycia zasobów, wiarygodności otrzymanych informacji, minimalnego nakładu czasu i maksymalnej szybkości wyszukiwania.
Wymóg kompletności pokrycia zasobów nie wymaga dodatkowych wyjaśnień, z wyjątkiem konieczności wykorzystania zasobów nie tylko dla WWW, ale także dla innych usług internetowych podczas wyszukiwania.
Wiarygodność informacji, biorąc pod uwagę specyfikę Internetu, staje się niezwykle ważnym wymogiem. Ocenę rzetelności można przeprowadzić zarówno metodami tradycyjnymi (sprawdzenie legalności publikacji na papierze, uzyskanie informacji o organizacjach i autorach, sprawdzenie aktualności ich zasobów elektronicznych itp.), jak i z wykorzystaniem możliwości Internetu (zapoznanie z alternatywnymi źródłami informacji, uzgodnienie materiału faktycznego, ustalenie częstotliwości jego wykorzystania przez inne źródła, poznanie statusu dokumentu i oceny źródła za pomocą wyszukiwarek, uzyskanie informacji o kompetencjach i statusie autora materiału za pomocą specjalnych usług wyszukiwania w Internecie, analiza poszczególnych elementów organizacji strony w celu oceny kwalifikacji wspierających ją specjalistów i nie tylko).
Czas wyszukiwania, nie licząc czasu spędzonego na specyfikacji połączenia, jest w dużej mierze zależny od planowania wyszukiwania i umiejętności specjalisty wyszukiwania w zakresie wybranego typu zasobów. Planowanie wyszukiwania polega na określeniu usług wyszukiwania wymaganych do rozwiązania żądania wyszukiwania oraz kolejności ich stosowania. Ponadto wiele zależy od umiejętności i doświadczenia konkretnego specjalisty ds. wyszukiwania.
Jak już wspomniano, informacje w Internecie są dostępne z różnego rodzaju źródeł. Przede wszystkim są to zasoby WWW (system hipertekstowy, katalogi zasobów, wyszukiwarki). Ponadto jest już znany czytelnikowi poczty e-mail, robotów pocztowych, Usenetu i innych grup dyskusyjnych, a także systemów ftp i archiwów (przy użyciu Gopher i Veronica). WWW umożliwia wyszukiwanie wymaganych zasobów w oparciu o swoje hiperwłaściwości, czyli istniejące wyszukiwarki działają z wykorzystaniem hiperłączy w trybie automatycznym, nie wykluczając możliwości ręcznego przeglądania. WWW oferuje szereg ogólnych i specjalistycznych usług wyszukiwania.