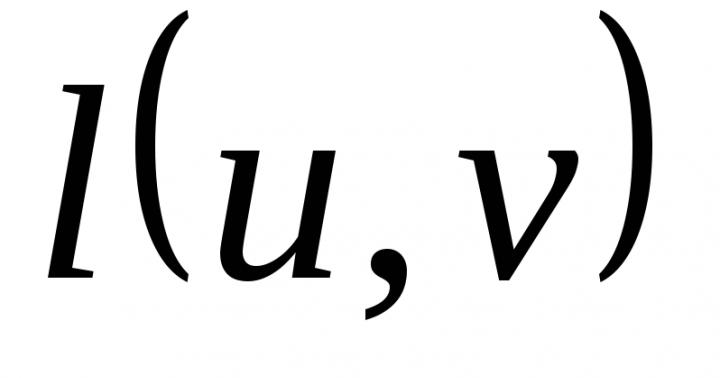هنگام حل وظایف بینایی کامپیوتر، بدون استفاده از نرم افزار تخصصی انجام نمی شود. من می خواهم به شما این را معرفی کنم - OpenCV - یک کتابخانه منبع باز در C ++. این مجموعه ای از ابزارهایی برای دیجیتالی کردن تصاویر، پردازش بعدی را از طریق الگوریتم های عددی یا عصبی پردازش می کند.
الگوریتم های پردازش تصویر پایه: تفسیر تصاویر، کالیبراسیون دوربین از طریق استاندارد، حذف اعوجاج نوری، تعریف شباهت، تجزیه و تحلیل حرکت جسم، تعریف شکل جسم و ردیابی شی، بازسازی 3D، تقسیم بندی شی، تشخیص ژست .
شما می توانید کتابخانه را در وب سایت رسمی دانلود کنید http://sourceforge.net/projects/opencvlibrary/
ساختار کتابخانه OpenCV
cxcore - هسته
* شامل ساختارهای داده های پایه و الگوریتم ها:
- عملیات اساسی در آرایه های عددی چند بعدی
- جبر ماتریکس، FS ریاضی، ژنراتورهای تصادفی
- ضبط / بازگرداندن ساختارهای داده به / از XML
- توابع اساسی گرافیک 2D
CV - تصویر ماژول پردازش تصویر و کامپیوتر
- عملیات اساسی در تصاویر (فیلتراسیون، تحولات هندسی، تبدیل فضاهای رنگی و غیره)
- تجزیه و تحلیل تصاویر (انتخاب ویژگی های متمایز، مورفولوژی، جستجو برای خطوط، هیستوگرام)
- تجزیه و تحلیل حرکت، ردیابی اشیاء
- تشخیص اشیاء، به ویژه افراد
- کالیبراسیون دوربین، عناصر بازسازی ساختار فضایی
Highgui - ماژول برای ورود / خروجی تصاویر و ویدئو، ایجاد یک رابط کاربر
- ضبط ویدئو از دوربین ها و از فایل های ویدئویی، خواندن / نوشتن تصاویر استاتیک.
- توابع سازماندهی یک UI ساده (تمام برنامه های آزمایشی از HighGui)
CVAUX - توابع تجربی و قدیمی
- فضاها چشم انداز: کالیبراسیون استریو، کالیبراسیون خود
- جستجوی استریو را جستجو کنید، در نمودار کلیک کنید
- پیدا کردن و ویژگی های توصیف
CVCAM - ضبط ویدئو
- به شما اجازه می دهد تا ویدیو را از دوربین های ویدئویی دیجیتال ضبط کنید (پشتیبانی متوقف می شود و در آخرین نسخه ها این ماژول گم شده است)

OpenCV را تحت لینوکس نصب کنید
پس از دانلود آخرین نسخه opencv از سایت توسعهدهنده http://sourceforge.net/projects/opencvlibrary/ شما باید بایگانی را باز کنید و مجمع را از طریق CMAKE نسخه 2.6 یا بالاتر ببرید.
نصب CMAKE استاندارد است:
sudo apt-get نصب CMAKE
برای نمایش ویندوز OpenCV، شما باید کتابخانه های GTK + 2.X و LIBGTK2.0-DEV را نصب کنید.
apt-get install libgtk2.0-dev
ما کتابخانه را جمع آوری می کنیم:
tar -xjf opencv-2.2.0.tar.bz2 cd opencv-2.2.0 cmake -d cmake_build_type \u003d release -d cmake_install_prefix \u003d / usr / local. نصب را نصب کنید
برای تست کتابخانه نصب شده، می توانید نمونه ها را جمع آوری کنید و چیزی را اجرا کنید:
نمونه های سی دی / c / chmod + x build_all.sh ./build_all.sh ./delaunay
اگر خطای خطا را در هنگام بارگیری کتابخانه های به اشتراک گذاشته به جای یک عکس تست مشاهده کنید: libopencv_core.so.2.2: آیا نمی توان فایل شیء مشترک را باز کرد: چنین فایل یا دایرکتوری "، این بدان معنی است که این برنامه نمی تواند کتابخانه ها را پیدا کند. شما باید به صراحت مسیر را برای آنها مشخص کنید:
$ صادرات ld_library_path \u003d / usr / local / lib: $ ld_library_path
اگر بعد از آن یک خطا:
ERROR OPENCV: خطای نامشخص (تابع اجرا نشده است. بازسازی کتابخانه با ویندوز، GTK + 2.X یا پشتیبانی کربن. اگر شما در اوبونتو یا دبیان هستید، libgtk2.0-dev و pkg-config را نصب کنید، سپس دوباره اجرا کنید cmake یا پیکربندی اسکریپت) در cvnamedwindow، file /usr/src/opencv-2.2.0/modules/highgui/src/window.cpp، خط 274 خاتمه نامیده می شود پس از پرتاب یک نمونه از "CV :: Exception" چه (): / usr /src/opencv-2.2.0/modules/highgui/src/window.cppp: خطا: (-2) تابع اجرا نمی شود. بازسازی کتابخانه با ویندوز، GTK + 2.X یا پشتیبانی کربن. اگر شما در اوبونتو یا دبیان هستید، libgtk2.0-dev و pkg-config را نصب کنید، سپس CMAKE را دوباره اجرا کنید یا پیکربندی اسکریپت را در تابع cvnamedwindow نصب کنید
بنابراین شما GTK + 2.x را فراموش کرده اید: libgtk2.0-dev. تنظیم را اجرا کنید (نگاه کنید به بالا).
هنگامی که نصب فایل های هدر تکمیل شده در دایرکتوری / usr / local / include / opencv در دسترس خواهد بود و فایل های کتابخانه ای در / usr / local / lib هستند
ما برنامه را با OpenCV جمع آوری می کنیم:
test.cpp
// // برای تست // // robocraft.ru // #include
makefile
CC: \u003d G ++ CFLAGS: \u003d -I / USR / محلی / شامل / opencv -l / usr / محلی / lib اشیاء: \u003d کتابخانه ها: \u003d -lopencv_core -lopencv_imgproc -lopencv_highgui .phony: همه پاک کردن همه: تست تست: $ (CC) $ (cflags) -o test test.cpp $ (کتابخانه ها) تمیز: RM -F * .o
راه اندازی مونتاژ فرماندهی

سلام دنیا!
OpenCV نصب شده و آماده کار است. اولین برنامه Hello Word خود را خوش آمدید!
#عبارتند از. 
بارگیری یک تصویر
این مثال پایه ای از تمام برنامه های شما در OpenCV خواهد بود. ما تصویر را از فایل image0.jpg در روز چهارشنبه دانلود خواهیم کرد.
#عبارتند از. 
انواع فرمت های تصویر پشتیبانی شده:
- ویندوز Bitmaps - BMP، DIB
- فایل های JPEG - JPEG، JPG، JPE
- گرافیک شبکه قابل حمل - PNG
- فرمت تصویر قابل حمل - PBM، PGM، PPM
- خورشید Rasters - SR، RAS
- فایل های TIFF - TIFF، TIF
برای تجدید نظر به تصویر شما می توانید چنین تماس هایی را انجام دهید:
Image-\u003e NCHANNELS // تعداد کانال های کانال (RGB، اگر چه در OpenCV - BGR) (1-4) Image-\u003e عمق // عمق در بیت Image-\u003e عرض // عرض عرض در پیکسل عکس-\u003e ارتفاع // عکس های ارتفاع در پیکسل های تصویر-\u003e Imagesize // عکس برگه حافظه (\u003d\u003d Image-\u003e ارتفاع * Image-\u003e WidthStep) Image-\u003e Widthstep // فاصله بین تصاویر عمودی عمودی مجاور (تعداد بایت ها در یک خط از تصویر - ممکن است برای خود دور زدن تمام تصاویر پیکسل مورد نیاز باشد)
بارگیری ویدئو
بارگذاری ویدئو بسیار پیچیده تر از بارگذاری تصویر به استثنای است که یک چرخه ای وجود دارد که از طریق فریم ها می رود.
تاخیر بین فریم ها در 33 میلی ثانیه تنظیم شده است. چنین تاخیری به شما امکان می دهد جریان ویدئو را با فرکانس استاندارد 30 فریم در ثانیه پردازش کنید.
#عبارتند از.
برای ضبط ویدئو از دوربین، شما نیاز به یک کد کمی تغییر دهید - به جای عملکرد CVCreatEFileCapture () CVCreateCamerAcapture استفاده می شود (). هنگامی که شما ESC را فشار می دهید، پخش را قطع می کند و پنجره را بسته می کند، و هنگامی که Enter را فشار می دهید، قاب فعلی ذخیره خواهد شد فایل jpg.
#عبارتند از.
opencv v1.0 نشان می دهد و یک تصویر از حداقل رزولوشن دوربین 320x240 را ذخیره می کند.

شناخت اشیاء شیء
برای تشخیص مناطق بر روی تصویر منبع در قالب یک تابع cvmatchtemplate () وجود دارد. این تابع قالب تصویر را به تصویر فعلی اعمال می کند و با توجه به الگوریتم انتخاب شده، جستجو برای همبستگی بین آنها را انجام می دهد. تعریف مرزهای قالب یافت شده بر روی تصویر منبع توسط تابع CVMINMAXLOC انجام می شود و الگوریتم جستجو Cvnormalize () را عادی می کند.
// // مثال CvmatchTemplate () // تصویر مقایسه با قالب // #include 
هی قبل از من، این وظیفه این بود که تشخیص علائم جاده ای از جریان ویدئو را درک کنیم. از آنجایی که من قبلا به وظایف این نوع نرسیده بودم، فرآیند تحقق به خودی خود به معنای "سیگار کشیدن" طولانی مدت از انجمن ها و خیانت بی رحمانه از نمونه های دیگران است. بنابراین، من تصمیم گرفتم همه چیز را در یک مکان برای نسل های آینده، و همچنین در طول داستان، جمع آوری کنم، چند سوال را تنظیم کنید.
مقدمه
بنابراین، پس از مطالعه همه ی ابزار که ممکن است برای پیاده سازی این کار استفاده شود، من در محیط توسعه مایکروسافت ویژوال © 2010 توسعه، با استفاده از کتابخانه OpenCV فوق العاده متوقف شدم.
فرایند کار با OpenCV نشان می دهد رقص های اولیه با یک تامورین، که به اندازه کافی شرح داده شده است:
دومین عمل رقص با یک تامورین.
در نهایت، به جهت آبشارهای آموزشی تبدیل شد. "Hapure" در این جهت متوجه شد که من به دو ابزار Createsampes و Harartaining نیاز دارم. اما آنها غایب نبودند و آنها غایب بودند و آنها حاضر به کامپایل شدند. در آن زمان، نسخه OpenCV 2.4.4 بود، پیکربندی شده توسط، در مقاله، من برای اولین بار در مورد استفاده از CMAKE هنگام نصب خوانده ام. در نتیجه، من تصمیم گرفتم نسخه 2.3.1 را دانلود کنم و کتابخانه را دوباره نصب کنم. پس از آن، من توانستم ابزار لازم را اجرا کنم خط فرمان و این سوال چگونه با آنها کار می کرد. همه اشاره به "و" مقالات را نشان می دهد پارامترهایی که شما نیاز به اجرای Createsampes و HarTraining با شرح مفصلی از این پارامترها را نشان می دهد.
کد از ورق خالص
در نهایت، از روش قدیمی رد شد، کد برای جایگزینی آبشارهای آموزش دیده بازنویسی شد.
کد 2.0
#include "stdafx.h" #include
چهارشنبه پیکربندی همانند پروژه گذشته.
تکرار - پدران ورزش.
مورد برای "کوچک" برای قطار آبشار.)
این جالب ترین را شروع می کند. پس از آن، من تصمیم گرفتم در مورد تمام این Solarms در Habr بنویسم و \u200b\u200bاز مشاوره بخواهم.
من 500 عکس را در اندازه 1600x1200 آماده کردم. و یک تصویر با اندازه 80x80. یک تصویر کافی خواهد بود، زیرا ما یک شی خاص را تشخیص می دهیم، و نه انواع مختلفی از افراد.
بنابراین، هنگام تهیه تصاویر و ایجاد یک فایل neg.dat با ساختار
منفی / n (1) .jpg منفی / n (2) .jpg منفی / n (3) .jpg منفی / n (4) .jpg ... منفی / n (500) .jpg
فایل opencv_createsamples.exe را از طریق CMD با پارامترهای زیر اجرا کنید
c: opencv2.3.1buildcommonx86opencv_createsamples.exe -vec c: opencv2.3.1buildcommonx86pepluitive.vect -bg c: opencv2.3.1buildcommonx86neg.dat -img c: opencv2.3.1buildcommonx86ustupi.jpg -Num 500 -W 50 -H 50 -BColor 0 -BGThresh 0 -Show.
پارامتر -Show تصاویر مثبت ایجاد شده را نشان می دهد، اما آنها در مقایسه با کسانی که در مقالات دیگر مشخص شده اند.
تصاویر، این کار را می کند
کم اهمیت

به این معناست که این ابزار یک تصویر BG را برای اندازه یک تصویر مثبت کاهش می دهد. تغییر پارامترها -W و -H نتایج نمی دهند و پس زمینه عقب هنوز تقریبا قابل مشاهده نیست. اگر ناگهان کسی می داند چه چیزی مهم است، ملاحظات را به اشتراک بگذارند. اندازه تصاویر منفی به 800x600 کاهش یافته است - نتیجه یکسان است.
c: opencv2.3.1buildcommonx86opencv_haartraining.exe -data c: opencv2.3.1buildcommonx86haarustupi -vec c: opencv2.3.1buildcommonx86positive.vect -bg c: opencv2.3.1buildcommonx86neg.dat -npos -npos -nsng 500 500 6 -nspages -nsplits 2 -w -ns 20 -H 24 -MEM 1536 -Mode همه -Nonsym -Minhitrate 0.999 -Maxfalsealarm 0.5
پس از آن شما یک فایل XML طولانی مدت را دریافت خواهید کرد که می توانید آن را بارگیری کنید منبع برنامه ها.
به عنوان یک نتیجه، آبشار کمی یادگیری و، با بسیاری از مثبت کاذب، واکنش نشان می دهد، که من را دوست داشت، من به نشانه علامت می روم.
اما من نمی توانم به ترمات های دقیق دست یابم، به نظر من، به نظر می رسد، به دلیل این واقعیت است که پس زمینه پشتی در تصاویر مثبت بریده شده است. و این تصاویر را مانند کتابچه راهنمای کار نمی کند. اما هنوز یک گزینه برای افزایش تعداد مراحل آموزشی وجود دارد و بارگیری کامپیوتر شما را برای تمام روز، صبر کنید تا آبشار بیشتر "تحصیل کرده" باشد. آنچه که من قصد دارم قبل از ظهور ایده های دیگر انجام دهم.
عظمت
این اولین مقاله Hellohabr- با من است. در انتظار نظرات شما در مورد سبک مواد. و البته نکات در مورد موضوع.
من امیدوارم پس از برنامه های دریافت شده چه چیزی برای ادامه داستان ادامه خواهد داد.
ایده اصلی این است که ارتباطات آماری بین ترتیب نقاط آنتروپومتریک فرد را به حساب آورید. در هر تصویر از چهره نقطه به همان ترتیب شماره گذاری می شود. توسط مکان متقابل خود، افراد مقایسه می شوند.
برای مقایسه، افراد می توانند از همان موقعیت چهره نسبت به دوربین استفاده کنند. بیشتر برای این ترجیح داده شده است.
ضبط جریان ویدئو با دوربین و انتخاب

#عبارتند از.
فایل های آبشار در دایرکتوری C: \\ opencv \\ build \\ ... ... Cascade دلخواه در دایرکتوری پروژه واقع شده است، جایی که و فایل اصلی منبع اصلی.
انتخاب نکات ویژه صورت
این برنامه بر اساس کد C ++ برای OpenCV FaceMark است

#عبارتند از.
در پروژه برنامه، کجا و فایل main.cpp، فایل های قرار داده شده haarcascade_frontalface_alt2.xml, drawlandmarks.hpp. و lbfmodel.yaml کدام لینک در کد است؟ فایل های آبشار در C: \\ opencv \\ build \\ ... files \\ ... واقع شده اند drawlandmarks.hpp. و lbfmodel.yaml در فایل facemark_lbf.rar وجود دارد.
پس از قرار دادن کد، خطاها به دلیل این واقعیت ظاهر شد که در OpenCV 3.4.3-VC14-VC15 تعداد زیادی از کتابخانه ها برای شروع برنامه وجود ندارد. کتابخانه آن را تکمیل کرد (دانلود opencv_new.zip) و آن را در ریشه دیسک C نصب کرد (C: \\ opencv-new).

در حال حاضر، تمام تنظیمات اجرا شده باید برای OpenCV-NEW انجام شود:
تنظیمات را در ویندوز انجام دهید. من به "تغییر محیط متغیر محیط" (Windows-\u003e Utilities-\u003e کنترل پنل -\u003e سیستم و امنیت -\u003e سیستم -\u003e گزینه های اضافی سیستم ها -\u003e متغیرهای چهارشنبه -\u003e PATH -\u003e ویرایش). در این پنجره من یک متغیر ایجاد می کنم c: \\ opencv-new.\\ x64 \\ vc14 \\ bin. راه اندازی مجدد ویندوز.
در خواص پروژه همچنین به کتابخانه opencv_new مراجعه کنید (به جای opencv). در پنجره "صفحات اموال" اقدامات انجام می شود:
- C / C ++ -\u003e GENERAL -\u003e اضافی شامل دایرکتوری ها -\u003e C: opencv-new.\\ عبارتند از.
- لینکر -\u003e عمومی -\u003e دایرکتوری های کتابخانه های اضافی -\u003e C: opencv-new.\\ x64 \\ vc14 \\ lib
- لینکر -\u003e ورودی -\u003e وابستگی های اضافی -\u003e opencv_core400.lib؛ opencv_face400.Lib؛ opencv_videooio400.lib؛ opencv_objdetect400.lib؛ opencv_imgproc400.lib؛ opencv_highgui400.lib
هنگام شروع، برنامه اگر در نصب پروژه های اشکالزدایی یک خطا را نشان می دهد. برای آزادی، شروع به موفقیت.

انتخاب ویژگی های فیلتر کردن تصاویر و تشخیص چهره
چارچوب نقطه ای از چهره به روش های مختلف بسته به عوامل هدفمند و ذهنی نمایش داده می شود.
عوامل عینی - موقعیت چهره نسبت به دوربین.

عوامل ذهنی - روشنایی ناهموار یا ضعیف، اعوجاج چهره به دلیل احساسات، یکپارچگی چشم و غیره در این موارد، چارچوب نقطه ممکن است نادرست باشد، ممکن است نقاط حتی ممکن است از طرف:

با تایپ ویدیو، چنین تصاویر گاهی اوقات پرش. آنها نیاز به فیلتر کردن دارند - هر دو هنگام یادگیری و تشخیص.
برخی از نقاط پایدار ترین و آموزنده هستند. آنها به شدت به چهره گره خورده اند، صرف نظر از موقعیت آن نسبت به دوربین. علاوه بر این، آنها به خوبی مشخص شده توسط مشخصه چهره. این نکات را می توان به عنوان پایه ای برای مدل سازی علائم استفاده کرد.

برای مقایسه، مردم می توانند از نقطه دوم نقطه ای از موقعیت چهره مشابه استفاده کنند. وضعیت مربوط به دوربین نسبت به دوربین بیشتر آموزنده است؟ بدیهی است، پیشانی. نه بیهوده در پزشکی قانونی عکس ها را در صورت و مشخصات. در حالی که با چهره مواجه می شود.
تمام نشانه ها (فاصله ها) باید بدون ابعاد (عادی)، به عنوان مثال، به اندازه ای (فاصله) ارتباط داشته باشد. من فرض می کنم که مناسب ترین اندازه برای این فاصله بین وسط نقاط زاویه ای چشم است. و چرا، به عنوان مثال، نه با نقاط زاویه ای خارجی از چشم، که در واقع در آرایه نشانه ها تعریف شده است؟ واقعیت این است که نقاط زاویه ای چشم در حال حرکت (نزدیک) در هنگام پاسخ به تغییر رنگ، بیان تعجب، چشمک زدن، و غیره فاصله بین وسط سطح چشم این نوسانات و بنابراین بیشتر ترجیحا.
چه نشانه ای به عنوان پایه ای در تقریب اول می گیرد؟ من فرض می کنم، فاصله از نقطه بالای بینی به نقطه پایین تر چانه. با توجه به عکس، این علامت می تواند به طور قابل توجهی برای افراد مختلف متفاوت باشد.

بنابراین، قبل از تشکیل نشانه ها برای یادگیری و مقایسه، شما باید فریم های نقطه ای از افرادی که توسط ضبط ویدئو دریافت شده فیلتر کنید، که به دلایل ذهنی یا عینی، تصویر صحیح پیشانی چهره (AFAs) ندارد.
ما فقط این فریم های نقطه ای را که در ویژگی های زیر عبور می کنند را ترک می کنیم:
- مستقیم، که از طریق نقاط افراطی چشم ها (خط چشم) عبور می کند، عمود بر خط مستقیم، که از طریق نقاط افراطی بینی (خط بینی) عبور می کند.
- خط چشم موازی با مستقیم است، که از طریق نقاط دهان (خط RTO) عبور می کند.
- تقارن نقاط فوق نسبت به خط بینی مشاهده می شود.
- نقاط گوشه ای از چشم (خارجی و داخلی) در یک خط مستقیم هستند.
یک نمونه از تصاویر پیشانی که در تمام زمینه ها منتقل می شود:

یک نمونه از تصاویری که فیلتر شده اند:

سعی کنید خود را برای تعیین اینکه چگونه از نشانه های تصویر عبور نمی کنید.
علائم چگونه فیلتر کردن و تشخیص چهره را ارائه می دهند؟ اساسا، آنها در شرایط تعیین فاصله بین نقاط، شرایط موازی و عمود بر اساس شرایط ساخته شده اند. وظیفه رسمی سازی چنین نشانه هایی در موضوع مورد توجه قرار گرفته است.
الگوریتم تشخیص چهره در نقاط 2D قاب
مختصات نقاط چارچوب چهره در ابتدا در سیستم مختصات قرار می گیرند، که به نقطه سمت چپ بالای پنجره متصل می شود. در همان زمان، محور Y هدایت می شود.
برای راحتی تعیین علائم، ما از سیستم مختصات سفارشی (PSK) استفاده می کنیم، محور x که از طریق بخش بین وسط چشم عبور می کند و محور Y عمود بر این بخش از طریق وسط آن به سمت بالا حرکت می کند . مختصات PSK (از -1 تا 1) نرمال شده است - با فاصله بین نقاط وسط چشم ارتباط دارد.

PSK راحتی و سادگی شناسایی علائم را فراهم می کند. به عنوان مثال، موقعیت چهره به سرعت توسط نشانه تقارن نقطه های مربوطه چشم نسبت به خط بینی تعیین می شود. این ویژگی توسط تصادف خط بینی با محور Y رسم شده است، I.E. x1 \u003d x2 \u003d 0، جایی که x1 و x2 مختصات نقاط بینی شدید (27 و 30) در کامپیوتر هستند.
پنجره SC را تعیین کنید
مختصات نقاط وسط چپ و راست (چپ و راست):
xl \u003d (x45 + x42) / 2؛ YL \u003d (Y45 + Y42) / 2؛ xr \u003d (x39 + x 36) / 2؛ yr \u003d (y39 + y 36) / 2؛

آغاز PSK:
x0 \u003d (xl + xr) / 2؛ y0 \u003d (yl + yr) / 2؛

فاصله بین میانگین چشم های چشم در امتداد محورهای X و Y:
dx \u003d xr - xl؛ dy \u003d yr - yl؛
فاصله واقعی L بین میانگین نقاط چشم (قضیه Pythagoreo):
l \u003d sqrt (DX ** 2 + DY ** 2)
زاویه های مثلثاتی از گوشه PSK:
از مختصات در پنجره پنجره به مختصات در PSK برویدبا استفاده از پارامترهای X0، Y0، L، SIN AL، COS AL:
x_user_0 \u003d 2 (x_window - x0) / l؛
y_user_0 \u003d - 2 (y_window - y0) / l؛
x_user \u003d x_user_0 * cos_al - y_user_0 * sin_al؛
y_user \u003d x_user_0 * sin_al + y_user_0 * cos_al؛
ما فیلتر کردن تصویر را اجرا می کنیم به طور مداوم علائم را بررسی کنید:
1. عمود بر خطوط بینی و چشم، و همچنین تقارن نقاط زاویه ای چشم. خط بینی توسط نقاط 27 و 30 تعریف شده است (نگاه کنید به شکل ب). هر دو ویژگی انجام می شود اگر مختصات این نقاط x1 \u003d x2 \u003d 0 (یعنی خط بینی با محور Y هماهنگ باشد) در PCC.
2. عبور موازی کردن خط چشم و دهان. خط دهان توسط نقاط 48 و 54 تعیین می شود (شکل B را ببینید). این ویژگی در صورتی که در PSK Y1-Y2 \u003d 0 انجام شود انجام می شود.
3. نشانه ای از تقارن نقاط زاویه ای دهان. خط دهان توسط نقاط 48 و 54 تعیین می شود (شکل B را ببینید). علامت x1 + x2 \u003d 0 انجام می شود
4. علامت "نقاط زاویه ای از چشم ها بر روی یک خط مستقیم". مستقیما توسط جفت نقاط تعیین می شود: (36 و 45)، و همچنین (39 و 42). از آنجا که آزمون در این ویژگی 1 در حال حاضر منتقل شده است، به اندازه کافی برای تعیین نشانه Y2-Y1 \u003d 0 در PSK تنها برای نقاط 36 و 39 کافی است.
بنابراین ممکن است هیچ برابری مطلق وجود نداشته باشد، بنابراین نشانه ها با مقدار کمی قابل قبول مقایسه می شوند.
برنامه مقایسه چهره یک علامت
به عنوان یک ویژگی، فاصله بین نقاط پل ها و چانه (نقاط نشانه های 27 و 8، نگاه کنید به شکل ب). علامت، نرمال شده، در نسبت PCT تعیین می شود: (Y1 - Y2) / L، جایی که L فاصله بین مراکز چشم است. هنگام آموزش یک برنامه، یک نشانه برای شخص خاص تعیین شده توسط تعداد مشخص شده در کنار فرد ردیابی (این قسمت از کد در برنامه نظر داده می شود). هنگام شناخت، مقدار ویژگی با علامت مشخص شده وارد شده به برنامه برای هر فرد مقایسه می شود. با یک نتیجه مثبت مقایسه، شناسه آن در کنار صورت ظاهر می شود.

این برنامه از طریق عکس که من 15 سال جوانتر هستم و حتی در آن زمان، با یک سبیل هستم، به رسمیت می شناسم. تفاوت در عکس ضروری است، نه هر کس مراقبت می کند. ولی برنامه کامپیوتری فریب نده

وظایف کنترل:
- با برنامه آشنا شوید
- ارزش مشخصه را برای چهره خود و چندین همکاران خود تعیین کنید.
- برنامه را برای شناسایی افراد (آن و همکاران) تست کنید.

#عبارتند از.
این مقاله یک مرور کلی از روش های جستجوی شی را در تصویر به ارمغان می آورد.
1. مقدمه
بسیاری از وظایف عملی از اتوماسیون کنترل در تولید به طراحی اتومبیل های روباتیک به طور مستقیم به وظیفه جستجو برای اشیاء در تصویر مرتبط هستند. برای حل آن، شما می توانید دو استراتژی مختلف را اعمال کنید که بستگی به شرایط تیراندازی دارد - مدل سازی پس زمینه و مدل سازی شیء.- مدل سازی پس زمینه - این رویکرد را می توان اعمال کرد اگر دوربین هنوز هم باشد، I.E. ما یک پس زمینه داریم که کمی تغییر می کند و بنابراین شما می توانید مدل خود را بسازید. تمام نقاط تصویر که به طور قابل توجهی از مدل پس زمینه منحرف می شوند، اشیاء پیش زمینه را در نظر می گیرند. به این ترتیب، شما می توانید وظایف تشخیص و تعمیر و نگهداری شی را حل کنید.
- شبیه سازی یک شی - این رویکرد به طور کلی بیشتر است، مورد استفاده در مواردی که پس زمینه به طور مداوم و به طور قابل توجهی تغییر می کند. بر خلاف پرونده قبلی، ما باید بدانیم که چه چیزی می خواهیم پیدا کنیم، به عنوان مثال لازم است یک مدل از یک شی را بسازید و سپس نقاط تصویر را برای انطباق با این مدل بررسی کنید.
2. بررسی روشها
در این بخش، ما لیستی از رویکردهایی را ارائه خواهیم داد که شما می توانید با موفقیت، به منظور افزایش پیچیدگی، کار خود را به موفقیت برسانید.- فیلترهای رنگی - اگر شی به طور قابل توجهی بر روی پس زمینه در رنگ مشخص شده باشد، می توانید فیلتر مربوطه را انتخاب کنید.
- انتخاب و تجزیه و تحلیل خطوط - اگر ما می دانیم که جسم شکل گرفته است، به عنوان مثال، یک دایره، پس شما می توانید یک دایره در تصویر جستجو کنید.
- نقشه برداری با قالب - ما یک تصویر از یک شی داریم، ما به دنبال تصویر دیگری از منطقه هستیم که با این تصویر از جسم همخوانی دارد.
- کار با نقاط خاص - در تصویر با شی به دنبال ویژگی ها (به عنوان مثال، زاویه)، که در حال تلاش برای مقایسه با چنین ویژگی های در تصویر دیگری است.
- روش های یادگیری ماشین - ما طبقه بندی را در تصاویر با یک شیء تدریس می کنیم، به نحوی ما تصویر را به قطعات تقسیم می کنیم، طبقه بندی هر بخش را برای حضور یک شی بررسی می کنیم.
3. فیلترهای رنگی
روش فیلتر رنگ را می توان در مواردی که جسم به طور قابل توجهی از پس زمینه بر روی رنگ و روشنایی متفاوت است، به طور یکنواخت استفاده می شود و تغییر نمی کند. جزئیات مربوط به روش فیلترهای رنگی را می توان در آن خواند.4. انتخاب و تجزیه و تحلیل خطوط
اگر جسم در پس زمینه در رنگ به طور قابل توجهی اختصاص داده نشده و / یا رنگ آمیزی پیچیده، استفاده از روش فیلتر رنگ نتایج خوب را ارائه نمی دهد. در این مورد، شما می توانید سعی کنید روش انتخاب و تجزیه و تحلیل خطوط را اعمال کنید. برای انجام این کار، مرزهای تصویر را برجسته می کنیم. مرزها مکان های تغییر شدید در روشنایی شیب هستند، آنها می توانند با استفاده از روش Canny پیدا شوند. بعد، ما می توانیم خطوط مرزی انتخاب شده را برای انطباق با سیراب های هندسی شیء بررسی کنیم، این را می توان با استفاده از روش تبدیل Hough انجام داد، به عنوان مثال، ما می توانیم در محدوده جستجو جستجو کنیم.


شکل 4:جستجو برای حلقه ها
این روش همچنین می تواند در ارتباط با فیلترهای رنگی استفاده شود. جزئیات مربوط به تخصیص و تجزیه و تحلیل خطوط را می توان در آن خواند. کد منبع از مثال با پایه محافل می تواند دانلود شود.
5. نقشه برداری با قالب
اگر تصویر دارای بسیاری از قطعات کوچک باشد، تجزیه و تحلیل کانتور ممکن است دشوار باشد. در این مورد، شما می توانید روش تطبیق الگو (تطبیق قالب) را اعمال کنید. این شامل موارد زیر است - ما یک عکس با یک جسم می گیریم (شکل 5) و ما به دنبال یک تصویر بزرگ از منطقه هماهنگ با تصویر جسم (FIG.6.7) هستیم. 
شکل 5: امکانات جستجو
6. کار با نقاط خاص
روش مقایسه با قالب شرح داده شده در بخش قبلی، به دنبال مسابقات دقیق نقاط الگوی با نقاط تصویر است. اگر تصویر ریشه یا مقیاس نسبت به پارامترهای الگو باشد، این روش به شدت کار می کند. برای غلبه بر این محدودیت ها، روش ها براساس اصطلاح به اصطلاح استفاده می شود. امتیازات ویژه، ما به آنها بیشتر نگاه خواهیم کرد. نقطه خاص (نقطه کلید) یک منطقه کوچک است که به طور قابل توجهی در تصویر برجسته شده است. روش های متعددی برای شناسایی چنین نقاط وجود دارد، ممکن است گوشه ها (آشکارساز هریس گوشه ای) یا لکه (لکه، قطره)، I.E. مناطق کوچک از همان روشنایی، یک مرز کاملا روشن در یک پس زمینه عمومی ایستاده است. برای یک نقطه خاص محاسبه شده به اصطلاح. توصیفگر - مشخصه یک نقطه خاص. توصیفگر بر اساس یک محله داده شده از یک نقطه خاص، به عنوان جهت شیب روشنایی بخش های مختلف این محله محاسبه می شود. روش های متعددی برای محاسبه توصیفگرها برای نقاط منحصر به فرد وجود دارد: SIFT، SUFF، ORB، و غیره باید اشاره کرد که برخی از روش های محاسبه توصیفگرها (به عنوان مثال، sift) و استفاده تجاری آنها محدود است. جزئیات در مورد نقاط خاص در تصاویر و روش های کار با آنها می توانید به یک سخنرانی گوش دهید. نقاط خاص را می توان برای جستجو برای یک شی در تصویر استفاده کرد. برای انجام این کار، ما باید یک تصویر از شی مورد نظر داشته باشیم و سپس مراحل زیر را انجام دهیم.- در تصویر با جسم ما به دنبال نکات خاص از جسم و محاسبه توصیفگرهای خود را.
- در تصویر تجزیه و تحلیل شده، ما همچنین نقاط خاصی را به فروش می رسانیم و توصیفگرها را برای آنها محاسبه می کنیم.
- توصیفگرها از نقاط خاص شی و توصیفگرهای نقاط خاص موجود در تصویر را مقایسه کنید.
- اگر تعداد کافی از مکاتبات پیدا شود، ما منطقه را با نقاط مربوطه علامت گذاری می کنیم.

شکل 8: آشکارساز شی برای نقاط خاص
کد منبع نمونه را می توان دانلود کرد.
7. روش های یادگیری ماشین
روش جستجوی شیء با مقایسه مجموعه ای از نقاط منحصر به فرد، نقاط ضعف خود را دارد، یکی از آنها توانایی تعمیم بد است. اگر ما یک کار را انجام دهیم، به عنوان مثال، انتخاب افراد در عکس، سپس با نقاط خاص، روش ما به دنبال یک عکس خاص خواهد بود. عکس هایی که نقاط خاصی برجسته شده بود، بقیه افراد بدتر می شوند، زیرا به احتمال زیاد به مجموعه های دیگر نقاط منحصر به فرد مربوط می شود. نتایج می تواند حتی بدتر شود اگر شما نمایش عکسبرداری را تغییر دهید. برای حل این مشکلات، ما در حال حاضر نیاز به روش های یادگیری ماشین و نه یک تصویر با جسم، بلکه کل کیت های آموزشی از صدها (و در برخی موارد - صدها هزار) از تصاویر مختلف با یک تصویر از یک شی در شرایط مختلف. استفاده از روش های یادگیری ماشین برای جستجو برای اشیاء در تصویر ما به بخش دوم این مقاله نگاه خواهیم کرد.ادبیات
- E.S. Borisov آشکارساز شی برای دوربین های ثابت.
- http: //syt/cv-backgr.html - E.S. Borisov پردازش ویدئو: اشیاء آشکارساز بر اساس فیلترهای رنگی.
- http: //syt/cv-detector-color.html - E.S. Borisov روش های پردازش تصویر اولیه تصویر.
- http: //syt/cv-base.html - Anton Konusin Computer Vision (2011). سخنرانی 3. روش های تجزیه و تحلیل تصویر ساده. نقشه های نقشه برداری
- http://www.youtube.com/watch؟v\u003dTE99WDBRRUI. - مستندات OpenCV: تشخیص گوشه هریس
- http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_feature2d/py_features_harris/py_features_harris.html - ویکی پدیا: blob_detection
- http://en.wikipedia.org/wiki/blob_detection. - Anton Konusin Computer Vision (2011). سخنرانی 5. ویژگی های محلی
- http://www.youtube.com/watch؟v\u003dvfseuiciss-s.
کتابخانه دید کامپیوتر و یادگیری ماشین باز منبع باز. این شامل بیش از 2500 الگوریتم است که در آن الگوریتم های کلاسیک و مدرن برای دیدگاه کامپیوتر و یادگیری ماشین وجود دارد. این کتابخانه دارای رابط های مختلف در زبان های مختلف است که از جمله پایتون وجود دارد (در این مقاله ما از آن استفاده می کنیم)، جاوا، C ++ و MATLAB.
نصب و راه اندازی
دستورالعمل نصب و راه اندازی در ویندوز را می توان مشاهده کرد، و در لینوکس -.
واردات و مشاهده تصاویر
واردات CV2 IMAGE \u003d CV2.IMREAD ("./ path / to / image. وب") cv2.imshow ("تصویر"، تصویر) cv2.waitkey (0) cv2.destroyallwindows ()توجه داشته باشید هنگام خواندن روش بالا، تصویر در فضای رنگی RGB نیست (همانطور که همه عادت کرده اند) و BGR. شاید در ابتدا بسیار مهم نیست، اما به محض اینکه شما شروع به کار با رنگ کنید - باید در مورد این ویژگی بدانید. 2 راه حل وجود دارد:
- کانال 1 را تغییر دهید (R - RED) با کانال سوم (B آبی)، و سپس قرمز (0.0.255)، و نه (255،0،0).
- فضای رنگ را در RGB تغییر دهید: rgb_image \u003d cv2.cvtcolor (تصویر، cv2.color_bgr2rgb)
و سپس در کد کار دیگر با تصویر، اما با RGB_IMAGE.
توجه داشته باشید برای بستن پنجره که در آن تصویر نمایش داده می شود، هر کلید را فشار دهید. اگر از دکمه بستن پنجره استفاده می کنید، می توانید بر روی آویزان بمانید.
در طول مقاله، کد زیر برای نمایش تصاویر استفاده می شود:
واردات CV2 DEF ViewImage: cv2.amedow (name_of_window، cv2.window_normal) cv2.imshow (name_of_window، تصویر) cv2.waitkey (0) cv2.destroyallwindows ()
جنجالی
Pensik پس از برداشت
واردات CV2 cropped \u003d تصویر نمایش (بریده شده، "pinsyk پس از کادیک")
جایی که تصویر تصویر است
تغییر اندازه
پس از تغییر اندازه 20٪
واردات cv2 scale_percent \u003d 20 # درصد از اندازه اصلی عرض \u003d int (img.shape * scale_percent / 100) ارتفاع \u003d int (img.shape * scale_percent / 100) dim \u003d (عرض، ارتفاع) تغییر اندازه شده \u003d cv2.Resize (IMG، DIM، interpolation \u003d cv2.inter_area) viewmage (تغییر اندازه، پس از تغییر اندازه 20٪ ")
این ویژگی نسبت به تصویر نسبت تصویر اصلی را در نظر می گیرد. تغییرات اندازه تصویر دیگر دیده می شود.
دور زدن
Pensik پس از تبدیل 180 درجه
واردات CV2 (H، W، D) \u003d image.shape center \u003d (w // 2، h // 2) m \u003d cv2.getrotationmatrix2d (مرکز، 180، 1.0) چرخش \u003d cv2.warpaffine (تصویر، M، (W ، h)) viewImage (چرخش، "Pensik پس از تبدیل 180 درجه")
image.Shape بازگشت ارتفاع، عرض و کانال ها. M - ماتریس به نوبه خود - تبدیل تصویر 180 درجه در اطراف مرکز. -ve یک زاویه چرخش تصویر در جهت عقربه های ساعت، به ترتیب، به ترتیب، به ترتیب، به ترتیب.
ترجمه در سیاه و سفید و تصویر سیاه و سفید در آستانه
Pensik در درجه بندی های خاکستری
گربه سیاه و سفید
واردات cv2 gray_image \u003d cv2.color_bgr2gray) ret، threshold_image \u003d cv2.threshold (IM، 127، 255، 0) viewImage (gray_image، "pensik در نمرات خاکستری") viewImage (threshold_image، "Pensik سیاه و سفید")
gray_Image یک نسخه تک کانال از تصویر است.
تابع آستانه یک تصویر را باز می گرداند که در آن تمام پیکسل هایی که تیره تر هستند (کمتر) 127 جایگزین 0 می شوند و همه چیز روشن تر (بیشتر) 127 255 است.
برای وضوح، مثال دیگری:
RET، Threshold \u003d CV2.Threshold (IM، 150، 200، 10)
در اینجا، همه چیز که تیره تر از 150 است، 10 جایگزین می شود و هر چیزی که روشن تر است 200 است.
ویژگی های آستانه باقی مانده شرح داده شده است.
تاری / صاف کردن
پختن پنیک
واردات cv2 tlurred \u003d cv2.gaussianblur (تصویر، (51، 51)، 0) ViewImage (تار، "مبهم پنگک")
عملکرد Gaussianblur (Blur در Gauss) طول می کشد 3 پارامتر:
- تصویر منبع
- Meancake از 2 عدد مثبت مثبت. بیشتر تعداد، قدرت صاف تر.
- sigmax و sigmay. اگر این پارامترها برابر با 0 باشند، ارزش آنها به صورت خودکار محاسبه می شود.
مستطیل نقاشی
یک پوزه مستطیل ریمس را ملزم کنید
واردات CV2 خروجی \u003d Image.Copy () CV2.Rectangle (خروجی، (2600، 800)، (4100، 2400، 2500)، (0، 255، 255)، 10) ViewImage (خروجی "، خروجی یک چهره مستطیل از Pensik" )
این ویژگی 5 پارامتر طول می کشد:
- تصویر خود.
- مختصات گوشه سمت چپ بالا (x1، y1).
- مختصات گوشه پایین سمت راست (x2، y2).
- رنگ مستطیل (GBR / RGB بسته به مدل رنگ انتخاب شده).
- ضخامت خط مستطیل.
خطوط نقاشی
2 پین، جدا شده توسط خط
وارد خروجی CV2 \u003d Image.Copy () CV2.Line (خروجی، (60، 20)، (400، 200)، (0، 0، 255)، 5) ViewImage (خروجی، 2 پین، جدا شده توسط خط ")
ویژگی خط 5 پارامتر طول می کشد:
- تصویر خود را که در آن خط کشیده شده است.
- مختصات نقطه اول (x1، y1).
- مختصات نقطه دوم (x2، y2).
- رنگ خط (GBR / RGB بسته به مدل رنگ انتخاب شده).
- ضخامت خط.
متن بر روی تصویر
تصویر با متن
واردات CV2 خروجی \u003d image.copy () cv2.puttext (خروجی، ما<3 Dogs", (1500, 3600),cv2.FONT_HERSHEY_SIMPLEX, 15, (30, 105, 210), 40) viewImage(output, "Изображение с текстом")
ویژگی Puttext 7 پارامتر طول می کشد:
- به طور مستقیم تصویر
- متن برای تصویر
- مختصات گوشه پایین سمت چپ متن متن (x، y).
- تصویر پردازش شده در درجه بندی خاکستری.
- پارامتر Scalactor برخی از چهره ها ممکن است بیش از دیگران باشد زیرا آنها نزدیک تر از دیگران هستند. این پارامتر برای چشم انداز جبران می شود.
- الگوریتم تشخیص از پنجره کشویی در طول تشخیص شی استفاده می کند. پارامتر Minneighbors تعداد اشیا را در اطراف صورت تعریف می کند. به این معناست که ارزش این پارامتر بیشتر است، اشیاء مشابهی که برای الگوریتم لازم است، به طوری که جسم فعلی را به صورت چهره تعیین می کند. تعداد مثبت کاذب بیش از حد کوچکتر می شود و الگوریتم بیش از حد بیشتر خواستار خواهد بود.
- mINISIZE - به طور مستقیم اندازه این مناطق.
افراد یافت شده: 2
واردات cv2 image_path \u003d "./put/foto.rasshirenie" face_cascade \u003d cv2.cascadecade \u003d cv2.cascadecadeacifier ("haarcascade_frontalface_default.xml") image \u003d cv2.imread (image_path) gray \u003d cv2.cvtcolor (تصویر، cv2.color_bgray) faces \u003d face_cascade .detectmultiscale (خاکستری، scalfactor \u003d 1.1، minneighbors \u003d 5، minsize \u003d (10، 10)) faces_detected \u003d "افراد یافت شده:" + فرمت (چهره) چاپ (faces_detected) # قرعه کشی مربع در اطراف صورت (X، Y، W، h) در چهره ها: cv2.Rectangle (تصویر، (x، y)، (x + w، y + h)، (255، 255، 0)، 2) viewImage (تصویر، faces_detecteded)
detectMultiscale یک تابع کلی برای شناخت هر دو افراد و اشیاء است. به منظور تابع به دنبال دقیقا چهره، ما به آن آبشار مربوطه منتقل می شود.
ویژگی DetectMultiscale 4 پارامتر طول می کشد:
خطوط - تشخیص شیء
تشخیص شیء با استفاده از تقسیم بندی رنگ ساخته شده است. برای این دو توابع وجود دارد: cv2.findcontours و cv2.drawcontours.
این مقاله جزئیات تشخیص اشیا را با استفاده از تقسیم بندی رنگ توصیف می کند. همه چیزهایی که برای آن نیاز دارید وجود دارد.
صرفه جویی در یک تصویر
واردات cv2 image \u003d cv2.imread ("/ واردات / مسیر وزن") cv2.imwrite ("./ export / path. وزن"، تصویر)نتیجه
OpenCV یک کتابخانه عالی با الگوریتم های سبک است که می تواند در رندر 3D، تصاویر پیشرفته ویرایش و ویدئو، ردیابی و شناسایی اشیاء و افراد در ویدئو استفاده شود، به دنبال تصاویر یکسان از مجموعه و بسیاری از چیزهای بسیاری است.
این کتابخانه برای کسانی که پروژه های مربوط به یادگیری ماشین را در زمینه تصاویر توسعه می دهند بسیار مهم است.