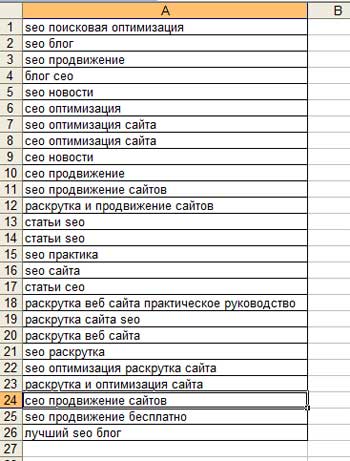
Jaki jest rdzeń semantyczny witryny? Rdzeń semantyczny serwisu (dalej nazywany Sya) To zbiór słów kluczowych i fraz, dla których zasób postęp w wyszukiwarkach i które wskazują, że witryna należy do określonego przedmiot.
Dla skutecznej promocji w wyszukiwarkach słowa kluczowe muszą być odpowiednio pogrupowane i rozmieszczone na stronach serwisu oraz w określonej formie zawartej w metaopisach (,, słowach kluczowych), a także w nagłówkach H1-H6. Jednocześnie nie należy zezwalać na nadmierne przesyłanie pieniędzy, aby nie „odlecieć” do Baden-Baden.
W tym artykule postaramy się spojrzeć na problem nie tylko z technicznego punktu widzenia, ale także spojrzeć na problem oczami właścicieli firm i marketerów.
Jaka jest kolekcja SJ?
- podręcznik - możliwe dla małych witryn (do 1000 słów kluczowych).
- Automatyczny - programy nie zawsze poprawnie określają kontekst zapytania, dlatego mogą wystąpić problemy z rozmieszczeniem słów kluczowych na stronach.
- Półautomatyczny - zwroty i częstotliwość są zbierane automatycznie, zwroty są dystrybuowane i korygowane ręcznie.
W tym artykule rozważymy półautomatyczne podejście do tworzenia rdzenia semantycznego, ponieważ jest ono najbardziej efektywne.
Ponadto istnieją dwa typowe przypadki podczas kompilowania CL:
- dla witryny z gotową strukturą;
- dla nowej witryny.
Druga opcja jest bardziej preferowana, ponieważ możliwe jest stworzenie idealnej struktury witryny dla wyszukiwarek.
Na czym polega proces sporządzania SA?
Praca nad utworzeniem rdzenia semantycznego podzielona jest na następujące etapy:
- Podkreślenie kierunków, w których witryna będzie promowana.
- Zbieranie słów kluczowych, analiza podobnych zapytań i sugestie wyszukiwania.
- Analiza częstotliwości, odfiltrowywanie „pustych” żądań.
- Grupowanie (grupowanie) żądań.
- Dystrybucja żądań na stronach serwisu (stworzenie idealnej struktury serwisu).
- Zalecenia dotyczące użytkowania.
Im lepiej zrobisz rdzeń witryny, a jakość w tym przypadku oznacza rozległość i głębię wypracowania semantyki, tym mocniejszy i bardziej niezawodny strumień ruchu wyszukiwania możesz wysłać do witryny i tym bardziej przyciągniesz klientów.
Jak skomponować semantyczny rdzeń witryny
Przyjrzyjmy się więc bliżej każdemu punktowi z różnymi przykładami.
W pierwszym kroku ważne jest, aby określić, które produkty i usługi w serwisie będą promowane w wynikach wyszukiwania Yandex i Google.
Przykład 1. Załóżmy, że w serwisie dostępne są dwa obszary usług: naprawa komputera w domu i szkolenie do pracy z programem Word / Excel w domu. W tym przypadku zdecydowano, że szkolenie nie jest już pożądane, więc nie ma sensu go promować, a tym samym gromadzić dla niego semantyki. Kolejna ważna kwestia, musisz zbierać nie tylko żądania zawierające „Naprawa komputera domowego”, ale również „Naprawa laptopa, naprawa komputera” i inni.
Przykład nr 2. Firma zajmuje się budownictwem o niskiej zabudowie. Ale jednocześnie buduje tylko drewniane domy. Odpowiednio, zapytania i semantyka według kierunku „Budowa domów z betonu komórkowego”lub „Budowanie murowanych domów”nie możesz zebrać.
Zbieranie semantyki
Przyjrzymy się dwóm głównym źródłom słów kluczowych: Yandex i Google. Powiemy Ci, jak bezpłatnie gromadzić semantykę i krótko przejrzyj płatne usługi, które pozwalają przyspieszyć i zautomatyzować ten proces.
W Yandex kluczowe frazy zbierane są z serwisu Yandex.Wordstat oraz w Google poprzez statystyki zapytań w Google AdWords. Jeśli są dostępne, dane z Yandex Webmaster i Yandex Metrics, Google Webmaster i Google Analytics mogą być wykorzystane jako dodatkowe źródła semantyki.
Zbieranie słów kluczowych z Yandex.Wordstat
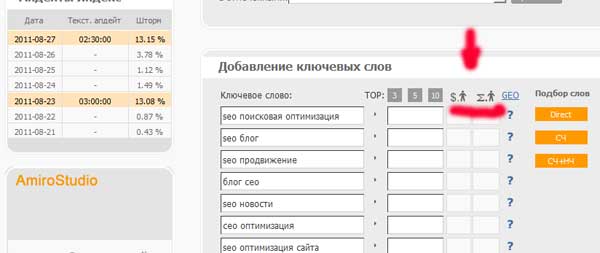
Zbieranie zapytań z Wordstat można uznać za bezpłatne. Aby wyświetlić dane tej usługi, potrzebujesz tylko konta Yandex. Więc idź do wordstat.yandex.rui wprowadź słowo kluczowe. Rozważmy przykład zbierania semantyki dla strony internetowej wypożyczalni samochodów.

Co widzimy na tym zrzucie ekranu?
- Lewa kolumna... Oto główne żądanie i jego różne odmiany z "Ogon".Naprzeciw każdego żądania znajduje się liczba wskazująca, ile zawiera dane żądanie generał był używany przez różnych użytkowników.
- Prawa kolumna... Zapytania podobne do głównego i wskaźniki ich ogólnej częstotliwości. Tutaj widzimy, że osoba, która oprócz wniosku chce wynająć samochód, chce "wypożyczalnia samochodów",można używać „Wynajem samochodów”, „Wynajem samochodów”, „Wynajem samochodów”i inni. To bardzo ważne dane, na które musisz zwrócić uwagę, aby nie przegapić ani jednej prośby.
- Regionalność i historia... Wybierając jedną z możliwych opcji, możesz sprawdzić rozkład zapytań według regionu, liczbę zapytań w danym regionie lub mieście oraz tendencję do zmian w czasie lub wraz ze zmianą pór roku.
- Urządzeniaz którego złożono wniosek. Przełączając zakładki, możesz zobaczyć, z których urządzeń są najczęściej wyszukiwane.
Sprawdź różne warianty fraz kluczowych i zapisz uzyskane dane w tabelach Excela lub Google. Dla wygody zainstaluj wtyczkę Yandex Wordstat Helper. Po zainstalowaniu obok wyszukiwanych fraz pojawią się znaki plus, po kliknięciu na które słowa zostaną skopiowane, nie będzie trzeba ręcznie wybierać i wstawiać wskaźnika częstotliwości.
Zbieranie słów kluczowych z Google AdWords
Niestety, Google nie ma otwartego źródła zapytań wyszukiwania z ich wskaźnikami częstotliwości, więc musimy tutaj popracować. Do tego potrzebujemy działającego konta Google AdWords.
Rejestrujemy konto w Google AdWords i uzupełniamy saldo na minimalną możliwą kwotę - 300 rubli (na koncie nieaktywnym pod względem budżetu wyświetlane są przybliżone dane). Następnie przejdź do „Narzędzia” - „Planer słów kluczowych”.

Otworzy się nowa strona, na której w zakładce „Wyszukaj nowe słowa kluczowe według frazy, witryny lub kategorii” wprowadź słowo kluczowe.

Przewiń w dół, kliknij „Pobierz opcje” i zobacz coś takiego.

- Podstawowe żądanie i średnia liczba żądań w miesiącu. Jeśli konto nie jest opłacone, zobaczysz przybliżone dane, czyli średnią liczbę żądań. Gdy na koncie są środki, zostaną pokazane dokładne dane, a także dynamika zmiany częstotliwości wprowadzanego słowa kluczowego.
- Słowa kluczowe według trafności. To jest to samo, co podobne zapytania w Yandex Wordstat.
- Pobieranie danych. To narzędzie jest wygodne, ponieważ dane w nim uzyskane można pobrać.
Omówiliśmy pracę z dwoma głównymi źródłami statystyk wyszukiwanych haseł. Przejdźmy teraz do automatyzacji tego procesu, ponieważ ręczne zbieranie semantyki zajmuje zbyt dużo czasu.
Programy i usługi do zbierania słów kluczowych
Kolekcjoner kluczy
Program jest zainstalowany na komputerze. Program łączy konta służbowe, z których będą zbierane statystyki. Następnie tworzony jest nowy projekt i folder na słowa kluczowe.
Wybierz „Zbiorcze zbieranie słów z lewej kolumny Yandex.Wordstat”, wprowadź żądania, dla których zbieramy dane.

Przykład przedstawiono na zrzucie ekranu, w rzeczywistości, aby uzyskać bardziej kompletny SY, tutaj dodatkowo musisz zebrać wszystkie opcje zapytań z markami i klasami samochodów. Na przykład „wypożyczenie bmw”, „kup toyotę z opcją zakupu”, „wypożyczyć SUV-a” i tak dalej.
SlovoEb
Bezpłatny analog poprzedni program. Można to uznać zarówno za plus - nie trzeba płacić, jak i minus - program ma znacznie ograniczoną funkcjonalność.
W przypadku zbierania słów kluczowych kroki są takie same.
Rush-analytics.ru
Serwis internetowy. Jego główną zaletą jest to, że nie musisz niczego pobierać ani instalować. Zarejestruj się i korzystaj. Usługa jest płatna, ale rejestrując się masz na koncie 200 monet, co wystarcza na zebranie małej semantyki (do 5000 żądań) i przeanalizowanie częstotliwości.
Wadą jest zbieranie semantyki tylko z Wordstat.
Sprawdzanie częstotliwości słów kluczowych i zapytań

I znowu zauważamy spadek liczby wniosków. Śmiało i wypróbuj inną formę słowa dla tego samego zapytania.

Zwracamy uwagę, że w liczbie pojedynczej żądanie to dotyczy znacznie mniejszej liczby użytkowników, co oznacza, że \u200b\u200bpierwsze żądanie ma dla nas wyższy priorytet.
Takie manipulacje należy przeprowadzać z każdym słowem i frazą. Te zapytania, dla których całkowita częstotliwość jest równa zero (przy użyciu cudzysłowów i wykrzyknika), są eliminowane, ponieważ „0” - oznacza, że \u200b\u200bnikt nie wprowadza takich żądań, a te żądania są tylko częścią innych. Celem budowania rdzenia semantycznego jest wybranie zapytań, których ludzie używają do wyszukiwania. Wszystkie żądania są następnie umieszczane w tabeli programu Excel, pogrupowane według znaczeń i rozprowadzane na stronach serwisu.

Robienie tego ręcznie jest po prostu nierealne, więc istnieje wiele usług w Internecie, płatnych i bezpłatnych, które pozwalają to zrobić automatycznie. Tu jest kilka:
- megaindex.com;
- rush-analytics.ru;
- tools.pixelplus.ru;
- key-collector.ru.
Usuwanie nieodpowiednich próśb
Po przesianiu słów kluczowych należy usunąć niepotrzebne. Jakie wyszukiwane hasła można usunąć z listy?
- zapytania z nazwami firm konkurencji (możesz zostawić);
- zapytania dotyczące towarów lub usług, których nie sprzedajesz;
- prośby wskazujące dzielnicę lub obszar, w którym nie pracujesz.
Grupowanie (grupowanie) żądań stron witryny
Istotą tego etapu jest łączenie zapytań o podobnym znaczeniu w klastry, a następnie ustalanie, na które strony będą promowane. Jak zrozumieć, które zapytania promować na jednej stronie, a które na innej?
1. Według typu zapytania.
Wiemy już, że wszystko jest podzielone na kilka typów, w zależności od celu wyszukiwania:
- komercyjne (kup, sprzedaj, zamów) - promowane są na strony docelowe, strony kategorii produktów, karty produktów, strony usług, cenniki;
- informacyjne (gdzie, jak, dlaczego, dlaczego) - artykuły, tematy na forum, nagłówek odpowiedzi na pytanie;
- nawigacja (telefon, adres, marka) - strona z kontaktami.
Jeśli masz wątpliwości co do typu żądania, wprowadź ciąg wyszukiwania i przeanalizuj wyniki. Na zapytanie komercyjne będzie więcej stron z ofertą usług, na informacyjną - artykuły.
Jest również. Większość zapytań handlowych jest zależnych od lokalizacji geograficznej, ponieważ ludzie bardziej ufają firmom w swoim mieście.
2. Logika żądania.
- "Kup iphone x" i "iphone x cena" - musisz promować jedną stronę, tak jak w pierwszym i drugim przypadku wyszukiwanie dotyczy tego samego produktu i bardziej szczegółowych informacji na jego temat;
- „Kup iPhone'a” i „Kup iPhone'a x” - należy promować na różnych stronach, ponieważ w pierwszym zapytaniu mamy do czynienia z zapytaniem ogólnym (odpowiednim dla kategorii produktów, w której znajdują się iPhone'y), aw drugim użytkownik szuka konkretnego produktu i to żądanie następuje promować towary na karcie;
- „Jak wybrać dobrego smartfona” - bardziej logiczne jest promowanie tej prośby w artykule na blogu z odpowiednim tytułem.
Zobacz ich wyniki wyszukiwania. Jeśli sprawdzisz, które strony różnych serwisów mają zapytania o „budowę domów z baru” i „budowę domów z cegieł”, to w 99% przypadków są to różne strony.
4. Automatyczne grupowanie według oprogramowania i ręczna rewizja.
Pierwsza i druga metoda doskonale nadają się do kompilowania semantycznego rdzenia małych witryn, w których gromadzonych jest maksymalnie 2-3 tysiące słów kluczowych. W przypadku dużego SN (od 10000 do nieskończonej liczby żądań) potrzebna jest pomoc maszyn. Oto kilka programów i usług, które umożliwiają tworzenie klastrów:
- KeyAssistant - assistant.contentmonster.ru;
- semparser.ru;
- just-magic.org;
- rush-analytics.ru;
- tools.pixelplus.ru;
- key-collector.ru.
Po zakończeniu automatycznego klastrowania konieczne jest ręczne sprawdzenie wyniku programu i, jeśli wystąpią błędy, poprawienie go.
Przykład: program może wysyłać następujące zapytania do jednego klastra: „wakacje w hotelu Soczi 2018” oraz „wakacje w hotelu Soczi 2018” - w pierwszym przypadku użytkownik poszukuje różnych opcji zakwaterowania w hotelu, w drugim konkretnego hotelu.
Aby wyeliminować występowanie takich nieścisłości, musisz ręcznie sprawdzić wszystko, a jeśli zostaną znalezione błędy, poprawić.
Co dalej, po skompilowaniu rdzenia semantycznego?
Na podstawie złożonego rdzenia semantycznego:
- tworzymy idealną strukturę (hierarchię) serwisu z punktu widzenia wyszukiwarek;
lub po uzgodnieniu z klientem zmieniamy strukturę starej witryny; - piszemy specyfikacje techniczne dla copywriterów do pisania tekstów z uwzględnieniem klastra zgłoszeń, które będą promowane na tej stronie;
lub finalizowanie starych artykułów i tekstów na stronie.
Wygląda mniej więcej tak.

Dla każdego wygenerowanego klastra zapytań tworzymy stronę w serwisie i określamy jej miejsce w strukturze serwisu. Najpopularniejsze zapytania są promowane na najwyższe strony w hierarchii zasobów, mniej popularne znajdują się pod nimi.
Dla każdej z tych stron zebraliśmy już prośby, które będziemy na nich promować. Następnie piszemy copywriterów TK, aby stworzyli tekst na te strony.
Warunki odniesienia dla copywritera
Podobnie jak w przypadku struktury serwisu, ten etap opiszemy ogólnie. Tak więc zakres zadań dla tekstu:
- liczba znaków bez spacji;
- tytuł strony;
- podpozycje (jeśli występują);
- lista słów (w oparciu o nasz rdzeń), które powinny znaleźć się w tekście;
- wymóg wyjątkowości (zawsze wymagaj 100% niepowtarzalności);
- żądany styl tekstu;
- inne wymagania i życzenia dotyczące tekstu.
Pamiętaj, nie próbuj promować +100500 zapytań na jednej stronie, ogranicz się do 5-10 + tail, w przeciwnym razie dostaniesz zakaz ponownej optymalizacji i wylecisz z gry na długi czas o miejsce w TOP.
Wynik
Kompilacja semantycznego rdzenia serwisu to żmudna i ciężka praca, na którą należy zwrócić szczególną uwagę, ponieważ to na nim opiera się dalsza promocja serwisu. Postępuj zgodnie z prostymi instrukcjami w tym artykule i podejmij działania.
- Wybierz kierunek promocji.
- Zbierz wszystkie możliwe żądania od Yandex i Google (korzystaj ze specjalnych programów i usług).
- Sprawdź częstotliwość żądań i pozbądź się spacji (które mają częstotliwość 0).
- Usuń zapytania niedocelowe - usługi i produkty, których nie sprzedajesz, zapytanie wspominające o konkurencji.
- Utwórz klastry zapytań i rozprowadź je na stronach.
- Stwórz idealną strukturę witryny i przygotuj zadanie techniczne dotyczące jej wypełnienia.
Rdzeń semantyczny to dość oklepany temat, prawda? Dzisiaj naprawimy to razem, łącząc semantykę w tym samouczku!
Nie wierzysz mi? - przekonaj się sam - wystarczy wprowadzić frazę do semantycznego rdzenia strony do Yandex lub Google. Myślę, że dzisiaj poprawię ten irytujący błąd.
Ale tak naprawdę, kim ona jest dla ciebie - doskonała semantyka? Można by pomyśleć, że to głupie pytanie, ale w rzeczywistości wcale nie jest głupie, po prostu większość webmasterów i właścicieli witryn mocno wierzy, że potrafią komponować rdzenie semantyczne i że każdy uczeń może sobie z tym wszystkim poradzić. i sami próbują uczyć innych ... Ale w rzeczywistości wszystko jest znacznie bardziej skomplikowane. Kiedyś zapytano mnie - co mam zrobić najpierw? - samą witrynę i jej zawartość, lub sem core, i zapytał człowieka, który nie uważa się za nowicjusza w SEO. To pytanie pozwoliło mi zrozumieć złożoność i niejednoznaczność tego problemu.
Rdzeń semantyczny - podstawa podstaw - jest pierwszym krokiem poprzedzającym rozpoczęcie jakiejkolwiek kampanii reklamowej w Internecie. Poza tym semantyka strony jest najbardziej ponurym procesem, który zajmie dużo czasu, ale w każdym przypadku opłaci się odsetkami.
Cóż ... Stwórzmy jego razem!
Mała przedmowa
Do stworzenia pola semantycznego serwisu potrzebny jest jeden i jedyny program - Kolekcjoner kluczy... Na przykładzie Collectora przeanalizuję przykład zebrania małej grupy semestralnej. Oprócz płatnego programu dostępne są bezpłatne analogi, takie jak SlovoEb i inne.
Semantyka zbierana jest w kilku podstawowych etapach, wśród których należy wyróżnić:
- burza mózgów - analiza podstawowych zwrotów i przygotowanie parsowania
- parsowanie - rozszerzenie podstawowej semantyki opartej na Wordstacie i innych źródłach
- dropout - dropout po parsowaniu
- analiza - analiza częstotliwości, sezonowości, konkurencji i innych ważnych wskaźników
- rewizja - grupowanie, rozdzielanie fraz handlowych i informacyjnych rdzenia
Poniżej omówione zostaną najważniejsze etapy zbiórki!
VIDEO - kompilacja rdzenia semantycznego dla zawodników
Semantyczny rdzeń burzy mózgów - wytężanie mózgów
Na tym etapie jest to konieczne dokonaj wyborusemantyczny rdzeń witryny i wymyśl jak najwięcej fraz dla naszego tematu. Tak więc uruchamiamy kolektor kluczy i wybieramy parsowanie Wordstatjak pokazano na zrzucie ekranu:

Otworzy się przed nami małe okienko, w którym musisz wpisać maksymalnie fraz na nasz temat. Jak już powiedziałem, w tym artykule stworzymy przykładowy zestaw fraz dla tego blogawięc wyrażenia mogą wyglądać następująco:
- blog SEO
- blog SEO
- blog o SEO
- blog o seo
- awans
- awans projekt
- awans
- awans
- promocja bloga
- promocja bloga
- promocja blogów
- promocja bloga
- artykuły promocyjne
- promocja artykułu
- miralinks
- pracować w sape
- kupowanie linków
- kupowanie linków
- optymalizacja
- optymalizacja strony
- wewnętrzna optymalizacja
- auto-promocja
- jak promować zasób
- jak promować swoją witrynę
- jak samodzielnie promować witrynę
- jak samodzielnie wypromować stronę internetową
- auto-promocja
- bezpłatna promocja
- bezpłatna promocja
- optymalizacja wyszukiwarki
- jak promować witrynę w Yandex
- jak promować witrynę w Yandex
- promocja w Yandex
- promocja google
- promocja w google
- indeksowanie
- szybsze indeksowanie
- wybór dawcy dla witryny
- badanie dawców
- promocja przez strażników
- stosowanie osłon
- promocja bloga
- algorytm Yandex
- update tic
- aktualizacja bazy wyszukiwania
- aktualizacja Yandex
- linki na zawsze
- wieczne więzi
- łącze do wynajęcia
- wypożyczony link
- linki z płatnością miesięczną
- kompilacja rdzenia semantycznego
- tajemnice promocji
- tajemnice promocji
- sekrety seo
- tajemnice optymalizacji
Myślę, że to wystarczy, więc lista to pół strony;) \u200b\u200bGeneralnie chodzi o to, żeby na pierwszym etapie przeanalizować swoją branżę jak najwięcej i wybrać jak najwięcej fraz, które odzwierciedlają tematykę serwisu. Chociaż jeśli coś przegapiłeś na tym etapie - nie rozpaczaj - na następnych etapach z pewnością pojawią się brakujące frazy, po prostu musisz wykonać dużo dodatkowej pracy, ale to jest w porządku. Bierzemy naszą listę i kopiujemy ją do kolektora kluczy. Następnie kliknij przycisk - Analiza z Yandex.Wordstat:
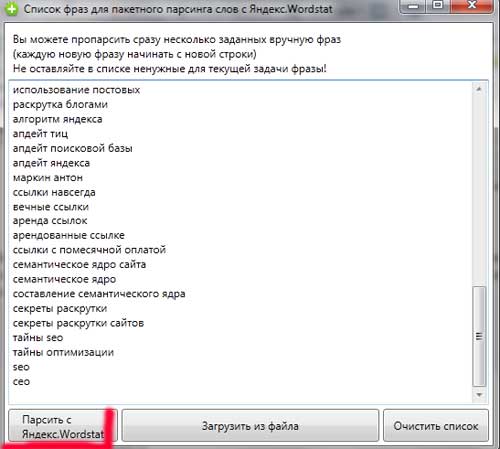
Przetwarzanie może zająć dużo czasu, więc bądź cierpliwy. Rdzeń semantyczny zajmuje zwykle 3-5 dni, a pierwszy dzień poświęcony będzie na przygotowanie podstawowego rdzenia semantycznego i parsowanie.
Napisałem szczegółowe instrukcje, jak pracować z zasobem, jak dobierać słowa kluczowe. Możesz też dowiedzieć się o promocji witryny pod kątem żądań o niskiej częstotliwości.
Dodatkowo powiem, że zamiast burzy mózgów, możemy skorzystać z gotowej semantyki konkurencji korzystającej z jednej ze specjalistycznych usług, na przykład SpyWords. W interfejsie tej usługi po prostu wpisujemy potrzebne nam słowo kluczowe i widzimy głównych konkurentów, którzy są w TOP dla tego wyrażenia. Co więcej, za pomocą tej usługi można całkowicie rozładować semantykę witryny konkurencji.

Ponadto możemy wybrać dowolne z nich i wyciągnąć z nich żądania, które pozostaną do usunięcia ze śmieci i użyte jako podstawowa semantyka do dalszego analizowania. Albo możemy to zrobić jeszcze łatwiej i wykorzystać.
Czyszczenie semantyki
Gdy tylko parsowanie wordstat zostanie całkowicie zatrzymane - czas usunąć rdzeń semantyczny... Ten etap jest bardzo ważny, dlatego traktuj go z należytą uwagą.
Tak więc moja analiza zakończyła się, ale frazy się skończyły Wielei dlatego odszukiwanie słów może zająć nam zbyt dużo czasu. Dlatego przed przystąpieniem do definicji częstotliwości należy przeprowadzić podstawowe czyszczenie słów. Zrobimy to w kilku etapach:
1. Odfiltrujmy zapytania o bardzo niskich częstotliwościach
Aby to zrobić, zarabiamy na symbolu sortowania według częstotliwości i zaczynamy czyścić wszystkie żądania o częstotliwościach poniżej 30:
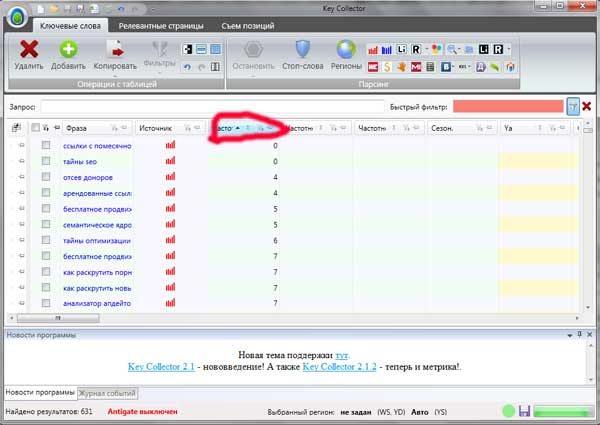
Myślę, że z tym przedmiotem bez problemu sobie poradzisz.
2. Usuńmy nieodpowiednie zapytania
Istnieją żądania, które mają wystarczającą częstotliwość i małą konkurencję, ale tak jest w ogóle nie pasują do naszego tematu... Takie klucze należy usunąć przed sprawdzeniem dokładnych wystąpień klucza. weryfikacja może być bardzo czasochłonna. Ręcznie usuniemy takie klucze. Tak więc w przypadku mojego bloga zbędne okazały się:
kursy optymalizacji pod kątem wyszukiwarek sprzedaż promowanej witryny
Analiza rdzenia semantycznego
Na tym etapie musimy określić dokładne częstotliwości naszych kluczy, dla których należy kliknąć symbol lupy, jak pokazano na obrazku:

Proces jest dość długi, więc możesz iść i zrobić sobie herbatę)
Po pomyślnym sprawdzeniu należy kontynuować czyszczenie naszego jądra.
Proponuję usunąć wszystkie klucze z częstotliwością mniejszą niż 10 żądań. Poza tym w przypadku mojego bloga usunę wszystkie żądania o wartości powyżej 1000, ponieważ nie planuję jeszcze przesuwać takich wniosków.
Eksport i grupowanie rdzenia semantycznego
Nie myśl, że ten etap będzie ostatnim. Ani trochę! Teraz musimy przenieść powstałą grupę do programu Exel, aby uzyskać maksymalną przejrzystość. Następnie posortujemy według stron, a wtedy zobaczymy wiele niedociągnięć i naprawimy je.
Nie jest trudno wyeksportować semantykę witryny do Exela. Aby to zrobić, wystarczy kliknąć odpowiedni symbol, jak pokazano na obrazku:
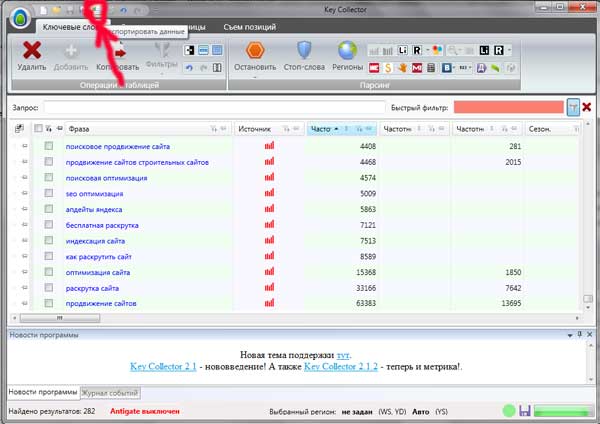
Po wstawieniu do Exela zobaczymy następujący obrazek:
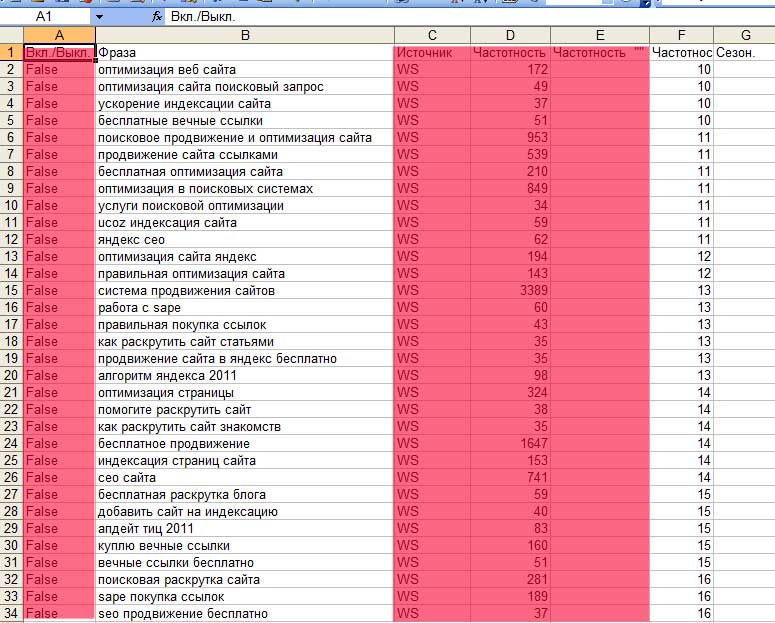
Kolumny zaznaczone na czerwono należy usunąć. Następnie tworzymy kolejną tabelę w Exelu, która będzie zawierać ostatni rdzeń semantyczny.
Nowa tabela będzie miała 3 kolumny: Urlstron, fraza kluczowa i jego częstotliwość... Jako adres URL wybierz istniejącą stronę lub stronę, która zostanie utworzona w perspektywie. Najpierw wybierzmy klucze do strony głównej mojego bloga:

Po wszystkich manipulacjach widzimy następujący obraz. I natychmiast nasuwa się kilka wniosków:
- częste zapytania, takie jak te, powinny mieć znacznie większy ogon z rzadziej występujących fraz, niż widzimy
- wiadomości SEO
- pojawił się nowy klucz, którego wcześniej nie braliśmy pod uwagę - artykuły SEO... Ten klucz musi zostać przeanalizowany
Jak powiedziałem, żaden klucz nie może się przed nami ukryć. Następnym krokiem jest dla nas burza mózgów. Po burzy mózgów powtórz wszystkie kroki, zaczynając od pierwszego punktu dla tych kluczy. Możesz pomyśleć, że to wszystko jest zbyt długie i żmudne, ale tak jest - kompilacja rdzenia semantycznego jest bardzo odpowiedzialną i żmudną pracą. Z drugiej strony dobrze zaprojektowane to pole znacznie pomoże w promocji strony internetowej i może znacznie zaoszczędzić budżet.
Po wykonaniu wszystkich operacji udało nam się uzyskać nowe klucze do strony głównej tego bloga:
- najlepszy blog SEO
- wiadomości SEO
- artykuły SEO
I kilka innych. Myślę, że technika jest dla ciebie jasna.
Po tych wszystkich manipulacjach zobaczymy, które strony naszego projektu wymagają zmiany (), a które nowe strony należy dodać. Większość znalezionych kluczy (z częstotliwością do 100, a czasem znacznie większą) można łatwo promować samodzielnie.
Ostateczna eliminacja
Zasadniczo rdzeń semantyczny jest prawie gotowy, ale jest jeszcze jeden dość ważny punkt, który pomoże nam znacznie ulepszyć naszą grupę semantyczną. Do tego potrzebujemy Seopult.
* W rzeczywistości tutaj możesz skorzystać z dowolnej z podobnych usług, które pozwalają poznać konkurencję za pomocą słów kluczowych, na przykład Mutagen!
Tak więc tworzymy kolejną tabelę w Exelu i kopiujemy tylko nazwy kluczy tam (środkowa kolumna). Aby nie tracić dużo czasu, skopiuję tylko klucze do strony głównej mojego bloga:

Następnie sprawdzamy koszt uzyskania jednego kliknięcia w nasze słowa kluczowe:
Koszt przejrzenia niektórych fraz przekroczył 5 rubli. Takie frazy należy wykluczyć z naszego rdzenia.

Być może twoje preferencje okażą się nieco inne, wtedy możesz wykluczyć tańsze frazy lub odwrotnie. W moim przypadku skasowałem 7 fraz.
Przydatna informacja!
na kompilacji rdzenia semantycznego, z naciskiem na selekcję słów kluczowych o najniższej konkurencyjności.
Jeśli masz własny sklep internetowy - czytać opis, w jaki sposób można wykorzystać rdzeń semantyczny.
Klastrowanie rdzeni semantycznych
Jestem pewien, że słyszałeś już to słowo w odniesieniu do promocji w wyszukiwarkach. Zastanówmy się, co to za bestia i dlaczego jest potrzebna przy promocji strony internetowej.
Klasyczny model promocji w wyszukiwarkach wygląda następująco:
- Wybór i analiza zapytań wyszukiwania
- Grupowanie żądań według stron serwisu (tworzenie stron docelowych)
- Przygotowywanie tekstów SEO dla stron docelowych na podstawie grupy zapytań o te strony
Aby ułatwić i ulepszyć drugi etap na powyższej liście, służy grupowanie. Zasadniczo grupowanie jest metodą oprogramowania, która służy uproszczeniu tego etapu podczas pracy z dużą semantyką, ale tutaj nie jest tak prosta, jak mogłoby się wydawać na pierwszy rzut oka.
Aby lepiej zrozumieć teorię klastrowania, warto wybrać się na krótką wycieczkę do historii SEO:
Jeszcze kilka lat temu, kiedy termin clustering nie wyglądał z każdego kąta, specjaliści SEO w przeważającej większości przypadków grupowali semantykę ręcznie. Ale kiedy ogromna semantyka została pogrupowana w 1000, 10 000, a nawet 100 000 zapytań, ta procedura stała się prawdziwą ciężką pracą dla zwykłego człowieka. A potem metoda grupowania według semantyki zaczęła być używana wszędzie (a dziś wiele osób stosuje to podejście). Metoda grupowania według semantyki zakłada łączenie w jedną grupę zapytań, które mają powinowactwo semantyczne. Na przykład zapytania „kup pralkę” i „kup pralkę do 10 000 sztuk” zostały połączone w jedną grupę. I wszystko byłoby dobrze, ale ta metoda zawiera szereg krytycznych problemów i dla ich zrozumienia konieczne jest wprowadzenie do naszej narracji nowego terminu, a mianowicie - „ zamiar żądania”.
Najprostszym sposobem opisania tego terminu może być potrzeba użytkownika, jego pragnienie. Intencja to nic innego jak pragnienie użytkownika wprowadzającego zapytanie.
Podstawą semantyki grupowania jest zebranie zapytań, które mają ten sam zamiar lub najbliższe intencje w jednej grupie, a tutaj pojawiają się jednocześnie 2 interesujące funkcje, a mianowicie:
- Ta sama intencja może mieć kilka zapytań, które nie mają żadnej semantycznej bliskości, na przykład „konserwacja samochodu” i „rejestracja w celu konserwacji”
- Zapytania, które mają absolutne podobieństwo semantyczne, mogą zawierać radykalnie różne intencje, na przykład sytuacja podręcznikowa - „telefon komórkowy” i „telefon komórkowy”. W jednym przypadku użytkownik chce kupić telefon, aw drugim obejrzeć film
Zatem grupowanie semantyki według dopasowania semantycznego nie bierze pod uwagę intencji żądań. A tak skomponowane grupy nie pozwolą Ci napisać tekstu, który trafi na TOP. W czasie ręcznego grupowania, aby wyeliminować to nieporozumienie, faceci z zawodu „asystent SEO” analizowali wyniki ręcznie.
Istotą clusteringu jest porównywanie wygenerowanych wyników wyszukiwarki w poszukiwaniu wzorców. Na podstawie tej definicji należy od razu zauważyć, że samo tworzenie klastrów nie jest ostateczną prawdą, ponieważ wygenerowany problem może nie w pełni ujawniać zamiar (baza danych Yandex może po prostu nie mieć witryny, która poprawnie łączy żądania w grupę).
Mechanika grupowania jest prosta i wygląda następująco:
- System po kolei wpisuje wszystkie przesłane do niego zapytania w wynikach wyszukiwania i zapamiętuje wyniki z TOP
- Po naprzemiennym wpisywaniu zapytań i zapisywaniu wyników, system wyszukuje w wynikach przecięcia. Jeśli ta sama witryna z tym samym dokumentem (stroną witryny) znajduje się na liście TOP dla kilku zapytań jednocześnie, wówczas te zapytania można teoretycznie połączyć w jedną grupę
- Parametr, taki jak siła grupowania, staje się istotny, który informuje system dokładnie, ile skrzyżowań musi być, aby zapytania mogły zostać dodane do jednej grupy. Na przykład siła grupowania równa 2 oznacza, że \u200b\u200bw wynikach dla 2 różnych żądań muszą występować co najmniej dwa przecięcia. Mówiąc jeszcze prościej - co najmniej dwie strony dwóch różnych witryn muszą znajdować się jednocześnie w TOP dla jednego i drugiego żądania. Zobacz przykład poniżej.
- Przy grupowaniu dużej semantyki istotna staje się logika powiązań między żądaniami, na podstawie której wyróżnia się 3 podstawowe typy klastrowania: miękki, średni i twardy. O typach klastrowania będziemy mówić w kolejnych wpisach tego bloga.
Witaj! Kiedy prowadzisz blog lub serwis z treścią, zawsze istnieje potrzeba skompilowania semantycznego rdzenia dla serwisu, klastra lub artykułu. Dla wygody i spójności lepiej jest pracować z rdzeniem semantycznym zgodnie ze schematem debugowania.
W tym artykule rozważymy:
- w jaki sposób zbiera się rdzeń semantyczny do napisania artykułu;
- z jakich usług można i należy korzystać;
- jak poprawnie wprowadzić klucze do artykułu;
- moje osobiste doświadczenie w doborze młodzieży.
Jak zbudować semantyczny rdzeń online
- Przede wszystkim musimy skorzystać z usługi Yandex -. Tutaj dokonamy wstępnego wyboru możliwych kluczy.
W tym artykule będę zbierać SJ na temat „jak układać laminat”. Podobnie, możesz użyć tej instrukcji, aby utworzyć rdzeń semantyczny dla dowolnego tematu.
- Jeśli nasz artykuł jest na temat "jak układać laminat", to wpiszemy to zapytanie, aby uzyskać informacje o częstotliwości w wordstat.yandex.ru.
Jak widać, oprócz żądania docelowego, otrzymaliśmy wiele podobnych żądań zawierających frazę „Ułóż laminat”tutaj możesz zasiać wszystkie niepotrzebne, wszystkie klucze, które nie będą brane pod uwagę w naszym artykule. Na przykład nie będziemy pisać na podobne tematy, takie jak „Ile kosztuje ułożenie laminatu”, „Laminat został ułożony nierówno” itp.
Aby pozbyć się wielu oczywiście nieodpowiednich zapytań, polecam użycie operator „-” (minus).
- Zastępujemy minus, a po nim wszystkie słowa są poza tematem.

- Teraz wybierz wszystko, co zostało i skopiuj żądania do Notatnika lub Worda.

- Po wstawieniu wszystkiego do pliku Worda, przeglądamy nasze oczy i usuwamy wszystko, co nie zostanie ujawnione w naszym artykule, jeśli są fałszywe żądania, to skrót klawiaturowy pomoże sprawdzić ich obecność w dokumencie Ctrl + F.otwiera się okno (boczny pasek po lewej), w którym wpisujemy wyszukiwane słowa.
Pierwsza część pracy jest zakończona, teraz możesz sprawdzić nasz pusty rdzeń semantyczny Yandex pod kątem czystej częstotliwości, operator cytatu nam w tym pomoże.
Jeśli jest kilka słów, łatwo to zrobić bezpośrednio w wordstat, zastępując frazę w cudzysłowie i znajdując czystą częstotliwość (cudzysłowy pokazują, ile żądań zostało złożonych z treścią tej konkretnej frazy, bez dodatkowych słów)... A jeśli, tak jak w naszym przykładzie semantycznego rdzenia artykułu lub witryny, słów jest wiele, to lepiej zautomatyzować tę pracę za pomocą usługi Mutagen.
Pozbyć się liczb wykonaj poniższe czynności z dokumentem programu Word.
- Ctrl + A - aby podkreślić całą treść dokumentu.
- Ctrl + H - wywołuje okno do zamiany znaków.
- Zastąp w pierwszej linii ^ # i kliknij „zamień wszystko” ta kombinacja usunie wszystkie liczby z naszego dokumentu.
Uważaj na klawisze zawierające cyfry, powyższe kroki mogą zmienić klucz.
Wybór rdzenia semantycznego witryny / artykułu online
Tak więc szczegółowo opisałem usługę. Tutaj będziemy kontynuować nasze szkolenie w zakresie kompilowania rdzenia semantycznego.
- Wchodzimy na stronę i używamy tego programu do kompilacji rdzenia semantycznego, ponieważ nie widziałem lepszej alternatywy.
- Najpierw parsujemy czystą częstotliwość w tym celu przechodzimy przez "parser wordstat" → "mass parsing"

- Wklej wszystkie wybrane przez nas słowa z dokumentu do okna parsera (Ctrl + C i Ctrl + V) i wybierz „Częstotliwość Wordstat” w cudzysłowie.

Taka automatyzacja procesu kosztuje tylko 2 kopiejek za frazę! Jeśli wybierasz rdzeń semantyczny dla sklepu internetowego, to takie podejście pozwoli Ci zaoszczędzić czas za grosze!
- Naciskamy, aby wysłać do weryfikacji iz reguły w ciągu 10-40 sekund (w zależności od ilości słów) będziesz mógł pobrać słowa, które już mają częstotliwość w cudzysłowie.
- Plik wyjściowy ma rozszerzenie .CSV i otwiera się w programie Excel. Rozpoczynamy filtrowanie danych, aby rdzeń semantyczny był online.

- Dodajemy trzecią kolumnę, potrzebna jest do wyświetlenia konkurencji (w kolejnym kroku).
- Umieściliśmy filtr na wszystkich trzech kolumnach.
- Filtruj kolumnę „częstotliwość” „w porządku malejącym”.
- Wszystko to ma częstotliwość poniżej 10 - usunięta.
Mamy listę kluczy, które możemy wykorzystać w tekście artykułu, ale najpierw musisz sprawdzić je pod kątem konkurencji... W końcu, jeśli ten temat był używany w Internecie, czy ma sens pisać artykuł o tym kluczu? Prawdopodobieństwo, że nasz artykuł na ten temat pojawi się w TOP jest bardzo małe!
- Aby sprawdzić konkurencję rdzenia semantycznego online, przechodzimy do „konkurencji”.

- Zaczynamy sprawdzać każde żądanie i zastępujemy wynikową wartość konkurencji w odpowiedniej kolumnie w naszym pliku Excel.
Koszt sprawdza, czy jedna fraza kluczowa to 30 kopiejek.
Po pierwszym uzupełnieniu salda będziesz mieć dostęp do 10 bezpłatnych czeków każdego dnia.
Aby zidentyfikować frazy, które warto napisać artykuł wybierz najlepszy stosunek częstotliwości do konkurencji.
Warto napisać artykuł:
- częstotliwość nie mniejsza niż 300;
- konkurencja nie jest wyższa niż 12 (mniej znaczy lepiej).
Kompilacja rdzenia semantycznego online używając fraz mało konkurencyjnych da ci ruch. Jeśli masz nową witrynę, nie pojawi się ona natychmiast, będziesz musiał poczekać od 4 do 8 miesięcy.
W prawie każdym temacie można znaleźć MF i HF z niską konkurencją od 1 do 5, z takimi kluczami można uzyskać od 50 odwiedzających dziennie.
Skorzystaj z rdzenia semantycznego do grupowania zapytań, pomogą one w stworzeniu prawidłowej struktury serwisu.
Gdzie wstawić rdzeń semantyczny w tekście
Po zebraniu semantycznego rdzenia witryny, czas na wpisanie w tekście kluczowych fraz, a oto kilka zaleceń dla początkujących i tych, którzy „nie wierzą” w istnienie ruchu związanego z wyszukiwaniem.
Zasady wprowadzania słów kluczowych do tekstu
- Wystarczy raz użyć klucza;
- słowa można odmieniać w przypadkach, zamieniać;
- możesz rozcieńczyć frazy innymi słowy, dobrze jest, gdy wszystkie frazy kluczowe są rozcieńczone i czytelne;
- możesz usuwać / zamieniać przyimki i słowa pytające (jak, co, dlaczego itp.);
- możesz wstawić do frazy znaki „-” i „:”
na przykład:
jest klucz: „Jak ułożyć laminat własnymi rękami” w tekście może to wyglądać tak: "... aby własnoręcznie ułożyć płyty laminowane, potrzebujemy ..." lub tak, „Każdy, kto próbował położyć laminat własnymi rękami…”.
Niektóre frazy zawierają już inne, na przykład wyrażenie:
„Jak ułożyć laminat własnymi rękami w kuchni” zawiera już frazę kluczową „Jak ułożyć laminat własnymi rękami”... W takim przypadku można pominąć drugi, ponieważ jest już obecny w tekście. Ale jeśli kluczy jest niewiele, lepiej użyć go również w tekście, tytule lub opisie.
- jeśli nie możesz dopasować frazy do tekstu, zostaw ją, nie rób tego (w tytule i opisie można użyć co najmniej dwóch fraz i nie wpisywać ich w treści artykułu);
- wymagany, jedna fraza to tytuł artykułu (najgrubsza częstotliwość to konkurencja), w języku webmasterów - to jest H1, wystarczy raz użyć tego zwrotu w treści tekstu.
Przeciwwskazania do pisania kluczy
- nie można oddzielić frazy kluczowej przecinkiem (tylko w ostateczności) ani kropką;
- nie można wprowadzić klucza w tekście w prostej formie, aby wyglądał nienaturalnie (nieczytelnie);
Tytuł i opis strony
Tytuł i opis - to tytuł i opis strony, nie są one widoczne w artykule, są pokazywane przez Yandex i Google w wynikach wyszukiwania użytkownikowi.
Zasady pisania:
- tytuł i opis powinny być „dziennikarskie”, to znaczy atrakcyjne do przejścia;
- zawierają tekst tematyczny (zgodny z zapytaniem), w tym celu w tytule i opisie wpisujemy frazy kluczowe (rozwodnione).
Generał wymagania dotyczące postaci podłącz Wszystko w jednym pakiecie SEO, następujące:
- Tytuł - 60 znaków (ze spacjami).
- Opis - 160 znaków (ze spacjami).
Możesz sprawdzić swoje dzieło pod kątem plagiatu lub otrzymane od Ciebie za pomocą.
W związku z tym, omawiając temat, co zrobić z rdzeniem semantycznym po kompilacji, ustaliliśmy to. Na zakończenie podzielę się własnym doświadczeniem.
Po skompilowaniu rdzenia semantycznego zgodnie z instrukcją - moje doświadczenie
Możesz pomyśleć, że wącham coś, co jest niewiarygodne. Aby nie być bezzasadnym, oto zrzut ekranu statystyk z ostatniego (ale nie jedynego) roku tej strony, jak udało mi się odbudować bloga i zacząć generować ruch.
To szkolenie w zakresie kompilowania rdzenia semantycznego, choć długie, jest skuteczne, ponieważ przy tworzeniu witryn najważniejsze jest właściwe podejście i cierpliwość!
Jeśli masz jakieś pytania lub krytykę to napisz w komentarzach, będzie to dla mnie interesujące, podziel się także swoim doświadczeniem!
W kontakcie z
Rdzeń semantyczny (SJ) to zestaw słów kluczowych, zapytań, wyszukiwanych fraz, dla których musisz promować swoją witrynę, aby trafiali do niej docelowi użytkownicy z wyszukiwarek. Kompilacja rdzenia semantycznego to drugi krok po skonfigurowaniu witryny na hosting. To, ile wysokiej jakości ruchu będzie w Twojej witrynie, zależy od dobrze zaprojektowanego CL.
Konieczność skompilowania rdzenia semantycznego składa się z kilku punktów.
Po pierwsze, daje możliwość opracowania skuteczniejszej strategii promocji w wyszukiwarkach, ponieważ webmaster, który będzie stanowił rdzeń semantyczny swojego projektu, będzie miał jasne wyobrażenie, jakie metody promocji w wyszukiwarkach będzie musiał zastosować na swojej stronie, decyduje koszt promocji w wyszukiwarce, który silnie zależy od poziomu konkurencji fraz kluczowych w wynikach wyszukiwania.
Po drugie, rdzeń semantyczny umożliwia wypełnienie zasobu treścią lepszej jakości, czyli treścią, która będzie dobrze zoptymalizowana pod kątem kluczowych zapytań. Na przykład, jeśli chcesz stworzyć witrynę o sufitach napinanych, to semantyczny rdzeń zapytań powinien być wybrany „zaczynając od” tego słowa kluczowego.
Ponadto kompilacja rdzenia semantycznego implikuje określenie częstotliwości używania słów kluczowych przez użytkowników wyszukiwarek, co pozwala określić wyszukiwarkę, w której należy zwrócić większą uwagę na promocję danego zapytania.
Należy również zwrócić uwagę na pewne zasady kompilowania rdzenia semantycznego, których należy przestrzegać, aby móc skomponować wysokiej jakości i efektywny SY.
Tak więc rdzeń semantyczny musi zawierać wszystkie możliwe kluczowe zapytania, za pomocą których witryna może być promowana, z wyjątkiem tych zapytań, które nie mogą przyciągać przynajmniej niewielkiej ilości ruchu do zasobu. Dlatego rdzeń semantyczny powinien zawierać słowa kluczowe o wysokiej częstotliwości (HF), średniej (MF) i niskiej częstotliwości (LF).
Tradycyjnie wnioski te można podzielić w następujący sposób: LF - do 1000 wniosków miesięcznie, MF - od 1000 do 10 000 wniosków miesięcznie, HF - ponad 10 000 wniosków miesięcznie. Należy również wziąć pod uwagę fakt, że w różnych tematach liczby te mogą się znacznie różnić (w niektórych szczególnie wąskich tematach maksymalna częstotliwość wniosków nie przekracza 100 wniosków miesięcznie).
Zapytania o niskiej częstotliwości wystarczy włączyć w strukturę rdzenia semantycznego, ponieważ każdy młody zasób ma możliwość awansowania w wyszukiwarkach przede wszystkim za ich pośrednictwem (i bez żadnej zewnętrznej promocji serwisu - napisali artykuł na zapytanie o niskiej częstotliwości, wyszukiwarka go zaindeksowała, a strona może znaleźć się w TOP za kilka tygodni).
Konieczne jest także przestrzeganie zasady konstruowania rdzenia semantycznego, zgodnie z którą wszystkie słowa kluczowe serwisu muszą być łączone w grupy nie tylko pod względem częstotliwości, ale także stopnia podobieństwa. Umożliwi to lepszą optymalizację treści, na przykład optymalizację niektórych tekstów dla kilku zapytań.
Ponadto w strukturze semantycznego rdzenia wielu witryn wskazane jest uwzględnienie takich typów zapytań, jak zapytania synonimiczne, zapytania slangowe, skróty itp.
Oto dobry przykład tego, jak możesz zwiększyć ruch w witrynie, pisząc po prostu zoptymalizowane artykuły, które zawierają MF i dużą liczbę zapytań LF:
1. Witryna dla mężczyzn. Choć jest bardzo rzadko aktualizowany (cały czas ukazało się nieco ponad 25 artykułów), dzięki dobrze dobranym zapytaniom zyskuje coraz większy ruch. W ogóle nie zakupiono żadnych linków do strony!

W tej chwili wzrost frekwencji utknął w martwym punkcie, ponieważ opublikowano tylko 3 artykuły.
2. Witryna dla kobiet. Początkowo publikowano na nim niezoptymalizowane artykuły. Latem skompilowano rdzeń semantyczny, na który składały się zapytania o bardzo niskiej konkurencji (poniżej opiszę, jak zbierać takie zapytania). W przypadku tych próśb napisano odpowiednie artykuły i uzyskano kilka linków do zasobów tematycznych. Wyniki tej promocji możesz zobaczyć poniżej: 
3. Placówka medyczna. Wybrano niszę medyczną z mniej lub bardziej odpowiednią konkurencją i opublikowano ponad 200 artykułów na smaczne zapytania z dobrymi ofertami (w Internecie termin „oferta” oznacza koszt jednego kliknięcia w link reklamowy przez użytkownika). Zacząłem kupować linki w lutym, kiedy strona miała 1,5 miesiąca. Jak dotąd większość ruchu pochodzi z Google, Yandex nie wziął jeszcze pod uwagę zakupionych linków.

Jak widać, wybór rdzenia semantycznego odgrywa ważną rolę w promocji serwisu. Nawet dysponując niewielkim budżetem lub bez niego, możesz stworzyć witrynę z ruchem, która przyniesie Ci zysk.
Wybór zapytań wyszukiwania
Możesz wybrać zapytania dla rdzenia semantycznego w następujący sposób:
Z pomocą bezpłatnych serwisów statystyk zapytań Google, Yandex lub Rambler
Za pomocą specjalnego oprogramowania lub usługi online (bezpłatnej lub płatnej).
Po przeanalizowaniu witryn konkurencji.
Wybór zapytań wyszukiwania za pomocą usług statystyki zapytań Google, Yandex lub Rambler
Chcę od razu ostrzec, że te usługi nie pokazują bardzo dokładnych informacji o liczbie zapytań w miesiącu.
Przykładowo, jeśli spojrzysz na 4 strony wyników wyszukiwania zapytania „okna plastikowe”, to serwis statystyczny pokaże Ci, że to zapytanie było wyszukiwane nie 1, a 4 razy, ponieważ nie tylko pierwsza strona wyników wyszukiwania jest liczona jako wyświetlenie, ale wszystkie kolejne, co oglądane przez użytkownika. Dlatego w praktyce liczby rzeczywiste będą nieco niższe niż pokazywane przez różne serwisy.
Aby określić dokładną liczbę kliknięć, najlepiej byłoby oczywiście spojrzeć na statystyki ruchu konkurentów, którzy znajdują się w TOP-10 (liveinternet lub mail.ru, jeśli jest otwarty). W ten sposób będzie można zrozumieć, ile ruchu przyniesie żądanie, które Cię interesuje.
Możesz również z grubsza obliczyć, ilu odwiedzających przyniesie Ci dane zapytanie, w zależności od pozycji, jaką zajmie witryna w wynikach wyszukiwania. Oto jak zmieni się CTR (współczynnik klikalności) Twojej witryny na różnych pozycjach w TOP:

Na przykład rozważmy zapytanie „! Odnów! Apartamenty”, region „Moskwa i region”:

W takim przypadku, jeśli Twoja witryna zajmuje 5. pozycję w wynikach wyszukiwania, to żądanie przyniesie około 75 odwiedzających miesięcznie (6%), 4. miejsce (8%) - 100 stron / miesiąc, 3. miejsce (11%) - 135 wsi / miesiąc, 2. miejsce (18%) - 223 wsi / miesiąc. i 1. miejsce (28%) - 350 odwiedzających miesięcznie.
Na CTR można również wpływać za pomocą jasnego fragmentu kodu, zwiększając w ten sposób ruch dla tego żądania. Możesz przeczytać, jak ulepszyć fragment i co to jest.
Statystyki wyszukiwania Google
Wcześniej częściej korzystałem ze statystyk zapytań w wyszukiwarce Google, ponieważ przede wszystkim promowałem się w tej wyszukiwarce. Wtedy wystarczyło zoptymalizować artykuł, kupić jak najwięcej różnych linków PR do niego (bardzo ważne, żeby te linki były naturalne, a linki śledzą odwiedzający) i voila - jesteś w TOP!
Teraz w Google sytuacja jest taka, że \u200b\u200bpromocja w nim nie jest dużo łatwiejsza niż w Yandex. Dlatego dużo więcej uwagi trzeba poświęcić zarówno pisaniu i projektowaniu (!) Artykułów, jak i kupowaniu linków do serwisu.
Chciałbym również zwrócić Państwa uwagę na następujący fakt:
W Rosji najpopularniejszy jest Yandex (Yandex - 57,7%, Google - 30,6%, Mail.ru - 8,9%, Rambler -1,5%, Nigma / Ask.com - 0,4%), więc jeśli promujesz się w tym kraju, jesteś na pierwszym miejscu z kolei warto skupić się na Yandex.
Na Ukrainie sytuacja wygląda inaczej: Google - 70-80%, Yandex - 20-25%. Dlatego ukraińscy webmasterzy powinni skupić się na promocji w Google.
Aby skorzystać ze statystyk wyszukiwania Google, przejdź do
Przyjrzyjmy się przykładowi wyszukiwania słów kluczowych w witrynie kulinarnej.
Przede wszystkim należy wpisać główne zapytanie, na podstawie którego zostaną wybrane opcje słów kluczowych dla przyszłego rdzenia semantycznego serwisu. Wpisałem zapytanie "jak gotować".
Następnym krokiem jest wybór rodzaju dopasowania. Łącznie są trzy typy dopasowań: przybliżone, frazowe i ścisłe. Radzę wybrać dokładnie tę opcję, ponieważ ta opcja pokaże najdokładniejsze informacje na żądanie. A teraz wyjaśnię dlaczego.
Dopasowanie przybliżone oznacza, że \u200b\u200bstatystyki wyświetleń będą pokazywane dla wszystkich słów w tym zapytaniu. Na przykład w zapytaniu „okna plastikowe” zostanie wyświetlone dla wszystkich słów zawierających słowo „plastikowe” i „okna” (plastikowe, okna, kup okna, kup rolety do okien, ceny okien z pcv). Krótko mówiąc, będzie dużo „śmieci”.
Dopasowanie frazowe oznacza, że \u200b\u200bstatystyki słów będą wyświetlane dokładnie w kolejności, w jakiej są wymienione. Wraz z określoną frazą słów w żądaniu mogą znajdować się inne słowa. W zapytaniu „okna plastikowe” zostaną wzięte pod uwagę słowa „niedrogie okna plastikowe”, „okna plastikowe Moskwa”, „ile kosztują okna plastikowe” itp.

Najbardziej interesują nas dane „Liczba zapytań w miesiącu (regiony docelowe)” i „Szacowany CPC” (jeśli zamierzamy umieszczać reklamy Adsense na stronach witryny).
Statystyki zapytań wyszukiwania Yandex
Ze statystyk wyszukiwanych haseł korzystam prawie codziennie, ponieważ są one prezentowane w wygodniejszej formie niż jej odpowiednik w Google.
Jedyną wadą Wordstat jest to, że nie znajdziesz w nim pasujących typów, nie zapiszesz wybranych zapytań na swój komputer, nie będziesz w stanie sprawdzić kosztu za kliknięcie itp.
Aby uzyskać dokładniejsze wyniki, musisz użyć specjalnych operatorów, za pomocą których możesz zawęzić zapytania, które nas interesują. Znajdziesz listę operatorów na tym.
Jeśli wpiszesz w Wordstat zapytanie „jak gotować”, otrzymamy następujące statystyki:

To jest to samo, co w przypadku wybrania „dopasowania przybliżonego” w AdWords.
Jeśli wpiszesz to samo zapytanie, ale w cudzysłowie, uzyskamy dokładniejsze statystyki (analogiczne do dopasowywania fraz w AdWords):

Cóż, aby uzyskać statystyki tylko dla danego żądania, musisz użyć operatora „!”: „! Jak! Gotować”

Aby uzyskać jeszcze dokładniejsze wyniki, musisz określić region, dla którego witryna jest promowana:

Również w górnym panelu Wordstat znajdują się narzędzia, za pomocą których możesz przeglądać statystyki dla danego zapytania według regionu, miesiąca i tygodnia. Nawiasem mówiąc, korzystając z tego ostatniego, bardzo wygodnie jest analizować statystyki sezonowych zapytań.
Przykładowo, analizując zapytanie „jak gotować”, można dowiedzieć się, że jest ono najbardziej popularne w grudniu (nie jest to zaskakujące - wszyscy przygotowują się do Nowego Roku):

Statystyki wyszukiwania Rambler
Chcę od razu ostrzec, że statystyki zapytań z Ramblera z roku na rok coraz bardziej tracą na aktualności (przede wszystkim jest to spowodowane małą popularnością tej wyszukiwarki). Więc prawdopodobnie nie będziesz musiał nawet z tym pracować.


Nie musisz wprowadzać żadnych operatorów w Adstat - od razu wyświetla częstotliwość zapytania w przypadku, w którym zostało wprowadzone. Zawiera również oddzielne statystyki dotyczące częstotliwości żądań dotyczących pierwszej strony wyników wyszukiwania i wszystkich stron wyników wyszukiwania, w tym pierwszej.
Wybór zapytań wyszukiwania za pomocą specjalnego oprogramowania lub usług online
Rookee może nie tylko promować Twoje zapytania, ale może również pomóc w tworzeniu semantycznego rdzenia witryny.
Z pomocą Rookee możesz łatwo wybrać rdzeń semantyczny dla swojej witryny, możesz w przybliżeniu przewidzieć liczbę odwiedzin dla wybranych zapytań i koszt ich awansu na szczyt.
Wybór zapytań za pomocą bezpłatnego programu Slovoeb
Jeśli masz zamiar skomponować SY (rdzeń semantyczny) na bardziej profesjonalnym poziomie lub potrzebujesz statystyk dotyczących zapytań w Google.Adwords, Rambler.Adstat, sieć społecznościowa Vkontakte, różne agregatory linków itp., Radzę natychmiast zakupić Kay Collector.
Jeśli chcesz skomponować duży rdzeń semantyczny, ale jednocześnie nie chcesz wydawać pieniędzy na zakup płatnych programów, najlepszą opcją w tym przypadku byłby program Slovoyob (informacje o programie przeczytaj tutaj). Jest „młodszym bratem” Kay Collector i pozwala zbierać SY na podstawie statystyk zapytań w Yandex.Wordstat.
Instalowanie programu SlovoEB.
Pobierz archiwum wraz z oprogramowaniem.
Upewnij się, że archiwum jest odblokowane. W tym celu we właściwościach pliku (w menu kontekstowym wybierz pozycję „Właściwości”) kliknij przycisk „Odblokuj” / „Odblokuj”, jeśli taki istnieje.
Rozpakuj zawartość archiwum.
Uruchom plik wykonywalny Slovoeb.exe
Tworzymy nowy projekt:

Wybierz żądany region (przycisk Regiony Yandex.Wordstat):

Zapisujemy zmiany.
Kliknij przycisk „Lewa kolumna Yandex.Wordstat”
W razie potrzeby ustaw „Stop words” (słowa, które nie powinny znajdować się w naszym rdzeniu semantycznym). Stop słowami mogą być takie słowa: „za darmo” (jeśli sprzedajesz coś na swojej stronie), „forum”, „wikipedia” (jeśli masz własną stronę informacyjną, na której nie ma forum), „porno”, „seks” (cóż, tutaj wszystko jest jasne) itp.
Teraz musisz ustawić początkową listę słów, na podstawie których zostanie skompilowany CJ. Zróbmy rdzeń dla firmy zajmującej się montażem sufitów napinanych (w Moskwie).
Wybierając dowolny rdzeń semantyczny należy przede wszystkim dokonać klasyfikacji analizowanego tematu.
W naszym przypadku sufity napinane można sklasyfikować według następujących kryteriów (takie wygodne mapy myśli wykonuję w programie MindJet MindManager):

Pomocna rada: wielu webmasterów z jakiegoś powodu zapomina o umieszczeniu nazw małych osad w rdzeniu semantycznym.
W naszym przypadku możliwe byłoby zawarcie w SY nazwy interesujących nas dzielnic Moskwy i miast regionu moskiewskiego. Nawet jeśli miesięcznie jest bardzo mało zapytań o te słowa kluczowe („sufity napinane Golitsyno”, „sufity napinane Aprelevka” itp.), Nadal musisz napisać dla nich co najmniej jeden mały artykuł, którego tytuł będzie zawierał wymagany klucz. Nie będziesz musiał nawet promować takich artykułów, ponieważ częściej niż nie, konkurencja na te prośby będzie bardzo niska.
10-20 takich artykułów, a Twoja strona będzie konsekwentnie otrzymywać kilka dodatkowych zamówień z tych miast.
Naciśnij przycisk "Yandex.Wordstat lewa kolumna" i wprowadź wymagane zapytania:

Kliknij przycisk „Parse”. W rezultacie otrzymujemy następującą listę zgłoszeń:

Odfiltrowujemy wszystkie niepotrzebne prośby, które nie pasują do tematyki serwisu (np. „Zrób to sam” sufity napinane zrób to sam ”- choć taka prośba przyniesie trochę ruchu, nie przyciągnie nas klientów, którzy zlecą montaż sufitów). Wybieramy te żądania i usuwamy je, aby nie tracić czasu na ich analizę w przyszłości.
Teraz musimy wyjaśnić częstotliwość dla każdego z kluczy. Naciśnij przycisk "Zbierz częstotliwości"! "":

Teraz mamy następujące informacje: żądanie, jego ogólna i dokładna częstotliwość.
Teraz, na podstawie uzyskanych częstotliwości, musisz ponownie zbadać wszystkie zapytania i usunąć niepotrzebne.
Niepotrzebne zapytania to zapytania, które mają:
Dokładna częstotliwość („!”) Jest bardzo niska (w wybranym przeze mnie temacie w zasadzie musisz docenić każdego odwiedzającego, więc odfiltruję zapytania z miesięczną częstotliwością mniejszą niż 10). Jeśli nie było tematu budowlanego, ale, powiedzmy, jakiś ogólny temat, możesz bezpiecznie odfiltrować żądania z częstotliwością poniżej 50-100 miesięcznie.
Stosunek częstotliwości ogólnej do dokładnej przekracza bardzo wysokie. Na przykład zapytanie „kup sufity napinane” (1335/5) można natychmiast usunąć, ponieważ jest to „zapytanie fikcyjne”.
Żądania z bardzo dużą konkurencją również muszą zostać usunięte, trudno będzie na nich awansować (zwłaszcza jeśli masz młodą witrynę i mały budżet na promocję). Taką prośbą w naszym przypadku są „sufity napinane”. Ponadto najczęściej te zapytania, które składają się z 3,4 lub więcej słów, są bardziej skuteczne - przyciągają bardziej ukierunkowanych użytkowników.
Oprócz Slovoyob istnieje inny doskonały program do wygodnego automatycznego zbierania, analizy i przetwarzania statystyk wyświetlania słów kluczowych Yandex.Direct.
Wyszukiwania wiadomości
W tym przypadku SJ nie jest tworzony w taki sam sposób, jak w przypadku zwykłego projektu treści. W przypadku witryny z wiadomościami musisz przede wszystkim wybrać nagłówki, pod którymi będą publikowane wiadomości:

Następnie musisz wybrać żądania dla każdej sekcji. Prośby o wiadomości można się spodziewać i nie można ich oczekiwać.
W przypadku pierwszego typu żądań powód informacyjny jest przewidywalny. Najczęściej można nawet wskazać datę, kiedy nastąpi wzrost popularności danego zapytania. Może to być dowolne święto (Nowy Rok, 9 maja, 8 marca, 23 lutego, Święto Niepodległości, Święto Konstytucji, święta kościelne), wydarzenie (imprezy muzyczne, koncerty, premiery filmowe, zawody sportowe, wybory prezydenckie).
Przygotuj takie żądania z wyprzedzeniem i określ przybliżoną wielkość ruchu w tym przypadku za pomocą
Nie zapomnij również spojrzeć na statystyki ruchu na swojej stronie (jeśli przeglądałeś już jakieś wydarzenie w swoim czasie) i witrynach konkurencji (jeśli ich statystyki są otwarte).
Drugi typ zapytań jest mniej przewidywalny. Należą do nich najnowsze wiadomości: kataklizmy, katastrofy, niektóre wydarzenia w rodzinach znanych osób (narodziny / ślub / śmierć), wydanie niezapowiedzianego oprogramowania itp. W takim przypadku wystarczy być jednym z pierwszych, którzy to opublikują Aktualności.
Aby to zrobić, nie wystarczy po prostu monitorować wiadomości w Google i Yandex - w tym przypadku Twoja witryna będzie tylko jedną z tych, którzy po prostu przedrukowali to wydarzenie. Bardziej skuteczną metodą, która pozwala wygrać duży jackpot, jest śledzenie zagranicznych witryn. Publikując tę \u200b\u200bwiadomość jako jedną z pierwszych w Runecie, oprócz mnóstwa ruchu, który spowoduje umieszczenie serwerów na Twoim hostingu, otrzymasz ogromną liczbę linków zwrotnych do Twojej witryny.
Zapytania dotyczące kina można również sklasyfikować jako zapytania oczekiwane. Rzeczywiście, w tym przypadku data premiery filmu jest znana z góry, scenariusz filmu i jego aktorzy są w przybliżeniu znani. Dlatego trzeba wcześniej przygotować stronę, na której pojawi się film, dodać na chwilę jego zwiastun. Na stronie można również publikować wiadomości o filmie, jego aktorach. Ta taktyka pomoże Ci z wyprzedzeniem zająć TOP pozycje w wyszukiwarkach i przyciągnie odwiedzających do serwisu jeszcze przed jego premierą.
Czy chcesz wiedzieć, jakie zapytania są obecnie w trendzie lub przewidzieć trafność tematu w przyszłości? Następnie skorzystaj z usług dostarczających informacji o trendach. Pozwala na wykonywanie wielu operacji analitycznych: porównanie trendów wyszukiwania dla kilku zapytań, analizę regionów geograficznych zapytania, przeglądanie najgorętszych trendów w danym momencie, przeglądanie odpowiednich aktualnych zapytań, eksport wyników do formatu CSV, możliwość subskrybowania kanału RSS dla aktualnych trendów itp. ...
Jak przyspieszyć zbieranie rdzenia semantycznego?
Myślę, że każdy, kto natknął się na zbiór rdzenia semantycznego, pomyślał: „Jak długie i żmudne jest analizowanie, zmęczone sortowaniem i grupowaniem tysięcy żądań!”. To normalne. Czasami też to mam. Zwłaszcza, gdy musisz analizować i iterować CJ, który składa się z kilkudziesięciu tysięcy żądań.
Przed rozpoczęciem analizowania zdecydowanie radzę podzielić wszystkie żądania na grupy. Na przykład, jeśli Twoja witryna to „Budowanie domu”, podziel ją na fundamenty, ściany, okna, drzwi, dachy, okablowanie, ogrzewanie itp. Po prostu znacznie łatwiej będzie ci później sortować i grupować zapytania, gdy będą one zlokalizowane w małą grupę i łączy je pewien wąski temat. Jeśli po prostu przeanalizujesz wszystko w jednym stosie, otrzymasz nierealistycznie dużą listę, której przetworzenie zajmie więcej niż jeden dzień. I tak, przetwarzając całą listę CY w małych krokach, nie tylko sprawniej przepracujesz wszystkie zgłoszenia, ale będziesz mógł jednocześnie zamawiać artykuły od copywriterów do już zebranych kluczy.
Proces zbierania rdzenia semantycznego prawie zawsze rozpoczyna się od automatycznego analizowania żądań (do tego używam Kay Collector). Możliwe jest również odbiór ręczny, ale jeśli pracujemy z dużą liczbą zgłoszeń, nie widzę powodu, aby tracić cenny czas na tę rutynową pracę.
Jeśli pracujesz z innymi programami, najprawdopodobniej będzie w nich dostępna funkcja pracy z serwerami proxy. Pozwala to przyspieszyć proces parsowania i chronić swój adres IP przed blokadą wyszukiwarek. Szczerze mówiąc, nie jest to przyjemne, gdy pilnie potrzebujesz zrealizować zamówienie, a twoje IP jest zbanowane na jeden dzień z powodu częstych połączeń z serwisem statystyk Google / Yandex. Tutaj na ratunek przychodzą płatne serwery proxy.
Osobiście w tej chwili nie używam ich z jednego prostego powodu - są stale zbanowane, nie jest łatwo znaleźć wysokiej jakości działające proxy i nie mam ochoty ponownie za nie płacić. Dlatego znalazłem alternatywny sposób zbierania SN, który kilkakrotnie przyspieszył ten proces.
W przeciwnym razie będziesz musiał poszukać innych witryn do analizy.
W większości przypadków witryny zamykają te statystyki, więc możesz użyć statystyk punktów wejścia.
Dzięki temu będziemy mieć statystyki najczęściej odwiedzanych stron serwisu. Przekazujemy im, wypisujemy główne zapytania, dla których został zoptymalizowany i na ich podstawie pobieramy SY.
Nawiasem mówiąc, jeśli witryna ma otwarte statystyki „Według wyszukiwanych słów”, możesz ułatwić sobie pracę i zbierać żądania za pomocą Key Collector (wystarczy wpisać adres witryny i kliknąć przycisk „Pobierz dane”):

Drugim sposobem analizy witryny konkurencji jest analiza jej witryny.
Niektóre zasoby mają widżet „Najpopularniejsze artykuły” (lub coś podobnego). Czasami najpopularniejsze artykuły są wybierane na podstawie liczby komentarzy, czasami na podstawie liczby wyświetleń.

W każdym razie, mając przed oczami listę najpopularniejszych artykułów, możesz dowiedzieć się, na jakie prośby został napisany ten lub inny artykuł.
Trzecim sposobem jest użycie narzędzi. Ogólnie rzecz biorąc, został stworzony w celu analizy zaufania witryn, ale szczerze mówiąc, uważa, że \u200b\u200bzaufanie jest bardzo złe. Ale to, co potrafi dobrze, to analizować żądania stron internetowych konkurencji.
Wpisz adres dowolnej witryny (nawet z zamkniętymi statystykami!) I kliknij przycisk sprawdzania zaufania. Na samym dole strony wyświetlą się statystyki widoczności serwisu według słów kluczowych:
Widoczność witryny w wyszukiwarkach (według słów kluczowych)

Jedyną wadą jest to, że tych zapytań nie można wyeksportować, musisz wszystko skopiować ręcznie.
Czwartym sposobem jest korzystanie z usług i.

Z jego pomocą można określić wszystkie zapytania, dla których witryna zajmuje pozycje w TOP-100 w obu wyszukiwarkach. Możliwy jest eksport pozycji i zapytań do formatu xls, ale nie mogłem otworzyć tego pliku na żadnym z komputerów.

Ostatnim sposobem na znalezienie słów kluczowych konkurentów jest pomoc
Przeanalizujmy jako przykład zapytanie „dom z bali”. W zakładce „Analiza konkurencji” wprowadź to żądanie (jeśli chcesz przeanalizować konkretną witrynę, wystarczy wpisać jej adres URL w tym polu).
W efekcie otrzymujemy informacje o częstotliwości zapytania, liczbie reklamodawców w każdej z wyszukiwarek (a jeśli są reklamodawcy, to w tej niszy są pieniądze) oraz średnim koszcie kliknięcia w Google i Yandex:

Możesz także przeglądać wszystkie reklamy w Yandex.Direct i Google Adwords:


A tak wygląda TOP każdego PS. Możesz kliknąć dowolną domenę i zobaczyć wszystkie żądania, dla których znajduje się na liście TOP oraz wszystkie jej reklamy kontekstowe:

Istnieje inny sposób analizy zgłoszeń konkurencji, o którym niewiele osób wie - skorzystanie z ukraińskiego serwisu
Nazwałbym to „ukraińską wersją słów kluczowych”, ponieważ mają one bardzo podobną funkcjonalność. Jedyna różnica polega na tym, że baza danych zawiera frazy kluczowe, których szukają ukraińscy użytkownicy. Więc jeśli pracujesz w UA-net, ta usługa będzie dla Ciebie bardzo przydatna!
Analiza zgłoszeń konkursowych
Tak więc wnioski są zbierane. Teraz musisz przeanalizować konkurencję dla każdego z nich, aby zrozumieć, jak trudne będzie promowanie tego lub innego słowa kluczowego.
Osobiście, kiedy tworzę nową stronę, przede wszystkim staram się pisać artykuły na zapytania, dla których jest mało konkurencji. Pozwoli to na krótki czas i przy minimalnych inwestycjach doprowadzić witrynę do całkiem dobrego ruchu. Przynajmniej w takich tematach jak budownictwo, medycyna, w 2,5 miesiąca można dotrzeć do 500-1000 zwiedzających. Generalnie milczę na temat kobiet.
Zobaczmy, jak możesz analizować konkurencję w sposób ręczny i automatyczny.
Ręczny sposób analizy konkurencji
Wprowadź żądane słowo kluczowe w wyszukiwaniu i spójrz na witryny T0P-10 (i jeśli to konieczne, T0P-20), które znajdują się w wynikach wyszukiwania.
Najbardziej podstawowe parametry, którym należy się przyjrzeć, to:
Liczba stron głównych w TOP (jeśli promujesz wewnętrzną stronę serwisu, aw TOPIE konkurenci mają głównie strony główne, to najprawdopodobniej nie będziesz w stanie ich wyprzedzić);
Liczba bezpośrednich napędów słów kluczowych w tytule strony.
W przypadku takich zapytań jak „promocja serwisu”, „jak schudnąć”, „jak zbudować dom”, panuje nierealistycznie duża konkurencja (w TOP jest wiele stron głównych z bezpośrednim wpisaniem słowa kluczowego w tytule), więc nie należy na nich awansować. Ale jeśli przejdziesz do zapytania „jak zbudować dom z bloków piankowych własnymi rękami z piwnicą”, będziesz miał większe szanse, aby dostać się do TOP. Dlatego ponownie skupiam swoją uwagę na fakcie, że należy przejść dalej do zapytań składających się z 3 lub więcej słów.
Ponadto, jeśli przeanalizujesz wyniki w Yandex, możesz zwrócić uwagę na TCI witryn (im wyższy, tym trudniej będzie je wyprzedzić, ponieważ wysoki TCI najczęściej wskazuje na dużą masę linków witryny), czy są w Yandex Catalog (strony z Yandex Catalog mają większe zaufanie), jego wieku (odwieczne strony są bardziej lubiane przez wyszukiwarki).
Jeśli analizujesz TOP strony w Google, zwróć uwagę na te same parametry, o których pisałem powyżej, tylko w tym przypadku zamiast Katalogu Yandex będzie katalog DMOZ, a zamiast wskaźnika TCI pojawi się wskaźnik PR (jeśli na TOP stronach witryn mają PR od 3 do 10, nie będzie łatwo ich wyprzedzić).
Radzę analizować strony za pomocą wtyczki. Pokazuje wszystkie informacje o witrynie konkurencji:

Automatyczny sposób analizy zgłoszeń konkursowych
Jeśli jest dużo żądań, możesz korzystać z programów, które wykonają całą pracę za Ciebie setki razy szybciej. W takim przypadku możesz użyć Slovoeb lub Kay Collector.
Wcześniej przy analizie konkurencji korzystałem z KEI (Competition Index). Ta funkcja jest dostępna w programie Key Collector i Word Word.
W Slovoyob wskaźnik KEI po prostu pokazuje całkowitą liczbę witryn w wynikach wyszukiwania dla określonego zapytania.
Pod tym względem Kay Collector ma tę zaletę, że ma możliwość samodzielnego ustawiania wzoru na obliczanie parametru KEI. Aby to zrobić, przejdź do Ustawienia programu - KEI:

W polu „Wzór na obliczenie KEI 1” należy wpisać:
(KEI_YandexMainPagesCount * KEI_YandexMainPagesCount * KEI_YandexMainPagesCount) + (KEI_YandexTitlesCount * KEI_YandexTitlesCount * KEI_YandexTitlesCount)
W polu „Wzór na obliczenie KEI 2” należy wpisać:
(KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount) + (KEI_GoogleTitlesCount * KEI_GoogleTitlesCount * KEI_GoogleTitlesCount)
Formuła ta uwzględnia liczbę stron głównych w wynikach wyszukiwania dla danego słowa kluczowego oraz liczbę stron w TOP-10, na których to słowo kluczowe znajduje się w tytule strony. W ten sposób możesz uzyskać mniej lub bardziej obiektywne dane dotyczące konkurencji dla każdego żądania.
W tym przypadku im mniejsze żądanie KEI, tym lepiej. Najlepsze słowa kluczowe będą miały KEI \u003d 0 (jeśli oczywiście mają przynajmniej pewien ruch).
Kliknij przyciski zbierania danych dla Yandex i Google:

Następnie kliknij ten przycisk:

Kolumny KEI 1 i KEI 2 będą wyświetlać dane dotyczące zapytań KEI dla Yandex i Google
odpowiednio. Posortujmy zapytania rosnąco według kolumny KEI 1:

Jak widać, wśród wyselekcjonowanych zapytań znajdują się takie, których promocja nie powinna stwarzać szczególnych problemów. W mniej konkurencyjnych tematach, aby takie zapytanie trafiło do TOP-10, wystarczy napisać dobry, zoptymalizowany artykuł. I nie będziesz musiał kupować linków zewnętrznych, aby go promować!
Jak powiedziałem powyżej, używałem wcześniej KEI. Teraz, aby ocenić konkurencję, wystarczy, że podam liczbę stron głównych w TOP i liczbę wystąpień słowa kluczowego w tytule strony. Key Collector ma podobną funkcję:


Następnie sortuję zapytania według kolumny „Liczba stron głównych w wyszukiwarce Yandex” i upewniam się, że dla tego parametru w TOP jest nie więcej niż 2 strony główne i jak najmniej wpisów w tytułach. Po skompilowaniu CJ dla wszystkich tych zapytań zmniejszam parametry filtru. W związku z tym pierwsze artykuły na stronie zostaną opublikowane dla żądań NK, a ostatnie - dla żądań SK i VK.
Po zebraniu i pogrupowaniu wszystkich najciekawszych zapytań (grupowanie omówię poniżej), kliknij przycisk „Eksportuj dane” i zapisz je do pliku. Zwykle w pliku eksportu umieszczam następujące parametry: częstotliwość według Yandex z „!” w danym regionie liczba głównych stron serwisów oraz liczba wystąpień słowa kluczowego w nagłówkach.
Wskazówka: Kay Collector czasami nie całkiem poprawnie pokazuje liczbę wystąpień żądań w nagłówkach. Dlatego wskazane jest dodatkowo wprowadzanie tych zapytań w Yandex i ręczne przeglądanie wyników.
Możesz również ocenić konkurencyjność zapytań, korzystając z bezpłatnego
Grupowanie wniosków
Po wyselekcjonowaniu wszystkich wniosków przychodzi czas na dość nudną i monotonną pracę nad grupowaniem wniosków. Musisz wybrać podobne zapytania, które można połączyć w jedną małą grupę i promować na jednej stronie.
Na przykład, jeśli na otrzymanej liście masz takie prośby: „jak nauczyć się robić pompki w domu”, „jak nauczyć się robić pompki w domu”, „nauczyć się robić pompki dla dziewczynki”. Takie zapytania można połączyć w jedną grupę i napisać dla niej jeden duży zoptymalizowany artykuł.
Aby przyspieszyć proces grupowania, parsuj słowa kluczowe na części (na przykład, jeśli masz witrynę o sprawności, to podczas analizy podziel YA na grupy, które będą zawierać żądania dotyczące szyi, ramion, pleców, klatki piersiowej, brzucha, nóg itp. itp.). To znacznie ułatwi Twoją pracę!
Jeśli otrzymane grupy będą zawierały niewielką liczbę wniosków, możesz na tym poprzestać. A kiedy w końcu nadal otrzymasz listę kilkudziesięciu, a nawet setek żądań, możesz wypróbować następujące metody.
Praca ze słowami stop
W narzędziu Key Collector można określić słowa pomijane, których można użyć do oznaczenia niepożądanych słów kluczowych w wynikowej tabeli zapytań. Takie zapytania są zwykle usuwane z rdzenia semantycznego.
Oprócz usuwania niechcianych zapytań funkcja ta może służyć do wyszukiwania wszystkich niezbędnych form wyrazów dla danego klucza.
Wskazujemy wymagany klucz:

Wszystkie formy słów określonego klucza są wyróżnione w tabeli zapytaniami:

Przenosimy je do nowej karty i już tam pracujemy ręcznie ze wszystkimi żądaniami.
Filtrowanie pod kątem pola „Fraza”
Możesz znaleźć wszystkie formy słów danego słowa kluczowego, korzystając z ustawień filtrowania w polu „Fraza”.
Spróbujmy znaleźć wszystkie zapytania zawierające słowo „bary”:

W efekcie otrzymujemy:

Narzędzie do analizy grup
Jest to najwygodniejsze narzędzie do grupowania fraz i dalszego ich ręcznego filtrowania.
Przejdź do zakładki „Dane” - „Analiza grupy”:

I oto, co jest wyświetlane, jeśli otworzysz którąkolwiek z tych grup:

Zaznaczając dowolną grupę fraz w tym oknie, jednocześnie zaznaczasz lub odznaczasz frazę w tabeli głównej we wszystkich zapytaniach.
W każdym razie nie możesz obejść się bez pracy ręcznej. Ale dzięki Kay Collector część pracy (i to niemała!) Została już wykonana, a to przynajmniej trochę, ale ułatwia proces kompilacji SY witryny.
Po ręcznym przetworzeniu wszystkich żądań powinieneś otrzymać coś takiego:

Jak znaleźć niską konkurencyjną dochodową niszę?
Przede wszystkim musisz sam zdecydować, jak będziesz zarabiać na swojej stronie. Wielu początkujących webmasterów popełnia ten sam głupi błąd - najpierw tworzą strony internetowe na temat, który im się podoba (na przykład po zakupie iPhone'a lub iPada każdy od razu biegnie, by stworzyć kolejną witrynę „związaną z jabłkami”), a potem zaczynają zdawać sobie sprawę, że konkurencja w tej niszy jest bardzo wysoka i ich govnositik będzie prawie niemożliwy do przebicia się na pierwszych miejscach. Albo tworzą witrynę kulinarną, ponieważ lubią gotować, a potem z przerażeniem zdają sobie sprawę, że nie wiedzą, jak zarabiać na takim ruchu.
Przed utworzeniem jakiejkolwiek witryny natychmiast zdecyduj, w jaki sposób będziesz zarabiać na projekcie. Jeśli masz motyw rozrywkowy, najprawdopodobniej odpowiednie są dla Ciebie reklamy zwiastuny. W przypadku nisz handlowych (w których coś jest sprzedawane) reklamy kontekstowe i banerowe są idealne.
Chcę tylko odwieść Cię od tworzenia witryn o tematyce ogólnej. Witryny, które mówią „wszystko o wszystkim”, nie są teraz tak łatwe do promowania, ponieważ TOP od dawna zajmują znane portale zaufania. Bardziej opłacalne będzie stworzenie strony o wąskim temacie, która w krótkim czasie przewyższy wszystkich konkurentów i na długo zdobędzie przyczółek w TOP. Mówię ci to z własnego doświadczenia.
Moja wąskotematyczna witryna medyczna już 4 miesiące po jej utworzeniu zajmuje pierwsze miejsca w Google i Yandex, wyprzedzając największe medyczne portale ogólnotematyczne.
Promuj wąskie witryny ŁATWIEJ I SZYBCIEJ!
Przejdźmy do wyboru niszy komercyjnej dla witryny, w której będziemy zarabiać na reklamie kontekstowej. Na tym etapie musisz spełnić 3 kryteria:

Oceniając konkurencję w jakiejś niszy, korzystam z wyszukiwania regionu moskiewskiego, w którym konkurencja jest zwykle większa. Aby to zrobić, określ w ustawieniach regionu na koncie Yandex „Moskwa”:
Wyjątkiem są przypadki, gdy strona jest stworzona dla konkretnego regionu - wtedy trzeba przyjrzeć się konkurentom dla tego konkretnego regionu.
Główne oznaki niskiej konkurencji w wynikach wyszukiwania są następujące:
Brak pełnych odpowiedzi na zapytanie (kwestia nieistotna).
W TOPIE jest nie więcej niż 2-3 strony główne (nazywane są również „kagańcami”). Duża liczba „twarzy” oznacza, że \u200b\u200bcała witryna jest celowo promowana w związku z tym żądaniem. W takim przypadku znacznie trudniej będzie promować wewnętrzną stronę Twojej witryny.
Niedokładne wyrażenia we fragmencie kodu wskazują, że wymagane informacje po prostu nie są dostępne w witrynach konkurentów lub że ich strony nie są w ogóle zoptymalizowane pod kątem tego żądania.
Niewielka liczba dużych portali tematycznych. Jeśli w przypadku wielu zapytań z przyszłego SN w TOP jest wiele dużych portali i stron o wąskiej tematyce, musisz zrozumieć, że nisza została już utworzona, a konkurencja jest tam bardzo duża.
Ponad 10 000 żądań miesięcznie pod względem częstotliwości podstawowej. To kryterium oznacza, że \u200b\u200bnie należy zbytnio „zawężać” tematu witryny. Nisza powinna mieć wystarczającą ilość ruchu, który można zarobić w kontekście. Dlatego główne zapytanie w wybranym temacie powinno mieć co najmniej 10 000 zapytań miesięcznie dla wordstat (bez cudzysłowów i z uwzględnieniem regionu!). W przeciwnym razie będziesz musiał nieco rozszerzyć temat.
Możesz również z grubsza oszacować ruch w niszy, korzystając ze statystyk ruchu w witrynach, które zajmują pierwsze pozycje w TOP. Jeśli ta statystyka jest dla nich zamknięta, użyj
Większość doświadczonych MFA-Schnicków szuka nisz dla swoich witryn nie w ten sposób, ale korzystając z usługi lub programu Micro Niche Finder.
Ten ostatni, nawiasem mówiąc, pokazuje parametr SOC (0-100 - żądanie osiągnie TOP tylko przy wewnętrznej optymalizacji, 100-2000 - średnia konkurencja). Możesz łatwo wybierać żądania z SOC mniejszym niż 300.
Na poniższym ekranie możesz zobaczyć nie tylko częstotliwość zapytań, ale także średni koszt kliknięcia, pozycję strony według zapytań:

Jest też przydatna sztuczka, np. „Potencjalni nabywcy reklam”:

Możesz też po prostu wpisać zapytanie, które Cię interesuje i przeanalizować je oraz podobne zapytania:

Jak widzisz, cały obraz jest przed Tobą, wystarczy, że sprawdzisz konkurencję dla każdej z próśb i wybierzesz najciekawszą z nich.

Szacowanie kosztów ofert dla witryn YAN
Przyjrzyjmy się teraz, jak przeanalizować koszt ofert w witrynach YAN.
Kontynuujemy wpisując interesujące nas zapytania:

W efekcie otrzymujemy:

Uwaga! Patrzymy na współczynnik gwarantowanych wyświetleń! Rzeczywisty przybliżony koszt kliknięcia będzie 4 razy mniejszy niż ten, który pokazuje usługa.
Okazuje się, że jeśli przeniesiesz na TOP stronę o leczeniu zapalenia zatok i odwiedzający klikną reklamę, wówczas koszt 1 kliknięcia w reklamę YAN wyniesie 12 rubli (1,55 / 4 \u003d 0,39 USD).
Jeśli wybierzesz region „Moskwa i region”, stawki będą jeszcze wyższe.
Dlatego tak ważne jest zajęcie pierwszych miejsc w TOP w tym regionie.
Zwróć uwagę, że podczas analizy wniosków nie musisz brać pod uwagę żądań komercyjnych (np. „Kup stolik”). W przypadku projektów merytorycznych należy analizować i promować prośby o informacje („jak zrobić stół własnymi rękami”, „jak wybrać stół do biura”, „gdzie kupić stół” itp.).
Gdzie szukać niszowych zapytań?
1. Rozpocznij burzę mózgów, zapisz wszystkie swoje zainteresowania.
2. Zapisz, co inspiruje Cię w życiu (może to być jakiś sen, związek, styl życia itp.).
3. Rozejrzyj się i zapisz wszystko, co Cię otacza (zapisz w zeszycie dosłownie wszystko: długopis, żarówkę, tapetę, sofę, fotel, obrazki).
4. Jaki jest Twój zawód? Czy pracujesz w fabryce przy maszynie lub jako laryngolog w szpitalu? Zapisz wszystkie rzeczy, których używasz w pracy, w notatniku.
5. W czym jesteś dobry? To też zapisz.
6. Przejrzyj reklamy w gazetach, magazynach, reklamy na stronach internetowych, spam w poczcie. Być może oferują coś interesującego, o czym mógłbyś zrobić stronę internetową.
Znajdź tam witryny z ruchem 1000-3000 osób dziennie. Przyjrzyj się tematom tych witryn i zapisz najczęstsze żądania, które powodują ich ruch. Może jest tam coś ciekawego.
Przedstawię wybór jednej wąskiej niszy tematycznej.
Tak więc interesowała mnie taka choroba jak „ostroga piętowa”. Jest to bardzo wąska mikronishe, dla której można utworzyć małą witrynę złożoną z 30 stron. Najlepiej byłoby, gdybyś poszukał szerszych nisz, dla których możesz stworzyć witrynę zawierającą 100 lub więcej stron.
Otwórz i sprawdź częstotliwość tego żądania (nie będziemy niczego określać w ustawieniach regionu!):

W porządku! Częstotliwość głównego żądania przekracza 10 000. W tej niszy jest ruch.
Teraz chcę sprawdzić konkurencję pod kątem żądań, dla których witryna będzie promowana („leczenie ostrogi piętowej”, „leczenie ostrogi piętowej”, „leczenie ostrogi piętowej”)
Przełączam się na Yandex, w ustawieniach określam region „Moskwa” i otrzymuję to:

W TOPIE znajduje się wiele wewnętrznych stron ogólnych serwisów tematycznych medycznych, które nie będą dla nas trudne do wyprzedzenia (choć stanie się to nie wcześniej niż za 3-4 miesiące) i znajduje się pysk 1 miejsca, który jest zaostrzony do leczenia ostrogi piętowej.
Witryna wnopa to 10-stronicowy govnosite (który jednak ma PR \u003d 3) z ruchem 500 odwiedzających. Podobną witrynę można również przejąć, jeśli stworzysz lepszą witrynę i wypromujesz stronę główną dla tego żądania.
Po przeanalizowaniu w ten sposób TOP dla każdego z zapytań możemy dojść do wniosku, że ten mikronisz nie jest jeszcze zajęty.
Pozostał ostatni etap - sprawdzanie ofert.
Przejdź do i wprowadź tam nasze zapytania (nie musisz wybierać regionu, ponieważ naszą stronę odwiedzą osoby rosyjskojęzyczne z całego świata)
Teraz znajduję średnią arytmetyczną wszystkich danych gwarantowanych wyświetleń. To daje 0,812 dolara. Dzielimy ten wskaźnik przez 4, okazuje się, że średnio 0,2 USD (6 rubli) za 1 kliknięcie. W przypadku tematów medycznych jest to w zasadzie normalny wskaźnik, ale jeśli chcesz, możesz znaleźć tematy z najlepszymi ofertami.
Czy powinieneś wybrać podobną niszę dla swojej witryny? Decyzja należy do Ciebie. Szukałbym szerszych nisz, które mają większy ruch i lepszy koszt kliknięcia.
Jeśli naprawdę chcesz znaleźć dobry temat, gorąco polecam wykonanie kolejnego kroku!
Zrób płytkę z następującymi kolumnami (podałem dane w przybliżeniu):

Musisz pisać co najmniej 25 żądań dziennie! Poświęć od 2 do 5 dni na szukanie niszy, a ostatecznie będziesz miał w czym wybierać!
Wybór niszy to jeden z najważniejszych kroków w tworzeniu strony internetowej, a jeśli potraktujesz ją niedbale, możesz pomyśleć, że w przyszłości po prostu stracisz czas i pieniądze.
Jak napisać odpowiednio zoptymalizowany artykuł
Kiedy piszę artykuł zoptymalizowany pod kątem dowolnego żądania, pierwszą rzeczą, o której myślę, jest uczynienie go użytecznym i interesującym dla odwiedzających witrynę. Dodatkowo staram się zaprojektować tekst tak, aby był przyjemny w czytaniu. W moim rozumieniu idealnie zaprojektowany tekst powinien zawierać:
1. Jasny, skuteczny nagłówek. Jest to tytuł, który jako pierwszy przyciąga użytkownika, gdy ogląda SERP. Należy pamiętać, że tytuł musi w pełni odpowiadać temu, co jest napisane w tekście!
2. Brak „wody” w tekście. Myślę, że niewielu ludzi lubi, gdy coś, co można napisać w 2 słowach, jest umieszczone na kilku arkuszach tekstu.
3. Uprość akapity i zdania. Aby tekst był bardziej czytelny, podziel duże zdania na krótkie, mieszczące się w jednym wierszu. Uprość złożone zakręty. Nie bez powodu we wszystkich gazetach i czasopismach tekst jest publikowany małymi zdaniami w kolumnach. Dzięki temu czytelnik lepiej odbierze tekst, a jego oczy nie męczą się tak szybko.
Akapity w tekście również powinny być małe. Najlepszy ze wszystkich będzie postrzegany tekst, w którym występuje naprzemienność małych i średnich akapitów. Idealny jest akapit składający się z 4-5 wierszy.
4. Używaj podtytułów w tekście (h2, h3, h4). Osoba potrzebuje 2 sekund, aby „zeskanować” otwartą stronę i zdecydować, czy ją przeczytać, czy nie. W tym czasie skanuje stronę oczami i podkreśla dla siebie najważniejsze elementy, które pomagają mu zrozumieć, o czym jest tekst. Podtytuły są właśnie narzędziem, za pomocą którego możesz przyciągnąć uwagę gościa.
Aby tekst był uporządkowany i czytelny, na każde 2-3 akapity należy stosować jeden podtytuł.
Należy pamiętać, że te tagi muszą być używane w kolejności (h2 do h4). Na przykład:
Nie musisz tego robić:
<И3>Podtytuł<И3>
<И3>Podtytuł<И3>
<И2>Podtytuł<И2>
A oto jak możesz:
<И2>Podtytuł<И2>
<И3>Podtytuł<И3>
<И4>Podtytuł<И4>
Możesz też wykonać następujące czynności:
<И2>Jak pompować prasę<И2>
<И3>Jak zbudować mięśnie brzucha w domu<И3> <И3>Jak pompować prasę na poziomym pasku<И3> <И2>Jak budować bicepsy<И2> <И3>Jak zbudować biceps bez maszyn do ćwiczeń<И3>
W tekstach słowa kluczowe należy stosować do minimum (nie więcej niż 2-3 razy w zależności od wielkości artykułu). Tekst powinien być jak najbardziej naturalny!
Zapomnij o pogrubionych i zapisanych kursywą słowach kluczowych. Jest to wyraźna oznaka nadmiernej optymalizacji, a Yandexowi się to nie podoba. W ten sposób podkreślaj tylko ważne zdania, przemyślenia, pomysły (jednocześnie staraj się nie dostawać w nich słów kluczowych).
5. Używaj we wszystkich swoich tekstach wypunktowanych i numerowanych list, cytatów (nie mylić z cytatami i aforyzmami znanych osób! Piszemy w nich tylko ważne przemyślenia, pomysły, rady), obrazki (z wypełnionymi atrybutami alt, tytuł i podpis). Wstawianie ciekawych filmów tematycznych do artykułów, ma to bardzo dobry wpływ na czas przebywania odwiedzających na stronie.
6. Jeśli artykuł jest bardzo duży, do poruszania się po tekście warto użyć treści i linków do zakotwiczeń.
Po wprowadzeniu wszystkich niezbędnych zmian w tekście przejrzyj go ponownie oczami. Czy to nie jest trudne do odczytania? Może jakieś sugestie trzeba zrobić jeszcze mniej? A może potrzebujesz zmienić czcionkę na bardziej czytelną?
Dopiero gdy jesteś zadowolony ze wszystkich zmian w tekście, możesz wpisać tytuł, opis i słowa kluczowe i wysłać do publikacji.
Wymagania dotyczące tytułu
Tytuł - jest to tytuł we fragmencie, który pojawia się w wynikach wyszukiwania. Tytuł w tytule i tytuł w artykule (ten, który jest wyróżniony tagiem
) muszą się od siebie różnić i jednocześnie muszą zawierać główne słowo kluczowe (lub kilka kluczy).Wymagania dotyczące opisu
Opis powinien być jasny i interesujący. W nim musisz krótko przekazać znaczenie artykułu i nie zapomnij podać niezbędnych słów kluczowych.
Wymagania dotyczące słów kluczowych
Wprowadź tutaj promowane słowa kluczowe oddzielone spacją. Nie więcej niż 10 sztuk.
Jak więc pisać zoptymalizowane artykuły.
Przede wszystkim wybieram zapytania, których będę używał w artykule. Na przykład, wezmę główne pytanie „jak nauczyć się pompować”. Wprowadzamy go do wordstat.yandex.ru

Wordstat wyświetlił 14 zapytań. Większość z nich postaram się wykorzystać w artykule, gdy tylko będzie to możliwe (wystarczy jeden raz wspomnieć o każdym słowie kluczowym). Słowa kluczowe mogą i powinny być odrzucane, przestawiane, zastępowane synonimami, możliwie różnorodne. Wyszukiwarki, które rozumieją język rosyjski (zwłaszcza Yandex), doskonale rozpoznają synonimy i uwzględniają je w rankingu.
Wielkość artykułu staram się określać po średniej wielkości artykułów z TOP.
Na przykład, jeśli w TOP-10 w wynikach wyszukiwania znajduje się 7 witryn, których rozmiar tekstu wynosi głównie 4000-7000 znaków, a 3 witryny, które mają ten wskaźnik, są bardzo niskie (lub wysokie), ostatnich 3 po prostu nie biorę pod uwagę Uwaga.
Oto przybliżona struktura html artykułu, zoptymalizowana pod kątem zapytania „jak nauczyć się pompować”:
……………………………
Jak dziewczyna może nauczyć się robić pompki 100 lub więcej razy w ciągu 2 miesięcy
……………………………
Jakie powinno być prawidłowe odżywianie?
……………………………
Codzienny reżim
……………………………
……………………………
Program treningowy
Niektórzy SEO radzą bezbłędnie napisać główny klucz w pierwszym akapicie. Zasadniczo jest to skuteczna metoda, ale jeśli masz w witrynie 100 artykułów, z których każdy zawiera promowane zapytanie w pierwszym akapicie, może to przynieść odwrotny skutek.
W każdym razie radzę nie rozłączać się z jednym konkretnym schematem, eksperymentować, eksperymentować i eksperymentować ponownie. I pamiętaj, jeśli chcesz stworzyć witrynę, którą pokochają roboty wyszukujące, spraw, aby pokochali ją prawdziwi ludzie!
Jak zwiększyć ruch na stronie za pomocą prostej manipulacji linkami?
Myślę, że każdy z was widział wiele różnych schematów linkowania na stronach i jestem więcej niż pewien, że nie przywiązywał pan do nich zbytniej wagi. Ale na próżno. Rzućmy okiem na pierwszy schemat linkowania, który ma większość witryn. Na nim jednak wciąż brakuje linków ze stron wewnętrznych do strony głównej, ale nie jest to takie ważne. Istotne jest, że w tym przypadku w serwisie najważniejsze będą strony kategorii (które najczęściej nie są promowane i są zamknięte przed indeksowaniem w pliku robots.txt!) Oraz strona główna serwisu. Strony postów w tym przypadku mają najmniejszą wagę:

Pomyślmy teraz logicznie: SEO, którzy promują projekty związane z treścią, najpierw promują które strony? Zgadza się - strony z rekordami (w naszym przypadku są to strony trzeciego poziomu). Dlaczego więc promując serwis za pomocą czynników zewnętrznych (linków), tak często zapominamy o nie mniej ważnych - czynnikach wewnętrznych (poprawne linkowanie)?
Przyjrzyjmy się teraz schematowi, w którym strony wewnętrzne będą miały większą wagę:

Można to osiągnąć po prostu przez odpowiednie dostosowanie przepływu ciężaru ze stron najwyższego poziomu do stron najniższego poziomu trzeciego. Nie zapominaj też, że strony wewnętrzne będą dodatkowo pompowane przez linki zewnętrzne w innych witrynach.
Jak ustawić ten transfer wagi? Bardzo proste - z tagami nofollow noindex.
Rozważmy witrynę, w której musisz pompować strony wewnętrzne:
Na stronie głównej (poziom 1): wszystkie linki wewnętrzne są otwarte do indeksowania, linki zewnętrzne są zamykane przez nofollow noindex, link do mapy witryny jest otwarty.
Na stronach z nagłówkami (poziom 2): linki do stron z postami (poziom 3) i do mapy witryny są otwarte do indeksowania, wszystkie inne linki (do strony głównej, nagłówki, tagi, zewnętrzne) zamykane są za pomocą nofollow noindex.
Na stronach z postami (poziom 3): linki do stron tego samego, 3 poziomu i do mapy serwisu są otwarte, wszystkie inne linki (do strony głównej, nagłówki, tagi, zewnętrzne) zamykane są poprzez nofollow noindex.
Po wykonaniu takiego linkowania największą wagę uzyskała mapa serwisu, która równomiernie rozłożyła ją na wszystkie strony wewnętrzne. Z kolei wewnętrzne strony znacznie się poprawiły. Najmniejszą wagę uzyskała strona główna i rubryka, czyli dokładnie to, co chciałem osiągnąć.
W programie sprawdzę wagę strony. Pomaga wizualnie zobaczyć rozkład ciężaru statycznego na stronie, skupić się na promowanych stronach, a tym samym podnieść Twoją witrynę w wynikach wyszukiwania, znacznie oszczędzając budżet na linki zewnętrzne.
Przejdźmy teraz do części zabawnej - wyników takiego eksperymentu.
Strona dla kobiet. Zmiany w rozkładzie ciężaru na stronie zostały wprowadzone w styczniu br. Podobny eksperyment przyniósł +1000 widzów:

Witryna jest pod filtrem Google, więc ruch wzrósł tylko w Yandex:

Nie zwracaj uwagi na spadek ruchu w maju, to sezonowość (maj
wakacje).
2. Druga strona dla kobiet, w styczniu wprowadzono również zmiany:


Ta strona jest jednak stale aktualizowana i kupowane są do niej linki.
Warunki odniesienia dla copywriterów do pisania artykułów
Tytuł artykułu:jak zielenie mogą być przydatne?
Wyjątkowość: nie mniej niż 95% według Etxt
Rozmiar artykułu: 4000-6000 znaków bez spacji
Słowa kluczowe:
jak przydatne są zielenie - główny klucz
zdrowe warzywa
przydatne właściwości zieleni
zalety zieleni
Wymagania dotyczące artykułu:
Główne słowo kluczowe (wymienione jako pierwsze na liście) nie musi znajdować się w pierwszym akapicie, musi tylko pojawić się w pierwszej połowie tekstu !!!
ZABRONIONE: aby pogrupować słowa kluczowe w części tekstu, konieczne jest rozmieszczenie słów kluczowych w całym tekście.
Słowa kluczowe należy wyróżnić pogrubioną czcionką (jest to konieczne, aby ułatwić sprawdzenie zamówienia)
Słowa kluczowe muszą być wpisywane harmonijnie (dlatego należy używać nie tylko bezpośrednich wystąpień kluczy, ale można je również deklarować, zamieniać miejscami słowa, używać synonimów itp.)
Użyj podtytułów w tekście. Staraj się nie używać bezpośrednich wystąpień słów kluczowych w podtytułach. Postaraj się, aby podtytuły każdego artykułu były jak najbardziej zróżnicowane!
Użyj nie więcej niż 2-3 bezpośrednich wystąpień głównego zapytania w tekście!
Jeśli w artykule musisz użyć słów kluczowych „jak warzywa są przydatne” i „jak warzywa są przydatne dla ludzi”, to pisząc drugie słowo kluczowe, automatycznie użyjesz pierwszego. Oznacza to, że nie ma specjalnej potrzeby pisania klucza 2 razy, jeśli jeden z nich zawiera już wpis dla innego klucza.
Witajcie drodzy czytelnicy bloga. Chciałbym złożyć kolejną wizytę na temat „zbierania liścienia”. Najpierw tak, jak powinno, a potem dużo ćwiczeń, może trochę niezręcznie w moim wykonaniu. Więc teksty. Byłem zmęczony chodzeniem z zawiązanymi oczami w poszukiwaniu szczęścia w rok po założeniu tego bloga. Tak, były „dobre trafienia” (intuicyjne odgadywanie często zadawanych wyszukiwarek) i był jakiś ruch z wyszukiwarek, ale za każdym razem chciałem trafić w cel (przynajmniej to zobaczyć).
Potem chciałem więcej - zautomatyzować proces zbierania zgłoszeń i selekcjonowania „manekinów”. Z tego powodu pojawiły się doświadczenia związane ze współpracą z Keykollektorem (i jego dysharmonijnym młodszym bratem) oraz kolejny artykuł na ten temat. Wszystko było super, a nawet po prostu cudowne, dopóki nie zdałem sobie sprawy, że jest jeden bardzo ważny punkt, który zasadniczo pozostał za kulisami - rozpraszanie próśb o artykuły.
Napisanie osobnego artykułu na osobny wniosek jest uzasadnione albo w bardzo konkurencyjnych, albo bardzo dochodowych tematach. W przypadku witryn informacyjnych jest to kompletny nonsens, dlatego należy łączyć żądania na jednej stronie. W jaki sposób? Intuicyjnie, tj. znowu na ślepo. Ale nie wszystkie zapytania trafiają na tę samą stronę i mają przynajmniej hipotetyczną szansę na dotarcie na szczyt.
Właściwie dzisiaj porozmawiamy o automatycznym klastrowaniu rdzenia semantycznego za pomocą KeyAssort (rozbijanie żądań według stron, a dla nowych witryn również budowanie na ich podstawie struktury, czyli sekcji, kategorii). Cóż, ponownie przejdziemy przez proces zbierania zgłoszeń dla każdego strażaka (także tych z nowymi narzędziami).
Który z etapów zbierania rdzenia semantycznego jest najważniejszy?
Zbieranie zapytań (podstawy rdzenia semantycznego) dla przyszłej lub istniejącej witryny jest samo w sobie dość interesującym procesem (jak każdy, oczywiście) i może być realizowane na kilka sposobów, których wyniki można następnie połączyć w jedną dużą listę (czyszczenie duplikatów, usuwanie manekin przez słowa stop).
Na przykład możesz ręcznie rozpocząć dręczenie Wordstata, a oprócz tego podłączyć Keycollector (lub jego dysonansową bezpłatną wersję). Jednak to wszystko jest świetne, gdy jesteś mniej lub bardziej zaznajomiony z tematem i znasz klucze, na których możesz polegać (zbieranie ich pochodnych i podobnych zapytań z prawej kolumny Wordstat).
W przeciwnym razie (tak, aw każdym razie nie zaszkodzi) można zacząć od narzędzi „zgrubnego szlifowania”. Na przykład, Serpstat (z domu Prodvigator), który pozwala dosłownie „okraść” konkurentów za używane przez nich słowa kluczowe (zobacz). Istnieją inne podobne usługi „okradania konkurentów” (słowa kluczowe, klucze.so), ale ja „utknąłem” w byłym Promotorze.
W końcu jest też darmowy Primer, który pozwala bardzo szybko rozpocząć zbieranie zgłoszeń. Możesz również zamówić prywatny rozładunek z bazy potworów Ahrefs i odzyskać klucze konkurencji. Generalnie warto zastanowić się nad wszystkim, co może przynieść choćby ułamek przydatnych próśb o przyszłą promocję, które później nie będą już tak trudne do uporządkowania i połączenia w jedną dużą (często nawet ogromną listę).
Rozważymy to (ogólnie rzecz biorąc, oczywiście) nieco poniżej, ale na końcu zawsze pojawia się główne pytanie - co zrobic nastepnie... W rzeczywistości nawet samo podejście do tego, co w rezultacie otrzymaliśmy (okradając kilkunastu lub dwóch konkurentów i porysowując dno beczki za pomocą Keykollectora) może być przerażające. Twoja głowa może pęknąć od próby podzielenia wszystkich tych zapytań (słów kluczowych) na oddzielne strony przyszłej lub istniejącej witryny.
Które zapytania sprawdzą się dobrze na jednej stronie, a które nie powinny być nawet łączone? Naprawdę trudne pytanie, które wcześniej rozwiązywałem czysto intuicyjnie, bo analiza kwestii Yandex (lub Google) na temat „co z konkurentami” jest uboga, a opcje automatyzacji nie trafiały na wyciągnięcie ręki. Cóż, na razie. Mimo wszystko takie narzędzie pojawiło się i zostanie omówione dzisiaj w końcowej części artykułu.
To nie jest usługa online, ale oprogramowanie, którego dystrybucja można pobrać na stronie głównej oficjalnej strony (wersja demonstracyjna).

W związku z tym nie ma ograniczeń co do liczby przetwarzanych wniosków - przetwarzaj tyle, ile potrzeba (są jednak niuanse w zbieraniu danych). Wersja płatna kosztuje niecałe dwa tysiące, co za rozwiązywane zadania, można by rzec, za nic (IMHO).
Ale o technicznej stronie KeyAssort porozmawiamy trochę poniżej, ale tutaj chciałbym powiedzieć o sobie zasada, która pozwala rozbić listę słów kluczowych (praktycznie dowolnej długości) w klastry, tj. zestaw słów kluczowych, które z powodzeniem można zastosować na jednej stronie serwisu (zoptymalizuj dla nich tekst, nagłówki i masę linków - zastosuj magię SEO).
Skąd możesz uzyskać informacje? Kto Ci powie, co się „wypali”, a co nie zadziała niezawodnie? Oczywiście najlepszym doradcą będzie sama wyszukiwarka (w naszym przypadku Yandex jako magazyn zapytań komercyjnych). Wystarczy spojrzeć na dużą ilość danych wyjściowych (powiedzmy, przeanalizować TOP 10) dla wszystkich tych zapytań (z zebranej listy przyszłych liścieni) i zrozumieć, co Twoi konkurenci zdołali pomyślnie połączyć na jednej stronie. Jeśli ta tendencja powtarza się kilkakrotnie, to możemy mówić o schemacie i na jego podstawie już można bić klucze w klastry.
KeyAssort umożliwia ustawienie „ważności”, z jaką będą tworzone klastry w ustawieniach (wybierz klucze, których można używać na jednej stronie). Na przykład w przypadku handlu sensowne jest zaostrzenie wymagań selekcyjnych, ponieważ ważne jest, aby uzyskać gwarantowany wynik, choć kosztem nieco wyższych kosztów pisania tekstów dla większej liczby klastrów. W przypadku witryn informacyjnych, przeciwnie, możesz zrobić kilka odpustów, aby uzyskać potencjalnie większy ruch przy mniejszym wysiłku (przy nieco większym ryzyku „niewypalenia się”). Porozmawiajmy jeszcze raz o tym, jak to zrobić.
Ale co, jeśli masz już witrynę z wieloma artykułami, ale chcesz poszerzyć istniejący liścień i zoptymalizować istniejące artykuły dla większej liczby kluczy, aby uzyskać większy ruch przy minimalnym wysiłku (nieznacznie przesuń nacisk na klawisze)? Ten program również daje odpowiedź na to pytanie - możesz tworzyć zapytania, dla których istniejące strony zostały już zoptymalizowane, tworzyć markery, a wokół nich KeyAssort zbierze klaster z dodatkowymi zapytaniami, które są dość skutecznie promowane (na jednej stronie) przez twoich konkurentów w wynikach wyszukiwania. Co ciekawe, okazuje się ...
Jak zebrać pulę zapytań na potrzebny temat?
Każdy rdzeń semantyczny zaczyna się w rzeczywistości od zebrania ogromnej liczby żądań, z których większość zostanie odrzucona. Ale najważniejsze jest to, że na początkowym etapie wpadają w nią same „perełki”, pod którymi będą tworzone i promowane później oddzielne strony Twojej przyszłej lub istniejącej witryny. Na tym etapie chyba najważniejsze jest zebranie jak największej liczby mniej lub bardziej odpowiednich zapytań i niczego nie przegapić, a wtedy łatwo odfiltrować atrapę.
Pytanie jest sprawiedliwe i jakich narzędzi użyć do tego? Jest jedna jednoznaczna i bardzo poprawna odpowiedź - inna. Im większy tym lepszy. Jednak te same techniki zbierania rdzenia semantycznego są prawdopodobnie warte wymienienia i podania ogólnych ocen i zaleceń dotyczących ich stosowania.
- Yandex Wordstat i jej odpowiedniki w innych wyszukiwarkach - początkowo narzędzia te były przeznaczone dla tych, którzy umieszczają reklamy kontekstowe, aby mogli zrozumieć, jak popularne są określone frazy wśród użytkowników wyszukiwarek. Cóż, jasne jest, że Seoshniks również z powodzeniem używają tych narzędzi. Polecam przejrzenie artykułu, a także artykułu wspomnianego na samym początku tej publikacji (przyda się początkującym).

Wśród wad Vodstat są:
- Wymagana jest ogromna ilość pracy ręcznej (automatyzacja jest zdecydowanie wymagana i zostanie omówiona poniżej), zarówno w przypadku wpisywania fraz opartych na kluczach, jak i wycinania zapytań asocjacyjnych z prawej kolumny.
- Ograniczenie liczby zapytań Wordstat (2000 żądań, a nie więcej linii) może stać się problemem, ponieważ dla niektórych fraz (na przykład „praca”) jest to bardzo małe i pomijamy zapytania o niskiej częstotliwości, a czasem nawet średniej częstotliwości, które mogą przynieść dobry ruch i dochód ( wielu za nimi tęskni). Trzeba „mocno nadwyrężać głowę” lub skorzystać z alternatywnych metod (na przykład baz danych słów kluczowych, z których jedną rozważymy poniżej - póki jest za darmo!).
- Kolekcjoner kay (i jego wolny młodszy brat Slovoeb) - kilka lat temu pojawienie się tego programu było tylko "zbawieniem" dla wielu pracowników sieci (i nawet teraz dość trudno sobie wyobrazić pracę na liścieniu bez CC). Tekst piosenki. Kupiłem KK dwa lub trzy lata temu, ale korzystałem z niego najwyżej kilka miesięcy, ponieważ program jest powiązany ze sprzętem (wypychaniem komputera) i zmieniam go kilka razy w roku. Ogólnie rzecz biorąc, mając licencję na QC używam SE - do tego prowadzi lenistwo.

Szczegóły można przeczytać w artykule „”. Oba programy pomogą Ci zebrać zapytania z prawej i lewej kolumny Wordstat, a także sugestie wyszukiwania dla potrzebnych fraz kluczowych. Sugestie wypadają z paska wyszukiwania, gdy zaczynasz wpisywać zapytanie. Użytkownicy często, bez uzupełniania zestawu, po prostu wybierają najbardziej odpowiednią opcję z tej listy. Firma Seoshniks zorientowała się w tym biznesie i używa takich zapytań w optymalizacji, a nawet.
KK i SE pozwalają na natychmiastowe zebranie bardzo dużej puli żądań (chociaż może to zająć dużo czasu lub kupowanie limitów XML, ale o tym poniżej) i łatwo jest usunąć manekiny, na przykład sprawdzając częstotliwość fraz w cudzysłowach (naucz się materiału, jeśli nie rozumiesz niż mowa - linki na początku publikacji) lub przez ustawienie listy słów pomijanych (szczególnie ważne w handlu). Następnie całą pulę zapytań można łatwo wyeksportować do programu Excel w celu dalszej pracy lub załadowania do KeyAssort (klasteryzatora), co zostanie omówione poniżej.
- SerpStat (i inne podobne usługi) - pozwala po wprowadzeniu adresu URL Twojej witryny uzyskać listę konkurencji w Yandex i Google. I dla każdego z tych konkurentów będzie można uzyskać pełną listę słów kluczowych, dla których udało im się przebić i osiągnąć określone wysokości (uzyskać ruch z wyszukiwarek). Tabela przestawna będzie zawierać częstotliwość wyrażenia, miejsce witryny na górze oraz kilka innych przydatnych i niezbyt przydatnych informacji.

Nie tak dawno korzystałem z prawie najdroższego planu taryfowego Serpstat (ale tylko na jeden miesiąc) iw tym czasie udało mi się zaoszczędzić w Excelu prawie gigabajt różnych przydatnych rzeczy. Zebrałem nie tylko klucze konkurentów, ale także po prostu pule zapytań o interesujące mnie frazy kluczowe, a także liścienie z najbardziej udanych stron moich konkurentów, co, jak sądzę, jest również bardzo ważne. Jedna rzecz jest zła - teraz nie mogę znaleźć czasu, aby zająć się przetwarzaniem tych wszystkich bezcennych informacji. Ale jest możliwe, że KeyAssort nadal będzie łagodzić oszołomienie przed potwornym kolosem danych, które muszą zostać przetworzone.
- Bukvarix - bezpłatna baza danych słów kluczowych we własnej powłoce oprogramowania. Wybór słów kluczowych zajmuje ułamek sekundy (ładowanie do Excela w kilka minut). Nie pamiętam, ile jest milionów słów, ale recenzje o niej (w tym moje) są po prostu doskonałe, a co najważniejsze, całe to bogactwo jest bezpłatne! Co prawda zestaw dystrybucyjny programu waży 28 Gig, a po rozpakowaniu baza zajmuje ponad 100 GB na dysku twardym, ale to wszystko są drobiazgi w porównaniu z prostotą i szybkością zbierania puli żądań.

Ale nie tylko szybkość zbierania liścienia to główna zaleta w porównaniu do Wordstat i KeyCollector. Najważniejsze jest to, że nie ma ograniczeń co do 2000 linii dla każdego żądania, co oznacza, że \u200b\u200bżadne niskie częstotliwości i zbyt niskie częstotliwości nam nie umkną. Oczywiście częstotliwość można ponownie wyjaśnić za pomocą tej samej kontroli jakości i za pomocą słów stop w niej możemy odfiltrować, ale główne zadanie Bukvarix jest doskonałe. To prawda, że \u200b\u200bsortowanie według kolumn nie działa dla niego, ale po zapisaniu puli żądań w Excelu będzie można tam sortować według własnego uznania.
Zapewne sam dasz przynajmniej kilka „poważniejszych” narzędzi do zbierania puli zapytań w komentarzach, a ja z powodzeniem je pożyczę ...
Jak wyczyścić zebrane zapytania wyszukiwania z „manekinów” i „śmieci”?
Lista wynikająca z powyższych manipulacji może być dość duża (jeśli nie ogromna). Dlatego przed załadowaniem go do klasteryzatora (będziemy go mieli KeyAssort) warto go lekko wyczyścić... Aby to zrobić, na przykład pulę zapytań można wyładować do keycollectora i usunąć:
- Zapytania o zbyt niskiej częstotliwości (osobiście wybijam częstotliwość w cudzysłowach, ale bez wykrzykników). To, jaki próg wybrać, zależy od Ciebie iw dużej mierze zależy od tematyki, konkurencji i rodzaju zasobu, do którego trafia liścień.
- W przypadku zapytań komercyjnych sensowne jest użycie listy słów pomijanych (takich jak „bezpłatne”, „pobieranie”, „streszczenie”, a także na przykład nazwy miast, lat itp.), Aby z góry usunąć z liścienia to, co jest znane nie będzie kierować docelowych nabywców do witryny (usuwać gratisy szukające informacji, a nie towarów, na przykład mieszkańców innych regionów).
- Czasami warto kierować się stopniem selekcji konkurencji dla danego zapytania w wynikach wyszukiwania. Np. Na życzenie „okien plastikowych” czy „klimatyzatorów” nie da się nawet kołysać łodzią - awaria jest z góry i ze 100% gwarancją.
Powiedz, że jest to zbyt proste słowami, ale trudne w praktyce. Ale nie. Czemu? A ponieważ jedna osoba, którą szanuję (Michaił Shakin) nie szczędziła czasu i nagrała wideo ze szczegółami opis sposobu czyszczenia zapytań wyszukiwania w narzędziu Key Collector:
Dziękuję mu za to, bo zadane pytanie jest dużo łatwiejsze i jaśniejsze do pokazania niż opisania w artykule. Generalnie radzę sobie, bo wierzę w Ciebie ...
Konfiguracja klastra nasienia KeyAssort dla Twojej witryny
Właściwie zaczyna się zabawa. Teraz cała ta ogromna lista kluczy będzie musiała zostać w jakiś sposób podzielona (rozrzucona) na oddzielnych stronach Twojej przyszłej lub istniejącej witryny (którą chcesz znacznie poprawić pod względem ruchu pochodzącego z wyszukiwarek). Nie będę się powtarzał i nie będę mówił o zasadach i złożoności tego procesu, bo w takim razie dlaczego napisałem pierwszą część tego artykułu.
Więc nasza metoda jest dość prosta. Wchodzimy na oficjalną stronę KeyAssort i pobierz wersję demowypróbować program na zębie (różnica między wersją demo a pełną to niemożność wyładowania, czyli wyeksportowania zmontowanego liścienia), a dopiero potem będzie można zapłacić (1900 rubli to za mało, za mało jak na współczesne realia). Jeśli chcesz od razu rozpocząć pracę nad jądrem, co nazywa się „czystą kopią”, to lepiej wybrać pełną wersję z możliwością eksportu.
Sam program KeyAssort nie może zbierać kluczy (w rzeczywistości nie jest to jego prerogatywą), dlatego będą musiały zostać do niego załadowane. Można to zrobić na cztery sposoby - ręcznie (prawdopodobnie warto użyć tej metody, aby dodać kilka kluczy, które zostały już znalezione po głównym zbiorze kluczy), oraz trzy sposoby importowania kluczy:
- w formacie txt - gdy wystarczy zaimportować listę kluczy (każdy w osobnym wierszu pliku txt i).
- a także dwie opcje formatu Excel: z parametrami, których potrzebujesz w przyszłości lub z zebranymi stronami z TOP10 dla każdego klucza. To ostatnie może przyspieszyć proces tworzenia klastrów, ponieważ program KeyAssort nie musi analizować samego wyjścia, aby zebrać te dane. Jednak adresy URL z TOP10 muszą być aktualne i dokładne (taką listę można znaleźć np. W Keycollector).
Tak, to, co mówię, lepiej raz zobaczyć:
W każdym razie najpierw nie zapomnij utworzyć nowego projektu w tym samym menu Plik, a dopiero wtedy funkcja importu stanie się dostępna:

Przyjrzyjmy się ustawieniom programu (na szczęście jest ich bardzo niewiele), ponieważ inny zestaw ustawień może być optymalny dla różnych typów witryn. Otwórz kartę „Usługa” - „Ustawienia programu” i możesz przejść bezpośrednio do zakładki "Grupowanie":

Najważniejszą rzeczą jest być może wybranie potrzebnego typu klastrowania... Program może korzystać z dwóch zasad łączenia żądań w grupy (klastry) - twardą i miękką.
- Twarde - wszystkie zapytania, które należą do jednej grupy (nadającej się do promocji na jednej stronie) muszą być połączone na jednej stronie dla wymaganej liczby zawodników z Top (liczba ta jest ustawiona w linii „siła grupowania”).
- Miękki - wszystkie żądania zawarte w tej samej grupie będą częściowo napotykane na tej samej stronie dla wymaganej liczby zawodników i Top (ta liczba jest również ustawiona w linii „siła grupowania”).
Jest dobry obraz, który jasno to wszystko ilustruje:

Jeśli nie jest to jasne, to nieważne, bo to tylko wyjaśnienie zasady, a dla nas ważna jest nie teoria, ale praktyka, która mówi, że:
- Twarde klastrowanie najlepiej sprawdza się w witrynach komercyjnych... Metoda ta zapewnia dużą dokładność, dzięki czemu prawdopodobieństwo wejścia na górę zapytań połączonych na jednej stronie serwisu będzie większe (przy odpowiednim podejściu do optymalizacji tekstu i jego promocji), chociaż w klastrze będzie mniej zapytań, co oznacza, że \u200b\u200bsamych klastrów będzie więcej (trzeba będzie stworzyć więcej stron i promować).
- W przypadku witryn informacyjnych warto stosować grupowanie miękkie, bo artykuły będą uzyskiwane z wysokim wskaźnikiem kompletności (będą w stanie udzielić odpowiedzi na szereg podobnych zapytań użytkowników), co również jest brane pod uwagę w rankingu. A same strony będą mniejsze.
Moim zdaniem kolejnym ważnym ustawieniem jest haczyk w polu „Użyj wyrażeń znacznikowych”... Dlaczego możesz tego potrzebować? Zobaczmy.
Załóżmy, że masz już witrynę internetową, ale jej strony zostały zoptymalizowane nie pod kątem puli żądań, ale tylko jednego, lub uważasz, że ta pula nie jest wystarczająco duża. Jednocześnie z całego serca chcesz rozszerzyć jądro zarodkowe nie tylko o dodawanie nowych stron, ale także ulepszanie istniejących (jest to jeszcze łatwiejsze w implementacji). Oznacza to, że dla każdej takiej strony konieczne jest „zapełnienie” seeda.
Do tego służy to ustawienie. Po aktywacji możesz zaznaczyć pole obok każdej frazy na liście żądań. Musisz tylko znaleźć te podstawowe zapytania, dla których już zoptymalizowałeś istniejące strony swojej witryny (po jednej na stronę), a program KeyAssort zbuduje wokół nich klastry. Właściwie to wszystko. Więcej „dymu” w tym filmie:
Kolejne ważne (dla poprawnego działania programu) ustawienie żyje w zakładce „Zbieranie danych z Yandex XML”... możesz przeczytać w podanym artykule. Krótko mówiąc, Seoshniki nieustannie drapie Yandex i Wordstat, powodując nadmierne obciążenie jego pojemności. W celu ochrony wprowadzono captcha, a także opracowano specjalny dostęp do XML, w którym captcha nie będzie już pojawiać się i nie będzie zniekształcenia danych na sprawdzanych kluczach. To prawda, że \u200b\u200bliczba takich kontroli dziennie będzie ściśle ograniczona.
Od czego zależy liczba przydzielonych limitów? Jak Yandex oceni Twój. możesz skorzystać z tego linku (będąc w tej samej przeglądarce, w której jesteś zalogowany do Ya.Webmaster). Na przykład dla mnie wygląda to tak:

Poniżej znajduje się również wykres poniżej rozkładu limitów według pory dnia, co również jest ważne. Jeśli potrzebujesz wielu żądań, ale jest kilka ograniczeń, nie stanowi to problemu. Można je kupić... Oczywiście nie od Yandex bezpośrednio, ale od tych, którzy mają te ograniczenia, ale ich nie potrzebują.
Mechanizm Yandex XML umożliwia przenoszenie limitów, a giełdy, które są pośrednikami, pomagają to wszystko zautomatyzować. Na przykład on XMLProxy możesz kupić limity za jedyne 5 rubli za 1000 żądań, co, jak widzisz, wcale nie jest drogie.
Ale to nie ma znaczenia, ponieważ kupione limity nadal będą wpływać na Twoje „konto”, ale aby użyć ich w KeyAssort, musisz przejść do sekcji „ Konfigurowanie"i skopiuj długi link do pola" URL dla żądań "(nie zapomnij kliknąć" Twój aktualny adres IP "i kliknij przycisk" Zapisz ", aby powiązać klucz z komputerem):

Następnie wystarczy wstawić ten adres URL do okna ustawień KeyAssort w polu „URL dla zapytań”:

Właściwie wszystko odbywa się za pomocą ustawień KeyAssort - możesz rozpocząć klastrowanie rdzenia semantycznego.
Klastrowanie fraz kluczowych w KeyAssort
Mam więc nadzieję, że wszystko skonfigurowałeś (wybrałeś żądany typ klastrowania, podłączyłeś własne lub zakupione limity z Yandex XML), zorientowałeś się w metodach importowania listy z żądaniami i pomyślnie przeniosłeś całość do KeyAssort. Co dalej? A potem na pewno najciekawsze jest rozpoczęcie zbierania danych (adresów URL witryn z Top10 dla każdego żądania), a następnie grupowanie całej listy w oparciu o te dane i wprowadzone ustawienia.
Więc najpierw kliknij przycisk „Zbieraj dane” i poczekaj od kilku minut do kilku godzin, aż program przejdzie przez Tops na wszystkie żądania z listy (im więcej, tym dłużej to zajmie):

Trzysta próśb zajęło mi około minuty (to mały rdzeń dla serii artykułów o pracy w Internecie). Wtedy już możesz przejdź bezpośrednio do grupowaniaprzycisk o tej samej nazwie staje się dostępny na pasku narzędzi KeyAssort. Ten proces jest bardzo szybki iw zaledwie kilka sekund otrzymałem cały zestaw kalsterów (grup), ułożonych w postaci zagnieżdżonych list:

Więcej o korzystaniu z interfejsu programu, a także o tworzenie klastrów dla już istniejących stron internetowych wyglądają lepiej na wideo, ponieważ jest to znacznie wyraźniejsze:
Mamy wszystko, czego chcieliśmy, i pamiętaj - w pełni automatycznie. Szept.
Chociaż, jeśli tworzysz nową witrynę, to oprócz tworzenia klastrów jest to bardzo ważne zarys przyszłej struktury witryny (zdefiniuj sekcje / kategorie i rozprowadź klastry dla przyszłych stron). Co dziwne, ale jest to całkiem wygodne w KeyAssort, ale prawda nie jest już w trybie automatycznym, ale w trybie ręcznym. W jaki sposób?
Jeszcze raz będzie to łatwiejsze do zobaczenia - wszystko jest rozłożone dosłownie na naszych oczach, po prostu przeciągając klastry z lewego okna programu do prawego:
Jeśli kupiłeś program, możesz wyeksportować wynikowy rdzeń semantyczny (a właściwie strukturę przyszłej witryny) do Excela. Ponadto na pierwszej karcie możesz pracować z zapytaniami jako pojedynczą listą, a na drugiej zapisana zostanie struktura skonfigurowana w KeyAssort. Bardzo, bardzo wygodne.
Cóż, to wszystko. Jestem gotowy do omówienia i wysłuchania Twojej opinii na temat odbioru liścienia na stronę.
Powodzenia! Do zobaczenia wkrótce na stronach blogu
Możesz być zainteresowany
Vpodskazke - nowa usługa w Tip do promowania wskazówek w wyszukiwarkach SE Ranking to najlepsza usługa monitorowania pozycji dla początkujących i profesjonalistów SEO Zbieranie pełnego rdzenia semantycznego w Topvisor, różne sposoby wybierania słów kluczowych i grupowania ich według stron Praktyka zbierania semantycznego rdzenia dla SEO od profesjonalisty - tak jak to bywa w obecnych realiach 2018 roku Optymalizacja czynników behawioralnych bez ich oszukiwania SEO PowerSuite - programy do wewnętrznej (WebSite Auditor, Rank Tracker) i zewnętrznej (SEO SpyGlass, LinkAssistant) optymalizacji stron internetowych Wybór słów kluczowych w Yandex Wordstat - analiza statystyk ręcznie i za pomocą programów Slovoeb lub Key Collector  Serpstat - przegląd monitorowania pozycji, grupowania i analizy tekstu
Serpstat - przegląd monitorowania pozycji, grupowania i analizy tekstu


