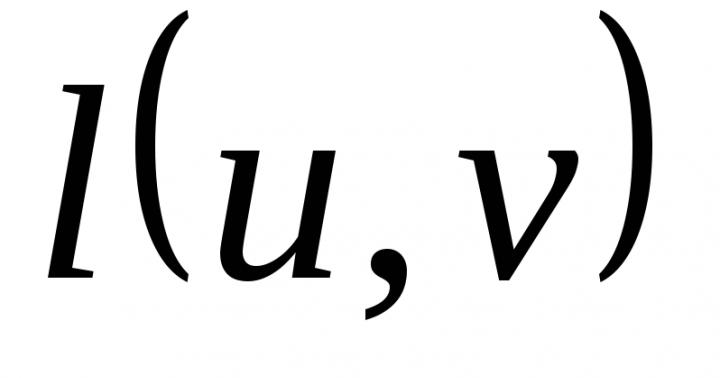04.04.2006 Leonid Chernyak. Rubryki: Technologia
"Open Systems" Tworzenie komputerów byłoby niemożliwe, jeśli jednocześnie z ich wyglądem zostaną stworzone teorii kodowania teorii kodowania? - Jeden z tych obszarów matematycznych, które znacząco wpłynęły na rozwój komputera.
"Open Systems"
Tworzenie komputerów byłoby niemożliwe, jeśli jednocześnie z ich wyglądem zostaną stworzone teorii kodowania sygnału
Teoria kodowania jest jednym z tych obszarów matematyki, która znacząco wpłynęła na rozwój komputera. Jego obszar działania ma zastosowanie do transmisji danych na temat rzeczywistego (lub niesamowitego) kanałów, a obiektem jest zapewnienie poprawności przesyłanych informacji. Innymi słowy, badania, jak lepiej spakować dane, tak aby po przekazywaniu sygnału z danych było możliwe bezpiecznie i po prostu przydzielić przydatne informacje. Czasami teoria kodowania jest mylona z szyfrowaniem, ale jest niepoprawna: kryptografia rozwiązuje odwrotne zadanie, jego celem jest utrudnianie uzyskania informacji z danych.
Potrzeba kodowania danych została po raz pierwszy napotkana ponad półtorej lata, wkrótce po tym wynalazku telegrafu. Kanały były drogami i niewiarygodnymi, które pilne zadanie minimalizacji kosztów i poprawy wiarygodności telegramów. Problem był jeszcze bardziej pogorszył z powodu uszczelki kabli transatlantyckich. Od 1845 r. Weszły do \u200b\u200bużytku specjalne książki kodowe; Z ich pomocą telegraphiści ręcznie wykonali "kompresję" wiadomości, zastępując wspólne sekwencje słów krótszych kodów. Jednocześnie, aby sprawdzić poprawność transferu zaczął używać kontroli parzystości, metoda, która została wykorzystana do weryfikacji poprawności wydajności Rolki Perfoch również w komputerach pierwszej i drugiej generacji. Aby to zrobić, w wprowadzonym talii tej ostatniej, zainwestowano specjalnie przygotowana karta z kontrolą. Jeśli urządzenie wejściowe nie było zbyt niezawodne (lub pokład jest zbyt duży), może wystąpić błąd. Aby go naprawić, procedura wejściowa została powtórzona do obliczenia sprawdź sumę nie pokrywał się z kwotą zapisaną na mapie. Nie tylko ten schemat jest niewygodny, również brakuje również podwójnych błędów. Wraz z rozwojem kanałów komunikacyjnych wymagany był bardziej wydajny mechanizm sterowania.
Pierwszym rozwiązaniem teoretycznym do problemu transmisji danych nad kanałami ryczącego było oferowane Claude Shannon, założyciel statystycznej teorii informacji. Shannon był gwiazdą swojego czasu, wszedł do elity akademickiej Stanów Zjednoczonych. Będąc absolwentem Vannevara Bush, w 1940 r. Otrzymał nagrodę Nobla (nie należy mylić z Nagrodą Nobla!), Nagrodzony naukowcem w wieku poniżej 30 lat. Praca w Bell Labs, Shannon napisał pracę "Teoria Matematyczna Message Transfer Teoria" (1948), która wykazała, że \u200b\u200bjeśli przepustowość kanału powyżej entropii źródła wiadomości, komunikat można zakodować, aby był to transmitowany bez nadmiernych opóźnień. Wniosek ten jest zawarty w jednej z twierdzeń udowodnionych przez Shannona, jego znaczenie jest zredukowane do tego, że jeśli jest kanał z wystarczającą przepustowość, wiadomość może być przesyłana z pewnymi opóźnieniami. Ponadto pokazał teoretyczną możliwość wiarygodnej transmisji w obecności hałasu w kanale. Formuła C \u003d W Log ((P + N) / N), wyrzeźbiony na skromnym pomniku Shannon zainstalowany w swoim miasto W Michigan porównują wartość z formułą Albert Einstein E \u003d MC 2.
Prace Shannon dał żywność dla wielu dalszych badań w dziedzinie teorii informacyjnej, ale nie miały praktycznego zastosowania inżynieryjnego. Przejście z teorii do praktyki było możliwe dzięki wysiłkom Hamming Richarda, kolegów Shannona w Bell Labs, którzy zdobyli sławę do otwarcia kodów klasowych, które zaczęły dzwonić "Kody Hamming". Istnieje legenda, że \u200b\u200bwynalazek jego kodów hamowania pchnął niedogodności w pracy z champartami na przekaźniku rachunkowość Bell Model V w połowie 40s. W weekendy dany czas, kiedy nie było operatorów, a on sam musiał się bawić wraz z wprowadzeniem. Chcesz być tak, jak może zatrudniać zasugerowane kody, które mogą skorygować błędy w kanałach komunikacyjnych, w tym w autostrady transferu danych w komputerach, głównie między procesorem a pamięcią. Kody Hamming stały się dowodem na praktycznie realizację możliwości, dla których wskazują teoremy Shannon.
Hamming opublikował swój artykuł w 1950 r., Chociaż w sprawozdaniach wewnętrznych teorii kodowania sięga do 1947 roku. Dlatego niektórzy uważają, że ojciec teorii kodowania należy rozważyć wbijanie, a nie Shannon. Jednak w historii technologii jest bezużyteczny, aby poszukać pierwszego.
Jest wiarygodnie tylko że Hamming jest pierwszym ofertą "Kod poprawiający błąd, ECC). Nowoczesne modyfikacje tych kodów są wykorzystywane we wszystkich systemach przechowywania i wymiany między procesorem a baran. Jedną z ich opcji, kody Reed-Salomon są używane w płytach CD, umożliwiając odtwarzanie rekordów bez skrzypania i hałasu, które mogą spowodować zadrapania i kurz. Istnieje wiele wersji kodów zbudowanych "opartych na Hammingu, różnią się one algorytmami kodowania i liczbą bitów weryfikacyjnych. Ze szczególnego znaczenia, takie kody zostały nabyte w związku z opracowaniem długotrwałych obligacji przestrzeni z stacjami międzyplanetarnymi, na przykład, istnieją kody Red Muller, gdzie 32 elementy sterujące na siedem bitów informacyjnych lub sześć do 26.
Wśród najnowszych kodów ECC należy nazwać kody LDPC (kod kontrolny parytetu o niskiej gęstości). W rzeczywistości wiadomo o trzydzieści latach, ale znaleźli w nich szczególne zainteresowanie ostatnie lataKiedy telewizyjna zaczęła się rozwijać wysoka rozdzielczość. Kody LDPC nie mają dokładności 100%, ale prawdopodobieństwo błędu można doprowadzić do pożądanego, a jednocześnie z maksymalną przepustowością zużytą kanałową. Są blisko "Turbokodes" (kod turbo), są one skuteczne podczas pracy z obiektami znajdującymi się w warunkach odległej przestrzeni i ograniczonej pasmo Kanał.
Nazwa teorii kodowania jest mocno wpisana przez nazwę Vladimir Aleksandrovich Kotelnikov. W 1933 r. W "Materiały radiokomunikujące dla Kongresu I Wszystkiego-Union na temat komunikacji z rekonstrukcją techniczną", czy opublikował pracę "o przepustowości? Eter? I? Przewody? ". Nazwa Kotelnikov jest na prawach równych w nazwie jednej z najważniejszych twierdzeń teorii kodowania. Ten twierdzenie określa warunki, w których przenoszony sygnał można przywrócić bez utraty informacji.
Ten twierdzenie nazywa się inaczej, w tym "twierdzenie WKS" (skrót WKS pobrany z Whittaker, Kotelnikova, Shannon). Niektóre źródła korzystają również do twierdzenia próbkowania Nyquist-Shannon i Whittaker-Shannon Twierdzenie próbek, aw podręcznikach uniwersyteckich domowych najczęściej występują po prostu "twierdzenie Kotelnikowa". W rzeczywistości teore ma dłuższą historię. Jej pierwsza w 1897 roku okazała się Francuski Emil Matematyk Emil. W 1915 roku Edmund Whitteketer wprowadził swój wkład. W 1920 r. Japońskie Kinnosuki Ogura opublikowało poprawki do badań Wittekera, aw 1928 r. Amerykanin Harry Nyquist wyjaśnił zasady digitalizacji i przywrócić sygnał analogowy.

Claude Shannon. (1916 - 2001) z lat szkolnych wykazały równy interes matematyki i inżynierii elektrycznej. W 1932 r. Wszedł na University of Michigan, w 1936 r. - Do Massachusetts Institute of Technology, która ukończyła w 1940 r., Po otrzymaniu dwóch stopni inżynierii magistra i lekarzy w dziedzinie matematyki. W 1941 roku Shannon poszedł do pracy w Bell Laboratories. Tutaj zaczął rozwijać pomysły, które następnie doprowadziły do \u200b\u200bteorii informacji. W 1948 r. Shannon opublikował artykuł "Matematyczna Teoria Komunikacji", gdzie podstawowe idee naukowca zostały sformułowane w szczególności określenie liczby informacji poprzez entropię, a także zaproponowało jednostkę informacji, która określa wybór dwóch równoważnych Opcje, czyli, co zostało następnie nazywane bitem. W latach 1957-1961 Shannon opublikował pracę, w której udowodniono twierdzenie przepustowości Kanałów Ryczających Kanały Komunikacji, które teraz przenosi swoją nazwę. W 1957 r. Shannon został profesorem w Massachusetts Institute of Technology, skąd wycofał się po 21 latach. W "Honorowany odpoczynek" Shannon całkowicie oddał się jego długotrwałym żonglerkiem. Zbudował kilka maszyn żonglowych, a nawet stworzony teoria ogólna żonglerka.

Richard Hamming. (1915 - 1998) rozpoczął edukację na Uniwersytecie w Chicago, gdzie w 1937 r. Otrzymał tytuł licencjata. W 1939 r. Otrzymał tytuł magistra na Uniwersytecie w Nebraskim, a stopień doktora w matematyce jest na University of Illinois. W 1945 r. Hamming zaczął pracować w ramach projektu Manhattan - działanie badań na dużą skalę nad stworzeniem bomby atomowej. W 1946 r. Hamming udał się do pracy w laboratoriach telefonicznych dzwonkowych, gdzie pracował z Claude Shannon. W 1976 r. Hamming otrzymał Departament w Studiach Podyplomowych Monterey w Kalifornii.
Praca, która uczyniła to sławnym, podstawowym badaniem kodeksów wykrywania i korekcji błędów, Hamming opublikował w 1950 roku. W 1956 r. Uczestniczył w pracy na jednym z wczesnych mineframek IBM 650. Jego prace położyły fundamentę języka programowania, które później ewoluowały w językach programowania wysokiego szczebla. W uznaniu zasługiwania zatruwania w dziedzinie informatyki, Instytut IEEE założył medal do wybitnych usług w rozwoju informatyki i teorii systemów o nazwie Neam Name.

Vladimir Kotelnikov. (1908 - 2005) W 1926 r. Wszedł na Wydział Elektrotechniczny Moskwy Wyższej Szkoły Technicznej o nazwie N. E. Bauman (MWU), ale stał się absolwentem Moskiewskiego Instytutu Energii (MEI), który stwierdził z MWU jako niezależnej instytucji. Podczas szkolenia w szkole absolwentowej (1931-1933), kotelnikow matematycznie zdefiniowany i udowodnił "licząc twierdzenie", który został następnie nazwany go. Po ukończeniu szkoły Graduate w 1933 r. Kotelnikov, pozostałe nauczane w Mei, poszedł do pracy w Centralnym Instytucie Badań Komunikacji (TSF). W 1941 r. V. A. Kotelnikov sformułował wyraźną pozycję na temat tego, jakie wymagania powinny spełniać matematycznie nie przesunięty system i otrzymuje dowód niemożności jego odszyfrowania. W 1944 r. Kotelnikow przyjął stanowisko profesora, dziekan Wydziału Radotechnicznego Mei, gdzie pracował do 1980 roku. W 1953 r. W wieku 45 lat Kotelnikow został natychmiast wybrany przez rzeczywisty członka Akademii ZSRR. W latach 1968-1990 V. A. Kotelnikov był także profesorem, szefem Wydziału Moskwy Fizyki i Technologii.
Narodziny teorii kodowania
Kodowanie. Podstawowe koncepcje.
Różne metody kodowania są szeroko stosowane w ludzkich działań praktycznych od niepamiętnych czasów. Na przykład system pozycjonowania dziesiętnego jest metodą kodowania numerów naturalnych. Innym sposobem zakodowania liczb naturalnych - liczb rzymskich, a ta metoda jest bardziej wizualna i naturalna, rzeczywiście palec - I, pięć - V, dwie pm - X. Jednakże, podczas gdy metoda kodowania jest trudniejsza do wykonywania operacji arytmetycznych Liczby, więc został przemieszczony w sposób kodujący na podstawie pozycyjnego systemu dziesiętnego. Z tego przykładu możesz to stwierdzić różne metody Kodowanie ma wrodzone konkretne cechy, które w zależności od celów kodowania może być zarówno zaletą danej metody kodowania, jak i niekorzystnej sytuacji.
Powszechne metody kodowania numerycznego przedmiotów geometrycznych i ich pozycji w przestrzeni: współrzędne kartezjańskie i współrzędne polarne. A te metody kodowania charakteryzują się szczególnymi osobnymi cechami.
Do XX wieku metody i sposoby kodowania odegrały rolę wspierającą, ale wraz z pojawieniem się komputerów sytuacja zmieniła się radykalnie. Kodowanie znajduje najszerszy użytek technologie informacyjne I często jest centralne pytanie Podczas rozwiązywania różnych zadań, takich jak:
- reprezentacja danych arbitralnego charakteru (liczby, tekst, grafika) w pamięci komputera;
- Optymalna transmisja danych na kanałach komunikacyjnych;
- Ochrona informacji (wiadomości) z nieautoryzowanego dostępu;
- zapewnienie immunitetu hałasu podczas przesyłania danych do kanałów komunikacyjnych;
- Kompresja informacji.
Z punktu widzenia teorii informacyjnej kodowanie jest procesem jednoznacznego porównania alfabetu źródła źródła komunikatu i pewnego zestawu symboli warunkowych przeprowadzonych przez określoną regułę, a kod (alfabet kodu) jest kompletny Ustaw (zestaw) różnych konwencjonalnych symboli (symboli kodu), które mogą być używane do kodowania wiadomości źródeł i które są możliwe, gdy ta reguła kodowanie. Liczba różnych symboli kodów składników alfabetu kodu nazywana jest kodem lub objętością alfabetu kodu. Oczywiście głośność alfabetu kodu może nie być mniejsza niż objętość alfabetu zakodowanego komunikatu źródłowego. W ten sposób kodowanie jest konwersja komunikatu źródłowego do zestawu lub sekwencji symboli kodu wyświetlających komunikat przesyłany przez kanał komunikacyjny.
Kodowanie może być numeryczne (cyfrowe) i numeryczne, w zależności od widoku, w którym prezentowane są znaki kodu: odpowiednio liczby w dowolnym systemie numeru lub innych obiektów lub znaków.
W większości przypadków symbole kodu są kombinacją lub sekwencją niektórych prostych elementów, na przykład sekwencji liczb w symbolach kodu kodu numerycznego, nazywane elementami symbolu kodu. Lokalizacja lub numer sekwencji elementu w słowa kodowym jest określona przez jego pozycję.
Liczba elementów symboli kodu używanych do reprezentowania jednego symbolu alfabetu źródła źródła jest nazywana wartością kodu. Jeśli wartość kodu jest taka sama dla wszystkich symboli alfabetu źródłowego, kod nazywa się jednolity, w przeciwnym razie nierówny. Liczba elementów zawartych w symbolu kodu jest czasami nazywana długością symbolu kodu.
Z punktu widzenia redundancji wszystkie kody można podzielić na nie puste kody i zbędne. W nadmiernych kategoriach liczba symboli kodów może być zmniejszona ze względu na bardziej efektywne wykorzystanie pozostałych elementów, w nieopolnych kategoriach, zmniejszenie liczby elementów w symbolach kodu jest niemożliwe.
Zadania kodowania w przypadku braku zakłóceń i ich obecności są znacznie różne. Dlatego wyróżnia się kodowanie efektywne (statystyczne) kodujące (odporne na hałasowanie (odporne na hałas). Dzięki skutecznym kodowaniu zadaniem jest osiągnięcie symboli symboli symboli alfabetu źródła wiadomości przez minimalną liczbę elementów symboli kodu średnio dla jednego symbolu alfabetu źródła wiadomości spowodowane zmniejszeniem redundancji kodu, co prowadzi do wzrostu w tempie przesyłania wiadomości. Z kodowaniem korygowania (odporne na hałas), zadaniem zmniejszenia prawdopodobieństwa błędów w transmisji symboli alfabetu oryginalnego jest wykonywane przez wykrywanie i korygowanie błędów, wprowadzając dodatkową redundancję kodu.
Oddzielnym zadaniem kodowania jest ochrona wiadomości przed nieautoryzowanym dostępem, zniekształceniami i zniszczeniem. W tym widoku kodowania kodowanie wiadomości przeprowadza się w taki sposób, aby nawet je zdobyć, atakujący nie mógł ich odrzucić. Proces takiego rodzaju kodowania wiadomości nazywa się szyfrowanie (lub Szyfrowanie), a proces dekodowania jest dekodowany (lub dekodowanie). Sama zakodowana wiadomość nazywana jest szyfrowana (lub po prostu zaszyfrowana), a zastosowaną metodę kodowania jest szyfr.
Dość często oddzielna klasa jest przydzielana dla metod kodowania, które umożliwiają budowanie (bez utraty informacji) kody przesyłania wiadomości o mniejszej długości w porównaniu z początkową wiadomością. Takie metody kodowania są nazywane kompresją lub metodami pakowania danych. Jakość kompresji określa się przez współczynnik ściskający, który jest zwykle mierzony jako procent, a który pokazuje, ile procent zakodowany komunikat jest krótszy niż źródło.
Dzięki automatycznym przetwarzaniu informacji za pomocą komputera zwykle korzysta z kodowania numerycznego (cyfrowego), podczas gdy naturalnie kwestia uzasadnienia dla używanego systemu numerów występuje. Rzeczywiście, ze zmniejszeniem podstawy systemu numeru, alfabet elementów symboli kodu jest uproszczony, ale symbole kodu są wydłużone. Z drugiej strony, tym większa podstawa systemu numerów, mniejsza liczba wyładowań jest wymagana do reprezentowania jednego symbolu kodu, a zatem i mniej czasu na przeniesienie, ale ze wzrostem podstawy systemu numerów, Wymagania dotyczące kanałów komunikacyjnych i Środki techniczne Uznanie sygnałów podstawowych odpowiadających różnym elementom znaków kodu. W szczególności kod numeru nagranego w systemie numeru binarnego wynosi średnio o około 3,5 razy dłuższy niż kod dziesiętny. Ponieważ wszystkie systemy przetwarzania informacji muszą przechowywać duże tabliczki informacyjne w postaci informacji numerycznych, jednym ze znaczących kryteriów wyboru alfabetu znaków kodu numerycznego (tj. Podstawą używanego systemu numeru) jest zminimalizowanie liczby elementów elektronicznych W urządzeniach pamięci masowej, a także łatwe i niezawodność.
Przy określaniu liczby elementów elektronicznych wymaganych do mocowania każdego z elementów symboli kodu, konieczne jest przejście z niemal uzasadnionego założenia, że \u200b\u200bwymaga to liczby prostych elementów elektronicznych (na przykład tranzystorów), równych podstawy System numerów. zA.. Następnie do przechowywania w niektórych urządzeniu n.elementy symboli kodu M.elementy elektroniczne:
M \u003d a · n. (2.1)
Największą liczbą różnych liczb, które można nagrać w tym urządzeniu N.:
N \u003d a n.
Programowanie tego wyrażenia i wyrażanie z tego n. Dostajemy:
n.\u003d Ln. N. / Ln. za.
Konwertowanie wyrażenia (2.1) na myśl
M.= a ∙.ln. N. / Ln. zA.(2.2)
można określić z fundamentem logarytmów zA.ilość elementów M.będzie minimalny z danym N.. Różnicowanie przez PO. zA.funkcjonować M \u003d f (a)i równa się jej pochodną do zera, otrzymujemy:
Oczywiście, dla każdego skończonego zA.
ln. N. / Ln2. a ≠ 0.
i dlatego,
ln. a -1 = 0,
z a \u003d e ≈ 2.7.
Ponieważ podstawa systemu numeru może być tylko liczbą całkowitą alewybierz na przykład równy 2 lub 3. zdefiniować maksymalny pojemnik na urządzenie pamięci masowej N.\u003d 10 6 numerów. Następnie, z różnymi zasadami systemów numerów ( ale) Ilość elementów ( M.) W takim urządzeniu pamięci masowej, zgodnie z wyrażeniem (2.2), następującą (tabela 2.1):
Tabela 2.1.
| ale | ||||||
| M. | 39,2 | 38,2 | 39,2 | 42,9 | 91,2 |
Dlatego, jeśli przejdziesz od minimalizacji liczby urządzeń, binarnej, tkaniny i czwartej, która jest blisko tego parametru, są najbardziej korzystne dla najbardziej opłacalnych. Ale ponieważ techniczna realizacja urządzeń działających w systemie numeru binarnego jest znacznie prostsza, kody oparte na systemie bazowym 2 otrzymały największy rozkład w kodowaniu numerycznym.
Ogólnie rzecz biorąc, kodowanie - dowolna konwersja wiadomości do sygnału, ustanawiając wzajemną zgodność między nimi. W wąskim sensie kodowanie - Konwertuj dyskretny komunikat do sekwencji symboli kodu zgodnie z określoną regułą. Wiele wszystkich sekwencji kodu ( kod kombinacje lub słowa), dla tej reguły kodowania formularze kod. Zasada kodowania może być wyrażona przez tabelę kodu z alfabetem zakodowanych wiadomości i odpowiednich kombinacji kodu. Połączenie znaków, z których sekwencje kodowe są nazywane kod alfabetu.i ich liczba (rozmiar alfabetu kodu) - kod podstawowy.
Kodowanie zasad  elementy wiadomości - rejestrowe reguły
elementy wiadomości - rejestrowe reguły  różne liczby B.
różne liczby B.  - Oficjalny system numerów. Rozróżniać dwójkowy
(
- Oficjalny system numerów. Rozróżniać dwójkowy
( ) JA. wieloosobowy
(
) JA. wieloosobowy
( - Przyjaciel.
- Przyjaciel.  )kody..
Długość słowa kodu
)kody..
Długość słowa kodu
 - liczba wyładowań w nim .
Wysyłać wiadomości do kod binarny Wystarczy mieć tylko dwa różne sygnały. Więc symbole
- liczba wyładowań w nim .
Wysyłać wiadomości do kod binarny Wystarczy mieć tylko dwa różne sygnały. Więc symbole  i
i  możesz przenieść różne oscylacje częstotliwości lub bieżące impulsy o różnej polaryzacji. Haamming odległości
możesz przenieść różne oscylacje częstotliwości lub bieżące impulsy o różnej polaryzacji. Haamming odległości
 między dwoma kodami
między dwoma kodami  i
i  znajdź w dwóch etapach. Złożył żądane słowa
znajdź w dwóch etapach. Złożył żądane słowa  - oficjalny system bez przeniesienia do najstarszej kategorii ( dodanie modułu podstawowego kodu
- oficjalny system bez przeniesienia do najstarszej kategorii ( dodanie modułu podstawowego kodu
 oznaczony symbolem.
oznaczony symbolem.  ). Uzyskane wartości są składane
). Uzyskane wartości są składane  - System oficera:
- System oficera:
 ,
(1.1)
,
(1.1)
gdzie  i
i  - to samo imię (
- to samo imię (  s) Zrzuć słowa kodowe
s) Zrzuć słowa kodowe  i
i  odpowiednio. Więc,
odpowiednio. Więc,  ,
, ,
, i
i  dla
dla  . W przypadku odległości kodu binarnego
. W przypadku odległości kodu binarnego  równy liczbie zrzutów, w których słowa
równy liczbie zrzutów, w których słowa  i
i  różne. Odległość kodu.
różne. Odległość kodu.
 - najmniejsza wartość dla tego kodu
- najmniejsza wartość dla tego kodu  . W równoodległy Kod odległości między dwoma dowolnymi słowami jest taki sam. Liczba niezerowych elementów słowa kodowego jest równa jego waga
. W równoodległy Kod odległości między dwoma dowolnymi słowami jest taki sam. Liczba niezerowych elementów słowa kodowego jest równa jego waga
 .
.
1.2. Klasyfikacja metod kodowania
Na rys. 1.1 Dana Klasyfikacja metod kodowania  . Jednym z jego zadań jest koordynowanie alfabetu komunikacji z alfabetem kanału. Każdy zespół wiadomości można zakodować na różne sposoby. Najlepszy kod. Spełnia wymagania:
. Jednym z jego zadań jest koordynowanie alfabetu komunikacji z alfabetem kanału. Każdy zespół wiadomości można zakodować na różne sposoby. Najlepszy kod. Spełnia wymagania:
1) Odbiornik może przywrócić wiadomość źródłową wysłaną linią;
2) Aby reprezentować jedną wiadomość, potrzebny jest środek minimalnej liczby znaków.
Pierwszy wymóg spełniony odwracalny kody. W nich wszystkie słowa kodu są różne i jednoznacznie związane z odpowiednimi wiadomościami. Gospodarczykody spełniają drugi wymóg.

Figa. 1.1. Klasyfikacja metod kodowania
Cel, powód efektywny(statystyczny) kodowanie jest zwiększenie szybkości transferu informacji i przybliżenie tej prędkości do maksymalnego możliwego - pasmokanał komunikacyjny. Koordynacja wydajność źródławiadomości S. przepustowość kanału - Jedno z najważniejszych zadań kodujących.
Kody są podstawowy(prosty lub prymitywny) JA. odporny na hałas. Proste kody składają się ze wszystkich słów kodowych, możliwe dzięki tej metodzie kodowania. Transformacja jednego symbolu słowa w innym ze względu na działanie zakłóceń podaje nowe słowo kodowe. Wystąpił błąd, którego nie można wykryć. W kategoriach odpornych na hałas ma zastosowanie tylko część całkowitej liczby ewentualnych słów kodowych. Zastosowane słowa zwane dozwolony, reszta - zakazany. Kodowanie odporne na hałas umożliwia zwiększenie lojalności wiadomości.
Rozróżniać urządzenia kodujące (codkers.) dla Źródło informacje i za kanałkomunikacja. Zadanie pierwszego jest ekonomiczne (w sensie minimum średniej liczby znaków) reprezentujących wiadomości, a drugim zadaniem jest zapewnienie niezawodnej transmisji wiadomości.
Rozszyfrowaniema przywrócić wiadomość na symbolach odebranych kodu. Urządzenie dekodujące ( dekoder.) Formy razem z enkoderem kodek. Zwykle kodek jest urządzeniem logicznym.
Prymitywny
(bezbroikony) Kodowanie służy do dopasowania alfabetu źródła za pomocą alfabetu kanału. Następnie Źródła nadmiarowości(Zob. Pkt 2.1) Utworzono
wyjście i wejście enkodera są takie same. Kodowanie jest również używane do szyfrowania przesyłanych informacji i zwiększenie stabilności systemu synchronizacji. W tym drugim przypadku zasada kodowania jest wybrana tak, że prawdopodobieństwo pojawienia się na wyjściu z długim kodera sekwencji, składa się tylko z  lub po prostu na zewnątrz
lub po prostu na zewnątrz  był minimalny. Taki koder jest nazywany scrambler. (Z angielskiego słowa Scramble - mix).
był minimalny. Taki koder jest nazywany scrambler. (Z angielskiego słowa Scramble - mix).
Przywracanie przesyłanej wiadomości w odbiorniku jest zawsze przybliżony. Część informacji potrzebnych do zapewnienia wymaganej dokładności odzyskiwania znaczny.
Kompresja
(kompresja)
wiadomości(dane) - pełne lub częściowe usuwanie z niego (je) nadmiar Informacja. Rozwiązanie tego zadania jest osiągane gospodarczy kodowanie. Kompresja danych daje oszczędzając urządzenia pamięci masowej i przepustowości kanałowej. Dzięki ekonomicznemu kodowaniu redundancja źródła utworzona przez wyjście enkodera jest mniejsza niż w wejściu enkodera. Kodowanie ekonomiczne jest używane w komputerze. Systemy operacyjne zawierają ich skład programu kompresji danych ( dynamiczne sprężarki i archiws.). Więc standard  na modemydo komunikacji między komputerem sieci telefoniczne. Ogólne zastosowanie obejmuje kompresję procedur przetwarzania danych (patrz załącznik).
na modemydo komunikacji między komputerem sieci telefoniczne. Ogólne zastosowanie obejmuje kompresję procedur przetwarzania danych (patrz załącznik).
Odporny na hałas (nadmierny) Kodowanie służy do wykrywania i poprawiania błędów, które występują podczas wysyłania wiadomości przez kanał. Następnie redundancja źródła utworzonego przez uwalnianie enkodera, większej redundancji źródła na wejściu enkodera. Kodowanie jest dystrybuowane w różnych systemach komunikacji, podczas przechowywania i przesyłania danych w sieciach komputerowych, w cyfrowej inżynierii audio i wideo.
Liczba wyładowań w różnych kodewkach kodowych może być taka sama lub inna. Odpowiednio, rozróżniać munduri nierówny kody. Zastosowanie jednolitych kodów upraszcza konstrukcję automatycznych urządzeń napisowych i nie wymaga transmisji znaków rozdzielających między słowami kodowymi. Liczba wyładowań  w dowolnym kodzie z kodem jednolitego - kodu bit.. W przypadku jednolitego kodu liczba możliwych kombinacji
w dowolnym kodzie z kodem jednolitego - kodu bit.. W przypadku jednolitego kodu liczba możliwych kombinacji  .
.
Przykład 1.2.1.Prymitywny jednolity kod używany w telegrafów jest kodem Bodo  elementy binarne w każdym słowie (
elementy binarne w każdym słowie ( 
 ). Pełna liczba słów
). Pełna liczba słów  . To wystarczy do kodowania
. To wystarczy do kodowania  litery rosyjskiego alfabetu, ale nie wystarczą do przesyłania wiadomości zawierającej litery, cyfry i różne konwencjonalne znaki (punkt, przecinek, dodawanie, mnożenie itp.). Następnie możesz zastosować kod domeny nr 2 (MTK-2) z zasadą rejestru. W tym taki sam
litery rosyjskiego alfabetu, ale nie wystarczą do przesyłania wiadomości zawierającej litery, cyfry i różne konwencjonalne znaki (punkt, przecinek, dodawanie, mnożenie itp.). Następnie możesz zastosować kod domeny nr 2 (MTK-2) z zasadą rejestru. W tym taki sam  słowo kodu elementu może być używane do trzech razy w zależności od pozycji rejestru: rosyjskiej, łacińskiej i cyfrowej. Całkowita liczba różnych znaków jest równa
słowo kodu elementu może być używane do trzech razy w zależności od pozycji rejestru: rosyjskiej, łacińskiej i cyfrowej. Całkowita liczba różnych znaków jest równa  to wystarczy do kodowania telegramów. Zaleca się przesyłanie danych
to wystarczy do kodowania telegramów. Zaleca się przesyłanie danych  kod elementarny MTK-5
kod elementarny MTK-5  .
.
W nierównomierne kodysłowa kodowe różnią się nie tylko układami znaków, ale także ich numer. Kody te wymagają specjalnych znaków dzielących wskazujących na koniec jednego i początku innego słowa kodowego lub są zbudowane tak, że nie ma słowa kodu na początku innego. Prefiks (nieskracalny) Kody spełniają najnowszy stan. Należy pamiętać, że jednolity kod jest nieredukowalny.
Struktura kodu jest wygodna do obecności w formularzu liczyć(codewood.), w którym z każdego węzeł Liczba oddziałów jest równa podstawy kodu (dla kodu binarnego, na przykład, stopnia  , krok w dół -
, krok w dół -  ).
).
Przykład 1.2.2.Kod Morse'a - typowy przykład nierównomiernego kodu binarnego  . W IT Symbole.
. W IT Symbole.  i
i  stosować tylko w dwóch kombinacjach - jako pojedynczy (
stosować tylko w dwóch kombinacjach - jako pojedynczy (  i
i  ) lub jak potrójne (
) lub jak potrójne (  i
i  ). Sygnał, odpowiedni
). Sygnał, odpowiedni  , zwany punktem i
, zwany punktem i  - Dash. Symbol
- Dash. Symbol  jest używany jako znak oddzielający punkt od kaszy, punkt z punktu i kreska z kreska. Całkowity
jest używany jako znak oddzielający punkt od kaszy, punkt z punktu i kreska z kreska. Całkowity  jest używany jako znak separacji słów kodowych.
jest używany jako znak separacji słów kodowych.
Prosty algorytm do uzyskania nierównomiernych kodów prefiksu był oferowany Shannon i Fano. Shannon Fano algorytm Dla kodu binarnego - następny. Symbole alfabetu źródłowego są napisane w kolejności bez zwiększenia prawdopodobieństwa ich wyglądu. Wtedy znaki są podzielone na  części, tak aby suma prawdopodobieństw znaków w każdej z tych części była w przybliżeniu taka sama. Wszystkie symbole.
części, tak aby suma prawdopodobieństw znaków w każdej z tych części była w przybliżeniu taka sama. Wszystkie symbole.  och (
och (  och, atrybut części
och, atrybut części  (
( ) tak jak
) tak jak  wow symbol słowa słowa. Wszystko na zewnątrz
wow symbol słowa słowa. Wszystko na zewnątrz  x części (jeśli jest więcej
x części (jeśli jest więcej  symbol) zostanie podzielony na dwa, jeśli to możliwe, nierównie części. Stosują tę samą zasadę kodowania. Proces jest powtarzany, aż pozostanie w każdej otrzymanej części
symbol) zostanie podzielony na dwa, jeśli to możliwe, nierównie części. Stosują tę samą zasadę kodowania. Proces jest powtarzany, aż pozostanie w każdej otrzymanej części  symbol Mu. Podział ze strony przykładów równych prawdopodobieństw nie zawsze jest jednoznaczna procedura. Błędy kodujące mogą być zmniejszone, a kod, aby wykonać bardziej wydajne, obracając się z kodowania według wynalazku do kodowania sekwencji znaków wiadomości przez powiększanie alfabetu (Patrz klauzula 4.2).
symbol Mu. Podział ze strony przykładów równych prawdopodobieństw nie zawsze jest jednoznaczna procedura. Błędy kodujące mogą być zmniejszone, a kod, aby wykonać bardziej wydajne, obracając się z kodowania według wynalazku do kodowania sekwencji znaków wiadomości przez powiększanie alfabetu (Patrz klauzula 4.2).
Przykład 1.2.3.Niech Alfabet.  Źródło składa się z znaków
Źródło składa się z znaków  ,
, . Prawdopodobieństwo wyglądu symboli na wyjściu źródła odpowiednio są równe
. Prawdopodobieństwo wyglądu symboli na wyjściu źródła odpowiednio są równe  ,
, ,
, ,
, ,
, i
i  . Procedura Kanona Fano do konstruowania nierównego kodu bez konsolidacji alfabetu źródłowego podano w tabeli. 1.1.
. Procedura Kanona Fano do konstruowania nierównego kodu bez konsolidacji alfabetu źródłowego podano w tabeli. 1.1.  .
.
Tabela 1.1. Kodowanie źródłowe Shannon Fano
|
|
|
Wybór nierównych znaków |
|
|||
|
| ||||||









Na  om etap wielu symboli DELIM
om etap wielu symboli DELIM  części:
części:  i
i  ; na
; na  om -
om -  i
i  ; na
; na  jeść -
jeść -  i
i  ; na
; na  om -
om -  i
i  ,
, i
i  . Bardziej prawdopodobne symbole źródła przypisują mniejsze słowa kodu długości
. Bardziej prawdopodobne symbole źródła przypisują mniejsze słowa kodu długości  . Zbuduj kod prefiksu. Średnia długość słowa kodu (średnia liczba znaków kodu na symbol źródła)
. Zbuduj kod prefiksu. Średnia długość słowa kodu (średnia liczba znaków kodu na symbol źródła)  .
.
Kody odporne na hałas są bloking i ciągły. Gdy kodowanie blokowania sekwencja symbolu źródła jest podzielona na segmenty. Każdy segment odpowiada określonej sekwencji (bloku) symboli kodu - kodowanie kodowe. Wiele słów kodów, dla tej metody kodowania tworzy kod blokowy. W mundur (nierówny) Kod długości bloków - stała (zmienna). Kody odporne na hałas są zwykle jednolite.
Kody blokowe są tam przesuwny i nierozerwalny. W kodzie podziału  długość
długość  symbole można podzielić na spotkanie
symbole można podzielić na spotkanie  informacja(Przewoźnik informacje o wiadomości) i
informacja(Przewoźnik informacje o wiadomości) i  czek. Prędkość kodu
czek. Prędkość kodu  . Całkowita liczba słów w kodzie jest równa
. Całkowita liczba słów w kodzie jest równa  , ale
, ale  - liczba dozwolonych słów. W nierozłącznych kodach nie można przydzielić symboli informacji i weryfikacji. Na przykład są to kody stała wagai kody oparte na macierzach Adamar(Patrz klauzula 6.3). W kodzie binarnym ze stałymi słowami kodów wagowych zawierają ten sam numer
- liczba dozwolonych słów. W nierozłącznych kodach nie można przydzielić symboli informacji i weryfikacji. Na przykład są to kody stała wagai kody oparte na macierzach Adamar(Patrz klauzula 6.3). W kodzie binarnym ze stałymi słowami kodów wagowych zawierają ten sam numer  . W standardowym kodem Telegrafa nr 3, którykolwiek z nich zawiera trzy
. W standardowym kodem Telegrafa nr 3, którykolwiek z nich zawiera trzy  i cztery
i cztery 
 .
.
Kody przesuwne są liniowy i nieliniowy. W kody liniowych.  (patrz (1.1))
(patrz (1.1))  x Wszystkie słowa kodowe tworzą słowo kodu tego samego kodu. Kod liniowy jest nazywany systematycznyJeśli pierwszy
x Wszystkie słowa kodowe tworzą słowo kodu tego samego kodu. Kod liniowy jest nazywany systematycznyJeśli pierwszy  znaki dowolnego ze swoich słów kodowych są informacyjne, a reszta
znaki dowolnego ze swoich słów kodowych są informacyjne, a reszta  - Weryfikacja. Podklasa kodów liniowych - kody cykliczne.(Patrz punkt 6.5). Mają wszystkie zestawy utworzone przez cykliczną permutację znaków w dowolnym słowa kodowym, są kodami tego samego kodu. Ta właściwość upraszcza konstrukcję kodeka, zwłaszcza podczas wykrywania i korygowania pojedynczych błędów. Przykłady cyklicznych kodów - kodów hamowania, kodów bowza-chowururi-hoccwingham (kody BCH) i inne. Przykład nieliniowy Kod binarny - Kod Berger (Patrz pkt 1.4) .
W nim symbole weryfikacyjne są formowane przez wpis binarny numer
- Weryfikacja. Podklasa kodów liniowych - kody cykliczne.(Patrz punkt 6.5). Mają wszystkie zestawy utworzone przez cykliczną permutację znaków w dowolnym słowa kodowym, są kodami tego samego kodu. Ta właściwość upraszcza konstrukcję kodeka, zwłaszcza podczas wykrywania i korygowania pojedynczych błędów. Przykłady cyklicznych kodów - kodów hamowania, kodów bowza-chowururi-hoccwingham (kody BCH) i inne. Przykład nieliniowy Kod binarny - Kod Berger (Patrz pkt 1.4) .
W nim symbole weryfikacyjne są formowane przez wpis binarny numer  w sekwencji symboli informacji.
w sekwencji symboli informacji.
Ciągłe kodowanie i dekodowanie dokonują ciągłej sekwencji symboli bez podziału go do bloków. Wśród ciągłych najczęściej używanych kody konwluntowe(Patrz pkt 6.8).
Odróżnij kanały komunikacyjne niezależny i grupowanie błędów. Odpowiednio, odporne na hałasy kody można podzielić na  klasa: Ustalanie niezależnych błędów i poprawianie pakiety Błędy. Aby poprawić ten ostatni, istnieje wiele skutecznych kodów. W praktyce bardziej widoczne jest stosowanie kodów, które poprawiają niezależne błędy wraz z urządzenie do przeplatania symboli(błędy dekarelacji.). Następnie symbole słowa nie są przesyłane sekwencyjnie i zmieszane z symbolami innych słów kodowych. Jeśli interwał między symbolami każdego słowa kodu zarabia bardziej amanti kanał, błędy w jednym słowie stanie się niezależne. Pozwala to zastosować kody, które poprawiają niezależne błędy.
klasa: Ustalanie niezależnych błędów i poprawianie pakiety Błędy. Aby poprawić ten ostatni, istnieje wiele skutecznych kodów. W praktyce bardziej widoczne jest stosowanie kodów, które poprawiają niezależne błędy wraz z urządzenie do przeplatania symboli(błędy dekarelacji.). Następnie symbole słowa nie są przesyłane sekwencyjnie i zmieszane z symbolami innych słów kodowych. Jeśli interwał między symbolami każdego słowa kodu zarabia bardziej amanti kanał, błędy w jednym słowie stanie się niezależne. Pozwala to zastosować kody, które poprawiają niezależne błędy.
Dodatek ilustruje zasady kodu budowlanego i kompresji danych na przykładzie sieci komputerowych.
Teoria kodowania jest zbadanie właściwości kodów i ich przydatności do osiągnięcia celu. Kodowanie informacji jest procesem jego konwersji z formularza, wygodnego do bezpośredniego stosowania, w formie, wygodne do transmisji, przechowywania, automatycznego przetwarzania i oszczędzania przed nieautoryzowanym dostępem. Główne problemy teorii kodowania obejmują kwestie wzajemnej wyjątkowości kodowania i złożoności kanału komunikacji w określonych warunkach. W związku z tym teoria kodowania korzystnie rozważa następujące obszary: kompresja danych, bezpośrednia korekcja błędów, kryptografia, kodowanie fizyczne, wykrywanie błędów i korekta.
Format
Kurs składa się z 10 tygodni szkolnych. W przypadku udanego rozwiązania większości zadań z testów wystarczy opanować materiał opowiedziany na wykładach. Seminaria zdemontowują bardziej złożone zadania, które będą mogły zainteresować słuchacza już zaznajomiony z podstawami.
Program kursu
- Kodowanie alfabetyczne. Wystarczające warunki Dekodowanie jednoznaczne: jednorodność, prefiks, przyrostek. Uznanie jednoznacznej: kryterium Markova. Oszacowanie długości niejednoznacznych słów.
- Nierówność rzemiosła-macminlane; Istnienie kodu prefiksu o danym zestawie słów; Dochodzenie uniwersalności kodów prefiksu.
- Kody z minimalną redundancją: Ustawianie problemu, twierdzenie Huffmana o redukcji.
- Zadanie poprawiania i wykrywania błędów. Interpretacja geometryczna. Typy błędów. Chemowanie i metryki Levenshtein. Odległość kodu. Główne zadania teorii kodów korygujących błędów.
- Kody Warsamov-Tennagol, algorytmy do mocowania pojedynczych błędów straty i wkładek symboli.
- Najprostsze granice dla kodów, poprawianie błędów zastępczych: granice opakowań sferycznych, Singleton, Polytkin.
- Inwestycja spacji metrycznych. Lemat na temat liczby wektorów w przestrzeni euklidesowej. Granica eliays-basalygo.
- Kody liniowe. Definicje. Matryce generujące i weryfikacyjne. Komunikacja z odległością kodu z macierzą weryfikacyjną. Granica Warshamova-Gilberta. Systematyczne kodowanie. Dekodowanie w zespole. Kody hemmingowe.
- Rezydualny kod. Granica Graisseter-Salomon-Stinifera.
- Złożoność zadania dekodowania kodów linii: zadanie NCP (zadania dotyczące najbliższego słowa kodowego).
- Kody Reed-Salomon. Algorytm dekodowania jest Blekhempa-Valch.
- Kody reed-muller: odległość kodu, algorytm dekodowania większości.
- Opcje dla uogólnienia projektu Mullera Reda. Lipton-Demillo Schwartz-Zippel Lemat. Koncepcja kodów algebrometrycznych.
- Expanders wykresów. Probabilistyczny dowód istnienia ekspandera. Kody oparte na wykresach DiCapid. Kody odległości kodu oparte na rozszerzeniu. Algorytm do dekodowania Sipsera-Spielman.
- Twierdzenia Shannon dla modelu kanału probabilistycznego.
- Zastosowania kodów, które poprawiają błędy. Randomizowany protokół w złożoności komunikacyjnej. Cryptosham Mcalis. Jednolite (pseudo-losowe) zestawy na podstawie kodów, ich zastosowań do przyczyn w zadaniu MAX-SAT.
- Jest to część teorii informacji, które badają metody identyfikacji wiadomości z sygnałami odblaskowymi. Zadaniem teorii kodowania jest koordynowanie źródła informacji z kanałem komunikacji.
Obiekt kodujący obsługuje zarówno informacje dyskretne, jak i ciągłe, które wchodzi do konsumenta poprzez źródło informacji. Koncepcja kodowania oznacza konwersję informacji w formularzu wygodnym dla transmisji do określonego kanału komunikacyjnego.
Odwróć operację - dekodowanie - jest przywrócenie odebranych wiadomości z zakodowanego widoku do ogólnie przyjętych, dostępnych dla konsumenta.
W teorii kodowania istnieje wiele obszarów:
- statyczne lub wydajne kodowanie;
- zakodowanie odporne na hałas;
- kody naprawcze;
- kody cykliczne;
- kody arytmetyczne.
Wraz z pojawieniem się systemów sterujących, w szczególności komputery, rola kodowania znacznie wzrosła i zmieniła, ponieważ transmisja informacji jest niemożliwa bez kodowania. Ostatnio pojawiła się nowy obszar wiedzy w związku z rozwojem systemów telekomunikacyjnych i szerokiego wykorzystania sprzętu komputerowego do przetwarzania i przechowywania informacji - bezpieczeństwo informacji.
Kodowanie nazywane jest uniwersalną metodą wyświetlania informacji podczas przechowywania, przetwarzania i przesyłania w postaci systemu korespondencji między sygnałami i elementami wiadomości, z którymi można zamocować te elementy.
Kod jest określoną regułą konwersji z jednej symbolicznej wiadomości do drugiej, zwykle bez utraty informacji.
Jeśli wszystkie słowa kodowe mają taką samą długość, kod jest nazywany mundurami lub blokiem.
W ramach abstrakcyjnego alfabetu zrozumiemy zamówiony dyskretny zestaw znaków.
Kodowanie alfabetyczne. Alfabetycznie, tj. Sponquent, kodowanie można ustawić jako tabela kodów. W rzeczywistości kod konwersji jest pewną substytucją.
Gdzie alfabet A, zestaw słów sporządzonych w alfabetu V. Wiele liter literowych nazywanych jest mnogość kodów podstawowych. Kodowanie alfabetyczne można użyć do dowolnego zestawu wiadomości.
Przetwarzanie danych komputerowych opiera się na użyciu kodu binarnego. Ta uniwersalna metoda kodowania jest odpowiednia dla dowolnych danych, niezależnie od ich pochodzenia i treści.
Kodowanie tekstu
Teksty są sekwencją symboli przychodzących na niektórych alfabetu. Kodowanie tekstowe jest zredukowane do kodowania alfabetu binarnego, na podstawie którego jest zbudowany. Najczęściej używany jest kodowanie bajtu alfabetu. W tym przypadku maksymalna moc alfabetu wynosi 256 znaków. Taki alfabet może zawierać dwa zestawy symboli alfabetycznych (na przykład, rosyjskiej i łacińskiej), liczb, znaków interpunkcyjnych i znaków matematycznych, przestrzeni i niewielkiej liczby dodatkowych znaków. Przykładem takiego alfabetu jest kod ASCII.
Jednak ograniczony zestaw 256 znaków Dzisiaj nie spełnia już zwiększonych potrzeb komunikacji międzynarodowej. Uniwersalny układ 16-bitowego kodowania znaków Unicode staje się coraz bardziej dystrybucji.
Moc alfabetu w systemie kodowania Unicode wynosi 216 \u003d 65,536 różnych kodów, z których 63 484 kod odpowiada symbolom większości alfabetów, a pozostałe 2048 kody są podzielone na pół i tworzą tabelę o wielkości 1024 kolumn x 1024 rzędy. W tej tabeli ponad milion komórek, w których istnieje nawet więcej niż milion różnych symboli. Są to symbole języków "martwych", a także symboli, które nie mają zawartości leksykalnej, wskaźników, znaków itp. Aby nagrać te dodatkowe znaki, wymagane jest para 16-bitowych słów (16 wyładowań dla numeru wiersza i 16 cyfr dla numeru kolumny).
W ten sposób system Unicode jest uniwersalny system Kodowanie wszystkich symboli krajowych systemów pisanych i ma możliwość istotnej ekspansji.
Obrazy kodujące
Koszulowane są zdjęcia, zdjęcia, zdjęcia w format rastrowy . W tym formularzu każdy obraz jest prostokątnym stołem składającym się z punktów kolorów. Kolor i jasność każdego pojedynczego punktu są wyrażone w formie numerycznej, co pozwala na użycie kodu binarnego do prezentacji danych graficznych.
Czarno-białe obrazy są podejmowane w celu reprezentowania w szarości, w tym celu stosuje się model greystów. Jeśli jasność punktu jest zakodowana przez jeden bajt, możesz użyć 256 różnych kolorów szarych. Taka dokładność jest zgodna z podatnością na ludzkie oko i możliwości sprzętu drukarskiego.
Podczas kodowania obrazów kolorów zasada koloru rozkładu do komponentów jest używana, w tym model RGB jest używany. Obraz kolorowy na ekranie otrzymuje się przez mieszanie trzech podstawowych kolorów: czerwony (czerwony, r), niebieski (niebieski, b) i zielony (zielony, g).
Każdy piksel na ekranie składa się z trzech ściśle zlokalizowanych elementów świecące z tymi kolorami.
Wyświetlacze kolorów, które używają takiej zasady nazywa się RGB-Monitor.
Kod koloru pikseli zawiera informacje o udziałie każdego podstawowego koloru.

schemat kolorystyki
Jeśli wszystkie trzy składniki mają taką samą intensywność (jasność), z ich kombinacji można uzyskać 8 różnych kolorów (23):
brązowy |
|||
Formowanie kolorów z głębokością koloru 24 bitów:
Im większa głębokość koloru, szersza zakres dostępnych kolorów i dokładniej ich reprezentacji na cyfrowym obrazie. Piksel z bitową głębokością, równa jednostka.Ma tylko 2 (w pierwszym stopniu) możliwych stanów - dwa kolory: czarny lub biały. Piksel z głębokością bitową 8 jednostek ma 28 lub 256 możliwych wartości kolorów. Piksel o głębokości bitowej 24 jednostek ma 224 stopnie) lub 16,7 miliona możliwych wartości. Uważa się, że 24-bitowe obrazy zawierające 16,7 miliona kolorów wystarczająco przesyłają farby wokół nas świata. Z reguły rozdzielczość bitowa jest ustawiona w zakresie od 1 do 48 bitów / pikseli.
Podczas drukowania na papierze stosuje się nieco inny moduł koloru: Jeśli monitor emitowany światło, odcień uzyskano w wyniku składanych kolorów, a następnie farby są pochłaniane przez światło, kolory są odjęte. Dlatego, jak główny używany niebieski (cyjan, c), fioletowy (magenta, m) i żółty (żółty, y) farby. Ponadto, ponieważ nie jest idealnością barwników, zwykle dodają czwarty - czarny (czarny, k). Aby przechowywać informacje o każdej farbie, aw tym przypadku, najczęściej używany jest 1 bajt. Ten system kodowania nazywa się CMYK.
Mniejsza reprezentacja kolorów wykorzystuje mniejszą liczbę wyładowań. Na przykład, kodowanie kolorowych grafiki 16-bitowych numery jest nazywany wysokim kolorem. W tym przypadku każdy kolor jest odprowadzany.
Kodowanie dźwięku i wideo
Przyszły techniki informacji o dźwięku technika komputerowa Później. Metoda kodowania analitycznego ma zastosowanie do dowolnego sygnały dźwiękowe Na podstawie konwersji analogowej do cyfrowej. Oryginalny sygnał analogowy jest reprezentowany jako sekwencja sygnałów cyfrowych nagranych w kodzie binarnej. Transformacja konwersji określa ilość danych odpowiadających oddzielnym sygnałem cyfrowym. Podczas odtwarzania dźwięk jest wykonywany odwrotną konwersję analogową cyfrową.
Ta metoda kodowania zawiera błąd, dzięki czemu odtwarzalny sygnał jest nieco inny niż oryginał.
Sposób kodowania na podstawie syntezy tabeli ma zastosowanie tylko do produktu muzycznego. W wyprzedzeni przechowywane stoły, próbki (próbki) dźwięków różnych dźwięków są przechowywane instrumenty muzyczne. Kody numeryczne definiują narzędzie, uwaga i czas trwania dźwięku.
Podczas kodowania sygnału wideo należy napisać sekwencję obrazów (ramek) i dźwięku (ścieżka dźwiękowego). Format wideo umożliwia włączenie obu strumieni danych w jednej sekwencji cyfrowej.